
YOLOv5 對決 Faster RCNN,誰贏誰輸?
重磅干貨,第一時間送達
撇開所有爭議不談,YOLOv5 看起來是一個“很有前途”的模型。因此,我將它與 Faster RCNN 進行了比較,F(xiàn)aster RCNN 是最好的 two stage 檢測器之一。為了進行比較,我選取了三段背景不同的視頻,并將這兩個模型并排運行。我的評估包括對結果質量和推理速度的觀察結果。那么,讓我們言歸正傳。
YOLOv5 的實現(xiàn)是在 PyTorch 中完成的,與之前基于 DarkNet 框架的開發(fā)形成了鮮明的對比。這使得該模型的理解、訓練和部署變得更加容易(目前暫時沒有使用 YOLO-v5 的論文發(fā)表)。以我的理解來看,在架構上,它和 YOLO-v4 很相似。一個不同之處可能是使用了 Cross Stage Partial Network(CSP)來降低計算成本。目前尚不清楚 YOLOv5 的運行速度是否比 YOLO-v4 更快,但我更喜歡 PyTorch 的實現(xiàn),而且讓驚訝的是,使用這個模型進行訓練是如此的容易。就我個人經驗而言,通過它進行推理的體驗也是如此。
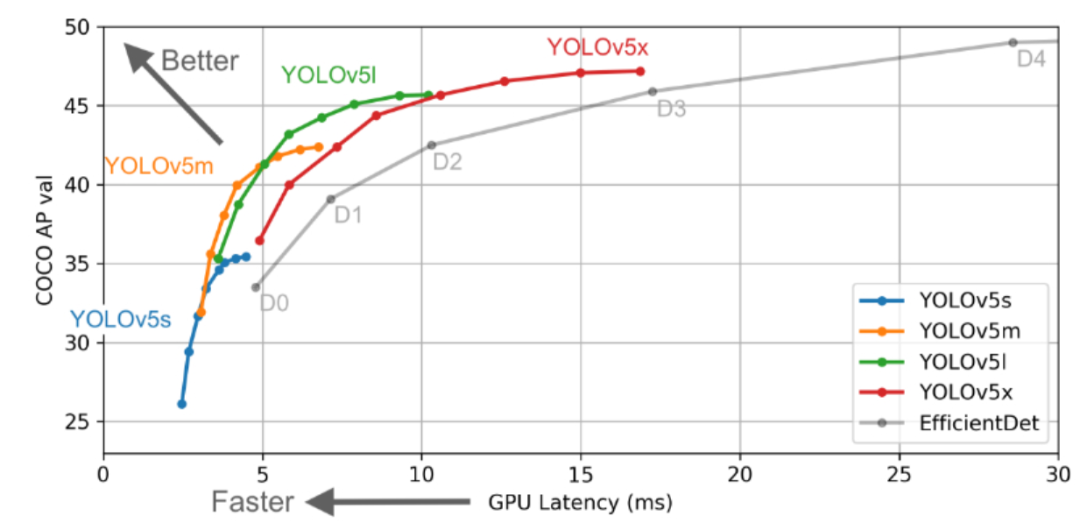
這次發(fā)布的 YOLOv5 包括五種不同尺寸的模型:YOLOv5s(最小)、YOLOv5m、YOLOv5l、YOLOv5x(最大)。這些模型的推理速度和平均精度均值(mean average precision,mAP)如下圖所示:
第一步就是克隆 YOLO-v5 的 repo,并安裝所有的依賴要求。我使用的是 PyTorch 1.5,代碼可以正常工作,沒有任何問題。
你可以按照以下方法下載不同預訓練 COCO 模型的所有權重:
bash weights/download_weights.sh
要對視頻進行推理,就必須將傳遞給視頻的路徑以及要使用的模型的權重。如果沒有設置權重參數(shù),那么在默認情況下,代碼在 YOLO 小模型上運行。我使用的示例參數(shù)如下所示。
python detect.py --source video/MOT20-01-raw-cut1.mp4 --output video_out/ --weights weights/yolov5s.pt --conf-thres 0.4
輸出視頻將保存在輸出文件夾中。
對于 Faster RCNN 模型,我使用了 TensorFlow Object Detection 中的預訓練模型。TensorFlow Object Detection 共享 COCO 預訓練的 Faster RCNN,用于各種主干。對于這個博客,我使用了 Faster RCNN ResNet 50 主干。這個 repo 分享了一個很不錯的教程,介紹如何使用他們的預訓練模型進行推理。
考慮到對自動駕駛行業(yè)的重要性,我選擇的第一個場景是街道駕駛場景。這兩個模型的結果分別如下:

YOLOv5 模型評估駕駛視頻

Faster RCNN 評估駕駛視頻
YOLO 模型似乎更善于檢測較小的目標,在這種情況下是紅綠燈,并且還能夠在當汽車距離較遠(即在透視上看起來較小)將其進行標記。
YOLOv5s 的運行速度(端到端包括讀取視頻、運行模型和將結果保存到文件)為 52.8 FPS。
而 Faser RCNN ResNet 50 的運行速度(端到端包括讀取視頻、運行模型和將結果保存到文件)為 21.7 FPS。
以上結果是在 NVIDIA 1080 Ti 上進行評估的。
到目前為止,YOLOv5 看上去比 Faster RCNN 更好一些。

YOLOv5 與 Faster RCNN 的比較(1)
下一段視頻是 YouTube 的籃球比賽視頻。兩個模型的結果如下所示:
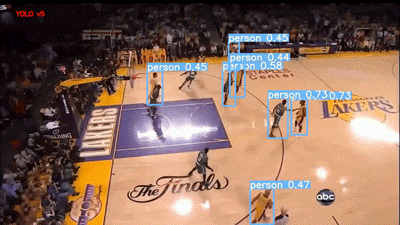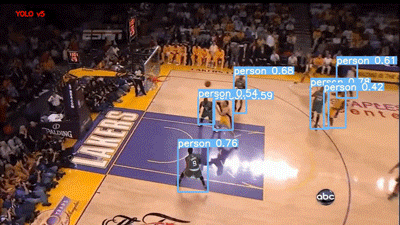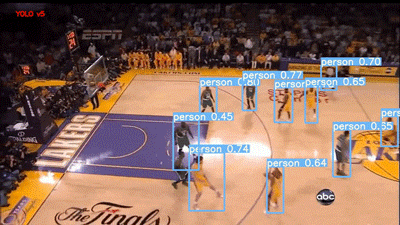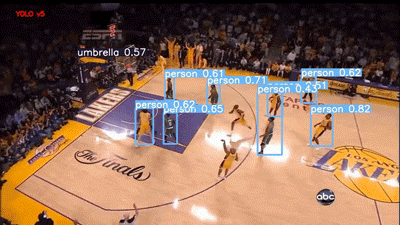
YOLOv5 評估籃球比賽視頻

Faster RCNN ResNet 50 評估籃球比賽視頻
Faster RCNN 模型在 60% 的閾值下運行,可以說它是用“Person”標簽對人群進行標記,但我個人更喜歡 YOLO,因為它的結果干凈整潔。不過,這兩種模型在視頻右下角的 abc(美國廣播公司)徽標上都存在假正類誤報。
我也很失望,雖然運動球也是 COCO 的類別之一,但這兩個模型都沒有檢測到籃球。它們現(xiàn)在的統(tǒng)計情況如下:
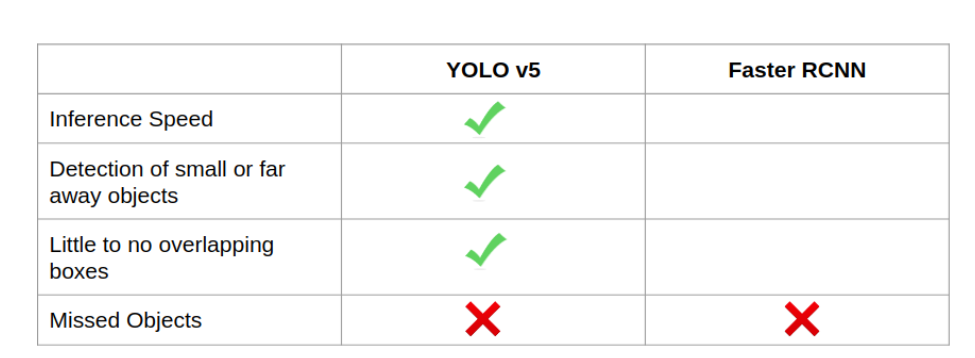
YOLOv5 與 Faster RCNN 的比較 (2)
在最后一段視頻中,我從 MOT 數(shù)據(jù)集中選擇了一個室內擁擠的場景。這是一段很有挑戰(zhàn)性的視頻,因為光線不足,距離遙遠,人群密集。這兩個模型的結果如下所示:

YOLOv5 模型在來自 MOT 數(shù)據(jù)集中的室內擁擠場景進行測試

Faster RCNN 模型在來自 MOT 數(shù)據(jù)集中的室內擁擠場景進行測試
這一次的測試很有趣。我想說的是,當人們走進走廊的時候,這兩種模型都很難檢測到遠處的人。這可能是由于光線較弱和目標較小所致。當人群靠近攝像機方向時,這兩種模型都能對重疊的人進行標記。
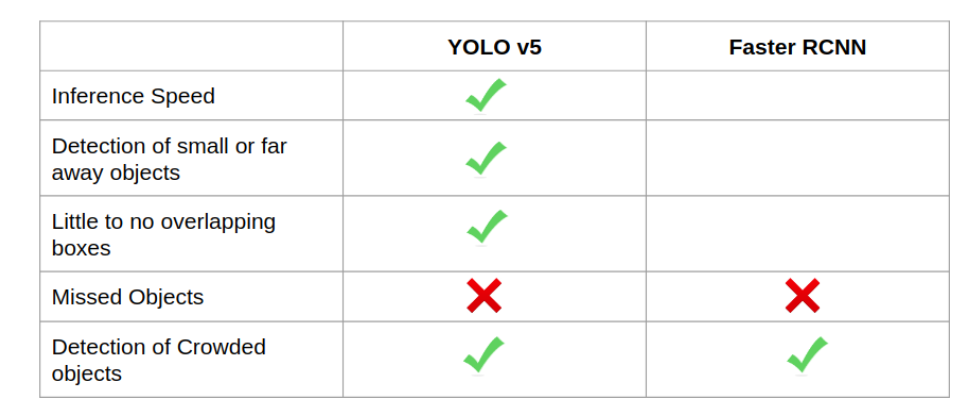
YOLOv5 與 Faster RCNN 的比較(3)
最后對比兩種模型可以看出,YOLOv5 在運行速度上有明顯優(yōu)勢。小型 YOLOv5 模型運行速度加快了約 2.5 倍,同時在檢測較小的目標時具有更好的性能。結果也更干凈,幾乎沒有重疊的邊框。Ultralytics 在他們的 YOLOv5 上做得非常出色,并開源了一個易于訓練和運行推理的模型。
該博文還顯示了計算機視覺目標檢測的一個新興趨勢,即朝既快又準確的模型發(fā)展。
原文鏈接:
https://towardsdatascience.com/yolov5-compared-to-faster-rcnn-who-wins-a771cd6c9fb4
轉自:AI前線
下載1:OpenCV黑魔法
在「AI算法與圖像處理」公眾號后臺回復:OpenCV黑魔法,即可下載小編精心編寫整理的計算機視覺趣味實戰(zhàn)教程
下載2 CVPR2020
在「AI算法與圖像處理」公眾號后臺回復:CVPR2020,即可下載1467篇CVPR 2020論文 個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學校/企業(yè)+研究方向+昵稱

覺得有趣就點亮在看吧
