臥槽!用 SQL 實(shí)現(xiàn)了KNN算法
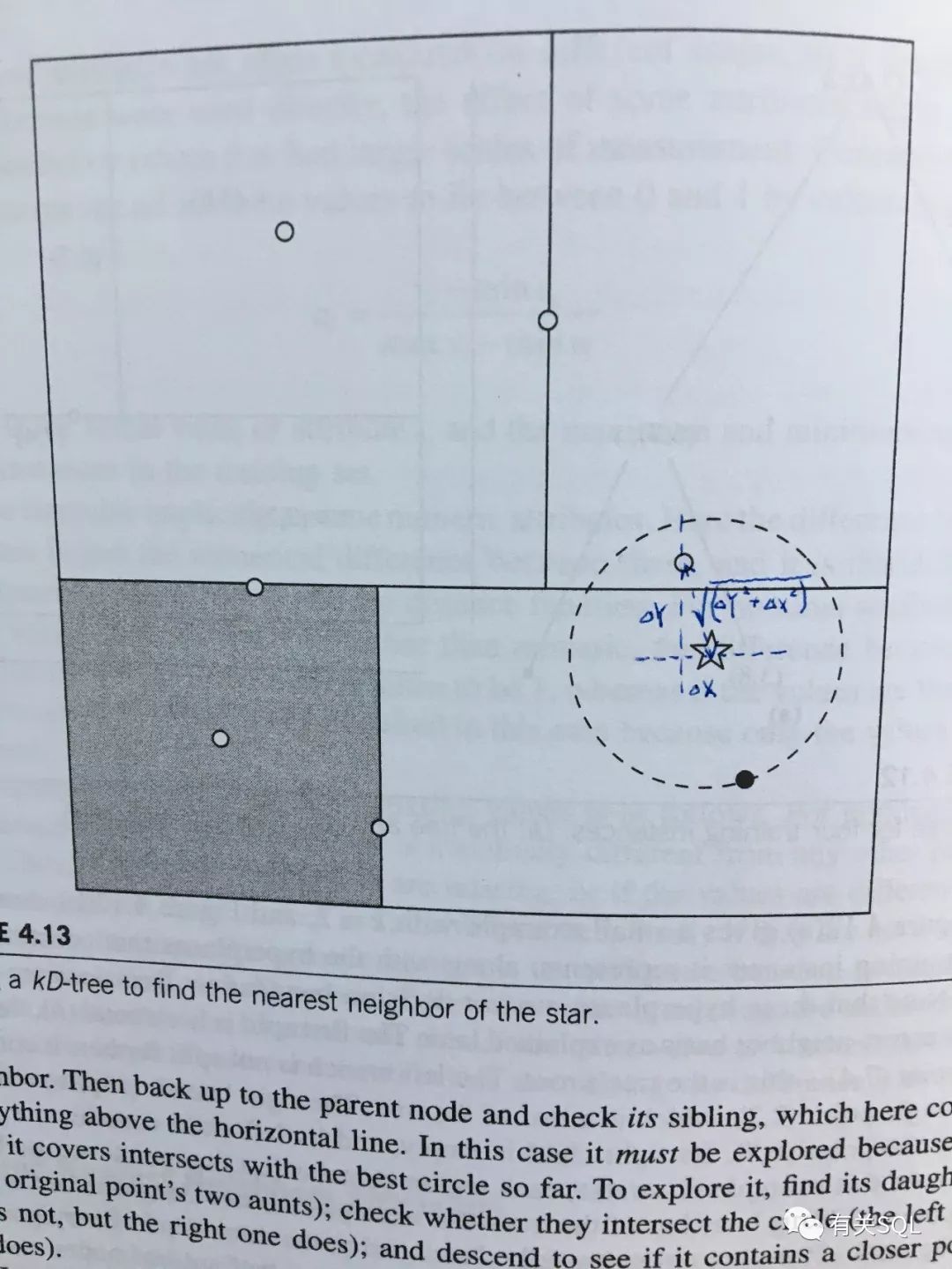
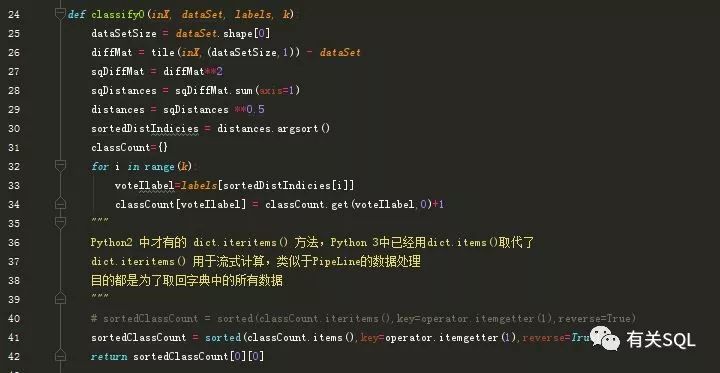
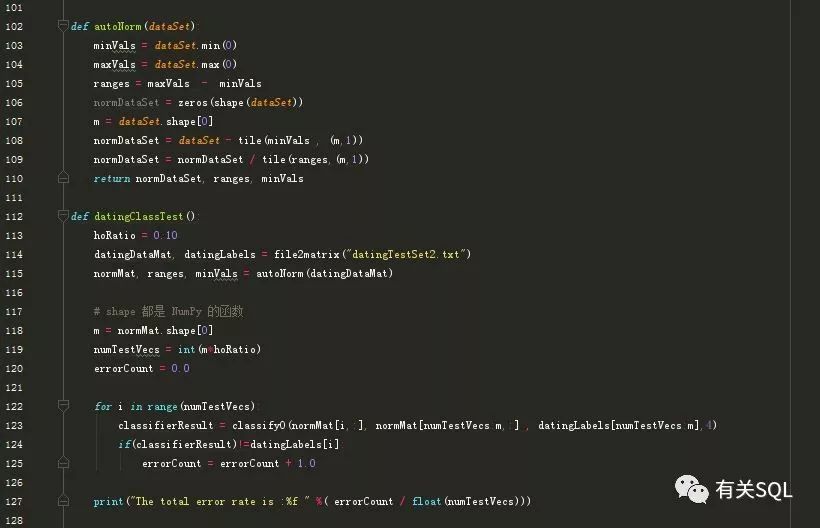
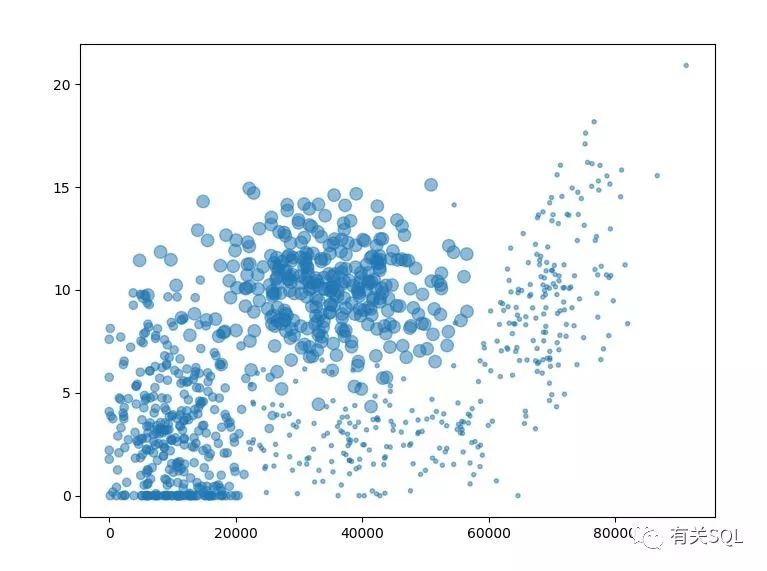

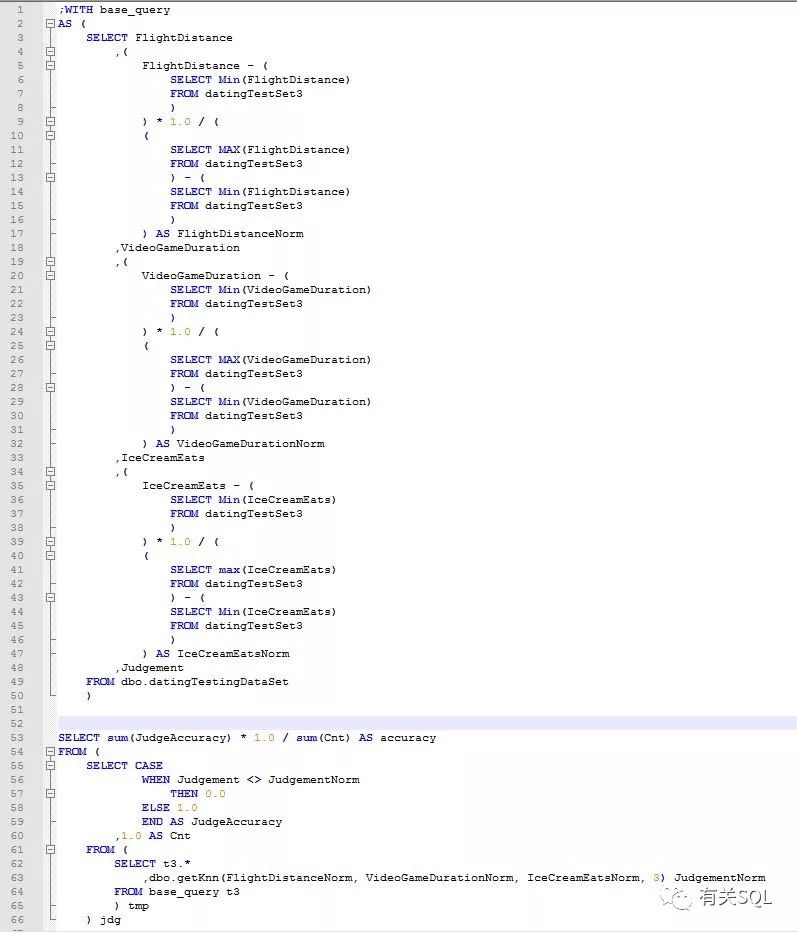
select *from dbo.datingSampleDataSetselect *from dbo.datingTestingDataSet


推薦閱讀
評(píng)論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APPselect *from dbo.datingSampleDataSetselect *from dbo.datingTestingDataSet
<b id="afajh"><abbr id="afajh"></abbr></b>