
搜索引擎工作原理
點(diǎn)擊上方關(guān)注 前端技術(shù)江湖,一起學(xué)習(xí),天天進(jìn)步
作者:君額上似可跑馬
https://segmentfault.com/a/1190000019830311
搜索引擎的工作過程大體可以分為三個階段:
1.對網(wǎng)頁進(jìn)行抓取建庫
搜索引擎蜘蛛通過抓取頁面上的鏈接訪問其他網(wǎng)頁,將獲得的HTML代碼存入數(shù)據(jù)庫
2.預(yù)處理
索引程序?qū)ψト淼捻撁鏀?shù)據(jù)進(jìn)行文字提取、中文分詞、索引等處理,為后面排名程序使用時做準(zhǔn)備。
3.給搜索結(jié)果進(jìn)行排名
用戶輸入關(guān)鍵詞后,排名程序調(diào)用索引庫數(shù)據(jù),計算數(shù)據(jù)和關(guān)鍵詞的相關(guān)性,然后按照一定格式生成搜索結(jié)果頁面。
用到了大概三個程序,蜘蛛、索引程序、排名程序
對網(wǎng)頁進(jìn)行爬行、抓取、建庫
如果我們要從一個頁面進(jìn)入另一個頁面,我們需要在頁面上點(diǎn)擊這個超鏈接跳轉(zhuǎn)到新的頁面,這個鏈接指向另一個網(wǎng)頁,相當(dāng)于這個網(wǎng)頁的入口
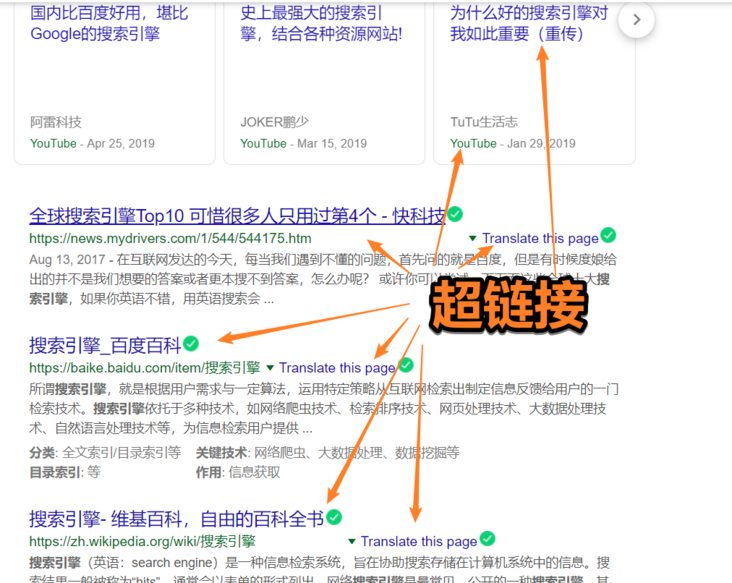
或者如果我們知道這個網(wǎng)頁的url地址,就算我們沒有在頁面上看到鏈接到該網(wǎng)頁的可點(diǎn)擊的超鏈接,也可以通過在地址欄輸入url地址轉(zhuǎn)到該頁面
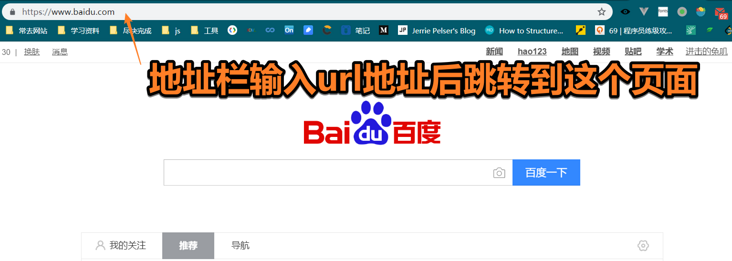
當(dāng)我們在一個網(wǎng)站發(fā)布了自己的文章,這篇文章會產(chǎn)生一個新的獨(dú)一無二的url地址,當(dāng)人們點(diǎn)擊這個地址,它不會跳轉(zhuǎn)到其他人寫的文章頁面,而是你寫的特定的那一篇。
可以看出,所有頁面,都會產(chǎn)生一個url地址使我們可以訪問它。
整個互聯(lián)網(wǎng)是由相互鏈接的頁面組成的,如果一個網(wǎng)頁,沒有任何一個頁面鏈接它,我們也不知道這個網(wǎng)頁的地址,就算這個頁面真實(shí)存在,它也會像一個孤島一樣,我們無法訪問到這個頁面。
日常生活中我們有多個搜索引擎可以使用,比如百度、谷歌、搜狗、bing等。
不同的搜索引擎就算查詢同一個內(nèi)容返回出來的結(jié)果都不一樣,這是因?yàn)楦鱾€公司給內(nèi)容進(jìn)行排序的計算方式都是不一樣的,哪個頁面該排到第一頁/哪個網(wǎng)頁該排到最后一頁/哪個網(wǎng)頁根本就不應(yīng)該展示出來都是有他們公司自己的評判標(biāo)準(zhǔn),這些排名算法具體的內(nèi)容基本都不會對外公開,避免被其他公司搜索引擎公司知道,因?yàn)榕琶惴ㄊ敲總€搜索引擎公司的核心競爭力。
為什么排名算法是每個搜索引擎公司的核心競爭力?
一般人們都會看哪個搜索引擎搜索出來的結(jié)果更符合TA自己的需求(相關(guān)性更高)就會選擇長期使用哪一個。
比如,你在搜索輸入框里輸入【空調(diào)】兩個字想查詢關(guān)于空調(diào)的信息,結(jié)果搜索結(jié)果頁給你返回的內(nèi)容第一頁竟然是一些電視機(jī)/馬桶/衣柜之類的銷售鏈接,這樣相關(guān)性不高的網(wǎng)頁越多,對你的使用體驗(yàn)就越差,最好的體驗(yàn)是,你搜索【空調(diào)】后,返回的頁面里全是關(guān)于空調(diào)的信息,這樣節(jié)約了你獲取信息的時間成本,使你更方便的獲取想要的資訊。
而排名算法就是為了讓返回的結(jié)果盡量符合用戶查詢的內(nèi)容的一種算法,他會對網(wǎng)頁進(jìn)行排名,把覺得對用戶最有價值的網(wǎng)頁排在前面,比如第一頁第一個,用戶能最快的看到這個網(wǎng)頁,把相關(guān)性較差不重要的網(wǎng)頁排在后面。把那些沒有用的沒有價值的頁面直接不展示出來,經(jīng)過對這些網(wǎng)頁的排序,讓用戶盡量在只看第一頁的情況下就能找到自己想要的資訊,解決掉自己的問題。
所以搜索引擎公司只要能對網(wǎng)頁進(jìn)行合理的排序,帶給用戶最大的方便,讓用戶感覺到返回的內(nèi)容都很精準(zhǔn),正好是他們想要的內(nèi)容,那么用戶就會持續(xù)使用這個搜索引擎,所以如何對這些網(wǎng)頁進(jìn)行排序的計算方式就是每個搜索引擎公司的公司機(jī)密了。
爬行和抓取搜索引擎工作的第一步,目的是完成數(shù)據(jù)收集的任務(wù)。
當(dāng)用戶在搜索框輸入想查詢的內(nèi)容后,所有展示出來的網(wǎng)頁都是需要先經(jīng)過搜索引擎的收集才能展示出來的,只有收集了,才能通過分析網(wǎng)頁中的內(nèi)容,對這些網(wǎng)頁的價值和相關(guān)性進(jìn)行一個判斷,經(jīng)過對網(wǎng)頁的排序之后再返回給用戶,用戶在搜索結(jié)果頁上看到的所有網(wǎng)頁,都是已經(jīng)被搜索引擎收集進(jìn)數(shù)據(jù)庫中的網(wǎng)頁。
而那些互聯(lián)網(wǎng)上沒有被搜索引擎收集到的網(wǎng)頁(搜索引擎不是什么網(wǎng)頁都會放進(jìn)數(shù)據(jù)庫,每個搜索引擎都有自己的一個標(biāo)準(zhǔn),就是什么樣的網(wǎng)頁才會被收集到數(shù)據(jù)庫中。就像人類吃東西一樣,只吃自己認(rèn)為該吃的食物),就變成了永遠(yuǎn)無法訪問的孤魂野鬼。
注:網(wǎng)頁和網(wǎng)站的區(qū)別需要注意,蜘蛛在判斷需不需要收集進(jìn)索引數(shù)據(jù)庫的是以網(wǎng)頁為單位的。
比如整個淘寶是一個網(wǎng)站,但是淘寶中某一個商品的詳情頁面才算網(wǎng)頁,還比如你現(xiàn)在所看的這篇文章所在的這一個頁面才算網(wǎng)頁。
所以,整個淘寶網(wǎng)站的頁面那么多,蜘蛛在收集網(wǎng)頁時,就算收集了A商品那頁詳情頁面,但不代表B商品詳情頁面也被收集進(jìn)索引數(shù)據(jù)庫了,蜘蛛會對每個頁面進(jìn)行評判,只有該頁面到達(dá)他的標(biāo)準(zhǔn)了,認(rèn)為可以收集到索引數(shù)據(jù)庫里了,才會把這個頁面添加進(jìn)去,而不是它認(rèn)為淘寶這個網(wǎng)站很有價值,就把整個網(wǎng)站里所有頁面全部收錄進(jìn)去了,SEO里有個概念叫做收錄率,指的是頁面的收錄率,而不是網(wǎng)站的收錄率。
蜘蛛
搜索引擎用來爬行和訪問頁面的程序叫做蜘蛛/爬蟲(spider),或機(jī)器人(bot)。
蜘蛛訪問網(wǎng)站頁面的流程和人們在瀏覽器上訪問頁面的流程差不多,蜘蛛訪問頁面時,會發(fā)出頁面訪問請求,服務(wù)器會返回HTML代碼,蜘蛛把收到的HTML代碼存入原始頁面數(shù)據(jù)庫。
互聯(lián)網(wǎng)上的頁面這么多,為了提高爬行和抓取的速度,搜索引擎會同時使用多個蜘蛛對頁面進(jìn)行爬行。
理論上來說,互聯(lián)網(wǎng)上的所有頁面(這里指的是通過超鏈接互聯(lián)鏈接在一起的頁面,而不是那種雖然這個頁面存在,但是沒有任何網(wǎng)頁用超鏈接指向他),蜘蛛都可以沿著頁面上的超鏈接將所有頁面爬行一遍,但是蜘蛛不會這么做,蜘蛛的時間有限,它會用效率最高的方式找到互聯(lián)網(wǎng)上它覺得最有價值的網(wǎng)頁。
如果一個網(wǎng)站的頁面普遍質(zhì)量較低,蜘蛛就會認(rèn)為這是一個低質(zhì)網(wǎng)站,讓用戶閱讀這類沒有價值的網(wǎng)頁是沒有必要的,對于這類網(wǎng)頁,它會減少爬行的頻率,將重點(diǎn)放在其他質(zhì)量更高的網(wǎng)站,去其他更有價值的網(wǎng)站上收集網(wǎng)頁存入數(shù)據(jù)庫。
但是蜘蛛不是全能,它也有評判錯誤的時候,比如蜘蛛不會收集空短頁面,也就是內(nèi)容空洞毫無營養(yǎng),主體內(nèi)容又短的頁面,蜘蛛不會浪費(fèi)數(shù)據(jù)庫的空間放入這些網(wǎng)頁。
但是一個頁面究竟是不是真正的無價值網(wǎng)頁,蜘蛛判斷成功的正確率并不是100%,就像一個登錄驗(yàn)證網(wǎng)頁,確實(shí)沒有比那些傳遞知識的網(wǎng)頁更有價值,但是這是大部分網(wǎng)站一個必不可少的一個頁面,嚴(yán)格來說并不是低質(zhì)頁面,但是如果蜘蛛爬行到了這個頁面,它并不理解人類眼中的驗(yàn)證頁面是一個怎樣的存在,他只覺得,內(nèi)容短,沒什么豐富的內(nèi)容,好,那就是無價值的網(wǎng)頁了,它就像有一個專門用來記錄的小本本一樣,嗯,A網(wǎng)站,有一個低質(zhì)頁面,給這個網(wǎng)站評價好還是不好我還要在考慮一下,如果這樣的低質(zhì)頁面多了,蜘蛛就會覺得你的網(wǎng)站整體質(zhì)量較低,慢慢的就不愛到你網(wǎng)站上抓取網(wǎng)頁了。
所以為了避免這種情況,不讓蜘蛛抓取這些網(wǎng)頁是最好的辦法,我們可以在項目根目錄創(chuàng)建一個txt文件,這個文件叫什么是有約定俗成的,文件名必須為 robots.txt,我們在文件里面規(guī)定好蜘蛛可以爬行/不能爬行哪些網(wǎng)頁就行(具體寫法可以百度)。
當(dāng)蜘蛛訪問任何一個網(wǎng)站的時候,第一件事就是先訪問這個網(wǎng)站根目錄下的robots.txt文件,如果文件里說了禁止讓蜘蛛抓取XX文件/XX目錄,蜘蛛就會按照文件里規(guī)定的那樣,只抓取可以抓取的頁面。
蜘蛛的分類
每個搜索引擎公司都有自己的蜘蛛,這些蜘蛛喜好不一,喜歡抓取什么類型的網(wǎng)頁要看他們的主人,也就是要看搜索引擎公司他們的想法,雖然這些蜘蛛統(tǒng)稱為蜘蛛,但他們屬于不同的主人,當(dāng)然名字肯定是不一樣的。
在日志文件中可以看到有哪些公司的蜘蛛來訪問過網(wǎng)站(user-agent那個)
蜘蛛主要分為下面幾個:
百度蜘蛛 Baiduspider
谷歌蜘蛛 Googlebot
有道蜘蛛 YodaoBot
理論上來說,隨便找一個頁面,順著這個頁面,蜘蛛可以將互聯(lián)網(wǎng)上所有的頁面都爬一遍
實(shí)際上這樣確實(shí)是可行的(除去那些沒有被任何一個網(wǎng)頁所指向的頁面),而蜘蛛是如何做到的呢?
比如,蜘蛛先從A頁面開始,它爬行到A頁面上,它可以獲取到A頁面中所有的超鏈接,蜘蛛再順著這個鏈接進(jìn)入到鏈接所指向的頁面,再獲取到這個頁面上所有的超鏈接進(jìn)行爬行抓取,這樣一來,所有用超鏈接所關(guān)聯(lián)上的網(wǎng)頁便可以被蜘蛛都爬行一遍。
蜘蛛在爬行時,也是有自己的爬行策略的,就像吃西瓜,把整個西瓜切一半切成一個半圓體,我們選擇吃西瓜的方式可以深度優(yōu)先,隨便從中間還是邊緣開始吃都行,比如先從中間吃,西瓜中間底下全部挖干凈了再圍著中間的圓圈慢慢往外面擴(kuò)散。
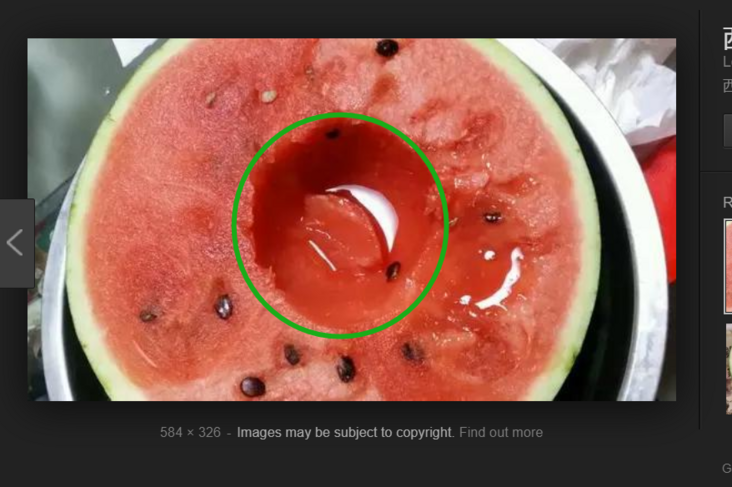
或者廣度優(yōu)先,從中間或者是邊緣隨便哪里開始都行,把表面一層挖完了西瓜再進(jìn)行下一個深度的挖取。
蜘蛛的爬行策略
蜘蛛的爬行策略和挖西瓜一樣,都是兩種方式
深度優(yōu)先
廣度優(yōu)先
深度優(yōu)先如下圖
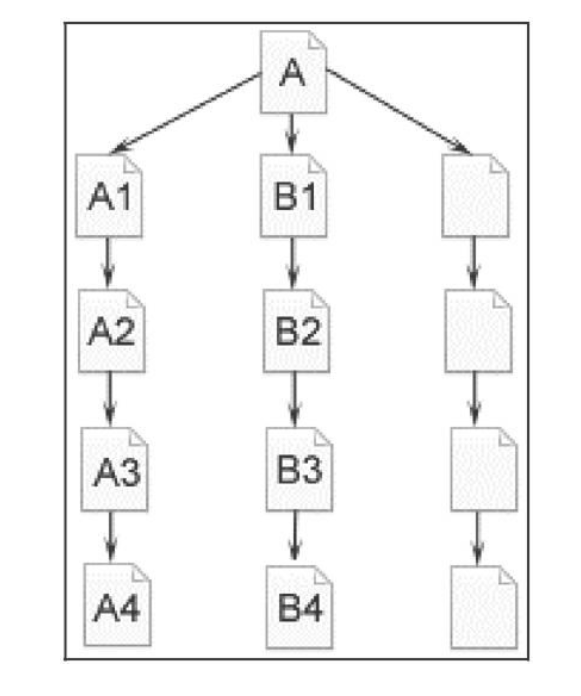
蜘蛛先從A頁面開始爬行,發(fā)現(xiàn)該頁面總共有3個超鏈接,A1、B1、XX,蜘蛛選擇先從A1頁面爬行下去,它在A1頁面發(fā)現(xiàn)了一個唯一的超鏈接A2,便沿著A2向下,以此類推,等爬到最底下,也就是A4頁面,A4整個頁面上沒有任何超鏈接,再也無法往下爬行了,它便返回到B1開始爬行,這就是深度優(yōu)先。
廣度優(yōu)先如下
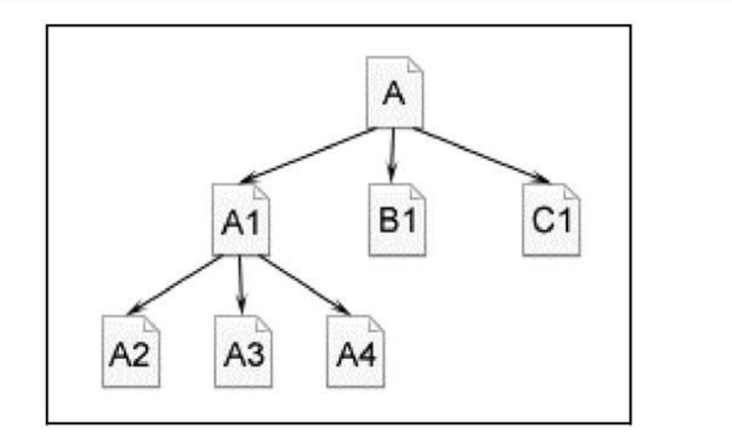
這次這是一個利用廣度優(yōu)先策略的蜘蛛,它先從A頁面出發(fā),現(xiàn)在A頁面有3個鏈接,A1、B1、C1,它會先把A1、B1、C1先爬一遍,也就是第一層發(fā)現(xiàn)的超鏈接全部爬行完,然后再進(jìn)入第二層,也就是A1頁面。把A1頁面中所有的超鏈接全部爬行一遍,保證廣度上全部鏈接是都完成爬行了的。
無論是深度優(yōu)先還是廣度優(yōu)先,蜘蛛都可以通過這兩個策略完成對整個互聯(lián)網(wǎng)頁面的爬行。
當(dāng)然,由于蜘蛛的帶寬資源和時間有限的問題,蜘蛛不會選擇爬完所有頁面,它實(shí)際收集到的頁面知識互聯(lián)網(wǎng)的一小部分,在條件限制的情況下,蜘蛛通常會深度優(yōu)先和廣度優(yōu)先混合使用,廣度優(yōu)先保證了盡可能照顧到多的網(wǎng)站,而廣度優(yōu)先保證了盡可能照顧到一部分網(wǎng)站中的內(nèi)頁。
吸引蜘蛛抓取頁面
可以看出,在實(shí)際情況中,蜘蛛不會爬行、抓取互聯(lián)網(wǎng)上所有的頁面,既然如此,蜘蛛所要做的就是盡量抓取重要頁面,而SEO人員要做的,就是吸引蜘蛛的注意,讓蜘蛛更多的抓取自己家網(wǎng)站的頁面。
對于蜘蛛來說,頁面擁有哪些特征會被看作是重要頁面呢,主要有以下這幾方面因素:
1.網(wǎng)站和頁面權(quán)重
質(zhì)量高,資格老的網(wǎng)站被認(rèn)為權(quán)重較高,這種網(wǎng)站上頁面的爬行深度也會比較高,所以這種網(wǎng)站網(wǎng)頁被收錄的機(jī)會會更多。
2.頁面更新度
如A網(wǎng)頁的數(shù)據(jù)之前在蜘蛛爬行后已經(jīng)被保存在數(shù)據(jù)庫中了,當(dāng)蜘蛛第二次爬行A網(wǎng)頁時,會將A網(wǎng)頁此時的數(shù)據(jù)和數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)行對比,如果蜘蛛發(fā)現(xiàn)A網(wǎng)頁的內(nèi)容更新了,就會認(rèn)為這個網(wǎng)頁更新頻率多,蜘蛛抓取這個頁面的頻率也會更加頻繁,如果頁面和上次儲存的數(shù)據(jù)完全一樣,就說明頁面是沒更新,蜘蛛就會減少自己爬行該頁面的頻率。
3.高質(zhì)量的外鏈
張三是班上公認(rèn)的人品好為人公正的學(xué)霸,李四是班上惹人討厭最愛撒謊的學(xué)生,張三給大家說王五這個人真的很聰明為人也很善良,其他同學(xué)都會認(rèn)為王五肯定是這樣,李四給其他同學(xué)說王五這個人很好,其他同學(xué)基本不會相信李四的鬼話。
同樣一句話,從不同人的嘴里說出來,造成的結(jié)果、影響都不一樣。
鏈接的引用也是這樣,比如在一個蜘蛛認(rèn)為的高質(zhì)量頁面中,頁面在最后引用了一個鏈接,指向你的頁面,那么這個高質(zhì)量頁面的引用,在蜘蛛判斷你的網(wǎng)頁是否是高質(zhì)量網(wǎng)頁時,也會產(chǎn)生一定的影響,被高質(zhì)量網(wǎng)頁引用的多了(超級多的大佬夸你人好),那么蜘蛛在判斷你頁面時產(chǎn)生的影響也就更大(同學(xué)也覺得你就是人好)。
4.與首頁的距離
一般來說自己網(wǎng)站被其他網(wǎng)站引用最多的頁面就是首頁,所以它的權(quán)重相比來說是最高的,比如A頁面是A網(wǎng)站的首頁,可以得出的結(jié)論是,離A網(wǎng)頁更進(jìn)的頁面,頁面權(quán)重也容易更高,比如A頁面上的超鏈接更容易被蜘蛛爬行,更容易獲得蜘蛛的抓取,那些沒被蜘蛛發(fā)現(xiàn)的網(wǎng)頁,權(quán)重自然就是0。
還有一點(diǎn)比較重要的是,蜘蛛在爬行頁面時會進(jìn)行一定程度的復(fù)制檢測,也就是當(dāng)前被爬行的頁面的內(nèi)容,是否和已經(jīng)保存的數(shù)據(jù)有重合(當(dāng)頁面內(nèi)容為轉(zhuǎn)載/不當(dāng)抄襲行為時就會被蜘蛛檢測出來),如果一個權(quán)重很低的網(wǎng)站上有大量轉(zhuǎn)載/抄襲行為,蜘蛛很可能不會再繼續(xù)爬行。
之所以要這么做也是為了用戶的體驗(yàn),如果沒有這些去重步驟,當(dāng)用戶想要搜索一些內(nèi)容時,發(fā)現(xiàn)返回的結(jié)果全都是一模一樣的內(nèi)容,會大大影響用戶的體驗(yàn),最后導(dǎo)致的結(jié)果就是這個搜索引擎絕對不會有人再用了,所以為了用戶使用的便利,也是為了自己公司的正常發(fā)展。
地址庫
互聯(lián)網(wǎng)上的網(wǎng)頁這么多,為了避免重復(fù)爬行和抓取網(wǎng)頁,搜索引擎會建立地址庫,一個是用來記錄已經(jīng)被發(fā)現(xiàn)但還沒有抓取的頁面,一個是已經(jīng)被抓取過的頁面。
待訪問地址庫(已經(jīng)發(fā)現(xiàn)但沒有抓取)中的地址來源于下面幾種方式:
1.人工錄入的地址
2.蜘蛛抓取頁面后,從HTML代碼中獲取新的鏈接地址,和這兩個地址庫中的數(shù)據(jù)進(jìn)行對比,如果沒有,就把地址存入待訪問地址庫。
3.站長(網(wǎng)站負(fù)責(zé)人)提交上去的想讓搜索引擎抓取的頁面。(一般這種效果不大)
蜘蛛按照重要性從待訪問地址庫中提取URL,訪問并抓取頁面,然后把這個URL地址從待訪問地址庫中刪除,放進(jìn)已訪問地址庫中。
文件存儲
蜘蛛會將抓取的數(shù)據(jù)存入原始頁面數(shù)據(jù)庫。
存入的數(shù)據(jù)和服務(wù)器返回給蜘蛛的HTML內(nèi)容是一樣的,每個頁面存在數(shù)據(jù)庫里時都有自己的一個獨(dú)一無二的文件編號。
預(yù)處理
我們?nèi)ド虉鲑I菜時,會看到蔬菜保險柜里的這些蔬菜被擺放的整整齊齊,這里舉的例子是那些用保鮮膜包好有經(jīng)過包裝的蔬菜。

最后呈現(xiàn)在顧客面前的就是上面這張圖那樣,包裝完好,按照不同的分類擺放有序,顧客一眼就能很清楚的看到每個區(qū)域分別是什么蔬菜。
在最終完成這個結(jié)果之前,整個流程大概也是三個步驟:
1.選出可以售賣的蔬菜
從一堆蔬菜中,選出可以拿去售賣的蔬菜。
2.預(yù)處理
此時你面前擺放的就是全部可以拿去售賣的蔬菜了,但是如果,今天就要把這些蔬菜放到蔬菜保險柜中的話,你今天才開始對這些蔬菜進(jìn)行整理會浪費(fèi)大量的時間(給蔬菜進(jìn)行包裝等),說不定顧客來了蔬菜還沒整理好。
所以你的解決方法是,提前將這些可以拿去售賣的蔬菜提前包裝好,存放在倉庫里,等保險柜中的蔬菜缺少了需要補(bǔ)貨時,花個幾分鐘時間跑去倉庫把蔬菜拿出來再擺放再貨架上就行了。(我猜的,具體商場里的流程是怎么樣的我也不知道,為了方便后續(xù)的理解用生活上的例子進(jìn)行說明效果會更好)
3.擺放上保險柜
也就是上面最后一段內(nèi)容那樣,當(dāng)需要補(bǔ)貨時,從倉庫里拿出包裝好的蔬菜,按照蔬菜的類別擺放到合適的位置就可以了,這個就是最后的排序步驟。
回到搜索引擎的工作流程中,這個預(yù)處理的步驟就和上面商場預(yù)處理步驟的作用一樣。
當(dāng)蜘蛛完成數(shù)據(jù)收集后,就會進(jìn)入到這個步驟。
蜘蛛所完成的工作,就是在收集了數(shù)據(jù)后將數(shù)據(jù)(HTML)存入原始頁面數(shù)據(jù)庫。
而這些數(shù)據(jù),不是用戶在搜索后,直接用來進(jìn)行排序并展示在搜索結(jié)果頁的數(shù)據(jù)。
原始頁面數(shù)據(jù)庫中的頁面數(shù)量都是在數(shù)萬億級別以上,如果在用戶搜索后對原始頁面數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)行實(shí)時排序,讓排名程序(每個步驟所使用的程序不一樣,收集數(shù)據(jù)的程序叫蜘蛛,排名時所用的程序是排名程序)分析每個頁面數(shù)據(jù)與用戶想搜索的內(nèi)容的相關(guān)性,計算量太大,會浪費(fèi)太多時間,不可能在一兩秒內(nèi)返回排名結(jié)果。
因此,我們需要先將原始頁面數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)行預(yù)處理,為最后的排名做好準(zhǔn)備。
提取文字
我們存入原始頁面數(shù)據(jù)庫中的,是HTML代碼,而HTML代碼中,不僅有用戶在頁面上直接可以看到的文字內(nèi)容,還有其他例如js,AJAX等這類搜索引擎無法用于排名的內(nèi)容。
首先要做的,就是從HTML文件中去除這些無法解析的內(nèi)容,提取出可以進(jìn)行排名處理步驟的文字內(nèi)容
比如下面這段代碼
<html>
<head>
<meta charset="utf-8">
<meta name="description" content="這是一個描述內(nèi)容"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no">
<link rel="icon" type="image/png" sizes="32x32" href="http://static001.infoq.cn/static/infoq/www/img/InfoQ-share-icon2.jpg">
<title>軟件工程師需要了解的搜索引擎知識</title>
<script type="text/javascript" src="http://res.wx.qq.com/open/js/jweixin-1.4.0.js"></script>
<script type="text/x-mathjax-config">
MathJax.Hub.Config({
showProcessingMessages: false,
messageStyle: "none",
tex2jax: {
inlineMath: [['$','$'], ['\\(','\\)']],
displayMath: [ ["$$","$$"] ],
skipTags: ['script', 'noscript', 'style', 'textarea', 'pre', 'code', 'a']
}
});
MathJax.Hub.Register.MessageHook("End Process", function (message) {
var eve = new Event('mathjaxfini')
window.dispatchEvent(eve)
})
</script>
</head>
<body>
<div id="app">hi</div>
<img alt="Google" src="/images/test.png"
</body>
</html>
可以看出整個HTML中,真正屬于文字內(nèi)容的信息只有兩句
這是一個描述內(nèi)容
軟件工程師需要了解的搜索引擎知識
hi
Google
搜索引擎最終提取出來的信息就是這四句,用于排名的文字也是這四句。
可以提取出來的文字內(nèi)容大概就是,Meta標(biāo)簽中的文字、img標(biāo)簽alt屬性中的文字、Flash文件的替代文字、鏈接錨文字等。
中文分詞
分詞是中文搜索引擎特有的步驟,搜索引擎存儲/處理頁面/用戶搜索時都是以詞為基礎(chǔ)的。
I'm fine, and you?
中文和英文等語言單詞不同,在使用英文時各個單詞會有空格分隔,搜索引擎可以直接把每一個句子劃分為多個英文單詞的集合。而對中文來說,詞匯和詞匯之間是沒有任何分隔符可以對各詞匯進(jìn)行分隔的。
比如這句話里的詞就是連接在一起的
對于這種情況,搜索引擎首先需要分辨哪幾個字組成一個詞,如 我喜歡吃【水果】,或者哪些字本身就是一個詞,如 這里有【水】,
再如下面這句話
你好,這是一篇關(guān)于搜索引擎的文章
搜索引擎會將這一段文字拆解成一個個詞匯,大概如下
你好
這是
一篇
關(guān)于
搜索引擎
的
文章
搜索引擎將這段文字拆解成了7個詞匯(我瞎猜的,具體多少個我也不知道,每個搜索引擎分詞的方法都不一樣)
中文分詞的方法基本上有兩種:
基于詞典匹配
基于統(tǒng)計
1.基于詞典匹配
將需要分析的一段漢字與一個時間創(chuàng)建好的詞典中的詞條進(jìn)行匹配,如果在這段漢字中掃描到詞典中已有的詞條則匹配成功。
這種匹配方式最簡單,但匹配的正確程序取決于這個詞典的完整性和更新情況。
2.基于統(tǒng)計
一般是通過機(jī)器學(xué)習(xí)完成,通過對海量網(wǎng)頁上的文字樣本進(jìn)行分析,計算出字與字相鄰出現(xiàn)的統(tǒng)計概率,幾個字相鄰出現(xiàn)越多,就越可能形成一個詞。
這種優(yōu)勢是對新出現(xiàn)的詞反應(yīng)更快速。
實(shí)際使用中的分詞系統(tǒng)都是兩種方法同時混合使用。
去停止詞
不管是英文還是中文,頁面中都會有一些出現(xiàn)頻率很高的&對內(nèi)容沒有任何影響的詞,如中文的【的】、【啊】、【哈】之類,這些詞被稱為停止詞。
英文中常見的停止詞有[the]/[a]/[an]等。
搜索引擎會去掉這些停止詞,使數(shù)據(jù)主題更突出,減少無謂的計算量。
去掉噪聲詞
大部分頁面里有這么一部分內(nèi)容對頁面主題沒什么貢獻(xiàn),比如A頁面的內(nèi)容是一篇關(guān)于SEO優(yōu)化的文章,關(guān)鍵詞是SEO,但是除了講解SEO這個內(nèi)容的主體內(nèi)容外,共同組成這個頁面的還有例如頁眉,頁腳,廣告等區(qū)域
在這些部分出現(xiàn)的詞語可能和頁面內(nèi)容本身的關(guān)鍵詞并不相關(guān)。
比如導(dǎo)航欄中如何出現(xiàn)【歷史】這個詞,導(dǎo)航欄上想要表達(dá)的實(shí)際是歷史記錄之類的意思,搜索引擎可能會把他誤以為是XX國家歷史,XX時代歷史之類這種層面的【歷史】,搜索引擎所理解的和頁面本身內(nèi)容想表達(dá)的完全不相關(guān),所以這些區(qū)域都屬于噪聲,在搜索引擎分析一個頁面的時候,它們只會對頁面主題起到分散作用。
搜索引擎的排名程序在對數(shù)據(jù)進(jìn)行排名時不能參考這些噪聲內(nèi)容,我們在預(yù)處理階段就需要把這些噪聲時別出來并消除他們。
消除噪聲的方法是根據(jù)HTML的標(biāo)簽對頁面進(jìn)行分塊,如頁眉是header標(biāo)簽,頁腳是footer標(biāo)簽等等,去除掉這些區(qū)域后,剩下的才是頁面主體內(nèi)容。
去重
也就是去掉重復(fù)的網(wǎng)頁,同一篇文章經(jīng)常會重復(fù)在不同網(wǎng)站/同一個網(wǎng)站的不同網(wǎng)址上。為了用戶的體驗(yàn),去重步驟是必須的,搜索引擎會對頁面進(jìn)行識別&刪除重復(fù)內(nèi)容,這個過程稱為蛆蟲和。
去重的方法是先從頁面主體內(nèi)容中選取最有代表性的一部分關(guān)鍵詞(經(jīng)常是出現(xiàn)頻率最高的關(guān)鍵詞,由于之前已經(jīng)有了去停止詞的步驟,因此在這時出現(xiàn)頻率最高的關(guān)鍵詞可能就真的是整個頁面的關(guān)鍵詞了),然后計算這些關(guān)鍵詞的數(shù)字指紋。
通常我們在頁面中選取10個關(guān)鍵詞就可以達(dá)到比較高的計算準(zhǔn)確性了。
典型的指紋計算方法如MD5算法(信息摘要算法第五版)。這類指紋算法的特點(diǎn)是,輸入(也就是上面提取出來的關(guān)鍵詞)只要有任何微小的變化,都會導(dǎo)致計算出的指紋有很大差距。
比如我們用兩個數(shù)相乘,第一組和第二組的不同僅僅是第一個數(shù)字 0.001 的差別,最終生成的結(jié)果卻千差萬別。

了解了搜索引擎的去重算法后,就會發(fā)現(xiàn)那些在文章發(fā)布者眼里的原創(chuàng)內(nèi)容實(shí)際對搜索引擎來說就是非原創(chuàng),比如簡單的增加/刪除【的】【地】等這些去停止詞、調(diào)換段落順序、混合不同文章等操作,在搜索引擎進(jìn)行去重算法后,都會被判斷為非原創(chuàng)內(nèi)容,因?yàn)檫@些操作并不會改變文章的關(guān)鍵詞。
(比如我寫的這篇筆記里的一些段落就是‘借鑒’了一下,我是從書里看的不是在網(wǎng)頁上直接瀏覽的,如果搜索引擎在對我這篇文章進(jìn)行文字提取、分詞、消噪、去重后,發(fā)現(xiàn)剩下的關(guān)鍵詞和已收錄的某個網(wǎng)頁數(shù)據(jù)的內(nèi)容都匹配上了,就會認(rèn)為我是偽原創(chuàng)甚至非原創(chuàng),最終影響的就是我這篇文章在搜索引擎工作原理這個關(guān)鍵詞上的排名)
正向索引
正向索引可以簡稱為索引。
經(jīng)過上述各步驟(提取、分詞、消噪、去重)后,搜索引擎最終得到的就是獨(dú)特的、能反映頁面主體內(nèi)容的、以詞為單位的內(nèi)容。
接下來由搜索引擎的索引程序提取關(guān)鍵詞,按照分詞程序劃分好的詞,把頁面轉(zhuǎn)換為一個由關(guān)鍵詞組成的集合,同時還需要記錄每一個關(guān)鍵詞在頁面上的出現(xiàn)頻率、出現(xiàn)次數(shù)、格式(如是出現(xiàn)在標(biāo)題標(biāo)簽、黑體、h標(biāo)簽、還是錨文字等)、位置(如頁面第一段文字等)。
搜索引擎的索引程序會將頁面和關(guān)鍵詞形成的詞表結(jié)構(gòu)存儲進(jìn)索引庫。
簡化的索引詞表形式如圖
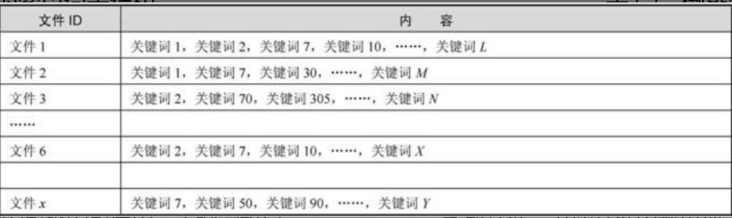
每個文件都對應(yīng)一個文件ID,文件內(nèi)容被表示成一串關(guān)鍵詞的集合。
實(shí)際上在搜索引擎索引庫中,關(guān)鍵詞也已經(jīng)轉(zhuǎn)換為關(guān)鍵詞ID,這樣的數(shù)據(jù)結(jié)構(gòu)被稱為正向索引。
倒排索引
正向索引不能直接用于排名,假設(shè)用戶搜索關(guān)鍵詞【2】,如果只存在正向索引,排名程序需要掃描所有索引庫中的文件,找出包含關(guān)鍵詞【2】的文件,再進(jìn)行相關(guān)性計算。
這樣的計算量無法滿足實(shí)時返回排名結(jié)果的要求。
我們可以提前對所有關(guān)鍵詞進(jìn)行分類,搜索引擎會將正向索引數(shù)據(jù)庫重新構(gòu)造為倒排索引,把文件對應(yīng)到關(guān)鍵詞的映射轉(zhuǎn)換為關(guān)鍵詞到文件的映射,如下圖
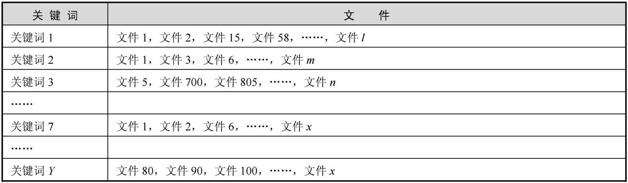
在倒排索引中關(guān)鍵詞是主鍵,每個關(guān)鍵詞都對應(yīng)著一系列文件,比如上圖第一排右側(cè)顯示出來的文件,都是包含了關(guān)鍵詞1的文件。
這樣當(dāng)用戶搜索某個關(guān)鍵詞時,排序程序在倒排索引中定位到這個關(guān)鍵詞,就可以馬上找出所有包含這個關(guān)鍵詞的文件。
給搜索結(jié)果進(jìn)行排名
經(jīng)過前面的蜘蛛抓取頁面,對數(shù)據(jù)預(yù)處理&索引程序計算得到倒排索引后,搜索引擎就準(zhǔn)備好可以隨時處理用戶搜索了。
用戶在搜索框輸入想要查詢的內(nèi)容后,排名程序調(diào)用索引庫的數(shù)據(jù),計算排名后將內(nèi)容展示在搜索結(jié)果頁中。
搜索詞處理
搜索引擎接收到用戶輸入的搜索詞后,需要對搜索詞做一些處理,然后才進(jìn)入排名過程。
搜索詞處理過程包括如下幾個方面:
1.中文分詞
和之前預(yù)處理步驟中的分詞流程一樣,搜索詞也必須進(jìn)行中文分詞,將查詢字符串轉(zhuǎn)換為以詞為單位的關(guān)鍵詞組合。分詞原理和頁面分詞時相同。
2.去停止詞
同上。
3.指令處理
上面兩個步驟完成后,搜索引擎對剩下的內(nèi)容的默認(rèn)處理方式是在關(guān)鍵詞之間使用【與】邏輯。
比如用戶在搜索框中輸入【減肥的方法】,經(jīng)過分詞和去停止詞后,剩下的關(guān)鍵詞為【減肥】、【方法】,搜索引擎排序時默認(rèn)認(rèn)為,用戶想要查詢的內(nèi)容既包含【減肥】,也!注意這個也!!!也包含【方法】!
只包含【減肥】不包含【方法】,或者只包含【方法】不包含【減肥】的頁面,都會被認(rèn)為是不符合搜索條件的。
文件匹配
搜索詞經(jīng)過上面的處理后,搜索引擎得到的是以詞為單位的關(guān)鍵詞集合。
進(jìn)入的下一個階段-文件匹配階段,就是找出含有所有關(guān)鍵詞的文件。
在索引部分提到的倒排索引使得文件匹配能夠快速完成,如下圖
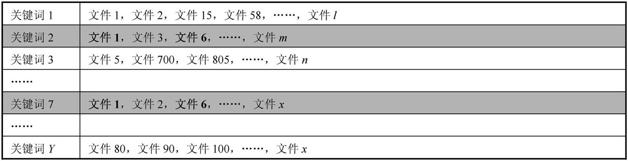
假設(shè)用戶搜索【關(guān)鍵詞2 關(guān)鍵詞7】,排名程序只要在倒排索引中找到【關(guān)鍵詞2】和【關(guān)鍵詞7】這兩個詞,就能找到分別含有這兩個詞的所有頁面文件。
經(jīng)過簡單計算就能找出既包含【關(guān)鍵詞2】,也包含【關(guān)鍵詞7】的所有頁面:【文件1】和【文件6】。
初始子集的選擇
找到包含所有關(guān)鍵詞的匹配文件后,還不能對這些文件進(jìn)行相關(guān)性計算,因?yàn)樵趯?shí)際情況中,找到的文件經(jīng)常會有幾十萬幾百萬,甚至上千萬個。要對這么多文件實(shí)時進(jìn)行相關(guān)性計算,需要的時間還是挺長的。
實(shí)際上大部分用戶只喜歡查看前面兩頁,也就是前20個結(jié)果,后面的真的是懶都懶得翻!
對于google搜索引擎來說,最多只會給用戶返回1000個搜索結(jié)果,如下(100頁,每頁10條結(jié)果)
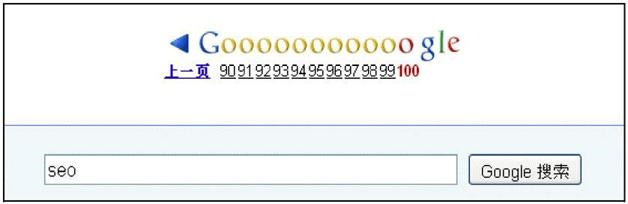
而百度搜索引擎,最多只會返回760條結(jié)果

所以搜索引擎只需要計算前1000/760個結(jié)果的相關(guān)性,就能滿足要求。
由于所有匹配文件都已經(jīng)具備了最基本的相關(guān)性(這些文件都包含所有查詢關(guān)鍵詞),搜索引擎會先篩選出1000個頁面權(quán)重較高的一個文件,通過對權(quán)重的篩選初始化一個子集,再對這個子集中的頁面進(jìn)行相關(guān)性計算。
相關(guān)性計算
用權(quán)重選出初始子集之后,就是對子集中的頁面計算關(guān)鍵詞相關(guān)性的步驟了。
計算相關(guān)性是排名過程中最重要的一步。
影響相關(guān)性的主要因素包括如下幾個方面:
1.關(guān)鍵詞常用程度。
經(jīng)過分詞后的多個關(guān)鍵詞,對整個搜索字符串的意義貢獻(xiàn)并不相同。
越常用的詞對搜索詞的意義貢獻(xiàn)越小,越不常用的詞對搜索詞的意義貢獻(xiàn)越大。舉個例子,假設(shè)用戶輸入的搜索詞是“我們冥王星”。“我們”這個詞常用程度非常高,在很多頁面上會出現(xiàn),它對“我們冥王星”這個搜索詞的辨識程度和意義相關(guān)度貢獻(xiàn)就很小。找出那些包含“我們”這個詞的頁面,對搜索排名相關(guān)性幾乎沒有什么影響,有太多頁面包含“我們”這個詞。
而“冥王星”這個詞常用程度就比較低,對“我們冥王星”這個搜索詞的意義貢獻(xiàn)要大得多。那些包含“冥王星”這個詞的頁面,對“我們冥王星”這個搜索詞會更為相關(guān)。
常用詞的極致就是停止詞,對頁面意義完全沒有影響。
所以搜索引擎對搜索詞串中的關(guān)鍵詞并不是一視同仁地處理,而是根據(jù)常用程度進(jìn)行加權(quán)。不常用的詞加權(quán)系數(shù)高,常用詞加權(quán)系數(shù)低,排名算法對不常用的詞給予更多關(guān)注。
我們假設(shè)A、B兩個頁面都各出現(xiàn)“我們”及“冥王星”兩個詞。但是“我們”這個詞在A頁面出現(xiàn)于普通文字中,“冥王星”這個詞在A頁面出現(xiàn)于標(biāo)題標(biāo)簽中。B頁面正相反,“我們”出現(xiàn)在標(biāo)題標(biāo)簽中,而“冥王星”出現(xiàn)在普通文字中。那么針對“我們冥王星”這個搜索詞,A頁面將更相關(guān)。
2.詞頻及密度。一般認(rèn)為在沒有關(guān)鍵詞堆積的情況下,搜索詞在頁面中出現(xiàn)的次數(shù)多,密度越高,說明頁面與搜索詞越相關(guān)。當(dāng)然這只是一個大致規(guī)律,實(shí)際情況未必如此,所以相關(guān)性計算還有其他因素。出現(xiàn)頻率及密度只是因素的一部分,而且重要程度越來越低。
3.關(guān)鍵詞位置及形式。就像在索引部分中提到的,頁面關(guān)鍵詞出現(xiàn)的格式和位置都被記錄在索引庫中。關(guān)鍵詞出現(xiàn)在比較重要的位置,如標(biāo)題標(biāo)簽、黑體、H1等,說明頁面與關(guān)鍵詞越相關(guān)。這一部分就是頁面SEO所要解決的。
4.關(guān)鍵詞距離。切分后的關(guān)鍵詞完整匹配地出現(xiàn),說明與搜索詞最相關(guān)。比如搜索“減肥方法”時,頁面上連續(xù)完整出現(xiàn)“減肥方法”四個字是最相關(guān)的。如果“減肥”和“方法”兩個詞沒有連續(xù)匹配出現(xiàn),出現(xiàn)的距離近一些,也被搜索引擎認(rèn)為相關(guān)性稍微大一些。
5.鏈接分析及頁面權(quán)重。除了頁面本身的因素,頁面之間的鏈接和權(quán)重關(guān)系也影響關(guān)鍵詞的相關(guān)性,其中最重要的是錨文字。頁面有越多以搜索詞為錨文字的導(dǎo)入鏈接,說明頁面的相關(guān)性越強(qiáng)。
鏈接分析還包括了鏈接源頁面本身的主題、錨文字周圍的文字等。
The End
歡迎自薦投稿到《前端技術(shù)江湖》,如果你覺得這篇內(nèi)容對你挺有啟發(fā),記得點(diǎn)個 「在看」哦
點(diǎn)個『在看』支持下 