
計(jì)算機(jī)網(wǎng)絡(luò)知識(shí)總結(jié)

應(yīng)用層
HTTP 是超文本傳輸協(xié)議,它定義了客戶端和服務(wù)器之間交換報(bào)文的格式和方式,默認(rèn)使用 80 端口。它使用 TCP 作為傳 輸層協(xié)議,保證了數(shù)據(jù)傳輸?shù)目煽啃浴?/span>
HTTP 是一個(gè)無狀態(tài)的協(xié)議,HTTP 服務(wù)器不會(huì)保存關(guān)于客戶的任何信息。
HTTP 有兩種連接模式,一種是持續(xù)連接,一種非持續(xù)連接。非持續(xù)連接指的是服務(wù)器必須為每一個(gè)請(qǐng)求的對(duì)象建立和維護(hù) 一個(gè)全新的連接。
持續(xù)連接下,TCP 連接默認(rèn)不關(guān)閉,可以被多個(gè)請(qǐng)求復(fù)用。采用持續(xù)連接的好處是可以避免每次建立 TCP 連接三次握手時(shí)所花費(fèi)的時(shí)間。
在 HTTP1.0 以前使用的非持續(xù)的連接,但是可以在請(qǐng)求時(shí),加上 Connection: keep-a live 來要求服務(wù)器不要關(guān)閉 TCP 連接。HTTP1.1 以后默認(rèn)采用的是持續(xù)的連接。目前對(duì)于同一個(gè)域,大多數(shù)瀏覽器支持 同時(shí)建立 6 個(gè)持久連接。
HTTP 請(qǐng)求報(bào)文
HTTP 報(bào)文有兩種,一種是請(qǐng)求報(bào)文,一種是響應(yīng)報(bào)文。
HTTP 請(qǐng)求報(bào)文的格式如下:
GET / HTTP/1.1User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)Accept: */*
HTTP 請(qǐng)求報(bào)文的第一行叫做請(qǐng)求行,后面的行叫做首部行,首部行后還可以跟一個(gè)實(shí)體主體。請(qǐng)求首部之后有一個(gè)空行,這 個(gè)空行不能省略,它用來劃分首部與實(shí)體。
請(qǐng)求行包含三個(gè)字段:方法字段、URL 字段和 HTTP 版本字段。
方法字段可以取幾種不同的值,一般有 GET、POST、HEAD、PUT 和 DELETE。一般 GET 方法只被用于向服務(wù)器獲取數(shù)據(jù)。
POST 方法用于將實(shí)體提交到指定的資源,通常會(huì)造成服務(wù)器資源的修改。
HEAD 方法與 GET 方法類似,但是在返回的響應(yīng) 中,不包含請(qǐng)求對(duì)象。PUT 方法用于上傳文件到服務(wù)器,DELETE 方法用于刪除服務(wù)器上的對(duì)象。
雖然請(qǐng)求的方法很多,但 更多表達(dá)的是一種語義上的區(qū)別,并不是說 POST 能做的事情,GET 就不能做了,主要看我們?nèi)绾芜x擇。更多的方法可以參 看文檔。
HTTP 響應(yīng)報(bào)文
HTTP 報(bào)文有兩種,一種是請(qǐng)求報(bào)文,一種是響應(yīng)報(bào)文。
HTTP 響應(yīng)報(bào)文的格式如下:
HTTP/1.0 200 OKContent-Type: text/plainContent-Length: 137582Expires: Thu, 05 Dec 1997 16:00:00 GMTLast-Modified: Wed, 5 August 1996 15:55:28 GMTServer: Apache 0.84<html><body>Hello World</body></html>
HTTP 響應(yīng)報(bào)文的第一行叫做狀態(tài)行,后面的行是首部行,最后是實(shí)體主體。
狀態(tài)行包含了三個(gè)字段:協(xié)議版本字段、狀態(tài)碼和相應(yīng)的狀態(tài)信息。
實(shí)體部分是報(bào)文的主要部分,它包含了所請(qǐng)求的對(duì)象。
常見的狀態(tài)有
200-請(qǐng)求成功、202-服務(wù)器端已經(jīng)收到請(qǐng)求消息,但是尚未進(jìn)行處理 301-永久移動(dòng)、302-臨時(shí)移動(dòng)、304-所請(qǐng)求的資源未修改、 400-客戶端請(qǐng)求的語法錯(cuò)誤、404-請(qǐng)求的資源不存在 500-服務(wù)器內(nèi)部錯(cuò)誤。
一般 1XX 代表服務(wù)器接收到請(qǐng)求、2XX 代表成功、3XX 代表重定向、4XX 代表客戶端錯(cuò)誤、5XX 代表服務(wù)器端錯(cuò)誤。
更多關(guān)于狀態(tài)碼的可以查看:
《HTTP 狀態(tài)碼》
首部行
首部可以分為四種首部,請(qǐng)求首部、響應(yīng)首部、通用首部和實(shí)體首部。通用首部和實(shí)體首部在請(qǐng)求報(bào)文和響應(yīng)報(bào)文中都可以設(shè) 置,區(qū)別在于請(qǐng)求首部和響應(yīng)首部。
常見的請(qǐng)求首部有 Accept 可接收媒體資源的類型、Accept-Charset 可接收的字符集、Host 請(qǐng)求的主機(jī)名。
常見的響應(yīng)首部有 ETag 資源的匹配信息,Location 客戶端重定向的 URI。
常見的通用首部有 Cache-Control 控制緩存策略、Connection 管理持久連接。
常見的實(shí)體首部有 Content-Length 實(shí)體主體的大小、Expires 實(shí)體主體的過期時(shí)間、Last-Modified 資源的最后修 改時(shí)間。
更多關(guān)于首部的資料可以查看:
《HTTP 首部字段詳細(xì)介紹》
《圖解 HTTP》
HTTP/1.1 協(xié)議缺點(diǎn)
HTTP/1.1 默認(rèn)使用了持久連接,多個(gè)請(qǐng)求可以復(fù)用同一個(gè) TCP 連接,但是在同一個(gè) TCP 連接里面,數(shù)據(jù)請(qǐng)求的通信次序 是固定的。服務(wù)器只有處理完一個(gè)請(qǐng)求的響應(yīng)后,才會(huì)進(jìn)行下一個(gè)請(qǐng)求的處理,如果前面請(qǐng)求的響應(yīng)特別慢的話,就會(huì)造成許 多請(qǐng)求排隊(duì)等待的情況,這種情況被稱為“隊(duì)頭堵塞”。隊(duì)頭阻塞會(huì)導(dǎo)致持久連接在達(dá)到最大數(shù)量時(shí),剩余的資源需要等待其他 資源請(qǐng)求完成后才能發(fā)起請(qǐng)求。
為了避免這個(gè)問題,一個(gè)是減少請(qǐng)求數(shù),一個(gè)是同時(shí)打開多個(gè)持久連接。這就是我們對(duì)網(wǎng)站優(yōu)化時(shí),使用雪碧圖、合并腳本的 原因。
HTTP/2 協(xié)議
2009 年,谷歌公開了自行研發(fā)的 SPDY 協(xié)議,主要解決 HTTP/1.1 效率不高的問題。這個(gè)協(xié)議在 Chrome 瀏覽器上證明 可行以后,就被當(dāng)作 HTTP/2 的基礎(chǔ),主要特性都在 HTTP/2 之中得到繼承。2015 年,HTTP/2 發(fā)布。
HTTP/2 主要有以下新的特性:
二進(jìn)制協(xié)議
HTTP/2 是一個(gè)二進(jìn)制協(xié)議。在 HTTP/1.1 版中,報(bào)文的頭信息必須是文本(ASCII 編碼),數(shù)據(jù)體可以是文本,也可以是 二進(jìn)制。HTTP/2 則是一個(gè)徹底的二進(jìn)制協(xié)議,頭信息和數(shù)據(jù)體都是二進(jìn)制,并且統(tǒng)稱為"幀",可以分為頭信息幀和數(shù)據(jù)幀。幀的概念是它實(shí)現(xiàn)多路復(fù)用的基礎(chǔ)。
多路復(fù)用
HTTP/2 實(shí)現(xiàn)了多路復(fù)用,HTTP/2 仍然復(fù)用 TCP 連接,但是在一個(gè)連接里,客戶端和服務(wù)器都可以同時(shí)發(fā)送多個(gè)請(qǐng)求或回 應(yīng),而且不用按照順序一一發(fā)送,這樣就避免了"隊(duì)頭堵塞"的問題。
數(shù)據(jù)流
HTTP/2 使用了數(shù)據(jù)流的概念,因?yàn)?HTTP/2 的數(shù)據(jù)包是不按順序發(fā)送的,同一個(gè)連接里面連續(xù)的數(shù)據(jù)包,可能屬于不同的 請(qǐng)求。因此,必須要對(duì)數(shù)據(jù)包做標(biāo)記,指出它屬于哪個(gè)請(qǐng)求。
HTTP/2 將每個(gè)請(qǐng)求或回應(yīng)的所有數(shù)據(jù)包,稱為一個(gè)數(shù)據(jù)流。每 個(gè)數(shù)據(jù)流都有一個(gè)獨(dú)一無二的編號(hào)。數(shù)據(jù)包發(fā)送的時(shí)候,都必須標(biāo)記數(shù)據(jù)流 ID ,用來區(qū)分它屬于哪個(gè)數(shù)據(jù)流。
頭信息壓縮
HTTP/2 實(shí)現(xiàn)了頭信息壓縮,由于 HTTP 1.1 協(xié)議不帶有狀態(tài),每次請(qǐng)求都必須附上所有信息。
所以,請(qǐng)求的很多字段都是 重復(fù)的,比如 Cookie 和 User Agent ,一模一樣的內(nèi)容,每次請(qǐng)求都必須附帶,這會(huì)浪費(fèi)很多帶寬,也影響速度。
HTTP/2 對(duì)這一點(diǎn)做了優(yōu)化,引入了頭信息壓縮機(jī)制。一方面,頭信息使用 gzip 或 compress 壓縮后再發(fā)送;另一方面, 客戶端和服務(wù)器同時(shí)維護(hù)一張頭信息表,所有字段都會(huì)存入這個(gè)表,生成一個(gè)索引號(hào),以后就不發(fā)送同樣字段了,只發(fā)送索引 號(hào),這樣就能提高速度了。
服務(wù)器推送
HTTP/2 允許服務(wù)器未經(jīng)請(qǐng)求,主動(dòng)向客戶端發(fā)送資源,這叫做服務(wù)器推送。使用服務(wù)器推送,提前給客戶端推送必要的資源 ,這樣就可以相對(duì)減少一些延遲時(shí)間。這里需要注意的是 http2 下服務(wù)器主動(dòng)推送的是靜態(tài)資源,和 WebSocket 以及使用 SSE 等方式向客戶端發(fā)送即時(shí)數(shù)據(jù)的推送是不同的。
詳細(xì)的資料可以參考: 《HTTP 協(xié)議入門》 《HTTP/2 服務(wù)器推送(Server Push)教程》
HTTP/2 協(xié)議缺點(diǎn)
因?yàn)?HTTP/2 使用了多路復(fù)用,一般來說同一域名下只需要使用一個(gè) TCP 連接。由于多個(gè)數(shù)據(jù)流使用同一個(gè) TCP 連接,遵 守同一個(gè)流量狀態(tài)控制和擁塞控制。
只要一個(gè)數(shù)據(jù)流遭遇到擁塞,剩下的數(shù)據(jù)流就沒法發(fā)出去,這樣就導(dǎo)致了后面的所有數(shù)據(jù)都 會(huì)被阻塞。
HTTP/2 出現(xiàn)的這個(gè)問題是由于其使用 TCP 協(xié)議的問題,與它本身的實(shí)現(xiàn)其實(shí)并沒有多大關(guān)系。
HTTP/3 協(xié)議
由于 TCP 本身存在的一些限制,Google 就開發(fā)了一個(gè)基于 UDP 協(xié)議的 QUIC 協(xié)議,并且使用在了 HTTP/3 上。QUIC 協(xié)議在 UDP 協(xié)議上實(shí)現(xiàn)了多路復(fù)用、有序交付、重傳等等功能
詳細(xì)資料可以參考: 《如何看待 HTTP/3 ?》
HTTPS 協(xié)議
HTTP 存在的問題
HTTP 報(bào)文使用明文方式發(fā)送,可能被第三方竊聽。
HTTP 報(bào)文可能被第三方截取后修改通信內(nèi)容,接收方?jīng)]有辦法發(fā)現(xiàn)報(bào)文內(nèi)容的修改。
HTTP 還存在認(rèn)證的問題,第三方可以冒充他人參與通信。
第一步,客戶端向服務(wù)器發(fā)起請(qǐng)求,請(qǐng)求中包含使用的協(xié)議版本號(hào)、生成的一個(gè)隨機(jī)數(shù)、以及客戶端支持的加密方法。 第二步,服務(wù)器端接收到請(qǐng)求后,確認(rèn)雙方使用的加密方法、并給出服務(wù)器的證書、以及一個(gè)服務(wù)器生成的隨機(jī)數(shù)。 第三步,客戶端確認(rèn)服務(wù)器證書有效后,生成一個(gè)新的隨機(jī)數(shù),并使用數(shù)字證書中的公鑰,加密這個(gè)隨機(jī)數(shù),然后發(fā)給服 務(wù)器。并且還會(huì)提供一個(gè)前面所有內(nèi)容的 hash 的值,用來供服務(wù)器檢驗(yàn)。 第四步,服務(wù)器使用自己的私鑰,來解密客戶端發(fā)送過來的隨機(jī)數(shù)。并提供前面所有內(nèi)容的 hash 值來供客戶端檢驗(yàn)。 第五步,客戶端和服務(wù)器端根據(jù)約定的加密方法使用前面的三個(gè)隨機(jī)數(shù),生成對(duì)話秘鑰,以后的對(duì)話過程都使用這個(gè)秘鑰 來加密信息。
主機(jī)名.次級(jí)域名.頂級(jí)域名.根域名# 即host.sld.tld.root
根據(jù)域名的層級(jí)結(jié)構(gòu),管理不同層級(jí)域名的服務(wù)器,可以分為根域名服務(wù)器、頂級(jí)域名服務(wù)器和權(quán)威域名服務(wù)器。
查詢過程
DNS 的查詢過程一般為,我們首先將 DNS 請(qǐng)求發(fā)送到本地 DNS 服務(wù)器,由本地 DNS 服務(wù)器來代為請(qǐng)求。
從"根域名服務(wù)器"查到"頂級(jí)域名服務(wù)器"的 NS 記錄和 A 記錄( IP 地址)。
從"頂級(jí)域名服務(wù)器"查到"次級(jí)域名服務(wù)器"的 NS 記錄和 A 記錄( IP 地址)。
從"次級(jí)域名服務(wù)器"查出"主機(jī)名"的 IP 地址。
比如我們?nèi)绻胍樵?www.baidu.com 的 IP 地址,我們首先會(huì)將請(qǐng)求發(fā)送到本地的 DNS 服務(wù)器中,本地 DNS 服務(wù) 器會(huì)判斷是否存在該域名的緩存,如果不存在,則向根域名服務(wù)器發(fā)送一個(gè)請(qǐng)求,根域名服務(wù)器返回負(fù)責(zé) .com 的頂級(jí)域名 服務(wù)器的 IP 地址的列表。
然后本地 DNS 服務(wù)器再向其中一個(gè)負(fù)責(zé) .com 的頂級(jí)域名服務(wù)器發(fā)送一個(gè)請(qǐng)求,負(fù)責(zé) .com 的頂級(jí)域名服務(wù)器返回負(fù)責(zé) .baidu 的權(quán)威域名服務(wù)器的 IP 地址列表。
然后本地 DNS 服務(wù)器再向其中一個(gè)權(quán)威域名服 務(wù)器發(fā)送一個(gè)請(qǐng)求,最后權(quán)威域名服務(wù)器返回一個(gè)對(duì)應(yīng)的主機(jī)名的 IP 地址列表。
DNS 記錄和報(bào)文
DNS 服務(wù)器中以資源記錄的形式存儲(chǔ)信息,每一個(gè) DNS 響應(yīng)報(bào)文一般包含多條資源記錄。一條資源記錄的具體的格式為
(Name,Value,Type,TTL)
其中 TTL 是資源記錄的生存時(shí)間,它定義了資源記錄能夠被其他的 DNS 服務(wù)器緩存多長時(shí)間。
常用的一共有四種 Type 的值,分別是 A、NS、CNAME 和 MX ,不同 Type 的值,對(duì)應(yīng)資源記錄代表的意義不同。
如果 Type = A,則 Name 是主機(jī)名,Value 是主機(jī)名對(duì)應(yīng)的 IP 地址。因此一條記錄為 A 的資源記錄,提供了標(biāo) 準(zhǔn)的主機(jī)名到 IP 地址的映射。
如果 Type = NS,則 Name 是個(gè)域名,Value 是負(fù)責(zé)該域名的 DNS 服務(wù)器的主機(jī)名。這個(gè)記錄主要用于 DNS 鏈?zhǔn)?查詢時(shí),返回下一級(jí)需要查詢的 DNS 服務(wù)器的信息。
如果 Type = CNAME,則 Name 為別名,Value 為該主機(jī)的規(guī)范主機(jī)名。該條記錄用于向查詢的主機(jī)返回一個(gè)主機(jī)名 對(duì)應(yīng)的規(guī)范主機(jī)名,從而告訴查詢主機(jī)去查詢這個(gè)主機(jī)名的 IP 地址。主機(jī)別名主要是為了通過給一些復(fù)雜的主機(jī)名提供 一個(gè)便于記憶的簡單的別名。
如果 Type = MX,則 Name 為一個(gè)郵件服務(wù)器的別名,Value 為郵件服務(wù)器的規(guī)范主機(jī)名。它的作用和 CNAME 是一 樣的,都是為了解決規(guī)范主機(jī)名不利于記憶的缺點(diǎn)。
遞歸查詢和迭代查詢
遞歸查詢指的是查詢請(qǐng)求發(fā)出后,域名服務(wù)器代為向下一級(jí)域名服務(wù)器發(fā)出請(qǐng)求,最后向用戶返回查詢的最終結(jié)果。使用遞歸 查詢,用戶只需要發(fā)出一次查詢請(qǐng)求。
迭代查詢指的是查詢請(qǐng)求后,域名服務(wù)器返回單次查詢的結(jié)果。下一級(jí)的查詢由用戶自己請(qǐng)求。使用迭代查詢,用戶需要發(fā)出 多次的查詢請(qǐng)求。
一般我們向本地 DNS 服務(wù)器發(fā)送請(qǐng)求的方式就是遞歸查詢,因?yàn)槲覀冎恍枰l(fā)出一次請(qǐng)求,然后本地 DNS 服務(wù)器返回給我 們最終的請(qǐng)求結(jié)果。
而本地 DNS 服務(wù)器向其他域名服務(wù)器請(qǐng)求的過程是迭代查詢的過程,因?yàn)槊恳淮斡蛎?wù)器只返回單次 查詢的結(jié)果,下一級(jí)的查詢由本地 DNS 服務(wù)器自己進(jìn)行。
DNS 緩存
DNS 緩存的原理非常簡單,在一個(gè)請(qǐng)求鏈中,當(dāng)某個(gè) DNS 服務(wù)器接收到一個(gè) DNS 回答后,它能夠?qū)⒒卮鹬械男畔⒕彺嬖诒?地存儲(chǔ)器中。返回的資源記錄中的 TTL 代表了該條記錄的緩存的時(shí)間。
DNS 實(shí)現(xiàn)負(fù)載平衡
DNS 可以用于在冗余的服務(wù)器上實(shí)現(xiàn)負(fù)載平衡。因?yàn)楝F(xiàn)在一般的大型網(wǎng)站使用多臺(tái)服務(wù)器提供服務(wù),因此一個(gè)域名可能會(huì)對(duì)應(yīng) 多個(gè)服務(wù)器地址。
當(dāng)用戶發(fā)起網(wǎng)站域名的 DNS 請(qǐng)求的時(shí)候,DNS 服務(wù)器返回這個(gè)域名所對(duì)應(yīng)的服務(wù)器 IP 地址的集合,但在 每個(gè)回答中,會(huì)循環(huán)這些 IP 地址的順序,用戶一般會(huì)選擇排在前面的地址發(fā)送請(qǐng)求。
以此將用戶的請(qǐng)求均衡的分配到各個(gè)不 同的服務(wù)器上,這樣來實(shí)現(xiàn)負(fù)載均衡。
詳細(xì)資料可以參考: 《DNS 原理入門》 《根域名的知識(shí)》
傳輸層
傳輸層協(xié)議主要是為不同主機(jī)上的不同進(jìn)程間提供了邏輯通信的功能。傳輸層只工作在端系統(tǒng)中。
多路復(fù)用與多路分解
將傳輸層報(bào)文段中的數(shù)據(jù)交付到正確的套接字的工作被稱為多路分解。
在源主機(jī)上從不同的套接字中收集數(shù)據(jù),封裝頭信息生成報(bào)文段后,將報(bào)文段傳遞到網(wǎng)絡(luò)層,這個(gè)過程被稱為多路復(fù)用。
無連接的多路復(fù)用和多路分解指的是 UDP 套接字的分配過程,一個(gè) UDP 套接字由一個(gè)二元組來標(biāo)識(shí),這個(gè)二元組包含了一 個(gè)目的地址和一個(gè)目的端口號(hào)。
因此不同源地址和端口號(hào)的 UDP 報(bào)文段到達(dá)主機(jī)后,如果它們擁有相同的目的地址和目的端 口號(hào),那么不同的報(bào)文段將會(huì)轉(zhuǎn)交到同一個(gè) UDP 套接字中。
面向連接的多路復(fù)用和多路分解指的是 TCP 套接字的分配過程,一個(gè) TCP 套接字由一個(gè)四元組來標(biāo)識(shí),這個(gè)四元組包含了 源 IP 地址、源端口號(hào)、目的地址和目的端口號(hào)。
因此,一個(gè) TCP 報(bào)文段從網(wǎng)絡(luò)中到達(dá)一臺(tái)主機(jī)上時(shí),該主機(jī)使用全部 4 個(gè) 值來將報(bào)文段定向到相應(yīng)的套接字。
UDP 協(xié)議
UDP 是一種無連接的,不可靠的傳輸層協(xié)議。它只提供了傳輸層需要實(shí)現(xiàn)的最低限度的功能,除了復(fù)用/分解功能和少量的差 錯(cuò)檢測外,它幾乎沒有對(duì) IP 增加其他的東西。UDP 協(xié)議適用于對(duì)實(shí)時(shí)性要求高的應(yīng)用場景。
特點(diǎn):
使用 UDP 時(shí),在發(fā)送報(bào)文段之前,通信雙方?jīng)]有握手的過程,因此 UDP 被稱為是無連接的傳輸層協(xié)議。因?yàn)闆]有握手 過程,相對(duì)于 TCP 來說,沒有建立連接的時(shí)延。因?yàn)闆]有連接,所以不需要在端系統(tǒng)中保存連接的狀態(tài)。
UDP 提供盡力而為的交付服務(wù),也就是說 UDP 協(xié)議不保證數(shù)據(jù)的可靠交付。
UDP 沒有擁塞控制和流量控制的機(jī)制,所以 UDP 報(bào)文段的發(fā)送速率沒有限制。
因?yàn)橐粋€(gè) UDP 套接字只使用目的地址和目的端口來標(biāo)識(shí),所以 UDP 可以支持一對(duì)一、一對(duì)多、多對(duì)一和多對(duì)多的交互 通信。
UDP 首部小,只有 8 個(gè)字節(jié)。
UDP 報(bào)文段結(jié)構(gòu)
UDP 報(bào)文段由首部和應(yīng)用數(shù)據(jù)組成。報(bào)文段首部包含四個(gè)字段,分別是源端口號(hào)、目的端口號(hào)、長度和檢驗(yàn)和,每個(gè)字段的長 度為兩個(gè)字節(jié)。長度字段指的是整個(gè)報(bào)文段的長度,包含了首部和應(yīng)用數(shù)據(jù)的大小。
校驗(yàn)和是 UDP 提供的一種差錯(cuò)校驗(yàn)機(jī)制。雖然提供了差錯(cuò)校驗(yàn)的機(jī)制,但是 UDP 對(duì)于差錯(cuò)的恢復(fù)無能為力。

TCP 協(xié)議是面向連接的,在通信雙方進(jìn)行通信前,需要通過三次握手建立連接。它需要在端系統(tǒng)中維護(hù)雙方連接的狀態(tài)信息。 TCP 協(xié)議通過序號(hào)、確認(rèn)號(hào)、定時(shí)重傳、檢驗(yàn)和等機(jī)制,來提供可靠的數(shù)據(jù)傳輸服務(wù)。 TCP 協(xié)議提供的是點(diǎn)對(duì)點(diǎn)的服務(wù),即它是在單個(gè)發(fā)送方和單個(gè)接收方之間的連接。 TCP 協(xié)議提供的是全雙工的服務(wù),也就是說連接的雙方的能夠向?qū)Ψ桨l(fā)送和接收數(shù)據(jù)。 TCP 提供了擁塞控制機(jī)制,在網(wǎng)絡(luò)擁塞的時(shí)候會(huì)控制發(fā)送數(shù)據(jù)的速率,有助于減少數(shù)據(jù)包的丟失和減輕網(wǎng)絡(luò)中的擁塞程度。 TCP 提供了流量控制機(jī)制,保證了通信雙方的發(fā)送和接收速率相同。如果接收方可接收的緩存很小時(shí),發(fā)送方會(huì)降低發(fā)送 速率,避免因?yàn)榫彺嫣顫M而造成的數(shù)據(jù)包的丟失。

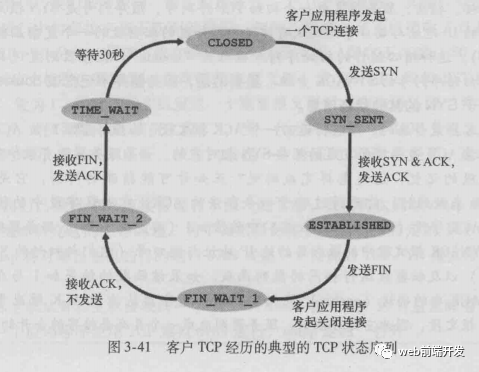
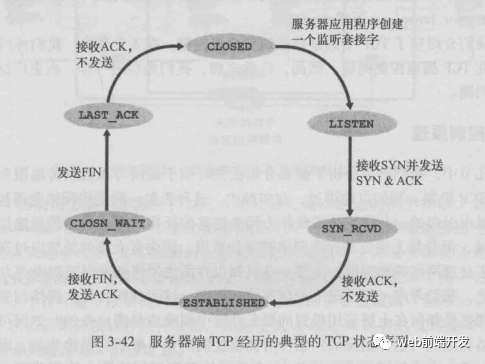
滑動(dòng)窗口協(xié)議
選擇重傳協(xié)議
Post 和 Get 是 HTTP 請(qǐng)求的兩種方法。(1)從應(yīng)用場景上來說,GET 請(qǐng)求是一個(gè)冪等的請(qǐng)求,一般 Get 請(qǐng)求用于對(duì)服務(wù)器資源不會(huì)產(chǎn)生影響的場景,比如說請(qǐng)求一個(gè)網(wǎng)頁。而 Post 不是一個(gè)冪等的請(qǐng)求,一般用于對(duì)服務(wù)器資源會(huì)產(chǎn)生影響的情景。比如注冊(cè)用戶這一類的操作。(2)因?yàn)椴煌膽?yīng)用場景,所以瀏覽器一般會(huì)對(duì) Get 請(qǐng)求緩存,但很少對(duì) Post 請(qǐng)求緩存。(3)從發(fā)送的報(bào)文格式來說,Get 請(qǐng)求的報(bào)文中實(shí)體部分為空,Post 請(qǐng)求的報(bào)文中實(shí)體部分一般為向服務(wù)器發(fā)送的數(shù)據(jù)。(4)但是 Get 請(qǐng)求也可以將請(qǐng)求的參數(shù)放入 url 中向服務(wù)器發(fā)送,這樣的做法相對(duì)于 Post 請(qǐng)求來說,一個(gè)方面是不太安全,因?yàn)檎?qǐng)求的 url 會(huì)被保留在歷史記錄中。并且瀏覽器由于對(duì) url 有一個(gè)長度上的限制,所以會(huì)影響 get 請(qǐng)求發(fā)送數(shù)據(jù)時(shí)的長度。這個(gè)限制是瀏覽器規(guī)定的,并不是 RFC 規(guī)定的。還有就是 post 的參數(shù)傳遞支持更多的數(shù)據(jù)類型。
2、TLS/SSL 中什么一定要用三個(gè)隨機(jī)數(shù),來生成"會(huì)話密鑰"?
客戶端和服務(wù)器都需要生成隨機(jī)數(shù),以此來保證每次生成的秘鑰都不相同。使用三個(gè)隨機(jī)數(shù),是因?yàn)?SSL 的協(xié)議默認(rèn)不信任每個(gè)主機(jī)都能產(chǎn)生完全隨機(jī)的數(shù),如果只使用一個(gè)偽隨機(jī)的數(shù)來生成秘鑰,就很容易被破解。通過使用三個(gè)隨機(jī)數(shù)的方式,增加了自由度,一個(gè)偽隨機(jī)可能被破解,但是三個(gè)偽隨機(jī)就很接近于隨機(jī)了,因此可以使用這種方法來保持生成秘鑰的隨機(jī)性和安全性。
3、SSL 連接斷開后如何恢復(fù)?
一共有兩種方法來恢復(fù)斷開的 SSL 連接,一種是使用 session ID,一種是 session ticket。使用 session ID 的方式,每一次的會(huì)話都有一個(gè)編號(hào),當(dāng)對(duì)話中斷后,下一次重新連接時(shí),只要客戶端給出這個(gè)編號(hào),服務(wù)器如果有這個(gè)編號(hào)的記錄,那么雙方就可以繼續(xù)使用以前的秘鑰,而不用重新生成一把。目前所有的瀏覽器都支持這一種方法。但是這種方法有一個(gè)缺點(diǎn)是,session ID 只能夠存在一臺(tái)服務(wù)器上,如果我們的請(qǐng)求通過負(fù)載平衡被轉(zhuǎn)移到了其他的服務(wù)器上,那么就無法恢復(fù)對(duì)話。另一種方式是 session ticket 的方式,session ticket 是服務(wù)器在上一次對(duì)話中發(fā)送給客戶的,這個(gè) ticket 是加密的,只有服務(wù)器能夠解密,里面包含了本次會(huì)話的信息,比如對(duì)話秘鑰和加密方法等。這樣不管我們的請(qǐng)求是否轉(zhuǎn)移到其他的服務(wù)器上,當(dāng)服務(wù)器將 ticket 解密以后,就能夠獲取上次對(duì)話的信息,就不用重新生成對(duì)話秘鑰了。
對(duì)極大整數(shù)做因數(shù)分解的難度決定了 RSA 算法的可靠性。換言之,對(duì)一極大整數(shù)做因數(shù)分解愈困難,RSA 算法愈可靠。現(xiàn)在1024位的 RSA 密鑰基本安全,2048位的密鑰極其安全。
DNS 使用 UDP 協(xié)議作為傳輸層協(xié)議的主要原因是為了避免使用 TCP 協(xié)議時(shí)造成的連接時(shí)延。因?yàn)闉榱说玫揭粋€(gè)域名的 IP 地址,往往會(huì)向多個(gè)域名服務(wù)器查詢,如果使用 TCP 協(xié)議,那么每次請(qǐng)求都會(huì)存在連接時(shí)延,這樣使 DNS 服務(wù)變得很慢,因?yàn)榇?/span>多數(shù)的地址查詢請(qǐng)求,都是瀏覽器請(qǐng)求頁面時(shí)發(fā)出的,這樣會(huì)造成網(wǎng)頁的等待時(shí)間過長。使用 UDP 協(xié)議作為 DNS 協(xié)議會(huì)有一個(gè)問題,由于歷史原因,物理鏈路的最小MTU = 576,所以為了限制報(bào)文長度不超過576,UDP 的報(bào)文段的長度被限制在 512 個(gè)字節(jié)以內(nèi),這樣一旦 DNS 的查詢或者應(yīng)答報(bào)文,超過了 512 字節(jié),那么基于 UDP 的DNS 協(xié)議就會(huì)被截?cái)酁?512 字節(jié),那么有可能用戶得到的 DNS 應(yīng)答就是不完整的。這里 DNS 報(bào)文的長度一旦超過限制,并不會(huì)像 TCP 協(xié)議那樣被拆分成多個(gè)報(bào)文段傳輸,因?yàn)?UDP 協(xié)議不會(huì)維護(hù)連接狀態(tài),所以我們沒有辦法確定那幾個(gè)報(bào)文段屬于同一個(gè)數(shù)據(jù),UDP 只會(huì)將多余的數(shù)據(jù)給截取掉。為了解決這個(gè)問題,我們可以使用 TCP 協(xié)議去請(qǐng)求報(bào)文。DNS 還存在的一個(gè)問題是安全問題,就是我們沒有辦法確定我們得到的應(yīng)答,一定是一個(gè)安全的應(yīng)答,因?yàn)閼?yīng)答可以被他人偽造,所以現(xiàn)在有了 DNS over HTTPS 來解決這個(gè)問題。
詳細(xì)資料可以參考: 《為什么 DNS 使用 UDP 而不是 TCP?》
6、當(dāng)你在瀏覽器中輸入 Google.com 并且按下回車之后發(fā)生了什么?
(1)首先會(huì)對(duì) URL 進(jìn)行解析,分析所需要使用的傳輸協(xié)議和請(qǐng)求的資源的路徑。如果輸入的 URL 中的協(xié)議或者主機(jī)名不合法,將會(huì)把地址欄中輸入的內(nèi)容傳遞給搜索引擎。如果沒有問題,瀏覽器會(huì)檢查 URL 中是否出現(xiàn)了非法字符,如果存在非法字符,則對(duì)非法字符進(jìn)行轉(zhuǎn)義后再進(jìn)行下一過程。(2)瀏覽器會(huì)判斷所請(qǐng)求的資源是否在緩存里,如果請(qǐng)求的資源在緩存里并且沒有失效,那么就直接使用,否則向服務(wù)器發(fā)起新的請(qǐng)求。(3)下一步我們首先需要獲取的是輸入的 URL 中的域名的 IP 地址,首先會(huì)判斷本地是否有該域名的 IP 地址的緩存,如果有則使用,如果沒有則向本地 DNS 服務(wù)器發(fā)起請(qǐng)求。本地 DNS 服務(wù)器也會(huì)先檢查是否存在緩存,如果沒有就會(huì)先向根域名服務(wù)器發(fā)起請(qǐng)求,獲得負(fù)責(zé)的頂級(jí)域名服務(wù)器的地址后,再向頂級(jí)域名服務(wù)器請(qǐng)求,然后獲得負(fù)責(zé)的權(quán)威域名服務(wù)器的地址后,再向權(quán)威域名服務(wù)器發(fā)起請(qǐng)求,最終獲得域名的 IP 地址后,本地 DNS 服務(wù)器再將這個(gè) IP 地址返回給請(qǐng)求的用戶。用戶向本地 DNS 服務(wù)器發(fā)起請(qǐng)求屬于遞歸請(qǐng)求,本地 DNS 服務(wù)器向各級(jí)域名服務(wù)器發(fā)起請(qǐng)求屬于迭代請(qǐng)求。(4)當(dāng)瀏覽器得到 IP 地址后,數(shù)據(jù)傳輸還需要知道目的主機(jī) MAC 地址,因?yàn)閼?yīng)用層下發(fā)數(shù)據(jù)給傳輸層,TCP 協(xié)議會(huì)指定源端口號(hào)和目的端口號(hào),然后下發(fā)給網(wǎng)絡(luò)層。網(wǎng)絡(luò)層會(huì)將本機(jī)地址作為源地址,獲取的 IP 地址作為目的地址。然后將下發(fā)給數(shù)據(jù)鏈路層,數(shù)據(jù)鏈路層的發(fā)送需要加入通信雙方的 MAC 地址,我們本機(jī)的 MAC 地址作為源 MAC 地址,目的 MAC 地址需要分情況處理,通過將 IP 地址與我們本機(jī)的子網(wǎng)掩碼相與,我們可以判斷我們是否與請(qǐng)求主機(jī)在同一個(gè)子網(wǎng)里,如果在同一個(gè)子網(wǎng)里,我們可以使用 APR 協(xié)議獲取到目的主機(jī)的 MAC 地址,如果我們不在一個(gè)子網(wǎng)里,那么我們的請(qǐng)求應(yīng)該轉(zhuǎn)發(fā)給我們的網(wǎng)關(guān),由它代為轉(zhuǎn)發(fā),此時(shí)同樣可以通過 ARP 協(xié)議來獲取網(wǎng)關(guān)的 MAC 地址,此時(shí)目的主機(jī)的 MAC 地址應(yīng)該為網(wǎng)關(guān)的地址。(5)下面是 TCP 建立連接的三次握手的過程,首先客戶端向服務(wù)器發(fā)送一個(gè) SYN 連接請(qǐng)求報(bào)文段和一個(gè)隨機(jī)序號(hào),服務(wù)端接收到請(qǐng)求后向服務(wù)器端發(fā)送一個(gè) SYN ACK報(bào)文段,確認(rèn)連接請(qǐng)求,并且也向客戶端發(fā)送一個(gè)隨機(jī)序號(hào)。客戶端接收服務(wù)器的確認(rèn)應(yīng)答后,進(jìn)入連接建立的狀態(tài),同時(shí)向服務(wù)器也發(fā)送一個(gè) ACK 確認(rèn)報(bào)文段,服務(wù)器端接收到確認(rèn)后,也進(jìn)入連接建立狀態(tài),此時(shí)雙方的連接就建立起來了。(6)如果使用的是 HTTPS 協(xié)議,在通信前還存在 TLS 的一個(gè)四次握手的過程。首先由客戶端向服務(wù)器端發(fā)送使用的協(xié)議的版本號(hào)、一個(gè)隨機(jī)數(shù)和可以使用的加密方法。服務(wù)器端收到后,確認(rèn)加密的方法,也向客戶端發(fā)送一個(gè)隨機(jī)數(shù)和自己的數(shù)字證書。客戶端收到后,首先檢查數(shù)字證書是否有效,如果有效,則再生成一個(gè)隨機(jī)數(shù),并使用證書中的公鑰對(duì)隨機(jī)數(shù)加密,然后發(fā)送給服務(wù)器端,并且還會(huì)提供一個(gè)前面所有內(nèi)容的 hash 值供服務(wù)器端檢驗(yàn)。服務(wù)器端接收后,使用自己的私鑰對(duì)數(shù)據(jù)解密,同時(shí)向客戶端發(fā)送一個(gè)前面所有內(nèi)容的 hash 值供客戶端檢驗(yàn)。這個(gè)時(shí)候雙方都有了三個(gè)隨機(jī)數(shù),按照之前所約定的加密方法,使用這三個(gè)隨機(jī)數(shù)生成一把秘鑰,以后雙方通信前,就使用這個(gè)秘鑰對(duì)數(shù)據(jù)進(jìn)行加密后再傳輸。(7)當(dāng)頁面請(qǐng)求發(fā)送到服務(wù)器端后,服務(wù)器端會(huì)返回一個(gè) html 文件作為響應(yīng),瀏覽器接收到響應(yīng)后,開始對(duì) html 文件進(jìn)行解析,開始頁面的渲染過程。(8)瀏覽器首先會(huì)根據(jù) html 文件構(gòu)建 DOM 樹,根據(jù)解析到的 css 文件構(gòu)建 CSSOM 樹,如果遇到 script 標(biāo)簽,則判端是否含有 defer 或者 async 屬性,要不然 script 的加載和執(zhí)行會(huì)造成頁面的渲染的阻塞。當(dāng) DOM 樹和 CSSOM 樹建立好后,根據(jù)它們來構(gòu)建渲染樹。渲染樹構(gòu)建好后,會(huì)根據(jù)渲染樹來進(jìn)行布局。布局完成后,最后使用瀏覽器的 UI 接口對(duì)頁面進(jìn)行繪制。這個(gè)時(shí)候整個(gè)頁面就顯示出來了。(9)最后一步是 TCP 斷開連接的四次揮手過程。
詳細(xì)資料可以參考: 《當(dāng)你在瀏覽器中輸入 Google.com 并且按下回車之后發(fā)生了什么?》
7、談?wù)?CDN 服務(wù)?
CDN 是一個(gè)內(nèi)容分發(fā)網(wǎng)絡(luò),通過對(duì)源網(wǎng)站資源的緩存,利用本身多臺(tái)位于不同地域、不同運(yùn)營商的服務(wù)器,向用戶提供資就近訪問的功能。也就是說,用戶的請(qǐng)求并不是直接發(fā)送給源網(wǎng)站,而是發(fā)送給 CDN 服務(wù)器,由 CND 服務(wù)器將請(qǐng)求定位到最近的含有該資源的服務(wù)器上去請(qǐng)求。這樣有利于提高網(wǎng)站的訪問速度,同時(shí)通過這種方式也減輕了源服務(wù)器的訪問壓力。
詳細(xì)資料可以參考: 《CDN 是什么?使用 CDN 有什么優(yōu)勢?》
8、什么是正向代理和反向代理?
我們常說的代理也就是指正向代理,正向代理的過程,它隱藏了真實(shí)的請(qǐng)求客戶端,服務(wù)端不知道真實(shí)的客戶端是誰,客戶端請(qǐng)求的服務(wù)都被代理服務(wù)器代替來請(qǐng)求。反向代理隱藏了真實(shí)的服務(wù)端,當(dāng)我們請(qǐng)求一個(gè)網(wǎng)站的時(shí)候,背后可能有成千上萬臺(tái)服務(wù)器為我們服務(wù),但具體是哪一臺(tái),我們不知道,也不需要知道,我們只需要知道反向代理服務(wù)器是誰就好了,反向代理服務(wù)器會(huì)幫我們把請(qǐng)求轉(zhuǎn)發(fā)到真實(shí)的服務(wù)器那里去。反向代理器一般用來實(shí)現(xiàn)負(fù)載平衡。
詳細(xì)資料可以參考: 《正向代理與反向代理有什么區(qū)別》 《webpack 配置 proxy 反向代理的原理是什么?》
9、負(fù)載平衡的兩種實(shí)現(xiàn)方式?
一種是使用反向代理的方式,用戶的請(qǐng)求都發(fā)送到反向代理服務(wù)上,然后由反向代理服務(wù)器來轉(zhuǎn)發(fā)請(qǐng)求到真實(shí)的服務(wù)器上,以此來實(shí)現(xiàn)集群的負(fù)載平衡。另一種是 DNS 的方式,DNS 可以用于在冗余的服務(wù)器上實(shí)現(xiàn)負(fù)載平衡。因?yàn)楝F(xiàn)在一般的大型網(wǎng)站使用多臺(tái)服務(wù)器提供服務(wù),因此一個(gè)域名可能會(huì)對(duì)應(yīng)多個(gè)服務(wù)器地址。當(dāng)用戶向網(wǎng)站域名請(qǐng)求的時(shí)候,DNS 服務(wù)器返回這個(gè)域名所對(duì)應(yīng)的服務(wù)器 IP 地址的集合,但在每個(gè)回答中,會(huì)循環(huán)這些 IP 地址的順序,用戶一般會(huì)選擇排在前面的地址發(fā)送請(qǐng)求。以此將用戶的請(qǐng)求均衡的分配到各個(gè)不同的服務(wù)器上,這樣來實(shí)現(xiàn)負(fù)載均衡。這種方式有一個(gè)缺點(diǎn)就是,由于 DNS 服務(wù)器中存在緩存,所以有可能一個(gè)服務(wù)器出現(xiàn)故障后,域名解析仍然返回的是那個(gè) IP 地址,就會(huì)造成訪問的問題。
詳細(xì)資料可以參考: 《負(fù)載均衡的原理》
10、 http 請(qǐng)求方法 options 方法有什么用?
OPTIONS 請(qǐng)求與 HEAD 類似,一般也是用于客戶端查看服務(wù)器的性能。這個(gè)方法會(huì)請(qǐng)求服務(wù)器返回該資源所支持的所有 HTTP 請(qǐng)求方法,該方法會(huì)用'*'來代替資源名稱,向服務(wù)器發(fā)送 OPTIONS 請(qǐng)求,可以測試服務(wù)器功能是否正常。JS 的 XMLHttpRequest對(duì)象進(jìn)行 CORS 跨域資源共享時(shí),對(duì)于復(fù)雜請(qǐng)求,就是使用 OPTIONS 方法發(fā)送嗅探請(qǐng)求,以判斷是否有對(duì)指定資源的訪問權(quán)限。
相關(guān)資料可以參考: 《HTTP 請(qǐng)求方法》
11、http1.1 和 http1.0 之間有哪些區(qū)別?
http1.1 相對(duì)于 http1.0 有這樣幾個(gè)區(qū)別:(1)連接方面的區(qū)別,http1.1 默認(rèn)使用持久連接,而 http1.0 默認(rèn)使用非持久連接。http1.1 通過使用持久連接來使多個(gè) http 請(qǐng)求復(fù)用同一個(gè) TCP 連接,以此來避免使用非持久連接時(shí)每次需要建立連接的時(shí)延。(2)資源請(qǐng)求方面的區(qū)別,在 http1.0 中,存在一些浪費(fèi)帶寬的現(xiàn)象,例如客戶端只是需要某個(gè)對(duì)象的一部分,而服務(wù)器卻將整個(gè)對(duì)象送過來了,并且不支持?jǐn)帱c(diǎn)續(xù)傳功能,http1.1 則在請(qǐng)求頭引入了 range 頭域,它允許只請(qǐng)求資源的某個(gè)部分,即返回碼是 206(Partial Content),這樣就方便了開發(fā)者自由的選擇以便于充分利用帶寬和連接。(3)緩存方面的區(qū)別,在 http1.0 中主要使用 header 里的 If-Modified-Since,Expires 來做為緩存判斷的標(biāo)準(zhǔn),http1.1 則引入了更多的緩存控制策略例如 Etag、If-Unmodified-Since、If-Match、If-None-Match 等更多可供選擇的緩存頭來控制緩存策略。(4)http1.1 中還新增了 host 字段,用來指定服務(wù)器的域名。http1.0 中認(rèn)為每臺(tái)服務(wù)器都綁定一個(gè)唯一的 IP 地址,因此,請(qǐng)求消息中的 URL 并沒有傳遞主機(jī)名(hostname)。但隨著虛擬主機(jī)技術(shù)的發(fā)展,在一臺(tái)物理服務(wù)器上可以存在多個(gè)虛擬主機(jī),并且它們共享一個(gè)IP地址。因此有了 host 字段,就可以將請(qǐng)求發(fā)往同一臺(tái)服務(wù)器上的不同網(wǎng)站。(5)http1.1 相對(duì)于 http1.0 還新增了很多方法,如 PUT、HEAD、OPTIONS 等。
詳細(xì)資料可以參考: 《HTTP1.0、HTTP1.1 和 HTTP2.0 的區(qū)別》 《HTTP 協(xié)議入門》 《網(wǎng)絡(luò)---一篇文章詳解請(qǐng)求頭 Host 的概念》
12、網(wǎng)站域名加 www 與不加 www 的區(qū)別?
詳細(xì)資料可以參考: 《為什么域名前要加 www 前綴 www 是什么意思?》 《為什么越來越多的網(wǎng)站域名不加「www」前綴?》 《域名有 www 與沒有 www 有什么區(qū)別?》
13、 即時(shí)通訊的實(shí)現(xiàn),短輪詢、長輪詢、SSE 和 WebSocket 間的區(qū)別?
短輪詢和長輪詢的目的都是用于實(shí)現(xiàn)客戶端和服務(wù)器端的一個(gè)即時(shí)通訊。短輪詢的基本思路就是瀏覽器每隔一段時(shí)間向?yàn)g覽器發(fā)送 http 請(qǐng)求,服務(wù)器端在收到請(qǐng)求后,不論是否有數(shù)據(jù)更新,都直接進(jìn)行響應(yīng)。這種方式實(shí)現(xiàn)的即時(shí)通信,本質(zhì)上還是瀏覽器發(fā)送請(qǐng)求,服務(wù)器接受請(qǐng)求的一個(gè)過程,通過讓客戶端不斷的進(jìn)行請(qǐng)求,使得客戶端能夠模擬實(shí)時(shí)地收到服務(wù)器端的數(shù)據(jù)的變化。這種方式的優(yōu)點(diǎn)是比較簡單,易于理解。缺點(diǎn)是這種方式由于需要不斷的建立 http 連接,嚴(yán)重浪費(fèi)了服務(wù)器端和客戶端的資源。當(dāng)用戶增加時(shí),服務(wù)器端的壓力就會(huì)變大,這是很不合理的。長輪詢的基本思路是,首先由客戶端向服務(wù)器發(fā)起請(qǐng)求,當(dāng)服務(wù)器收到客戶端發(fā)來的請(qǐng)求后,服務(wù)器端不會(huì)直接進(jìn)行響應(yīng),而是先將這個(gè)請(qǐng)求掛起,然后判斷服務(wù)器端數(shù)據(jù)是否有更新。如果有更新,則進(jìn)行響應(yīng),如果一直沒有數(shù)據(jù),則到達(dá)一定的時(shí)間限制才返回。客戶端 JavaScript 響應(yīng)處理函數(shù)會(huì)在處理完服務(wù)器返回的信息后,再次發(fā)出請(qǐng)求,重新建立連接。長輪詢和短輪詢比起來,它的優(yōu)點(diǎn)是明顯減少了很多不必要的 http 請(qǐng)求次數(shù),相比之下節(jié)約了資源。長輪詢的缺點(diǎn)在于,連接掛起也會(huì)導(dǎo)致資源的浪費(fèi)。SSE 的基本思想是,服務(wù)器使用流信息向服務(wù)器推送信息。嚴(yán)格地說,http 協(xié)議無法做到服務(wù)器主動(dòng)推送信息。但是,有一種變通方法,就是服務(wù)器向客戶端聲明,接下來要發(fā)送的是流信息。也就是說,發(fā)送的不是一次性的數(shù)據(jù)包,而是一個(gè)數(shù)據(jù)流,會(huì)連續(xù)不斷地發(fā)送過來。這時(shí),客戶端不會(huì)關(guān)閉連接,會(huì)一直等著服務(wù)器發(fā)過來的新的數(shù)據(jù)流,視頻播放就是這樣的例子。SSE 就是利用這種機(jī)制,使用流信息向?yàn)g覽器推送信息。它基于 http 協(xié)議,目前除了 IE/Edge,其他瀏覽器都支持。它相對(duì)于前面兩種方式來說,不需要建立過多的 http 請(qǐng)求,相比之下節(jié)約了資源。上面三種方式本質(zhì)上都是基于 http 協(xié)議的,我們還可以使用 WebSocket 協(xié)議來實(shí)現(xiàn)。WebSocket 是 Html5 定義的一個(gè)新協(xié)議,與傳統(tǒng)的 http 協(xié)議不同,該協(xié)議允許由服務(wù)器主動(dòng)的向客戶端推送信息。使用 WebSocket 協(xié)議的缺點(diǎn)是在服務(wù)器端的配置比較復(fù)雜。WebSocket 是一個(gè)全雙工的協(xié)議,也就是通信雙方是平等的,可以相互發(fā)送消息,而 SSE 的方式是單向通信的,只能由服務(wù)器端向客戶端推送信息,如果客戶端需要發(fā)送信息就是屬于下一個(gè) http 請(qǐng)求了。
在多個(gè)網(wǎng)站之間共享登錄狀態(tài)指的就是單點(diǎn)登錄。多個(gè)應(yīng)用系統(tǒng)中,用戶只需要登錄一次就可以訪問所有相互信任的應(yīng)用系統(tǒng)。我認(rèn)為單點(diǎn)登錄可以這樣來實(shí)現(xiàn),首先將用戶信息的驗(yàn)證中心獨(dú)立出來,作為一個(gè)單獨(dú)的認(rèn)證中心,該認(rèn)證中心的作用是判斷客戶端發(fā)送的賬號(hào)密碼的正確性,然后向客戶端返回對(duì)應(yīng)的用戶信息,并且返回一個(gè)由服務(wù)器端秘鑰加密的登錄信息的 token 給客戶端,該token 具有一定的有效時(shí)限。當(dāng)一個(gè)應(yīng)用系統(tǒng)跳轉(zhuǎn)到另一個(gè)應(yīng)用系統(tǒng)時(shí),通過 url 參數(shù)的方式來傳遞 token,然后轉(zhuǎn)移到的應(yīng)用站點(diǎn)發(fā)送給認(rèn)證中心,認(rèn)證中心對(duì) token 進(jìn)行解密后驗(yàn)證,如果用戶信息沒有失效,則向客戶端返回對(duì)應(yīng)的用戶信息,如果失效了則將頁面重定向會(huì)單點(diǎn)登錄頁面。
詳細(xì)資料可以參考: 《HTTP 是個(gè)無狀態(tài)協(xié)議,怎么保持登錄狀態(tài)?》
