
這些有難度的NodeJS面試題,你能答對幾個?

作者 | 孟祥_成都
來源 | https://juejin.cn/post/6844903951742025736
1、Node模塊機制
1.1 請介紹一下node里的模塊是什么
function Module(id, parent) {this.id = id;this.exports = {};this.parent = parent;this.filename = null;this.loaded = false;this.children = [];}module.exports = Module;var module = new Module(filename, parent);
所有的模塊都是 Module 的實例。可以看到,當前模塊(module.js)也是 Module 的一個實例。
1.2 請介紹一下require的模塊加載機制
這道題基本上就可以了解到面試者對Node模塊機制的了解程度 基本上面試提到
1)、先計算模塊路徑
2)、如果模塊在緩存里面,取出緩存
3)、加載模塊
4)、的輸出模塊的exports屬性即可
// require 其實內(nèi)部調(diào)用 Module._load 方法Module._load = function(request, parent, isMain) {// 計算絕對路徑var filename = Module._resolveFilename(request, parent);// 第一步:如果有緩存,取出緩存var cachedModule = Module._cache[filename];if (cachedModule) {return cachedModule.exports;// 第二步:是否為內(nèi)置模塊if (NativeModule.exists(filename)) {return NativeModule.require(filename);}/********************************這里注意了**************************/// 第三步:生成模塊實例,存入緩存// 這里的Module就是我們上面的1.1定義的Modulevar module = new Module(filename, parent);Module._cache[filename] = module;/********************************這里注意了**************************/// 第四步:加載模塊// 下面的module.load實際上是Module原型上有一個方法叫Module.prototype.loadtry {module.load(filename);hadException = false;} finally {if (hadException) {delete Module._cache[filename];}}// 第五步:輸出模塊的exports屬性return module.exports;};
接著上一題繼續(xù)發(fā)問
1.3 加載模塊時,為什么每個模塊都有__dirname,__filename屬性呢,new Module的時候我們看到1.1部分沒有這兩個屬性的,那么這兩個屬性是從哪里來的
// 上面(1.2部分)的第四步module.load(filename)// 這一步,module模塊相當于被包裝了,包裝形式如下// 加載js模塊,相當于下面的代碼(加載node模塊和json模塊邏輯不一樣)(function (exports, require, module, __filename, __dirname) {// 模塊源碼// 假如模塊代碼如下var math = require('math');exports.area = function(radius){return Math.PI * radius * radius}});
也就是說,每個module里面都會傳入__filename, __dirname參數(shù),這兩個參數(shù)并不是module本身就有的,是外界傳入的
1.4 我們知道node導出模塊有兩種方式,一種是exports.xxx=xxx和Module.exports={}有什么區(qū)別嗎
exports其實就是module.exports
其實1.3問題的代碼已經(jīng)說明問題了,接著我引用廖雪峰大神的講解,希望能講的更清楚。
module.exports vs exports很多時候,你會看到,在Node環(huán)境中,有兩種方法可以在一個模塊中輸出變量:方法一:對module.exports賦值:// hello.jsfunction hello() {console.log('Hello, world!');}function greet(name) {console.log('Hello, ' + name + '!');}module.exports = {hello: hello,greet: greet};方法二:直接使用exports:// hello.jsfunction hello() {console.log('Hello, world!');}function greet(name) {console.log('Hello, ' + name + '!');}function hello() {console.log('Hello, world!');}exports.hello = hello;exports.greet = greet;但是你不可以直接對exports賦值:// 代碼可以執(zhí)行,但是模塊并沒有輸出任何變量:exports = {hello: hello,greet: greet};如果你對上面的寫法感到十分困惑,不要著急,我們來分析Node的加載機制:首先,Node會把整個待加載的hello.js文件放入一個包裝函數(shù)load中執(zhí)行。在執(zhí)行這個load()函數(shù)前,Node準備好了module變量:var module = {id: 'hello',exports: {}};load()函數(shù)最終返回module.exports:var load = function (exports, module) {// hello.js的文件內(nèi)容...// load函數(shù)返回:return module.exports;};var exportes = load(module.exports, module);也就是說,默認情況下,Node準備的exports變量和module.exports變量實際上是同一個變量,并且初始化為空對象{},于是,我們可以寫:exports.foo = function () { return 'foo'; };exports.bar = function () { return 'bar'; };也可以寫:module.exports.foo = function () { return 'foo'; };module.exports.bar = function () { return 'bar'; };換句話說,Node默認給你準備了一個空對象{},這樣你可以直接往里面加東西。但是,如果我們要輸出的是一個函數(shù)或數(shù)組,那么,只能給module.exports賦值:module.exports = function () { return 'foo'; };給exports賦值是無效的,因為賦值后,module.exports仍然是空對象{}。結論如果要輸出一個鍵值對象{},可以利用exports這個已存在的空對象{},并繼續(xù)在上面添加新的鍵值;如果要輸出一個函數(shù)或數(shù)組,必須直接對module.exports對象賦值。所以我們可以得出結論:直接對module.exports賦值,可以應對任何情況:module.exports = {foo: function () { return 'foo'; }};或者:module.exports = function () { return 'foo'; };最終,我們強烈建議使用module.exports = xxx的方式來輸出模塊變量,這樣,你只需要記憶一種方法。
2、Node的異步I/O
本章的答題思路大多借鑒于樸靈大神的《深入淺出的NodeJS》
2.1 請介紹一下Node事件循環(huán)的流程
在進程啟動時,Node便會創(chuàng)建一個類似于while(true)的循環(huán),每執(zhí)行一次循環(huán)體的過程我們成為Tick。
每個Tick的過程就是查看是否有事件待處理。如果有就取出事件及其相關的回調(diào)函數(shù)。然后進入下一個循環(huán),如果不再有事件處理,就退出進程。
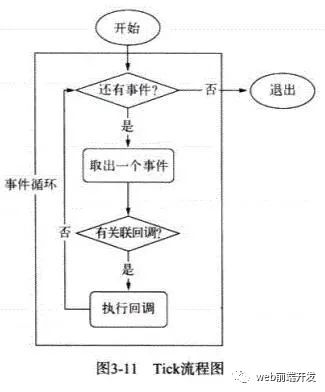
2.2 在每個tick的過程中,如何判斷是否有事件需要處理呢?
每個事件循環(huán)中有一個或者多個觀察者,而判斷是否有事件需要處理的過程就是向這些觀察者詢問是否有要處理的事件。
在Node中,事件主要來源于網(wǎng)絡請求、文件的I/O等,這些事件對應的觀察者有文件I/O觀察者,網(wǎng)絡I/O的觀察者。
事件循環(huán)是一個典型的生產(chǎn)者/消費者模型。異步I/O,網(wǎng)絡請求等則是事件的生產(chǎn)者,源源不斷為Node提供不同類型的事件,這些事件被傳遞到對應的觀察者那里,事件循環(huán)則從觀察者那里取出事件并處理。
在windows下,這個循環(huán)基于IOCP創(chuàng)建,在*nix下則基于多線程創(chuàng)建。
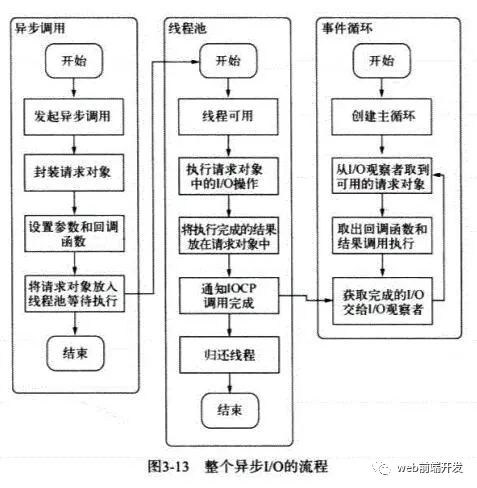
2.3 請描述一下整個異步I/O的流程
3、V8的垃圾回收機制
3.1 如何查看V8的內(nèi)存使用情況
使用process.memoryUsage(),返回如下
{rss: 4935680,heapTotal: 1826816,heapUsed: 650472,external: 49879}
heapTotal 和 heapUsed 代表V8的內(nèi)存使用情況。 external代表V8管理的,綁定到JavaScript的C++對象的內(nèi)存使用情況。 rss, 駐留集大小, 是給這個進程分配了多少物理內(nèi)存(占總分配內(nèi)存的一部分) 這些物理內(nèi)存中包含堆,棧,和代碼段。
3.2 V8的內(nèi)存限制是多少,為什么V8這樣設計
64位系統(tǒng)下是1.4GB, 32位系統(tǒng)下是0.7GB。因為1.5GB的垃圾回收堆內(nèi)存,V8需要花費50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。這是垃圾回收中引起JavaScript線程暫停執(zhí)行的事件,在這樣的花銷下,應用的性能和影響力都會直線下降。
3.3 V8的內(nèi)存分代和回收算法請簡單講一講
在V8中,主要將內(nèi)存分為新生代和老生代兩代。新生代中的對象存活時間較短的對象,老生代中的對象存活時間較長,或常駐內(nèi)存的對象。

3.3.1 新生代
新生代中的對象主要通過Scavenge算法進行垃圾回收。這是一種采用復制的方式實現(xiàn)的垃圾回收算法。它將堆內(nèi)存一份為二,每一部分空間成為semispace。
在這兩個semispace空間中,只有一個處于使用中,另一個處于閑置狀態(tài)。處于使用狀態(tài)的semispace空間稱為From空間,處于閑置狀態(tài)的空間稱為To空間。

當開始垃圾回收的時候,會檢查From空間中的存活對象,這些存活對象將被復制到To空間中,而非存活對象占用的空間將會被釋放。完成復制后,F(xiàn)rom空間和To空間發(fā)生角色對換。
應為新生代中對象的生命周期比較短,就比較適合這個算法。
當一個對象經(jīng)過多次復制依然存活,它將會被認為是生命周期較長的對象。這種新生代中生命周期較長的對象隨后會被移到老生代中。
3.3.2 老生代
老生代主要采取的是標記清除的垃圾回收算法。與Scavenge復制活著的對象不同,標記清除算法在標記階段遍歷堆中的所有對象,并標記活著的對象,只清理死亡對象。
活對象在新生代中只占叫小部分,死對象在老生代中只占較小部分,這是為什么采用標記清除算法的原因。
3.3.3 標記清楚算法的問題
主要問題是每一次進行標記清除回收后,內(nèi)存空間會出現(xiàn)不連續(xù)的狀態(tài)

這種內(nèi)存碎片會對后續(xù)內(nèi)存分配造成問題,很可能出現(xiàn)需要分配一個大對象的情況,這時所有的碎片空間都無法完成此次分配,就會提前觸發(fā)垃圾回收,而這次回收是不必要的。
為了解決碎片問題,標記整理被提出來。就是在對象被標記死亡后,在整理的過程中,將活著的對象往一端移動,移動完成后,直接清理掉邊界外的內(nèi)存。
3.3.4 哪些情況會造成V8無法立即回收內(nèi)存
閉包和全局變量
3.3.5 請談一下內(nèi)存泄漏是什么,以及常見內(nèi)存泄漏的原因,和排查的方法
什么是內(nèi)存泄漏
內(nèi)存泄漏(Memory Leak)指由于疏忽或錯誤造成程序未能釋放已經(jīng)不再使用的內(nèi)存的情況。
如果內(nèi)存泄漏的位置比較關鍵,那么隨著處理的進行可能持有越來越多的無用內(nèi)存,這些無用的內(nèi)存變多會引起服務器響應速度變慢。
嚴重的情況下導致內(nèi)存達到某個極限(可能是進程的上限,如 v8 的上限;也可能是系統(tǒng)可提供的內(nèi)存上限)會使得應用程序崩潰。 常見內(nèi)存泄漏的原因 內(nèi)存泄漏的幾種情況:
一、全局變量
a = 10;//未聲明對象。global.b = 11;//全局變量引用這種比較簡單的原因,全局變量直接掛在 root 對象上,不會被清除掉。
二、閉包
function out() {const bigData = new Buffer(100);inner = function () {}}
閉包會引用到父級函數(shù)中的變量,如果閉包未釋放,就會導致內(nèi)存泄漏。上面例子是 inner 直接掛在了 root 上,那么每次執(zhí)行 out 函數(shù)所產(chǎn)生的 bigData 都不會釋放,從而導致內(nèi)存泄漏。
需要注意的是,這里舉得例子只是簡單的將引用掛在全局對象上,實際的業(yè)務情況可能是掛在某個可以從 root 追溯到的對象上導致的。
三、事件監(jiān)聽
Node.js 的事件監(jiān)聽也可能出現(xiàn)的內(nèi)存泄漏。例如對同一個事件重復監(jiān)聽,忘記移除(removeListener),將造成內(nèi)存泄漏。這種情況很容易在復用對象上添加事件時出現(xiàn),所以事件重復監(jiān)聽可能收到如下警告:
emitter.setMaxListeners() to increase limit
例如,Node.js 中 Agent 的 keepAlive 為 true 時,可能造成的內(nèi)存泄漏。當 Agent keepAlive 為 true 的時候,將會復用之前使用過的 socket,如果在 socket 上添加事件監(jiān)聽,忘記清除的話,因為 socket 的復用,將導致事件重復監(jiān)聽從而產(chǎn)生內(nèi)存泄漏。
原理上與前一個添加事件監(jiān)聽的時候忘了清除是一樣的。在使用 Node.js 的 http 模塊時,不通過 keepAlive 復用是沒有問題的,復用了以后就會可能產(chǎn)生內(nèi)存泄漏。所以,你需要了解添加事件監(jiān)聽的對象的生命周期,并注意自行移除。
排查方法
想要定位內(nèi)存泄漏,通常會有兩種情況:
對于只要正常使用就可以重現(xiàn)的內(nèi)存泄漏,這是很簡單的情況只要在測試環(huán)境模擬就可以排查了。
對于偶然的內(nèi)存泄漏,一般會與特殊的輸入有關系。想穩(wěn)定重現(xiàn)這種輸入是很耗時的過程。如果不能通過代碼的日志定位到這個特殊的輸入,那么推薦去生產(chǎn)環(huán)境打印內(nèi)存快照了。
需要注意的是,打印內(nèi)存快照是很耗 CPU 的操作,可能會對線上業(yè)務造成影響。 快照工具推薦使用 heapdump 用來保存內(nèi)存快照,使用 devtool 來查看內(nèi)存快照。
使用 heapdump 保存內(nèi)存快照時,只會有 Node.js 環(huán)境中的對象,不會受到干擾(如果使用 node-inspector 的話,快照中會有前端的變量干擾)。
PS:安裝 heapdump 在某些 Node.js 版本上可能出錯,建議使用 npm install heapdump -target=Node.js 版本來安裝。
4、Buffer模塊
4.1 新建Buffer會占用V8分配的內(nèi)存嗎
不會,Buffer屬于堆外內(nèi)存,不是V8分配的。
4.2 Buffer.alloc和Buffer.allocUnsafe的區(qū)別
Buffer.allocUnsafe創(chuàng)建的 Buffer 實例的底層內(nèi)存是未初始化的。 新創(chuàng)建的 Buffer 的內(nèi)容是未知的,可能包含敏感數(shù)據(jù)。 使用 Buffer.alloc() 可以創(chuàng)建以零初始化的 Buffer 實例。
4.3 Buffer的內(nèi)存分配機制
為了高效的使用申請來的內(nèi)存,Node采用了slab分配機制。slab是一種動態(tài)的內(nèi)存管理機制。 Node以8kb為界限來來區(qū)分Buffer為大對象還是小對象,如果是小于8kb就是小Buffer,大于8kb就是大Buffer。
例如第一次分配一個1024字節(jié)的Buffer,Buffer.alloc(1024),那么這次分配就會用到一個slab,接著如果繼續(xù)Buffer.alloc(1024),那么上一次用的slab的空間還沒有用完,因為總共是8kb,1024+1024 = 2048個字節(jié),沒有8kb,所以就繼續(xù)用這個slab給Buffer分配空間。
如果超過8kb,那么直接用C++底層地宮的SlowBuffer來給Buffer對象提供空間。
4.4 Buffer亂碼問題
例如一個份文件test.md里的內(nèi)容如下:
床前明月光,疑是地上霜,舉頭望明月,低頭思故鄉(xiāng)
我們這樣讀取就會出現(xiàn)亂碼:
var rs = require('fs').createReadStream('test.md', {highWaterMark: 11});// 床前明???光,疑???地上霜,舉頭???明月,???頭思故鄉(xiāng)
一般情況下,只需要設置rs.setEncoding('utf8')即可解決亂碼問題
5、webSocket
5.1 webSocket與傳統(tǒng)的http有什么優(yōu)勢
客戶端與服務器只需要一個TCP連接,比http長輪詢使用更少的連接
webSocket服務端可以推送數(shù)據(jù)到客戶端
更輕量的協(xié)議頭,減少數(shù)據(jù)傳輸量
5.2 webSocket協(xié)議升級時什么,能簡述一下嗎?
首先,WebSocket連接必須由瀏覽器發(fā)起,因為請求協(xié)議是一個標準的HTTP請求,格式如下:
GET ws://localhost:3000/ws/chat HTTP/1.1Host: localhostUpgrade: websocketConnection: UpgradeOrigin: http://localhost:3000Sec-WebSocket-Key: client-random-stringSec-WebSocket-Version: 13
該請求和普通的HTTP請求有幾點不同:
GET請求的地址不是類似/path/,而是以ws://開頭的地址;
請求頭Upgrade: websocket和Connection: Upgrade表示這個連接將要被轉換為WebSocket連接;
Sec-WebSocket-Key是用于標識這個連接,并非用于加密數(shù)據(jù);
Sec-WebSocket-Version指定了WebSocket的協(xié)議版本。
隨后,服務器如果接受該請求,就會返回如下響應:
HTTP/1.1 101 Switching ProtocolsUpgrade: websocketConnection: UpgradeSec-WebSocket-Accept: server-random-string
該響應代碼101表示本次連接的HTTP協(xié)議即將被更改,更改后的協(xié)議就是Upgrade: websocket指定的WebSocket協(xié)議。
6、https
6.1 https用哪些端口進行通信,這些端口分別有什么用
443端口用來驗證服務器端和客戶端的身份,比如驗證證書的合法性
80端口用來傳輸數(shù)據(jù)(在驗證身份合法的情況下,用來數(shù)據(jù)傳輸)
6.2 身份驗證過程中會涉及到密鑰, 對稱加密,非對稱加密,摘要的概念,請解釋一下
密鑰:密鑰是一種參數(shù),它是在明文轉換為密文或將密文轉換為明文的算法中輸入的參數(shù)。密鑰分為對稱密鑰與非對稱密鑰,分別應用在對稱加密和非對稱加密上。
對稱加密:對稱加密又叫做私鑰加密,即信息的發(fā)送方和接收方使用同一個密鑰去加密和解密數(shù)據(jù)。
對稱加密的特點是算法公開、加密和解密速度快,適合于對大數(shù)據(jù)量進行加密,常見的對稱加密算法有DES、3DES、TDEA、Blowfish、RC5和IDEA。
非對稱加密:非對稱加密也叫做公鑰加密。非對稱加密與對稱加密相比,其安全性更好。
對稱加密的通信雙方使用相同的密鑰,如果一方的密鑰遭泄露,那么整個通信就會被破解。
而非對稱加密使用一對密鑰,即公鑰和私鑰,且二者成對出現(xiàn)。私鑰被自己保存,不能對外泄露。公鑰指的是公共的密鑰,任何人都可以獲得該密鑰。用公鑰或私鑰中的任何一個進行加密,用另一個進行解密。
摘要: 摘要算法又稱哈希/散列算法。它通過一個函數(shù),把任意長度的數(shù)據(jù)轉換為一個長度固定的數(shù)據(jù)串(通常用16進制的字符串表示)。算法不可逆。
6.3 為什么需要CA機構對證書簽名
如果不簽名會存在中間人攻擊的風險,簽名之后保證了證書里的信息,比如公鑰、服務器信息、企業(yè)信息等不被篡改,能夠驗證客戶端和服務器端的“合法性”。
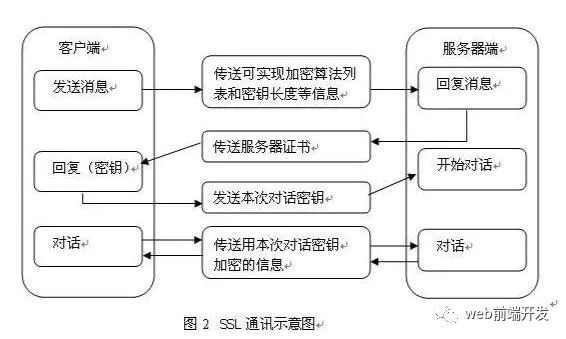
6.4 https驗證身份也就是TSL/SSL身份驗證的過程
簡要圖解如下:
7、進程通信
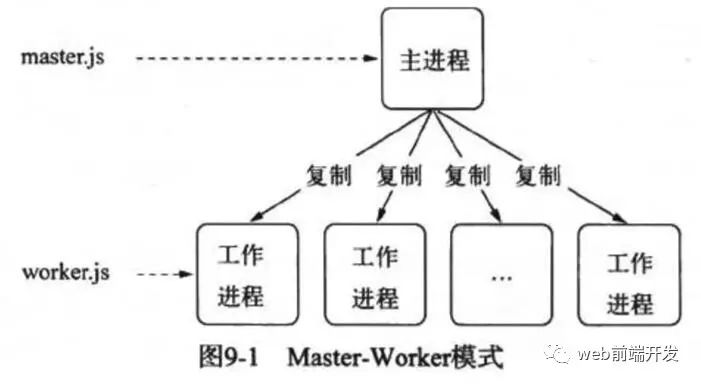
7.1 請簡述一下node的多進程架構
面對node單線程對多核CPU使用不足的情況,Node提供了child_process模塊,來實現(xiàn)進程的復制,node的多進程架構是主從模式,如下所示:
var fork = require('child_process').fork;var cpus = require('os').cpus();for(var i = 0; i < cpus.length; i++){fork('./worker.js');}
在linux中,我們通過ps aux | grep worker.js查看進程

這就是著名的主從模式,Master-Worker
7.2 請問創(chuàng)建子進程的方法有哪些,簡單說一下它們的區(qū)別
創(chuàng)建子進程的方法大致有:
spawn(): 啟動一個子進程來執(zhí)行命令
exec(): 啟動一個子進程來執(zhí)行命令,與spawn()不同的是其接口不同,它有一個回調(diào)函數(shù)獲知子進程的狀況
execFlie(): 啟動一個子進程來執(zhí)行可執(zhí)行文件
fork(): 與spawn()類似,不同電在于它創(chuàng)建Node子進程需要執(zhí)行js文件
spawn()與exec()、execFile()不同的是,后兩者創(chuàng)建時可以指定timeout屬性設置超時時間,一旦創(chuàng)建的進程超過設定的時間就會被殺死
exec()與execFile()不同的是,exec()適合執(zhí)行已有命令,execFile()適合執(zhí)行文件。
7.3 請問你知道spawn在創(chuàng)建子進程的時候,第三個參數(shù)有一個stdio選項嗎,這個選項的作用是什么,默認的值是什么。
選項用于配置在父進程和子進程之間建立的管道。
默認情況下,子進程的 stdin、 stdout 和 stderr 會被重定向到 ChildProcess 對象上相應的 subprocess.stdin、subprocess.stdout 和 subprocess.stderr 流。
這相當于將 options.stdio 設置為 ['pipe', 'pipe', 'pipe']。
7.4 請問實現(xiàn)一個node子進程被殺死,然后自動重啟代碼的思路
在創(chuàng)建子進程的時候就讓子進程監(jiān)聽exit事件,如果被殺死就重新fork一下
var createWorker = function(){var worker = fork(__dirname + 'worker.js')worker.on('exit', function(){console.log('Worker' + worker.pid + 'exited');// 如果退出就創(chuàng)建新的workercreateWorker()})}
7.5 在7.4的基礎上,實現(xiàn)限量重啟,比如我最多讓其在1分鐘內(nèi)重啟5次,超過了就報警給運維
思路大概是在創(chuàng)建worker的時候,就判斷創(chuàng)建的這個worker是否在1分鐘內(nèi)重啟次數(shù)超過5次
所以每一次創(chuàng)建worker的時候都要記錄這個worker 創(chuàng)建時間,放入一個數(shù)組隊列里面,每次創(chuàng)建worker都去取隊列里前5條記錄
如果這5條記錄的時間間隔小于1分鐘,就說明到了報警的時候了
7.6 如何實現(xiàn)進程間的狀態(tài)共享,或者數(shù)據(jù)共享
我自己沒用過Kafka這類消息隊列工具,問了java,可以用類似工具來實現(xiàn)進程間通信,更好的方法歡迎留言。
8、中間件
8.1 如果使用過koa、egg這兩個Node框架,請簡述其中的中間件原理,最好用代碼表示一下。

上面是在網(wǎng)上找的一個示意圖,就是說中間件執(zhí)行就像洋蔥一樣,最早use的中間件,就放在最外層。處理順序從左到右,左邊接收一個request,右邊輸出返回response
一般的中間件都會執(zhí)行兩次,調(diào)用next之前為第一次,調(diào)用next時把控制傳遞給下游的下一個中間件。當下游不再有中間件或者沒有執(zhí)行next函數(shù)時,就將依次恢復上游中間件的行為,讓上游中間件執(zhí)行next之后的代碼
例如下面這段代碼
const Koa = require('koa')const app = new Koa()app.use((ctx, next) => {console.log(1)next()console.log(3)})app.use((ctx) => {console.log(2)})app.listen(3001)執(zhí)行結果是1=>2=>3
koa中間件實現(xiàn)源碼大致思路如下:
// 注意其中的compose函數(shù),這個函數(shù)是實現(xiàn)中間件洋蔥模型的關鍵// 場景模擬// 異步 promise 模擬const delay = async () => {return new Promise((resolve, reject) => {setTimeout(() => {resolve();}, 2000);});}// 中間間模擬const fn1 = async (ctx, next) => {console.log(1);await next();console.log(2);}const fn2 = async (ctx, next) => {console.log(3);await delay();await next();console.log(4);}const fn3 = async (ctx, next) => {console.log(5);}const middlewares = [fn1, fn2, fn3];// compose 實現(xiàn)洋蔥模型const compose = (middlewares, ctx) => {const dispatch = (i) => {let fn = middlewares[i];if(!fn){ return Promise.resolve() }return Promise.resolve(fn(ctx, () => {return dispatch(i+1);}));}return dispatch(0);}compose(middlewares, 1);
9、其它
現(xiàn)在在重新過一遍node 12版本的主要API,有很多新發(fā)現(xiàn),比如說
fs.watch這個模塊,事件的回調(diào)函數(shù)有一個參數(shù)是觸發(fā)的事件名稱,但是呢,無論我增刪改,都是觸發(fā)rename事件(如果更改是update事件,刪除delete事件,重命名是rename事件,這樣語義明晰該多好)。
后來網(wǎng)上找到一個node-watch模塊,此模塊增刪改都有對應的事件, 并且還高效的支持遞歸watch 文件。
util模塊有個promisify方法,可以讓一個遵循異常優(yōu)先的回調(diào)風格的函數(shù),即 (err, value) => ... 回調(diào)函數(shù)是最后一個參數(shù),返回一個返回值是一個 promise 版本的函數(shù)。
const util = require('util');const fs = require('fs');const stat = util.promisify(fs.stat);stat('.').then((stats) => {// 處理 `stats`。}).catch((error) => {// 處理錯誤。});
9.1 雜想
crypto模塊,可以考察基礎的加密學知識,比如摘要算法有哪些(md5, sha1, sha256,加鹽的md5,sha256等等),接著可以問如何用md5自己模擬一個加鹽的md5算法, 接著可以問加密算法(crypto.createCiphe)中的aes,eds算法的區(qū)別,分組加密模式有哪些(比如ECB,CBC,為什么ECB不推薦),node里的分組加密模式是哪種(CMM),這些加密算法里的填充和向量是什么意思,接著可以問數(shù)字簽名和https的流程(為什么需要CA,為什么要對稱加密來加密公鑰等等)
tcp/ip,可以問很多基礎問題,比如鏈路層通過什么協(xié)議根據(jù)IP地址獲取物理地址(arp),網(wǎng)關是什么,ip里的ICMP協(xié)議有什么用,tcp的三次握手,四次分手的過程是什么,tcp如何控制重發(fā),網(wǎng)絡堵塞TCP會怎么辦等等,udp和tcp的區(qū)別,udp里的廣播和組播是什么,組播在node里通過什么模塊實現(xiàn)。
os,操作系統(tǒng)相關基礎,io的流程是什么(從硬盤里讀取數(shù)據(jù)到內(nèi)核的內(nèi)存中,然后內(nèi)核的內(nèi)存將數(shù)據(jù)傳入到調(diào)用io的應用程序的進程內(nèi)存中),馮諾依曼體系是什么,進程和線程的區(qū)別等等(我最近在看馬哥linux教程,因為自己不是科班出身,聽了很多基礎的計算機知識,受益匪淺,建議去bilibili看)
linux相關操作知識(node涉及到后臺,雖然是做中臺,不涉及數(shù)據(jù)庫,但是基本的linux操作還是要會的)
node性能監(jiān)控(自己也正在學習中)
測試,因為用的egg框架,有很完善的學習單元測試的文檔,省略這部分
數(shù)據(jù)庫可以問一些比如事務的等級有哪些,mysql默認的事務等級是什么,會產(chǎn)生什么問題,然后考一些mysql查詢的筆試題。。。和常用優(yōu)化技巧,node的mysql的orm工具使用過沒有。。。
學習更多技能
請點擊下方公眾號
![]()
