
最強的Python 辦公自動化之 PDF 攻略來了(全)

辦公自動化應該算是打工人上班摸魚的極致追求了,況且對于 Python 愛好者來說,辦公自動化簡直是太簡單了
比如,今天的辦公自動化主題:Python 操作 PDF
關于 Python 與 PDF 的操作,前面也有提到幾篇,文末也會 列出相關幾篇文章,感興趣的可以都學習一下
今天的具體內容將會從以下幾個小節(jié)展開:
相關介紹 批量拆分 批量合并 提取文字內容 提起表格內容 提起圖片內容 轉換為PDF圖片 添加水印 加密與解碼
上述操作比較常用,也可以解決較多的辦公內容,下面直接開始本節(jié)內容:
1. 相關介紹
Python 操作 PDF 會用到兩個庫,分別是:PyPDF2 和 pdfplumber
其中 PyPDF2 可以更好的讀取、寫入、分割、合并PDF文件,而 pdfplumber 可以更好的讀取 PDF 文件中內容和提取 PDF 中的表格
對應的官網(wǎng)分別是:
PyPDF2:https://pythonhosted.org/PyPDF2/ pdfplumber:https://github.com/jsvine/pdfplumber
由于這兩個庫都不是 Python 的標準庫,所以在使用之前都需要單獨安裝
win+r 后輸入 cmd 打開 command 窗口,依次輸入如下命令進行安裝:
pip install PyPDF2 pip install pdfplumber
安裝完成后顯示 success 則表示安裝成功
2. 批量拆分
將一個完整的 PDF 拆分成幾個小的 PDF,因為主要涉及到 PDF 整體的操作,所以本小節(jié)需要用到 PyPDF2 這個庫
拆分的大概思路如下:
讀取 PDF 的整體信息、總頁數(shù)等 遍歷每一頁內容,以每個 step 為間隔將 PDF 存成每一個小的文件塊 將小的文件塊重新保存為新的 PDF 文件
需要注意的是,在拆分的過程中,可以手動設置間隔,例如:每5頁保存成一個小的 PDF 文件
拆分的代碼如下:
import os
from PyPDF2 import PdfFileWriter, PdfFileReader
def split_pdf(filename, filepath, save_dirpath, step=5):
"""
拆分PDF為多個小的PDF文件,
@param filename:文件名
@param filepath:文件路徑
@param save_dirpath:保存小的PDF的文件路徑
@param step: 每step間隔的頁面生成一個文件,例如step=5,表示0-4頁、5-9頁...為一個文件
@return:
"""
if not os.path.exists(save_dirpath):
os.mkdir(save_dirpath)
pdf_reader = PdfFileReader(filepath)
# 讀取每一頁的數(shù)據(jù)
pages = pdf_reader.getNumPages()
for page in range(0, pages, step):
pdf_writer = PdfFileWriter()
# 拆分pdf,每 step 頁的拆分為一個文件
for index in range(page, page+step):
if index < pages:
pdf_writer.addPage(pdf_reader.getPage(index))
# 保存拆分后的小文件
save_path = os.path.join(save_dirpath, filename+str(int(page/step)+1)+'.pdf')
print(save_path)
with open(save_path, "wb") as out:
pdf_writer.write(out)
print("文件已成功拆分,保存路徑為:"+save_dirpath)
split_pdf(filename, filepath, save_dirpath, step=5)
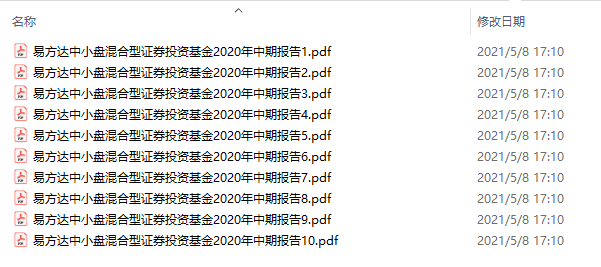
以“易方達中小盤混合型證券投資基金2020年中期報告”為例,整個 PDF 文件一共 46 頁,每5頁為間隔,最終生成了10個小的 PDF 文件
3. 批量合并
比起拆分來,合并的思路更加簡單:
確定要合并的 文件順序 循環(huán)追加到一個文件塊中 保存成一個新的文件
對應的代碼比較簡單:
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
def concat_pdf(filename, read_dirpath, save_filepath):
"""
合并多個PDF文件
@param filename:文件名
@param read_dirpath:要合并的PDF目錄
@param save_filepath:合并后的PDF文件路徑
@return:
"""
pdf_writer = PdfFileWriter()
# 對文件名進行排序
list_filename = os.listdir(read_dirpath)
list_filename.sort(key=lambda x: int(x[:-4].replace(filename, "")))
for filename in list_filename:
print(filename)
filepath = os.path.join(read_dirpath, filename)
# 讀取文件并獲取文件的頁數(shù)
pdf_reader = PdfFileReader(filepath)
pages = pdf_reader.getNumPages()
# 逐頁添加
for page in range(pages):
pdf_writer.addPage(pdf_reader.getPage(page))
# 保存合并后的文件
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
print("文件已成功合并,保存路徑為:"+save_filepath)
concat_pdf(filename, read_dirpath, save_filepath)4. 提取文字內容
涉及到具體的 PDF 內容 操作,本小節(jié)需要用到 pdfplumber 這個庫
在進行文字提取的時候,主要用到 extract_text 這個函數(shù)
具體代碼如下:
import os
import pdfplumber
def extract_text_info(filepath):
"""
提取PDF中的文字
@param filepath:文件路徑
@return:
"""
with pdfplumber.open(filepath) as pdf:
# 獲取第2頁數(shù)據(jù)
page = pdf.pages[1]
print(page.extract_text())
# 提取文字內容
extract_text_info(filepath)
可以看到,直接通過下標即可定位到相應的頁碼,從而通過 extract_text 函數(shù)提取該也的所有文字
而如果想要提取所有頁的文字,只需要改成:
with pdfplumber.open(filepath) as pdf:
# 獲取全部數(shù)據(jù)
for page in pdf.pages
print(page.extract_text())
例如,提取“易方達中小盤混合型證券投資基金2020年中期報告” 第一頁的內容時,源文件是這樣的:

運行代碼后提取出來是這樣的:

5. 提取表格內容
同樣的,本節(jié)是對具體內容的操作,所以也需要用到 pdfplumber 這個庫
和提取文字十分類似的是,提取表格內容只是將 extract_text 函數(shù)換成了 extract_table 函數(shù)
對應的代碼如下:
import os
import pandas as pd
import pdfplumber
def extract_table_info(filepath):
"""
提取PDF中的圖表數(shù)據(jù)
@param filepath:
@return:
"""
with pdfplumber.open(filepath) as pdf:
# 獲取第18頁數(shù)據(jù)
page = pdf.pages[17]
# 如果一頁有一個表格,設置表格的第一行為表頭,其余為數(shù)據(jù)
table_info = page.extract_table()
df_table = pd.DataFrame(table_info[1:], columns=table_info[0])
df_table.to_csv('dmeo.csv', index=False, encoding='gbk')
# 提取表格內容
extract_table_info(filepath)
上面代碼可以獲取到第 18 頁的第一個表格內容,并且將其保存為 csv 文件存在本地
但是,如果說第 18 頁有多個表格內容呢?
因為讀取的表格會被存成二維數(shù)組,而多個二維數(shù)組就組成一個三維數(shù)組
遍歷這個三位數(shù)組,就可以得到該頁的每一個表格數(shù)據(jù),對應的將 extract_table 函數(shù) 改成 extract_tables 即可
具體代碼如下:
# 如果一頁有多個表格,對應的數(shù)據(jù)是一個三維數(shù)組
tables_info = page.extract_tables()
for index in range(len(tables_info)):
# 設置表格的第一行為表頭,其余為數(shù)據(jù)
df_table = pd.DataFrame(tables_info[index][1:], columns=tables_info[index][0])
print(df_table)
# df_table.to_csv('dmeo.csv', index=False, encoding='gbk')
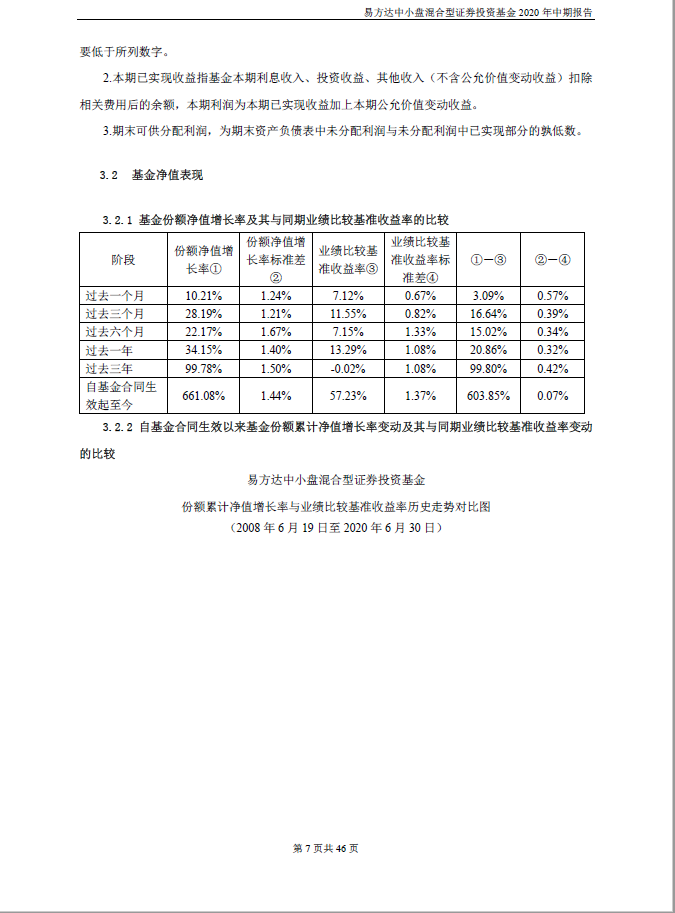
以“易方達中小盤混合型證券投資基金2020年中期報告” 第 xx 頁的第一個表格為例:
源文件中的表格是這樣的:
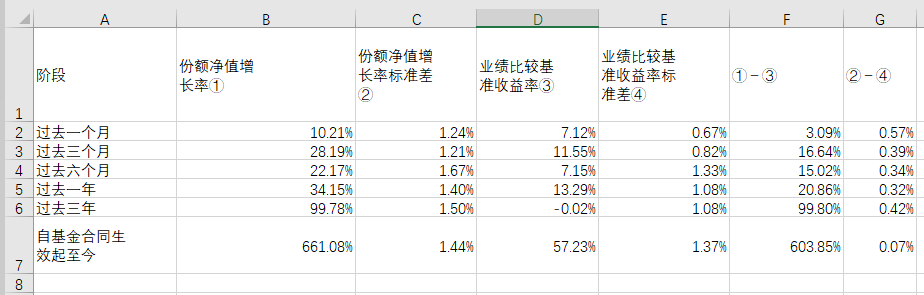
提取并存入 excel 之后的表格是這樣的:
6. 提取圖片內容
提取 PDF 中的圖片和將 PDF 轉存為圖片是不一樣的(下一小節(jié)),需要區(qū)分開。
提取圖片:顧名思義,就是將內容中的圖片都提取出來;
轉存為圖片:則是將每一頁的 PDF 內容存成一頁一頁的圖片,下一小節(jié)會詳細說明
轉存為圖片中,需要用到一個模塊叫 fitz,fitz 的最新版 1.18.13,非最新版的在部分函數(shù)名稱上存在差異,代碼中會標記出來
使用 fitz 需要先安裝 PyMuPDF 模塊,安裝方式如下:
pip install PyMuPDF
提取圖片的整體邏輯如下:
使用 fitz 打開文檔,獲取文檔詳細數(shù)據(jù) 遍歷每一個元素,通過正則找到圖片的索引位置 使用 Pixmap 將索引對應的元素生成圖片 通過 size 函數(shù)過濾較小的圖片
實現(xiàn)的具體代碼如下:
import os
import re
import fitz
def extract_pic_info(filepath, pic_dirpath):
"""
提取PDF中的圖片
@param filepath:pdf文件路徑
@param pic_dirpath:要保存的圖片目錄路徑
@return:
"""
if not os.path.exists(pic_dirpath):
os.makedirs(pic_dirpath)
# 使用正則表達式來查找圖片
check_XObject = r"/Type(?= */XObject)"
check_Image = r"/Subtype(?= */Image)"
img_count = 0
"""1. 打開pdf,打印相關信息"""
pdf_info = fitz.open(filepath)
# 1.16.8版本用法 xref_len = doc._getXrefLength()
# 最新版本
xref_len = pdf_info.xref_length()
# 打印PDF的信息
print("文件名:{}, 頁數(shù): {}, 對象: {}".format(filepath, len(pdf_info), xref_len-1))
"""2. 遍歷PDF中的對象,遇到是圖像才進行下一步,不然就continue"""
for index in range(1, xref_len):
# 1.16.8版本用法 text = doc._getXrefString(index)
# 最新版本
text = pdf_info.xref_object(index)
is_XObject = re.search(check_XObject, text)
is_Image = re.search(check_Image, text)
# 如果不是對象也不是圖片,則不操作
if is_XObject or is_Image:
img_count += 1
# 根據(jù)索引生成圖像
pix = fitz.Pixmap(pdf_info, index)
pic_filepath = os.path.join(pic_dirpath, 'img_' + str(img_count) + '.png')
"""pix.size 可以反映像素多少,簡單的色素塊該值較低,可以通過設置一個閾值過濾。以閾值 10000 為例過濾"""
# if pix.size < 10000:
# continue
"""三、 將圖像存為png格式"""
if pix.n >= 5:
# 先轉換CMYK
pix = fitz.Pixmap(fitz.csRGB, pix)
# 存為PNG
pix.writePNG(pic_filepath)
# 提取圖片內容
extract_pic_info(filepath, pic_dirpath)
以本節(jié)示例的“易方達中小盤混合型證券投資基金2020年中期報告” 中的圖片為例,代碼運行后提取的圖片如下:

這個結果和文檔中的共 1 張圖片的 結果符合
7. 轉換為圖片
轉換為照片比較簡單,就是將一頁頁的 PDF 轉換為一張張的圖片。大致過程如下:
安裝 pdf2image
首先需要安裝對應的庫,最新的 pdf2image 庫版本應該是 1.14.0
它的 github地址 為:https://github.com/Belval/pdf2image ,感興趣的可以自行了解
安裝方式如下:
pip install pdf2image
安裝組件
對于不同的平臺,需要安裝相應的組件,這里以 windows 平臺和 mac 平臺為例:
Windows 平臺
對于 windows 用戶需要安裝 poppler for Windows,安裝鏈接是:http://blog.alivate.com.au/poppler-windows/
另外,還需要添加環(huán)境變量, 將 bin 文件夾的路徑添加到環(huán)境變量 PATH 中
注意這里配置之后需要重啟一下電腦才會生效,不然會報錯
Mac
對于 mac 用戶,需要安裝 poppler for Mac,具體可以參考這個鏈接:http://macappstore.org/poppler/
詳細代碼如下:
import os
from pdf2image import convert_from_path, convert_from_bytes
def convert_to_pic(filepath, pic_dirpath):
"""
每一頁的PDF轉換成圖片
@param filepath:pdf文件路徑
@param pic_dirpath:圖片目錄路徑
@return:
"""
print(filepath)
if not os.path.exists(pic_dirpath):
os.makedirs(pic_dirpath)
images = convert_from_bytes(open(filepath, 'rb').read())
# images = convert_from_path(filepath, dpi=200)
for image in images:
# 保存圖片
pic_filepath = os.path.join(pic_dirpath, 'img_'+str(images.index(image))+'.png')
image.save(pic_filepath, 'PNG')
# PDF轉換為圖片
convert_to_pic(filepath, pic_dirpath)
以本節(jié)示例的“易方達中小盤混合型證券投資基金2020年中期報告” 中的圖片為例,該文檔共 46 頁,保存后的 PDF 照片如下:
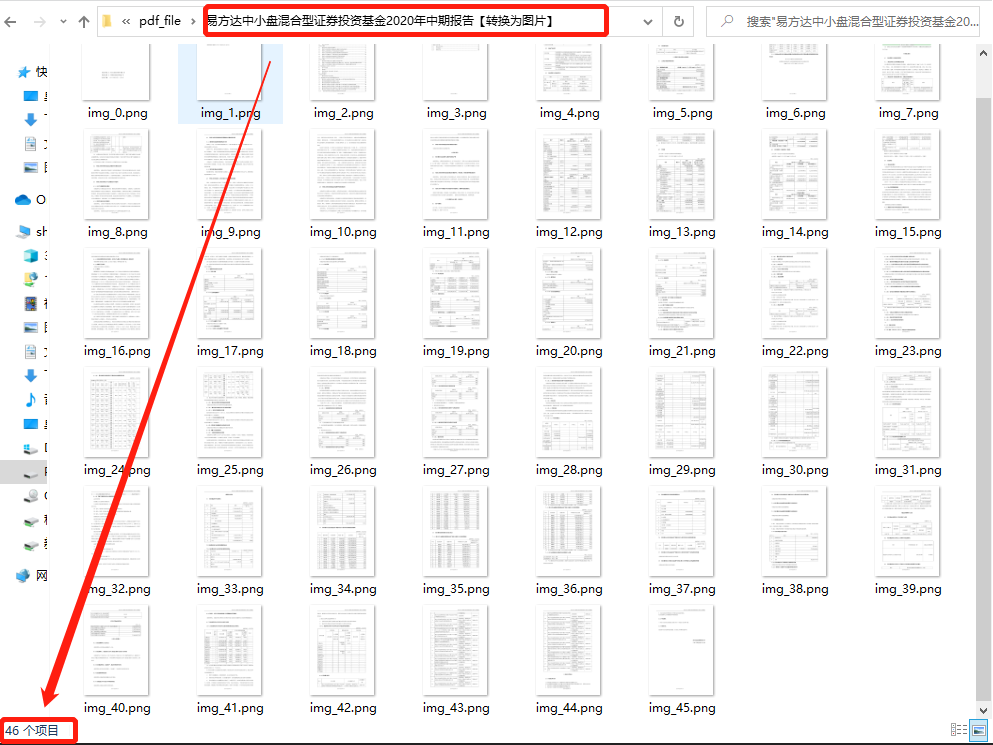
一共 46 張圖片
8. 添加水印
添加水印后的效果如下:
在制作水印的時候,可以自定義水印內容、透明度、斜度、字間寬度等等,可操作性比較好。
前面專門寫過一篇文章,講的特別詳細:Python快速給PDF文件添加自定義水印
9. 文檔加密與解密
你可能在打開部分 PDF 文件的時候,會彈出下面這個界面:
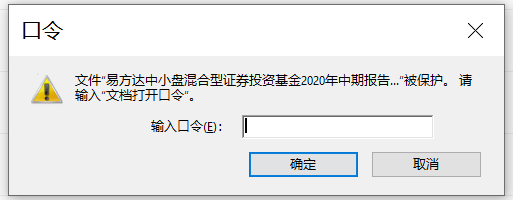
這種就是 PDF 文件被加密了,在打開的時候需要相應的密碼才行
本節(jié)所提到的也只是基于 PDF 文檔的加密解密,而不是所謂的 PDF 密碼破解。
在對 PDF 文件加密需要使用 encrypt 函數(shù),對應的加密代碼也比較簡單:
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
def encrypt_pdf(filepath, save_filepath, passwd='xiaoyi'):
"""
PDF文檔加密
@param filepath:PDF文件路徑
@param save_filepath:加密后的文件保存路徑
@param passwd:密碼
@return:
"""
pdf_reader = PdfFileReader(filepath)
pdf_writer = PdfFileWriter()
for page_index in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page_index))
# 添加密碼
pdf_writer.encrypt(passwd)
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
# 文檔加密
encrypt_pdf(filepath, save_filepath, passwd='xiaoyi')
代碼執(zhí)行成功后再次打開 PDF 文件則需要輸入密碼才行
根據(jù)這個思路,破解 PDF 也可以通過暴力求解實現(xiàn),例如:通過本地密碼本一個個去嘗試,或者根據(jù)數(shù)字+字母的密碼形式循環(huán)嘗試,最終成功打開的密碼就是破解密碼
上述破解方法耗時耗力,不建議嘗試
另外,針對已經(jīng)加密的 PDF 文件,也可以使用 decrypt 函數(shù)進行解密操作
解密代碼如下:
def decrypt_pdf(filepath, save_filepath, passwd='xiaoyi'):
"""
解密 PDF 文檔并且保存為未加密的 PDF
@param filepath:PDF文件路徑
@param save_filepath:解密后的文件保存路徑
@param passwd:密碼
@return:
"""
pdf_reader = PdfFileReader(filepath)
# PDF文檔解密
pdf_reader.decrypt('xiaoyi')
pdf_writer = PdfFileWriter()
for page_index in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page_index))
with open(save_filepath, "wb") as out:
pdf_writer.write(out)
# 文檔解密
decrypt_pdf(filepath, save_filepath, passwd='xiaoyi')
解密完成后的 PDF 文檔打開后不再需要輸入密碼,如需加密可再次執(zhí)行加密代碼。
推薦閱讀:
入門: 最全的零基礎學Python的問題 | 零基礎學了8個月的Python | 實戰(zhàn)項目 |學Python就是這條捷徑
干貨:爬取豆瓣短評,電影《后來的我們》 | 38年NBA最佳球員分析 | 從萬眾期待到口碑撲街!唐探3令人失望 | 笑看新倚天屠龍記 | 燈謎答題王 |用Python做個海量小姐姐素描圖 |碟中諜這么火,我用機器學習做個迷你推薦系統(tǒng)電影
趣味:彈球游戲 | 九宮格 | 漂亮的花 | 兩百行Python《天天酷跑》游戲!
AI: 會做詩的機器人 | 給圖片上色 | 預測收入 | 碟中諜這么火,我用機器學習做個迷你推薦系統(tǒng)電影
小工具: Pdf轉Word,輕松搞定表格和水印! | 一鍵把html網(wǎng)頁保存為pdf!| 再見PDF提取收費! | 用90行代碼打造最強PDF轉換器,word、PPT、excel、markdown、html一鍵轉換 | 制作一款釘釘?shù)蛢r機票提示器! |60行代碼做了一個語音壁紙切換器天天看小姐姐!|

年度爆款文案
點閱讀原文,領廖雪峰視頻資料!
