
【NLP】下一站,Embodied AI
不知大家有沒有注意到(也可能是我敏感了),最近一些大機(jī)構(gòu)不約而同地開始挖新坑了,兩個(gè)風(fēng)向標(biāo)DeepMind和OpenAI,先后發(fā)布了Gato和VPT,期望除了圖像和文本之外,預(yù)訓(xùn)練模型也能夠與環(huán)境交互。
這個(gè)方向,叫Embodied AI(具象AI)。
與具象AI對立的詞是Internet AI[1],指通過互聯(lián)網(wǎng)上的數(shù)據(jù)進(jìn)行學(xué)習(xí),比如我們一直在做的CV、NLP。而Embodied AI是指從與環(huán)境的交互中學(xué)習(xí)。
NLP+CV+RL,這個(gè)組合大概率是通向終極目標(biāo)的必經(jīng)之路,但我沒想到這么快就要來了。而且隨著預(yù)訓(xùn)練的顛覆,這個(gè)坑變成了:
如何通過互聯(lián)網(wǎng)上豐富的多模態(tài)數(shù)據(jù),訓(xùn)練一個(gè)通用模型,可以根據(jù)指令在環(huán)境中執(zhí)行各種任務(wù)。
上述是我自己給出的問題定義,其中有以下兩個(gè)難點(diǎn):
如何提升學(xué)習(xí)效率:正如LeCun說的,通過與環(huán)境交互學(xué)習(xí)有很大風(fēng)險(xiǎn),效率也低(正向獎(jiǎng)勵(lì)太少),而通過觀察(observation),利用現(xiàn)有數(shù)據(jù)學(xué)習(xí)效率才更高,這樣也可以延續(xù)預(yù)訓(xùn)練-精調(diào)/Prompt的范式,把更多的知識遷移到下游 復(fù)雜的輸入輸出和環(huán)境:在最復(fù)雜的情況下,模型的輸入是多模態(tài)指令,輸出是可以在真實(shí)環(huán)境執(zhí)行的動作。其實(shí)針對Embodied AI的評估有多種任務(wù),比如Navigation、Manipulation、Instruction following,但指令是可以描述所有任務(wù)的,需要更高維的理解。同時(shí),輸出的動作空間大小、環(huán)境是模擬的還是真實(shí)的,都會帶來不同的挑戰(zhàn)
以這兩個(gè)難點(diǎn)為軸,上半年一些機(jī)構(gòu)的進(jìn)展如下:
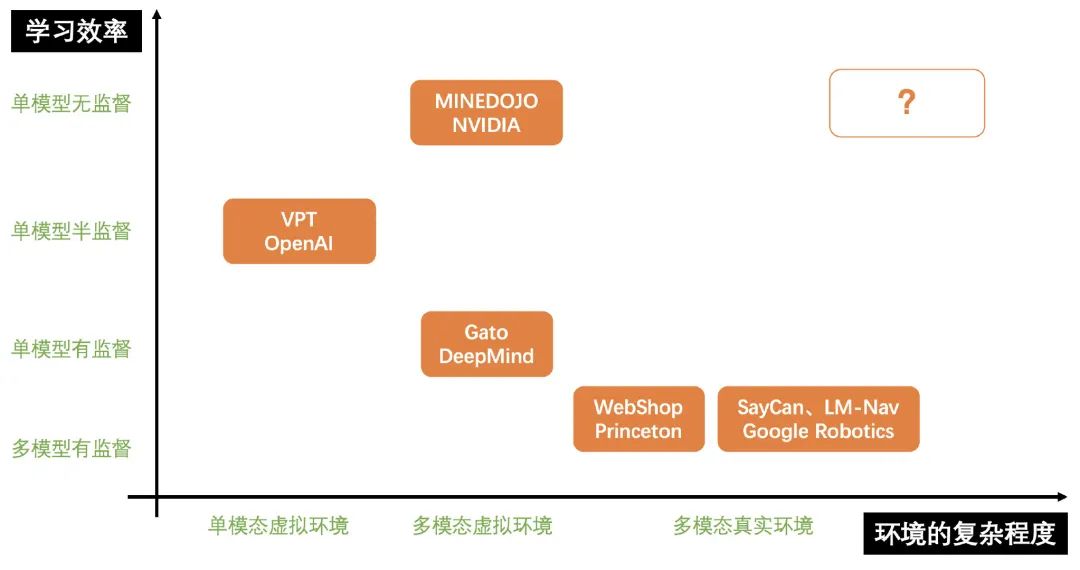
下面就從右下到左上的順序介紹一下這些工作。
P.S. 這些工作大部分都是我近幾個(gè)月在信息流看到的,如有遺漏請留言我。
SayCan、LM-Nav
在今年4月份,Google Robotics團(tuán)隊(duì)發(fā)布了一篇SayCan的工作[2],輸入自然語言指令,讓機(jī)器人在真實(shí)的環(huán)境中執(zhí)行任務(wù)。
Robotics的團(tuán)隊(duì)還是比較偏RL的,作者的方法是搭建了一個(gè)Pipeline:
把指令變成Prompt,利用LM把指令分解成skill,這些skill都是提前用RL訓(xùn)練好的(比如機(jī)械手拿起眼前的物體就是一個(gè)skill) 通過訓(xùn)練好的價(jià)值函數(shù),聯(lián)合LM給出skill的概率分布,執(zhí)行概率最大的 執(zhí)行完第一個(gè)skill之后,再拼接成新的prompt生成第二個(gè)skill
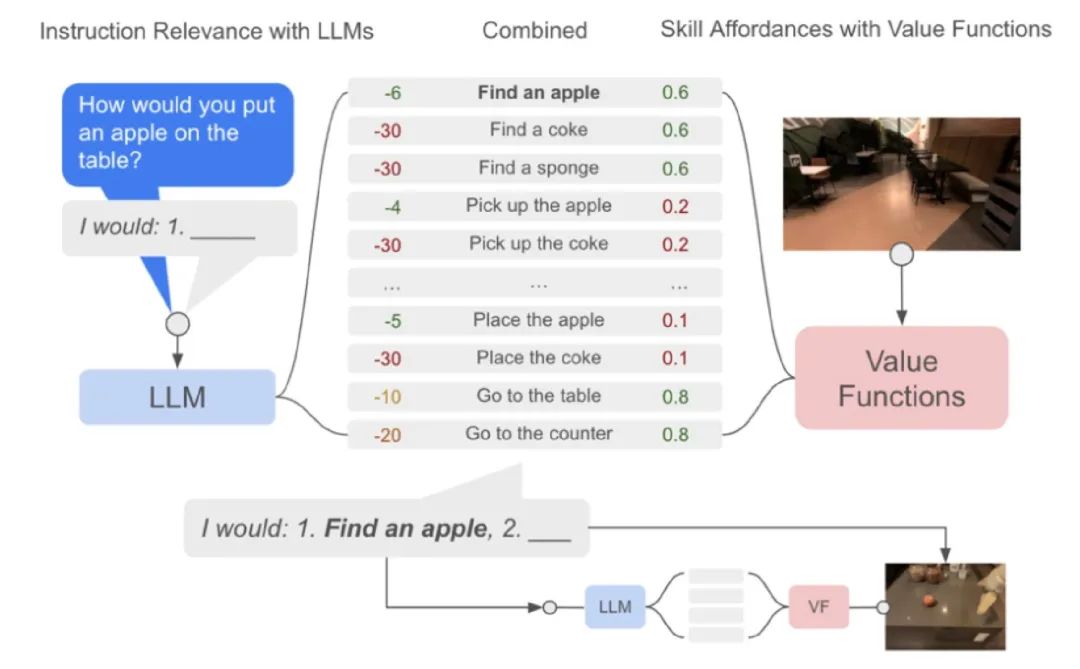
作者雖然能夠在真實(shí)環(huán)境中執(zhí)行任務(wù),但在學(xué)習(xí)效率上還有待提高,每個(gè)skill都是單獨(dú)訓(xùn)練的,只利用了訓(xùn)練好的語言模型來減少學(xué)習(xí)成本。
隨后在7月初,這個(gè)團(tuán)隊(duì)又推出了一篇LM-Nav的工作[3],更加fancy,給小車一個(gè)指令,告訴它往哪走,在哪兒拐,小車就能自己開過去。
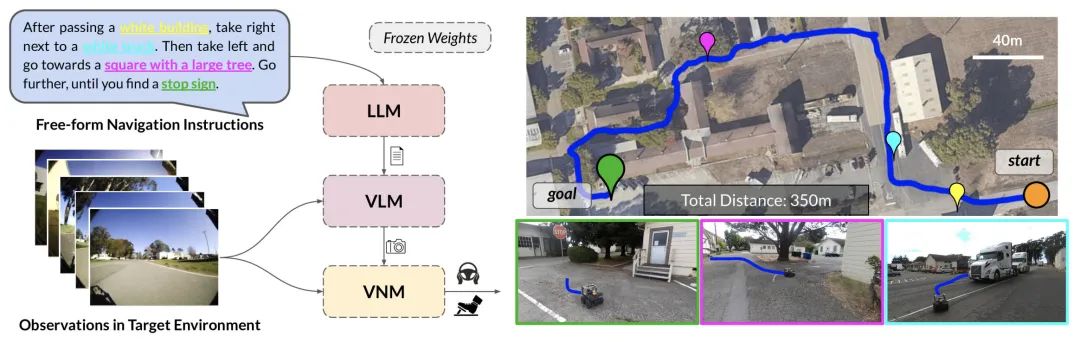
不過作者拆解得也更加復(fù)雜,總共用了三個(gè)模型:

執(zhí)行的流程是:
VNM對環(huán)境進(jìn)行建模 LLM對命令進(jìn)行拆解 VLM對環(huán)境進(jìn)行解析 把1和3結(jié)合起來,搜索最佳路徑 用VNM執(zhí)行
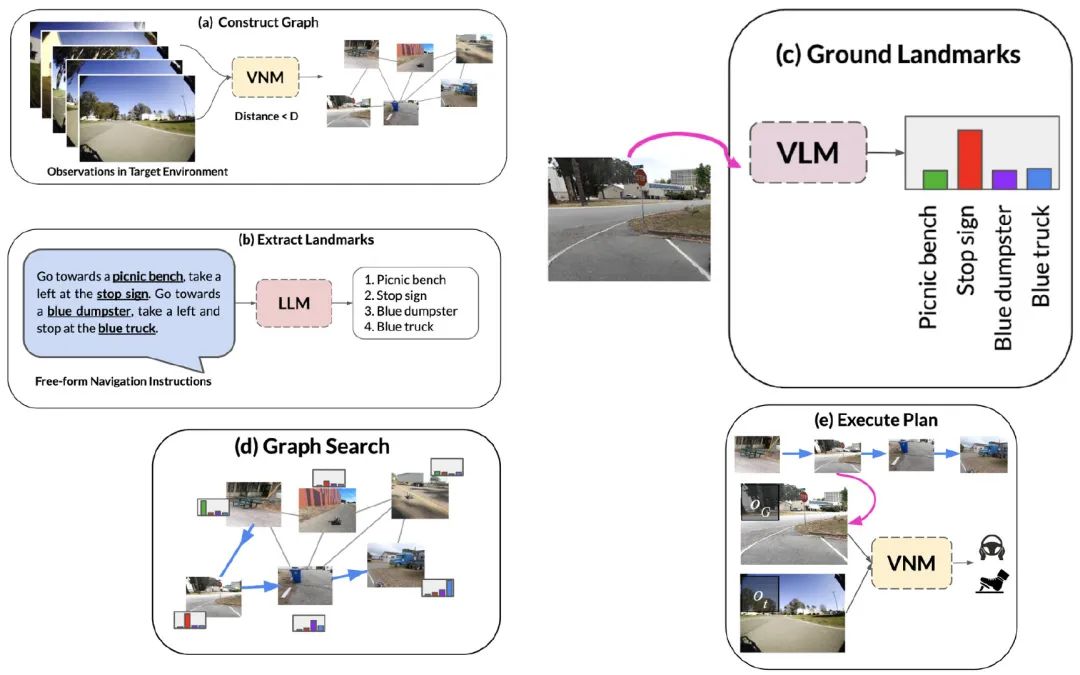
做Robotics的團(tuán)隊(duì)還是很強(qiáng)的,做完了就真的能直接在現(xiàn)實(shí)里跑起來,不過解決方案的效率離終極目標(biāo)還有些距離。下面介紹的工作基本都是在虛擬環(huán)境中嘗試了。
WebShop
WebShop[4]是7月份普林斯頓剛出的工作,作者做了一個(gè)簡化版的電商APP,學(xué)習(xí)如何根據(jù)用戶需求去下單商品。真正放到亞馬遜上使用后成功率有27%,跟測試的28%很接近,不夠本事就都是「虛擬環(huán)境」,比起上篇工作的復(fù)雜度還是弱一些。
作者也是通過Pipeline方案實(shí)現(xiàn)的:
對于輸入的指令,用seq2seq模型生成搜索query 因?yàn)閯幼骺臻g比較有限,作者訓(xùn)練了一個(gè)選擇模型,分別給每個(gè)動作進(jìn)行打分得到 S(o,a),從而采樣出下一步動作,如下圖
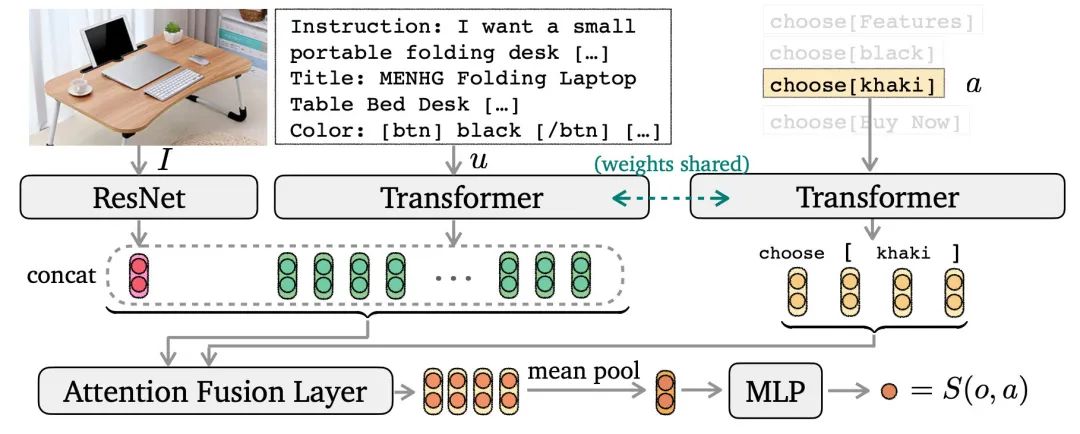
這份工作也是很好的嘗試,除了真實(shí)環(huán)境之外,與手機(jī)、電腦的交互占據(jù)了我們生活中大部分時(shí)間,提效的第三方個(gè)性化工具也是有些發(fā)展前景的。
Gato
Gato[5]是DeepMind在5月份發(fā)表的工作,當(dāng)時(shí)還是蠻刷屏的,如果說上面兩個(gè)工作都仍舊把Embodied AI拆解成多模態(tài)理解+RL模型執(zhí)行,那Gato則是證明了一個(gè)模型就可以做所有事情。
作者讓一個(gè)自回歸模型承擔(dān)所有,包括打游戲(RL)、圖像說明、聊天
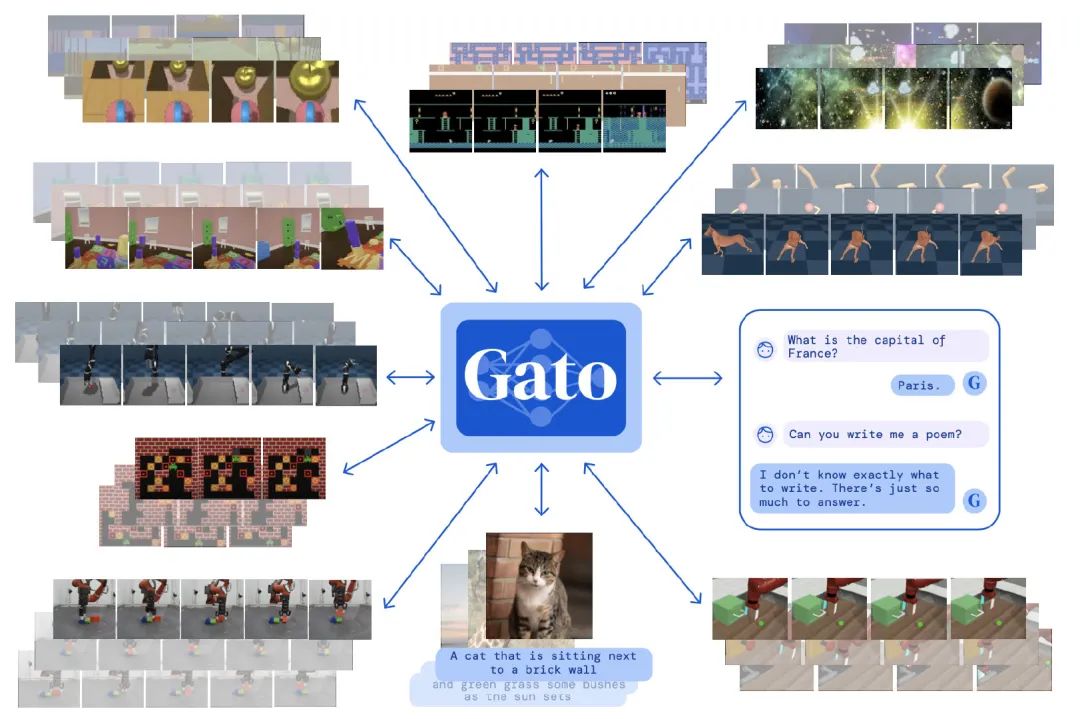
不過在學(xué)習(xí)打游戲時(shí),是利用其他SOTA的強(qiáng)化模型直接生成的監(jiān)督數(shù)據(jù)。
雖然在數(shù)據(jù)利用上沒有延續(xù)預(yù)訓(xùn)練的范式,但終于完成了由Pipeline到End2End的突破。
VPT
VPT[6]是OpenAI在6月底提出的工作,就是那個(gè)在「我的世界」里玩的賊6的agent。
OpenAI延續(xù)了以往的風(fēng)格,自回歸 is all you need。
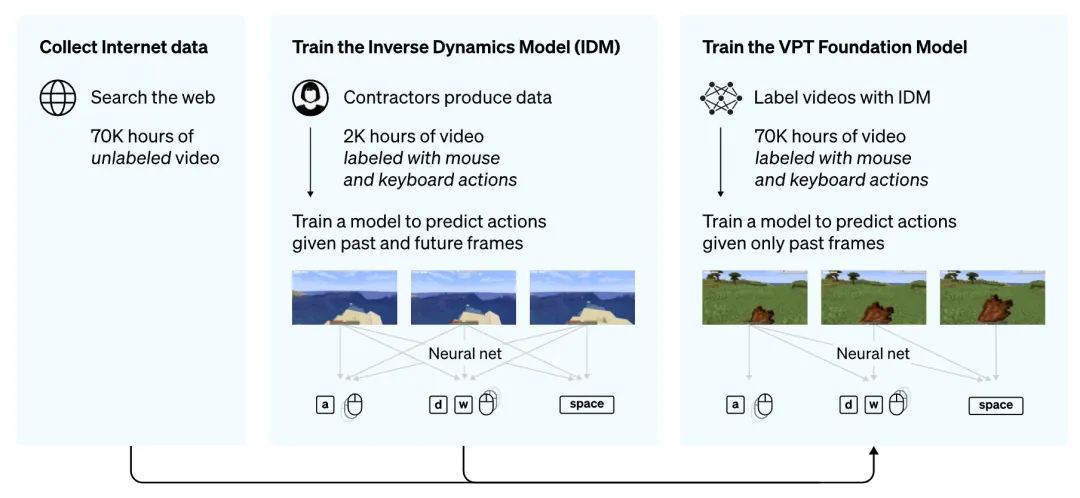
最粗暴的想法,就是輸入圖像,預(yù)測下一幀,但下一幀圖像怎么映射成動作呢?
于是作者先訓(xùn)練了一個(gè)反向模型IDM(inverse dynamics model),輸入雙向上下文視頻,預(yù)測當(dāng)前幀對應(yīng)的鍵盤和鼠標(biāo)動作。訓(xùn)練完了之后給8年長的視頻進(jìn)行標(biāo)注,這樣監(jiān)督數(shù)據(jù)就都有了。
于是延續(xù)老方法,自回歸一把梭,訓(xùn)出了一個(gè)LM,根據(jù)輸入的幀序列,預(yù)測未來的動作,就把游戲給玩6了。
這個(gè)工作也把圖像理解和動作預(yù)測結(jié)合到了一起,但輸入沒有指令,復(fù)雜程度還差一些。也可能是發(fā)布的比較倉促,因?yàn)榫驮谶@篇工作的前6天,英偉達(dá)發(fā)布了同樣以「我的世界」為基礎(chǔ)的MINEDOJO。
MINEDOJO
英偉達(dá)在6月中發(fā)布的MINEDOJO[7]是我目前個(gè)人最喜歡的一篇工作,比起VPT它有兩個(gè)優(yōu)點(diǎn):
無監(jiān)督,學(xué)習(xí)效率更高 指令作為輸入,更加復(fù)雜
英偉達(dá)更多的還是從RL的角度來思考解決方案,RL最重要的就是獎(jiǎng)勵(lì)函數(shù),它作為監(jiān)督信號,會影響模型的動作,從而決定是否能采樣到有效數(shù)據(jù)。
于是作者提出了MINECLIP模型,利用CLIP的思路進(jìn)行預(yù)訓(xùn)練,計(jì)算視頻和文本指令的相似度,作為RL的獎(jiǎng)勵(lì)值,有種生成器-判別器的感覺。
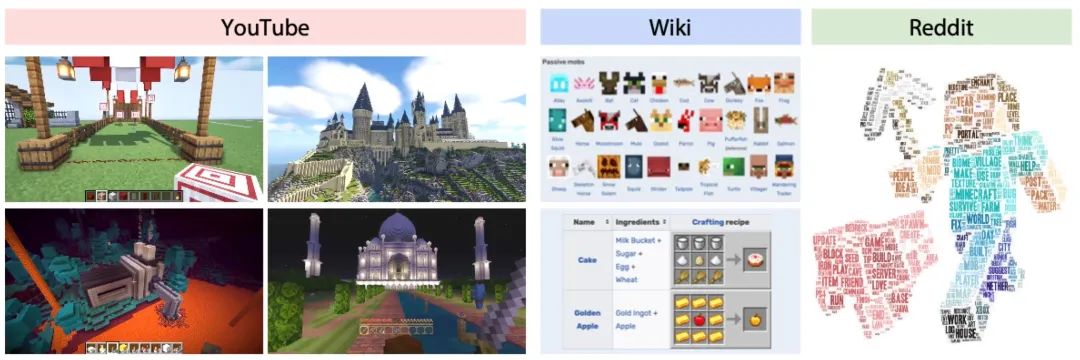
同時(shí),相比起OpenAI整理的8年視頻數(shù)據(jù),英偉達(dá)收集了MineCraft相關(guān)的33年的視頻、6k+維基百科、百萬級別的reddit討論,全部都開源出來了,真是太良心。
總結(jié)
最近業(yè)余時(shí)間主要關(guān)注了一些Embodied AI的工作,同時(shí)也給了我其他啟發(fā):如果說數(shù)據(jù)是算法的天花板,那現(xiàn)在的瓶頸,比如推理、常識學(xué)習(xí),原因可能在于現(xiàn)有數(shù)據(jù)的多樣性?
視覺、聽覺、觸覺都是我們認(rèn)識世界的途徑之一,他們之間的聯(lián)系也會讓我們加深理解,把模態(tài)疊加起來,讓模型不斷接近我們的現(xiàn)實(shí)世界,或許是突破單模態(tài)任務(wù)瓶頸的方法。
另外,這個(gè)方向也催生了另外一門生意,還記得靠模型和數(shù)據(jù)起家估值20億的HuggingFace嗎?到了Embodied AI時(shí)代,虛擬環(huán)境就是必需品了,OpenAI、英偉達(dá)、AllenAI都發(fā)布了他們的虛擬環(huán)境,能否滋生一個(gè)新的生態(tài),未來可期。
參考資料
A Survey of Embodied AI: From Simulators to Research Tasks: https://arxiv.org/abs/2103.04918v5
[2]Do As I Can, Not As I Say: Grounding Language in Robotic Affordances : https://arxiv.org/abs/2204.01691
[3]LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action: https://arxiv.org/abs/2207.04429
[4]WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents: https://arxiv.org/abs/2207.01206v1
[5]A Generalist Agent: https://arxiv.org/abs/2205.06175
[6]Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos: https://arxiv.org/abs/2206.11795
[7]MINEDOJO: Building Open-Ended Embodied Agents with Internet-Scale Knowledge: https://arxiv.org/abs/2206.08853v1
往期精彩回顧