
深入Linux內(nèi)核IO技術(shù)棧


這是《Linux系統(tǒng)調(diào)用那些事》高級部分的第一章《聊聊Linux IO》。高級部分的文章均假設(shè)讀者完整的學(xué)習(xí)過Linux系統(tǒng)基礎(chǔ)以及Linux系統(tǒng)編程相關(guān)的內(nèi)容,并已有一定的工程實踐經(jīng)驗。受限于個人水平和眼界限制,文章內(nèi)容若您有不同的見解,希望我們可以一起討論交流。
《Linux系統(tǒng)調(diào)用那些事》系列所有文章均以 署名-非商業(yè)性使用-禁止演繹 3.0 協(xié)議發(fā)布,在不違反發(fā)布協(xié)議的前提下允許自由分發(fā),無需知會作者。
寫在前面
在開始正式的討論前,我先拋出幾個問題:
談到磁盤時,常說的HDD磁盤和SSD磁盤最大的區(qū)別是什么?這些差異會影響我們的系統(tǒng)設(shè)計嗎?
單線程寫文件有點慢,那多開幾個線程一起寫是不是可以加速呢?
write函數(shù)成功返回了,數(shù)據(jù)就已經(jīng)成功寫入磁盤了嗎?此時設(shè)備斷電會有影響嗎?會丟失數(shù)據(jù)嗎?write調(diào)用是原子的嗎?多線程寫文件是否要對文件加鎖?有沒有例外,比如append方式?坊間傳聞,
mmap的方式讀文件比傳統(tǒng)的方式要快,因為少一次拷貝。真是這樣嗎?為什么少一次拷貝?
如果你覺得這些問題都很簡單,都能很明確的回答上來。那么很遺憾這篇文章不是為你準(zhǔn)備的,你可以關(guān)掉網(wǎng)頁去做其他更有意義的事情了。如果你覺得無法明確的回答這些問題,那么就耐心地讀完這篇文章,相信不會浪費你的時間。受限于個人時間和文章篇幅,部分議題如果我不能給出更好的解釋或者已有專業(yè)和嚴(yán)謹(jǐn)?shù)馁Y料,就只會給出相關(guān)的參考文獻(xiàn)的鏈接,請讀者自行參閱。
言歸正傳,我們的討論從存儲器的層次結(jié)構(gòu)開始。
存儲器的金字塔結(jié)構(gòu)
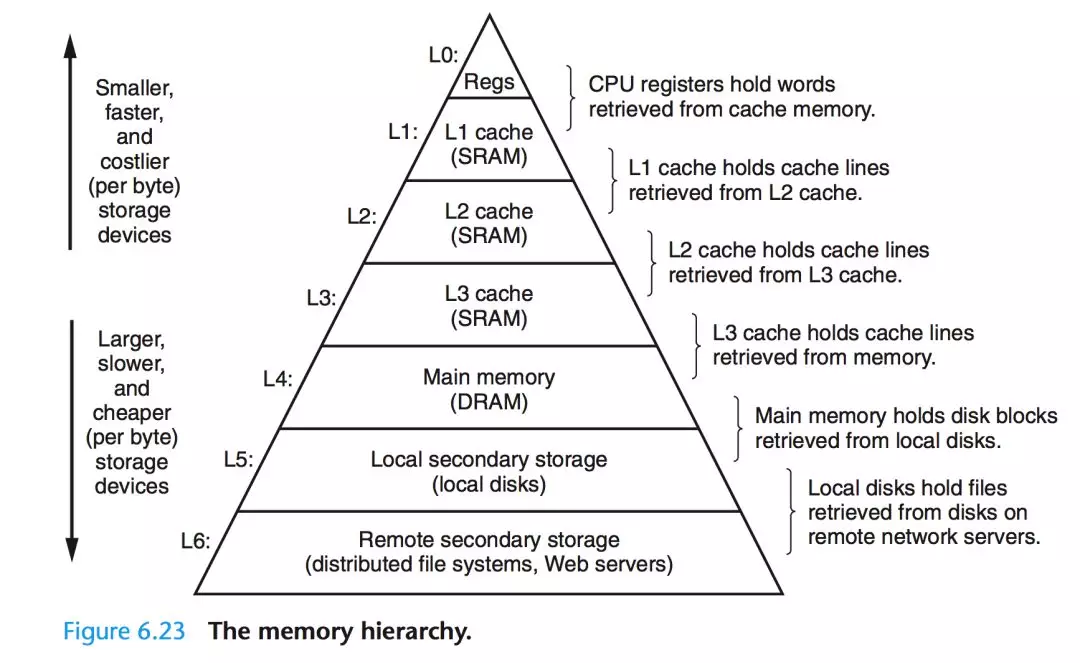
受限于存儲介質(zhì)的存取速率和成本,現(xiàn)代計算機的存儲結(jié)構(gòu)呈現(xiàn)為金字塔型[1]。越往塔頂,存取效率越高、但成本也越高,所以容量也就越小。得益于程序訪問的局部性原理[2],這種節(jié)省成本的做法也能取得不俗的運行效率。從存儲器的層次結(jié)構(gòu)以及計算機對數(shù)據(jù)的處理方式來看,上層一般作為下層的Cache層來使用(廣義上的Cache)。比如寄存器緩存CPU Cache的數(shù)據(jù),CPU Cache L1~L3層視具體實現(xiàn)彼此緩存或直接緩存內(nèi)存的數(shù)據(jù),而內(nèi)存往往緩存來自本地磁盤的數(shù)據(jù)。
本文主要討論磁盤IO操作,故只聚焦于Local Disk的訪問特性和其與DRAM之間的數(shù)據(jù)交互。
無處不在的緩存

如圖,當(dāng)程序調(diào)用各類文件操作函數(shù)后,用戶數(shù)據(jù)(User Data)到達(dá)磁盤(Disk)的流程如圖所示[3]。圖中描述了Linux下文件操作函數(shù)的層級關(guān)系和內(nèi)存緩存層的存在位置。中間的黑色實線是用戶態(tài)和內(nèi)核態(tài)的分界線。
從上往下分析這張圖,首先是C語言stdio庫定義的相關(guān)文件操作函數(shù),這些都是用戶態(tài)實現(xiàn)的跨平臺封裝函數(shù)。stdio中實現(xiàn)的文件操作函數(shù)有自己的stdio buffer,這是在用戶態(tài)實現(xiàn)的緩存。此處使用緩存的原因很簡單——系統(tǒng)調(diào)用總是昂貴的。如果用戶代碼以較小的size不斷的讀或?qū)懳募脑挘?code style="box-sizing: border-box;">stdio庫將多次的讀或者寫操作通過buffer進(jìn)行聚合是可以提高程序運行效率的。stdio庫同時也支持fflush函數(shù)來主動的刷新buffer,主動的調(diào)用底層的系統(tǒng)調(diào)用立即更新buffer里的數(shù)據(jù)。特別地,setbuf函數(shù)可以對stdio庫的用戶態(tài)buffer進(jìn)行設(shè)置,甚至取消buffer的使用。
系統(tǒng)調(diào)用的read/write和真實的磁盤讀寫之間也存在一層buffer,這里用術(shù)語Kernel buffer cache來指代這一層緩存。在Linux下,文件的緩存習(xí)慣性的稱之為Page Cache,而更低一級的設(shè)備的緩存稱之為Buffer Cache. 這兩個概念很容易混淆,這里簡單的介紹下概念上的區(qū)別:Page Cache用于緩存文件的內(nèi)容,和文件系統(tǒng)比較相關(guān)。文件的內(nèi)容需要映射到實際的物理磁盤,這種映射關(guān)系由文件系統(tǒng)來完成;Buffer Cache用于緩存存儲設(shè)備塊(比如磁盤扇區(qū))的數(shù)據(jù),而不關(guān)心是否有文件系統(tǒng)的存在(文件系統(tǒng)的元數(shù)據(jù)緩存在Buffer Cache中)。
綜上,既然討論Linux下的IO操作,自然是跳過stdio庫的用戶態(tài)這一堆東西,直接討論系統(tǒng)調(diào)用層面的概念了。對stdio庫的IO層有興趣的同學(xué)可以自行去了解。從上文的描述中也介紹了文件的內(nèi)核級緩存是保存在文件系統(tǒng)的Page Cache中的。所以后面的討論基本上是討論IO相關(guān)的系統(tǒng)調(diào)用和文件系統(tǒng)Page Cache的一些機制。
Linux內(nèi)核中的IO棧
這一小節(jié)來看Linux內(nèi)核的IO棧的結(jié)構(gòu)。先上一張全貌圖[4]:
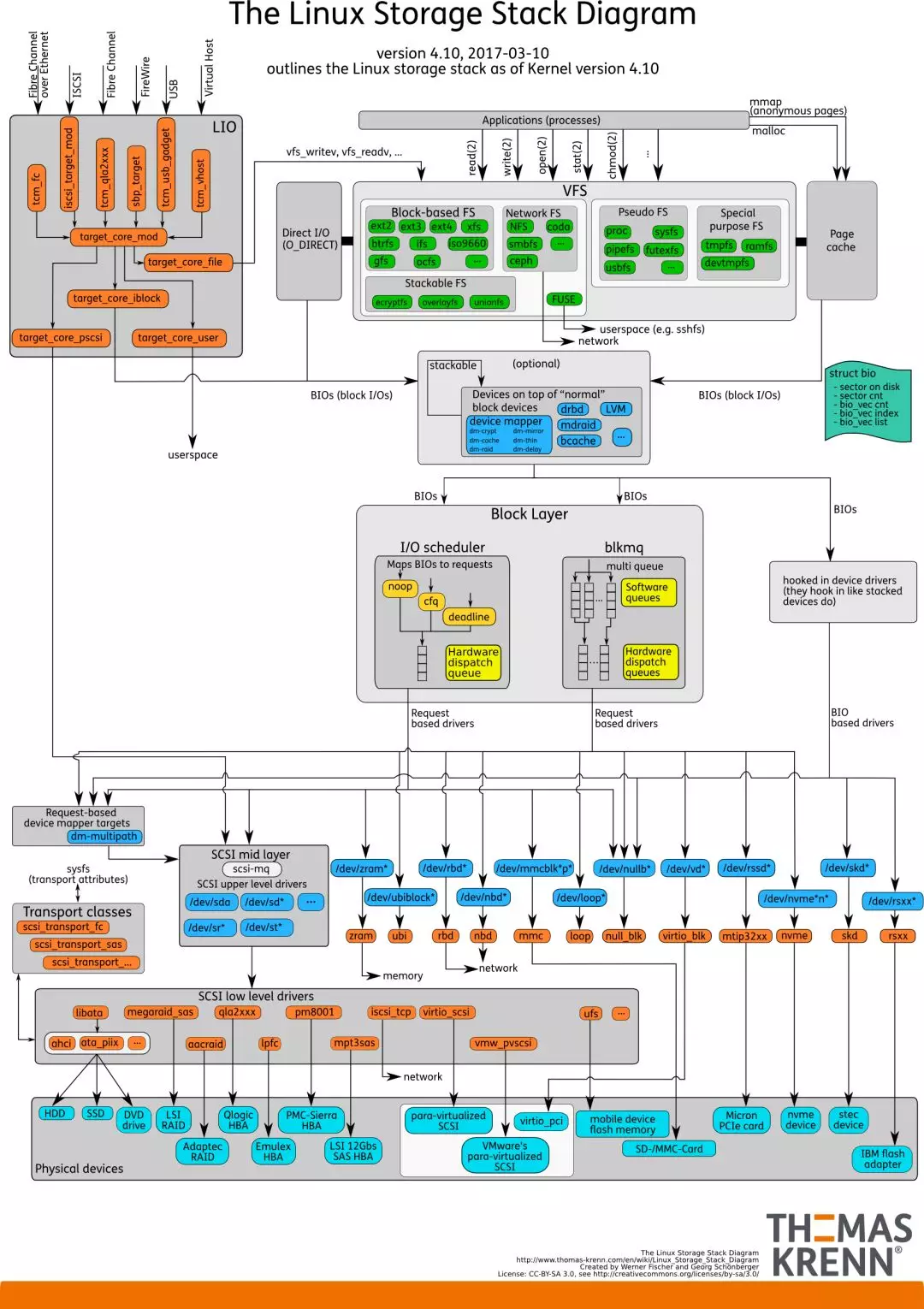
由圖可見,從系統(tǒng)調(diào)用的接口再往下,Linux下的IO棧致大致有三個層次:
文件系統(tǒng)層,以 write 為例,內(nèi)核拷貝了write參數(shù)指定的用戶態(tài)數(shù)據(jù)到文件系統(tǒng)Cache中,并適時向下層同步
塊層,管理塊設(shè)備的IO隊列,對IO請求進(jìn)行合并、排序(還記得操作系統(tǒng)課程學(xué)習(xí)過的IO調(diào)度算法嗎?)
設(shè)備層,通過DMA與內(nèi)存直接交互,完成數(shù)據(jù)和具體設(shè)備之間的交互
結(jié)合這個圖,想想Linux系統(tǒng)編程里用到的Buffered IO、mmap、Direct IO,這些機制怎么和Linux IO棧聯(lián)系起來呢?上面的圖有點復(fù)雜,我畫一幅簡圖,把這些機制所在的位置添加進(jìn)去:

這下一目了然了吧?傳統(tǒng)的Buffered IO使用read讀取文件的過程什么樣的?假設(shè)要去讀一個冷文件(Cache中不存在),open打開文件內(nèi)核后建立了一系列的數(shù)據(jù)結(jié)構(gòu),接下來調(diào)用read,到達(dá)文件系統(tǒng)這一層,發(fā)現(xiàn)Page Cache中不存在該位置的磁盤映射,然后創(chuàng)建相應(yīng)的Page Cache并和相關(guān)的扇區(qū)關(guān)聯(lián)。然后請求繼續(xù)到達(dá)塊設(shè)備層,在IO隊列里排隊,接受一系列的調(diào)度后到達(dá)設(shè)備驅(qū)動層,此時一般使用DMA方式讀取相應(yīng)的磁盤扇區(qū)到Cache中,然后read拷貝數(shù)據(jù)到用戶提供的用戶態(tài)buffer中去(read的參數(shù)指出的)。
整個過程有幾次拷貝?從磁盤到Page Cache算第一次的話,從Page Cache到用戶態(tài)buffer就是第二次了。而mmap做了什么?mmap直接把Page Cache映射到了用戶態(tài)的地址空間里了,所以mmap的方式讀文件是沒有第二次拷貝過程的。那Direct IO做了什么?這個機制更狠,直接讓用戶態(tài)和塊IO層對接,直接放棄Page Cache,從磁盤直接和用戶態(tài)拷貝數(shù)據(jù)。好處是什么?寫操作直接映射進(jìn)程的buffer到磁盤扇區(qū),以DMA的方式傳輸數(shù)據(jù),減少了原本需要到Page Cache層的一次拷貝,提升了寫的效率。對于讀而言,第一次肯定也是快于傳統(tǒng)的方式的,但是之后的讀就不如傳統(tǒng)方式了(當(dāng)然也可以在用戶態(tài)自己做Cache,有些商用數(shù)據(jù)庫就是這么做的)。
除了傳統(tǒng)的Buffered IO可以比較自由的用偏移+長度的方式讀寫文件之外,mmap和Direct IO均有數(shù)據(jù)按頁對齊的要求,Direct IO還限制讀寫必須是底層存儲設(shè)備塊大小的整數(shù)倍(甚至Linux 2.4還要求是文件系統(tǒng)邏輯塊的整數(shù)倍)。所以接口越來越底層,換來表面上的效率提升的背后,需要在應(yīng)用程序這一層做更多的事情。所以想用好這些高級特性,除了深刻理解其背后的機制之外,也要在系統(tǒng)設(shè)計上下一番功夫。
Page Cache 的同步
廣義上Cache的同步方式有兩種,即Write Through(寫穿)和Write back(寫回). 從名字上就能看出這兩種方式都是從寫操作的不同處理方式引出的概念(純讀的話就不存在Cache一致性了,不是么)。對應(yīng)到Linux的Page Cache上所謂Write Through就是指write操作將數(shù)據(jù)拷貝到Page Cache后立即和下層進(jìn)行同步的寫操作,完成下層的更新后才返回。而Write back正好相反,指的是寫完Page Cache就可以返回了。Page Cache到下層的更新操作是異步進(jìn)行的。
Linux下Buffered IO默認(rèn)使用的是Write back機制,即文件操作的寫只寫到Page Cache就返回,之后Page Cache到磁盤的更新操作是異步進(jìn)行的。Page Cache中被修改的內(nèi)存頁稱之為臟頁(Dirty Page),臟頁在特定的時候被一個叫做pdflush(Page Dirty Flush)的內(nèi)核線程寫入磁盤,寫入的時機和條件如下:
當(dāng)空閑內(nèi)存低于一個特定的閾值時,內(nèi)核必須將臟頁寫回磁盤,以便釋放內(nèi)存。
當(dāng)臟頁在內(nèi)存中駐留時間超過一個特定的閾值時,內(nèi)核必須將超時的臟頁寫回磁盤。
用戶進(jìn)程調(diào)用
sync、fsync、fdatasync系統(tǒng)調(diào)用時,內(nèi)核會執(zhí)行相應(yīng)的寫回操作。
刷新策略由以下幾個參數(shù)決定(數(shù)值單位均為1/100秒):

默認(rèn)是寫回方式,如果想指定某個文件是寫穿方式呢?即寫操作的可靠性壓倒效率的時候,能否做到呢?當(dāng)然能,除了之前提到的fsync之類的系統(tǒng)調(diào)用外,在open打開文件時,傳入O_SYNC這個flag即可實現(xiàn)。這里給篇參考文章[5],不再贅述(更好的選擇是去讀TLPI相關(guān)章節(jié))。
文件讀寫遭遇斷電時,數(shù)據(jù)還安全嗎?相信你有自己的答案了。使用O_SYNC或者fsync刷新文件就能保證安全嗎?現(xiàn)代磁盤一般都內(nèi)置了緩存,代碼層面上也只能講數(shù)據(jù)刷新到磁盤的緩存了。當(dāng)數(shù)據(jù)已經(jīng)進(jìn)入到磁盤的高速緩存時斷電了會怎么樣?這個恐怕不能一概而論了。不過可以使用hdparm -W0命令關(guān)掉這個緩存,相應(yīng)的,磁盤性能必然會降低。
文件操作與鎖
當(dāng)多個進(jìn)程/線程對同一個文件發(fā)生寫操作的時候會發(fā)生什么?如果寫的是文件的同一個位置呢?這個問題討論起來有點復(fù)雜了。首先write調(diào)用不是原子操作,不要被TLPI的中文版5.2章節(jié)的第一句話誤導(dǎo)了(英文版也是有歧義的,作者在http://www.man7.org/tlpi/errata/index.html給出了勘誤信息)。當(dāng)多個write操作對一個文件的同一部分發(fā)起寫操作的時候,情況實際上和多個線程訪問共享的變量沒有什么區(qū)別。按照不同的邏輯執(zhí)行流,會有很多種可能的結(jié)果。也許大多數(shù)情況下符合預(yù)期,但是本質(zhì)上這樣的代碼是不可靠的。
特別的,文件操作中有兩個操作是內(nèi)核保證原子的。分別是open調(diào)用的O_CREAT和O_APPEND這兩個flag屬性。前者是文件不存在就創(chuàng)建,后者是每次寫文件時把文件游標(biāo)移動到文件最后追加寫(NFS等文件系統(tǒng)不保證這個flag)。有意思的問題來了,以O_APPEND方式打開的文件write操作是不是原子的?文件游標(biāo)的移動和調(diào)用寫操作是原子的,那寫操作本身會不會發(fā)生改變呢?有的開源軟件比如apache寫日志就是這樣寫的,這是可靠安全的嗎?坦白講我也不清楚,有人說Then O_APPEND is atomic and write-in-full for all reasonably-sized> writes to regular files.但是我也沒有找到很權(quán)威的說法。這里給出一個郵件列表上的討論,可以參考下[6]。今天先放過去,后面有時間的話專門研究下這個問題。如果你能給出很明確的說法和證明,還望不吝賜教。
Linux下的文件鎖有兩種,分別是flock的方式和fcntl的方式,前者源于BSD,后者源于System V,各有限制和應(yīng)用場景。老規(guī)矩,TLPI上講的很清楚的這里不贅述。我個人是沒有用過文件鎖的,系統(tǒng)設(shè)計的時候一般會避免多個執(zhí)行流寫一個文件的情況,或者在代碼邏輯上以mutex加鎖,而不是直接加鎖文件本身。數(shù)據(jù)庫場景下這樣的操作可能會多一些(這個純屬臆測),這就不是我了解的范疇了。
磁盤的性能測試
在具體的機器上跑服務(wù)程序,如果涉及大量IO的話,首先要對機器本身的磁盤性能有明確的了解,包括不限于IOPS、IO Depth等等。這些數(shù)據(jù)不僅能指導(dǎo)系統(tǒng)設(shè)計,也能幫助資源規(guī)劃以及定位系統(tǒng)瓶頸。比如我們知道機械磁盤的連續(xù)讀寫性能一般不會超過120M/s,而普通的SSD磁盤隨意就能超過機械盤幾倍(商用SSD的連續(xù)讀寫速率達(dá)到2G+/s不是什么新鮮事)。另外由于磁盤的工作原理不同,機械磁盤需要旋轉(zhuǎn)來尋找數(shù)據(jù)存放的磁道,所以其隨機存取的效率受到了“尋道時間”的嚴(yán)重影響,遠(yuǎn)遠(yuǎn)小于連續(xù)存取的效率;而SSD磁盤讀寫任意扇區(qū)可以認(rèn)為是相同的時間,隨機存取的性能遠(yuǎn)遠(yuǎn)超過機械盤。所以呢,在機械磁盤作為底層存儲時,如果一個線程寫文件很慢的話,多個線程分別去寫這個文件的各個部分能否加速呢?不見得吧?如果這個文件很大,各個部分的尋道時間帶來極大的時間消耗的話,效率就很低了(先不考慮Page Cache)。SSD呢?可以明確,設(shè)計合理的話,SSD多線程讀寫文件的效率會高于單線程。當(dāng)前的SSD盤很多都以高并發(fā)的讀取為賣點的,一個線程壓根就喂不飽一塊SSD盤。一般SSD的IO Depth都在32甚至更高,使用32或者64個線程才能跑滿一個SSD磁盤的帶寬(同步IO情況下)。
具體的SSD原理不在本文計劃內(nèi),這里給出一篇詳細(xì)的參考文章[7]。有時候一些文章中所謂的STAT磁盤一般說的就是機械盤(雖然STAT本身只是一個總線接口)。接口會影響存儲設(shè)備的最大速率,基本上是STAT -> PCI-E -> NVMe的發(fā)展路徑,具體請自行Google了解。
具體的設(shè)備一般使用fio工具[8]來測試相關(guān)磁盤的讀寫性能。fio的介紹和使用教程有很多[9],不再贅述。這里不想貼性能數(shù)據(jù)的原因是存儲介質(zhì)的發(fā)展實在太快了,一方面不想貼某些很快就過時的數(shù)據(jù)以免讓初學(xué)者留下不恰當(dāng)?shù)牡谝挥∠螅硪环矫嬉蚕Mx寫自己實踐下fio命令。
前文提到存儲介質(zhì)的原理會影響程序設(shè)計,我想稍微的解釋下。這里說的“影響”不是說具體的讀寫能到某個速率,程序中就依賴這個數(shù)值,換個工作環(huán)境就性能大幅度降低(當(dāng)然,為專門的機型做過優(yōu)化的結(jié)果很可能有這個副作用)。而是說根據(jù)存儲介質(zhì)的特性,程序的設(shè)計起碼要遵循某個設(shè)計套路。舉個簡單的例子,SATA機械盤的隨機存取很慢,那系統(tǒng)設(shè)計時,就要盡可能的避免隨機的IO出現(xiàn),盡可能的轉(zhuǎn)換成連續(xù)的文件存取來加速運行。比如Google的LevelDB就是轉(zhuǎn)換隨機的Key-Value寫入為Binlog(連續(xù)文件寫入)+ 內(nèi)存插入MemTable(內(nèi)存隨機讀寫可以認(rèn)為是O(1)的性能),之后批量dump到磁盤(連續(xù)文件寫入)。這種LSM-Tree的設(shè)計便是合理的利用了存儲介質(zhì)的特性,做到了最大化的性能利用(磁盤換成SSD也依舊能有很好的運行效率)。
寫在最后
每天抽出不到半個小時,零零散散地寫了一周,這是說是入門都有些謬贊了,只算是對Linux下的IO機制稍微深入的介紹了一點。無論如何,希望學(xué)習(xí)完Linux系統(tǒng)編程的同學(xué),能繼續(xù)的往下走一走,嘗試?yán)斫庀到y(tǒng)調(diào)用背后隱含的機制和原理。探索的結(jié)果無所謂,重要的是探索的過程以及相關(guān)的學(xué)習(xí)經(jīng)驗和方法。前文提出的幾個問題我并沒有刻意去解答所有的,但是讀到現(xiàn)在,不知道你自己能回答上幾個了?
參考文獻(xiàn)
[1] 圖片引自《Computer Systems: A Programmer's Perspective》Chapter 6 The Memory Hierarchy, 另可參考
https://zh.wikipedia.org/wiki/%E5%AD%98%E5%82%A8%E5%99%A8%E5%B1%B1
[2] Locality of reference,
https://en.wikipedia.org/wiki/Locality_of_reference
[3] 圖片引自《The Linux Programming Interface》Chapter 13 FILE I/O BUFFERING
[4] Linux Storage Stack Diagram,
https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
[5] O_DIRECT和O_SYNC詳解,
http://www.cnblogs.com/suzhou/p/5381738.html
[6] http://librelist.com/browser/usp.ruby/2013/6/5/o-append-atomicity/
[7] Coding for SSD,
https://dirtysalt.github.io/coding-for-ssd.html
[8] fio作者Jens Axboe是Linux內(nèi)核IO部分的maintainer,
工具主頁 http://freecode.com/projects/fio/
[9] How to benchmark disk I/O,
https://www.binarylane.com.au/support/solutions/articles/1000055889-how-to-benchmark-disk-i-o
[10] 深入Linux內(nèi)核架構(gòu), (德)莫爾勒, 人民郵電出版社

轉(zhuǎn)載申明:轉(zhuǎn)載本號文章請注明作者和來源,本號發(fā)布文章若存在版權(quán)等問題,請留言聯(lián)系處理,謝謝。
推薦閱讀
更多架構(gòu)相關(guān)技術(shù)知識總結(jié)請參考“架構(gòu)師全店鋪技術(shù)資料打包”相關(guān)電子書(37本技術(shù)資料打包匯總詳情可通過“閱讀原文”獲取)。
全店內(nèi)容持續(xù)更新,現(xiàn)下單“架構(gòu)師技術(shù)全店資料打包匯總(全)”,后續(xù)可享全店內(nèi)容更新“免費”贈閱,價格僅收198元(原總價350元)。
溫馨提示:
掃描二維碼關(guān)注公眾號,點擊小程序鏈接獲取“架構(gòu)師技術(shù)聯(lián)盟書店”電子書資料詳情。
