
HBase 實(shí)踐 | HBase 在人資數(shù)據(jù)預(yù)處理平臺(tái)中的實(shí)踐

Tech
導(dǎo)讀

物流人資數(shù)據(jù)預(yù)處理平臺(tái),負(fù)責(zé)接收一線幾十萬員工不同條線的工作量,每日數(shù)據(jù)量約2000w,系統(tǒng)負(fù)責(zé)加工轉(zhuǎn)換并提供數(shù)據(jù)查詢的同時(shí),還需保證查詢性能,以及修改單個(gè)業(yè)務(wù)量功能。本文通過HBase在物流人資數(shù)據(jù)預(yù)處理平臺(tái)中實(shí)踐,講解HBase集群如何協(xié)同工作,并概述讀取數(shù)據(jù)以及存儲(chǔ)數(shù)據(jù)的原理,以及使用HBase注意事項(xiàng)。
人資績(jī)效數(shù)據(jù)預(yù)處理平臺(tái),負(fù)責(zé)接收所有上游業(yè)務(wù)量數(shù)據(jù)(工作內(nèi)容數(shù)據(jù)),用于一線幾十萬員工薪資計(jì)算。平臺(tái)單日接收量可達(dá)2000w,月度數(shù)據(jù)超5億。目前已有超過100種業(yè)務(wù)量接入,各業(yè)務(wù)量具有字段不一,數(shù)據(jù)格式不一致等特點(diǎn)。同時(shí)平臺(tái)還需對(duì)業(yè)務(wù)量更新以及高性能查詢有較高要求。通常技術(shù)上可以選擇OSS、MySql數(shù)據(jù)庫(kù)、ES,CK等方案。其中OSS云存儲(chǔ)方案,高并發(fā)下查詢性能以及單業(yè)務(wù)量字段更新無法滿足。MySql數(shù)據(jù)庫(kù)很難處理超過上億數(shù)據(jù)量。而ES存儲(chǔ)與查詢都可以滿足,對(duì)單個(gè)字段更新不夠友好,且ES成本較高。CK更適合做OLAP。
基于以上背景,技術(shù)選型時(shí),充分考慮到人資數(shù)據(jù)預(yù)處理平臺(tái)的特性,數(shù)據(jù)量大、數(shù)據(jù)非結(jié)構(gòu)化、高性能、開源穩(wěn)定等要求,選型HBase。
HBase是一個(gè)分布式的、面向列的開源數(shù)據(jù)庫(kù),它是一個(gè)適合于非結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)的數(shù)據(jù)庫(kù),它在Hadoop之上提供了類似于Bigtable的能力,同時(shí)又是一個(gè)高可靠性、高性能、面向列、可伸縮的分布式存儲(chǔ)系統(tǒng),同時(shí)HBase技術(shù)可在廉價(jià)PC Server上搭建起大規(guī)模結(jié)構(gòu)化存儲(chǔ)集群,性價(jià)比非常高。
京東內(nèi)部提供JDNosql即通過HBase搭建,參考文檔http://doc.nosql.jd.com/
對(duì)象存儲(chǔ):不少的頭條類、新聞?lì)惖男侣劇⒕W(wǎng)頁(yè)、圖片存儲(chǔ)在HBase之中,一些病毒公司的病毒庫(kù)也是存儲(chǔ)在HBase之中。
時(shí)序數(shù)據(jù):HBase之上有OpenTSDB模塊,可以滿足時(shí)序類場(chǎng)景的需求。
時(shí)空數(shù)據(jù):不少車聯(lián)網(wǎng)企業(yè),數(shù)據(jù)都是存在HBase之中。
消息/訂單:Facebook用HBase存儲(chǔ)在線消息,每天數(shù)據(jù)量近百億,每月數(shù)據(jù)量250 ~ 300T, HBase讀寫比基本在1:1,吞吐量150w qps。
Feeds流:典型的應(yīng)用如微信朋友圈。
命名空間:類比MySql中數(shù)據(jù)庫(kù)庫(kù)名。
表名:類比MySql中表名。
列族:一組列的集合為列族。列族下的列可以N個(gè)。
列名稱:存在列族下的單個(gè)列,列族下的名稱。
RowKey:HBase存儲(chǔ)采用 key-value方式,Key即為RowKey,所有的修改查詢等操作只能基于RowKey,必須唯一。
HBase由三種類型的服務(wù)器以主從模式構(gòu)成。
Region Server:負(fù)責(zé)數(shù)據(jù)的讀寫服務(wù),用戶通過與Region Server交互來實(shí)現(xiàn)對(duì)數(shù)據(jù)的訪問。每個(gè)Region服務(wù)器中包含最多1000個(gè)Region,每個(gè)Region里面包含了StartKey到EndKey的一個(gè)區(qū)間數(shù)據(jù)。
HBase HMaster:分組分配Region和操作DDL,在集群處于數(shù)據(jù)恢復(fù)或者動(dòng)態(tài)調(diào)整時(shí),監(jiān)控所有Region Server的狀態(tài)。
ZooKeeper:負(fù)責(zé)維護(hù)集群的狀態(tài)(某臺(tái)服務(wù)器是否在線,服務(wù)器之間數(shù)據(jù)的同步操作及HMaster的選舉等)。
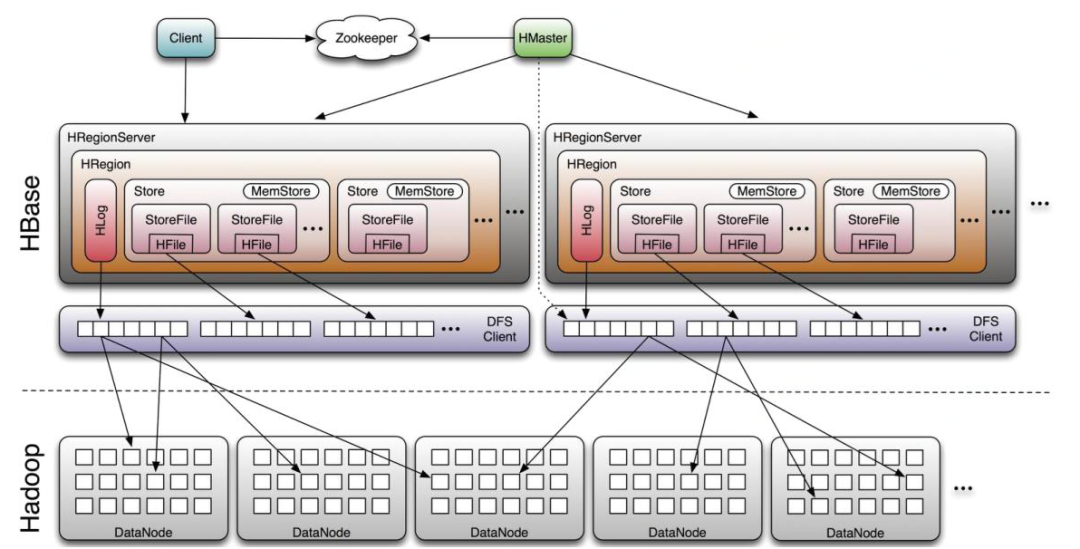
圖一 HBase整體架構(gòu)圖
Region Server,會(huì)通過心跳方式與ZooKeeper保持連接,并創(chuàng)建一個(gè)臨時(shí)節(jié)點(diǎn),當(dāng)無法監(jiān)聽到心跳時(shí),會(huì)通知ZooKeeper,同時(shí)刪除臨時(shí)節(jié)點(diǎn),而HMaser會(huì)通過ZooKeeper得到Region Server服務(wù)器的狀態(tài),當(dāng)服務(wù)器下線時(shí),會(huì)進(jìn)行數(shù)據(jù)恢復(fù)、容災(zāi)等操作。HMaster同樣會(huì)同ZooKeeper保持心跳,用于監(jiān)控HMaster狀態(tài),當(dāng)HMaster下線時(shí),會(huì)通過選舉方式,將HMaster集群中的一臺(tái)機(jī)器設(shè)置成Active,其他機(jī)器設(shè)置成InActive狀態(tài),來保證整個(gè)集群的高可用性。
數(shù)據(jù)讀取過程——
客戶端發(fā)起請(qǐng)求,從Zooeeper中獲取一個(gè)叫MetaTable的元數(shù)據(jù)。
注:如果本地有緩存會(huì)優(yōu)先讀取本地緩存。
客戶端通過MetaTable,得知RowKey所有在的Region Server服務(wù)器得到Region位置。
客戶端優(yōu)先從Region中的BlockCache(讀取緩存)中獲取數(shù)據(jù),如果BlockCache中不存在,會(huì)通過MemStore(寫入緩存)中獲取數(shù)據(jù),如果還不存在,會(huì)通過HFile中讀取,并將數(shù)據(jù)返回給客戶端。
讀取HFile時(shí),會(huì)通過尾部指針中布隆過濾區(qū)域與時(shí)間區(qū)域,可以快讀定位RowKey是否在HFile文件當(dāng)中。
HFile讀取后,會(huì)將多級(jí)索引加載在BlockCache中,用于讀加速。
數(shù)據(jù)寫入過程——
HBase客戶端發(fā)起Put請(qǐng)求時(shí),會(huì)先將數(shù)據(jù)寫入預(yù)寫日志(WAL)中,將操作記錄寫入WAL末尾。WAL用于Region Server服務(wù)器崩潰時(shí),恢復(fù)MemStore中數(shù)據(jù),WAL存儲(chǔ)在Hadoop的HDFS中。
數(shù)據(jù)在寫入Wal后,會(huì)將數(shù)據(jù)先寫入Region Server下Region中MemStore中(寫入緩存,內(nèi)存級(jí)別)。
在寫入MemStore成功后,反饋給客戶端本次寫入已經(jīng)完成。
當(dāng)MemStore達(dá)到一定量級(jí)時(shí),會(huì)通過Flush方式,生成HFile,存入Hadoop的HDFS中。HFile在生成前,會(huì)在內(nèi)存中對(duì)Key進(jìn)行升序排序,將排序好的數(shù)據(jù)順序?qū)懭際File中,并在HFile中生成一個(gè)多級(jí)索引,還有一個(gè)尾部指針。
HBase主要特點(diǎn)(人資績(jī)效數(shù)據(jù)預(yù)處理平臺(tái)實(shí)踐適配的特點(diǎn))——
HBase為分布式列式數(shù)據(jù)庫(kù),可以橫向進(jìn)行擴(kuò)展,解決系統(tǒng)存儲(chǔ)數(shù)據(jù)超2000w的問題。
HBase為列式存儲(chǔ)數(shù)據(jù)庫(kù),一個(gè)列族下可以支持成百上千列,解決系統(tǒng)對(duì)非結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)與單個(gè)數(shù)據(jù)列更新等問題。
HBase具備毫秒級(jí)讀寫,隨機(jī)讀寫,實(shí)時(shí)讀寫,無線存儲(chǔ)拓展,數(shù)據(jù)高可用,多級(jí)緩存,服務(wù)不中斷,主備自動(dòng)切換,異地雙活等特性,解決系統(tǒng)高可用等問題。
HBase存儲(chǔ)自帶多種壓縮算法,降低數(shù)據(jù)存儲(chǔ)量。
HBase數(shù)據(jù)支持多版本,對(duì)修改的數(shù)據(jù)可以支持多個(gè)版本數(shù)據(jù)。
HBase自帶數(shù)據(jù)有效期功能,對(duì)于冷數(shù)據(jù)可以定期刪除。
HBase優(yōu)點(diǎn)——
列可以動(dòng)態(tài)增加,并且列為空就不存儲(chǔ)數(shù)據(jù),節(jié)省存儲(chǔ)空間。
HBase自動(dòng)切分?jǐn)?shù)據(jù),使得數(shù)據(jù)存儲(chǔ)自動(dòng)具有水平擴(kuò)展能力。
HBase可以提供高并發(fā)讀寫操作的支持。
HBase缺點(diǎn)——
不能支持條件查詢,只支持按照RowKey來查詢。
不適合于大范圍掃描查詢。
不支持事務(wù)。
HBase注意事項(xiàng)——
1.數(shù)據(jù)熱點(diǎn)問題以及解決方法
HBase創(chuàng)建表時(shí)會(huì)使用多個(gè)Region,如果使用不正確會(huì)導(dǎo)致所有數(shù)據(jù)寫入同一個(gè)Region服務(wù)器下,造成數(shù)據(jù)熱點(diǎn)問題,解決數(shù)據(jù)熱點(diǎn)問題一共需要注意兩個(gè)方面。
第一方面是建表時(shí)(預(yù)分區(qū)建表),要根據(jù)自己的RowKey特性選擇正確的分區(qū)規(guī)則,人資數(shù)據(jù)預(yù)處理平臺(tái)采用 HexStringSplit這種方式。
第二方面是RowKey的設(shè)計(jì),需要保證唯一的同時(shí)盡量散列。人資側(cè)采用雪花算法生成唯一ID,對(duì)唯一ID高位進(jìn)行MD5轉(zhuǎn)16進(jìn)制加上反轉(zhuǎn)后的唯一ID作為RowKey,可以將數(shù)據(jù)均勻的分散到多個(gè)Region中,避免數(shù)據(jù)熱點(diǎn)問題。
2.HBase批量獲取數(shù)據(jù)大小建議
對(duì)HBase進(jìn)行批量查詢時(shí),將批量數(shù)據(jù)控制到100KB以內(nèi),超過后性能下降非常明顯。
3.單行數(shù)據(jù)大小限制
單行不建議超過400KB,KV存儲(chǔ)系統(tǒng)非對(duì)象存儲(chǔ)系統(tǒng)。如果Value過大會(huì)導(dǎo)致處理性能直線下降。
4.Scan使用
Scan屬于不穩(wěn)定接口,如掃描范圍過大或設(shè)置不準(zhǔn)會(huì)導(dǎo)致性能下降,使用時(shí)必須設(shè)置startKey與endKey,同時(shí)start與end之間不要超過100條數(shù)據(jù)。
5.HBase連接事項(xiàng)
HBase每次連接耗時(shí)較高,構(gòu)建Connect對(duì)象時(shí),需要在程序啟動(dòng)時(shí)進(jìn)行,避免使用時(shí)創(chuàng)建。
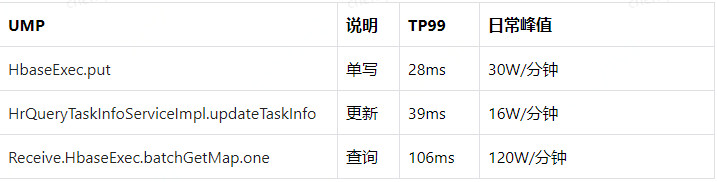
圖2 HBase在人資績(jī)效數(shù)據(jù)預(yù)處理平臺(tái)中的性能參考
HBase寫入最近30天TP99
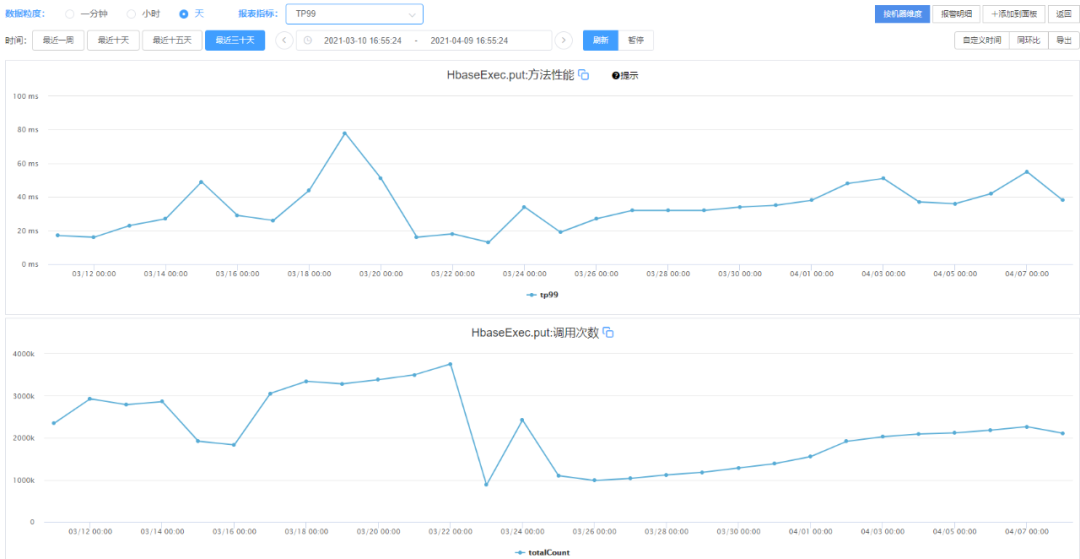
圖3 HBase寫入最近30天TP99
HBase更新性能
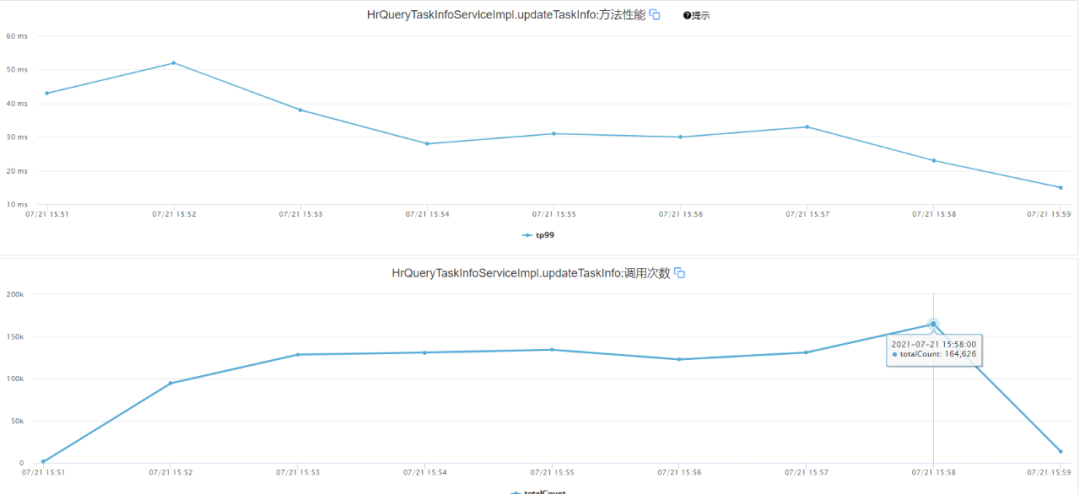
圖4 HBase更新性能
HBase查詢速度TP99

圖5 HBase查詢速度TP99

KDD 2021:基于Seq2Seq多任務(wù)學(xué)習(xí)的路網(wǎng)軌跡恢復(fù)
