本文約6000字,建議閱讀15分鐘?
本文為你介紹聯(lián)邦學(xué)習(xí)的詳細(xì)講解及示例代碼。
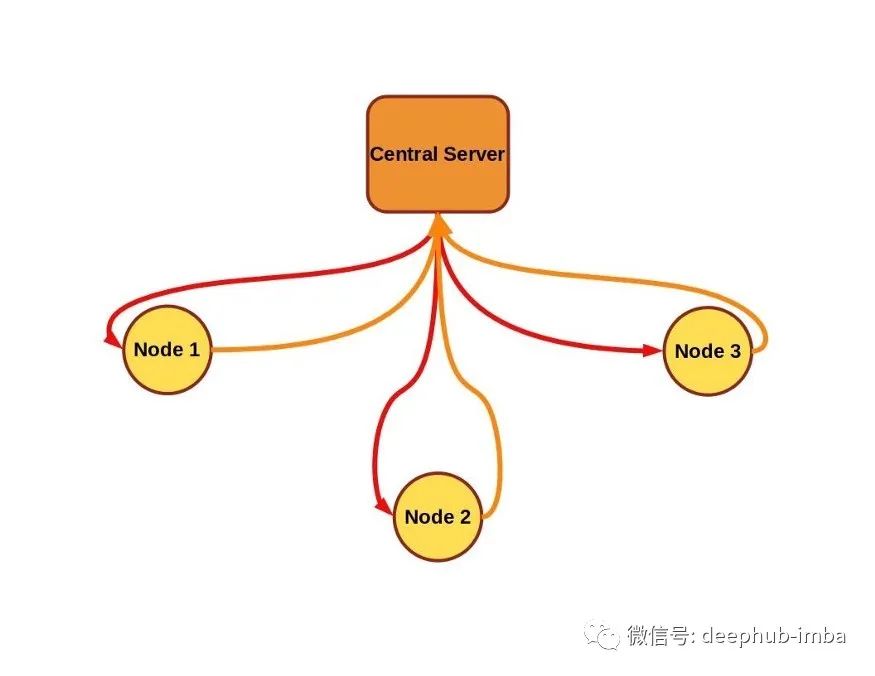
聯(lián)邦學(xué)習(xí)也稱為協(xié)同學(xué)習(xí),它可以在產(chǎn)生數(shù)據(jù)的設(shè)備上進(jìn)行大規(guī)模的訓(xùn)練,并且這些敏感數(shù)據(jù)保留在數(shù)據(jù)的所有者那里,本地收集、本地訓(xùn)練。在本地訓(xùn)練后,中央的訓(xùn)練協(xié)調(diào)器通過(guò)獲取分布模型的更新獲得每個(gè)節(jié)點(diǎn)的訓(xùn)練貢獻(xiàn),但是不訪問(wèn)實(shí)際的敏感數(shù)據(jù)。
聯(lián)邦學(xué)習(xí)本身并不能保證隱私(稍后我們將討論聯(lián)邦學(xué)習(xí)系統(tǒng)中的隱私破壞和修復(fù)),但它確實(shí)使隱私成為可能。- 手機(jī)輸入法的下一個(gè)詞預(yù)測(cè)(e.g. McMahan et al. 2017, Hard et al. 2019)
- 健康研究(e.g. Kaissis et al. 2020, Sadilek et al. 2021)
- 汽車(chē)自動(dòng)駕駛(e.g. Zeng et al. 2021, OpenMined 的文章)
- “智能家居”系統(tǒng)(e.g. Matchi et al. 2019, Wu et al. 2020)
因?yàn)殡[私的問(wèn)題所以對(duì)于個(gè)人來(lái)說(shuō),人們寧愿放棄他們的個(gè)人數(shù)據(jù),也不會(huì)將數(shù)據(jù)提供給平臺(tái)(平臺(tái)有時(shí)候也想著白嫖??),所以聯(lián)邦學(xué)習(xí)幾乎涵蓋了所有以個(gè)人為單位進(jìn)行預(yù)測(cè)的所有場(chǎng)景。隨著公眾和政策制定者越來(lái)越意識(shí)到隱私的重要性,數(shù)據(jù)實(shí)踐中對(duì)保護(hù)隱私的機(jī)器學(xué)習(xí)的需求也正在上升,對(duì)于數(shù)據(jù)的訪問(wèn)受到越來(lái)越多的審查,對(duì)聯(lián)邦學(xué)習(xí)等尊重隱私的工具的研究也越來(lái)越活躍。在理想情況下,聯(lián)邦學(xué)習(xí)可以在保護(hù)個(gè)人和機(jī)構(gòu)的隱私的前提下,使數(shù)據(jù)利益相關(guān)者之間的合作成為可能,因?yàn)橐郧吧虡I(yè)機(jī)密、私人健康信息或數(shù)據(jù)泄露風(fēng)險(xiǎn)的通常使這種合作變得困難甚至無(wú)法進(jìn)行。
歐盟《通用數(shù)據(jù)保護(hù)條例》或《加利福尼亞消費(fèi)者隱私法》等政府法規(guī)使聯(lián)邦學(xué)習(xí)等隱私保護(hù)策略成為希望保持合法運(yùn)營(yíng)的企業(yè)的有用工具。與此同時(shí),在保持模型性能和效率的同時(shí)獲得所需的隱私和安全程度,這本身就帶來(lái)了大量技術(shù)挑戰(zhàn)。從個(gè)人數(shù)據(jù)生產(chǎn)者(我們都是其中的一員)的日常角度來(lái)看,至少在理論上是可以在私人健康和財(cái)務(wù)數(shù)據(jù)之間放置一些東西來(lái)屏蔽那種跟蹤你在網(wǎng)上行為設(shè)置暴露你的個(gè)人隱私的所謂的大雜燴生態(tài)系統(tǒng)。如果這些問(wèn)題中的任何一個(gè)引起你的共鳴,請(qǐng)繼續(xù)閱讀以了解更多關(guān)于聯(lián)邦學(xué)習(xí)的復(fù)雜性以及它可以為使用敏感數(shù)據(jù)的機(jī)器學(xué)習(xí)做了哪些工作。聯(lián)邦學(xué)習(xí)簡(jiǎn)介
聯(lián)邦學(xué)習(xí)的目的是訓(xùn)練來(lái)自多個(gè)數(shù)據(jù)源的單個(gè)模型,其約束條件是數(shù)據(jù)停留在數(shù)據(jù)源上,而不是由數(shù)據(jù)源(也稱為節(jié)點(diǎn)、客戶端)交換,也不是由中央服務(wù)器進(jìn)行編排訓(xùn)練(如果存在的話)。在典型的聯(lián)邦學(xué)習(xí)方案中,中央服務(wù)器將模型參數(shù)發(fā)送到各節(jié)點(diǎn)(也稱為客戶端、終端或工作器)。節(jié)點(diǎn)針對(duì)本地?cái)?shù)據(jù)的一些訓(xùn)練初始模型,并將新訓(xùn)練的權(quán)重發(fā)送回中央服務(wù)器,中央服務(wù)器對(duì)新模型參數(shù)求平均值(通常與在每個(gè)節(jié)點(diǎn)上執(zhí)行的訓(xùn)練量有關(guān))。在這種情況下,中央服務(wù)器或其他節(jié)點(diǎn)永遠(yuǎn)不會(huì)直接看到任何一個(gè)其他節(jié)點(diǎn)上的數(shù)據(jù),并使用安全聚合等附加技術(shù)進(jìn)一步增強(qiáng)隱私。
該框架內(nèi)有許多變體。例如,在本文中主要關(guān)注由中央服務(wù)器管理的聯(lián)邦學(xué)習(xí)方案,該方案在多個(gè)相同類型的設(shè)備上編排訓(xùn)練,節(jié)點(diǎn)上每次訓(xùn)練都使用自己的本地?cái)?shù)據(jù)并將結(jié)果上傳到中央服務(wù)器,這是在 2017 年由 McMahan 等人描述的基本方案。但是某些情況下可能需要取消訓(xùn)練的集中控制,當(dāng)單個(gè)節(jié)點(diǎn)分配中央管理器的角色時(shí),它就變成了去中心化的聯(lián)邦學(xué)習(xí),這是針對(duì)特殊的醫(yī)療數(shù)據(jù)訓(xùn)練模型的一種有效的解決方案。典型的聯(lián)邦學(xué)習(xí)場(chǎng)景可能涉及大量的設(shè)備(例如手機(jī)),所有手機(jī)的計(jì)算能力大致相似,訓(xùn)練相同的模型架構(gòu)。但有一些方案,例如Diao等人2021年提出的HeteroFL允許在具有巨大差異的通信和計(jì)算能力的各種設(shè)備上訓(xùn)練一個(gè)單一的推理模型,甚至可以訓(xùn)練具有不同架構(gòu)和參數(shù)數(shù)量的局部模型,然后將訓(xùn)練的參數(shù)聚集到一個(gè)全局推理模型中。聯(lián)邦學(xué)習(xí)還有一個(gè)優(yōu)勢(shì)是數(shù)據(jù)保存在產(chǎn)生數(shù)據(jù)的設(shè)備上,訓(xùn)練數(shù)據(jù)集通常比模型要大得多,因此發(fā)送后者而不是前者可以節(jié)省帶寬。但在這些優(yōu)勢(shì)中最重要的還是隱私保護(hù),雖然有可能僅通過(guò)模型參數(shù)更新就推斷出關(guān)于私有數(shù)據(jù)集內(nèi)容的某些內(nèi)容。McMahan等人在2017年使用了一個(gè)簡(jiǎn)單的例子來(lái)解釋該漏洞,即使用一個(gè)“詞袋”輸入向量訓(xùn)練的語(yǔ)言模型,其中每個(gè)輸入向量具體對(duì)應(yīng)于一個(gè)大詞匯表中的一個(gè)單詞。對(duì)于相應(yīng)單詞的每個(gè)非零梯度更新將為竊聽(tīng)者提供一個(gè)關(guān)于該單詞在私有數(shù)據(jù)集中存在(反之亦然)的線索,還有更復(fù)雜的攻擊也被證實(shí)了。為了解決這個(gè)問(wèn)題,可以將多種隱私增強(qiáng)技術(shù)整合到聯(lián)邦學(xué)習(xí)中,從安全的更新聚合到使用完全同態(tài)加密進(jìn)行訓(xùn)練。下面我們將簡(jiǎn)要介紹聯(lián)邦學(xué)習(xí)中對(duì)隱私的最突出的威脅及其緩解措施。國(guó)家對(duì)數(shù)據(jù)隱私的監(jiān)管是一個(gè)新興的政策領(lǐng)域,但是要比基于個(gè)人數(shù)據(jù)收集和分析的發(fā)展要晚10到20年。2016年頒布的《歐洲一般數(shù)據(jù)保護(hù)條例》(European General data Protection regulation,簡(jiǎn)稱GDPR)是最重要的關(guān)于公眾個(gè)人數(shù)據(jù)的法規(guī),這可能會(huì)有些奇怪,因?yàn)轭愃频谋Wo(hù)限制企業(yè)監(jiān)測(cè)和數(shù)據(jù)收集的措施施尚處于起步階段甚至是沒(méi)有。兩年后的2018年,加州消費(fèi)者隱私法案緊隨歐盟的GDPR成為法律。作為一項(xiàng)州法律,與GDPR相比,CCPA在地理范圍上明顯受到限制,該法案對(duì)個(gè)人信息的定義更窄。聯(lián)邦學(xué)習(xí)的名字是由McMahan等人在2017年的一篇論文中引入的,用來(lái)描述分散數(shù)據(jù)模型的訓(xùn)練。作者根據(jù)2012年白宮關(guān)于消費(fèi)者數(shù)據(jù)隱私的報(bào)告為他們的系統(tǒng)制定了設(shè)計(jì)策略。他們提出了聯(lián)邦學(xué)習(xí)的兩個(gè)主要用例:圖像分類和用于語(yǔ)音識(shí)別或下一個(gè)單詞/短語(yǔ)預(yù)測(cè)的語(yǔ)言模型。不久以后與分布式訓(xùn)練相關(guān)的潛在攻擊就相繼的出現(xiàn)了。Phong et al. 2017和Bhowmick et al. 2018等人的工作表明,即使只訪問(wèn)從聯(lián)邦學(xué)習(xí)客戶端返回到服務(wù)器的梯度更新或部分訓(xùn)練的模型,也可以推斷出一些描述私人數(shù)據(jù)的細(xì)節(jié)。在inphero的文章中,你可以看到關(guān)于隱私問(wèn)題的總結(jié)和解決方法。在聯(lián)邦學(xué)習(xí)中,隱私、有效性和效率之間的平衡涉及廣泛的領(lǐng)域。服務(wù)器和客戶機(jī)之間的通信(或者僅僅是去中心化客戶機(jī)之間的通信)可以在傳輸時(shí)進(jìn)行加密,但還有一個(gè)更健壯的選項(xiàng)即在訓(xùn)練期間數(shù)據(jù)和模型也保持加密。同態(tài)加密可用于對(duì)加密的數(shù)據(jù)執(zhí)行計(jì)算,因此(在理想情況下)輸出只能由持有密鑰的涉眾解密。OpenMined的PySyft、Microsoft的SEAL或TensorFlow Encrypted等庫(kù)為加密的深度學(xué)習(xí)提供了工具,這些工具可以應(yīng)用到聯(lián)邦學(xué)習(xí)系統(tǒng)中。關(guān)于聯(lián)邦學(xué)習(xí)的介紹到此為止,接下來(lái)我們將在教程部分中設(shè)置一個(gè)簡(jiǎn)單的聯(lián)邦學(xué)習(xí)演示。聯(lián)邦學(xué)習(xí)代碼實(shí)現(xiàn)
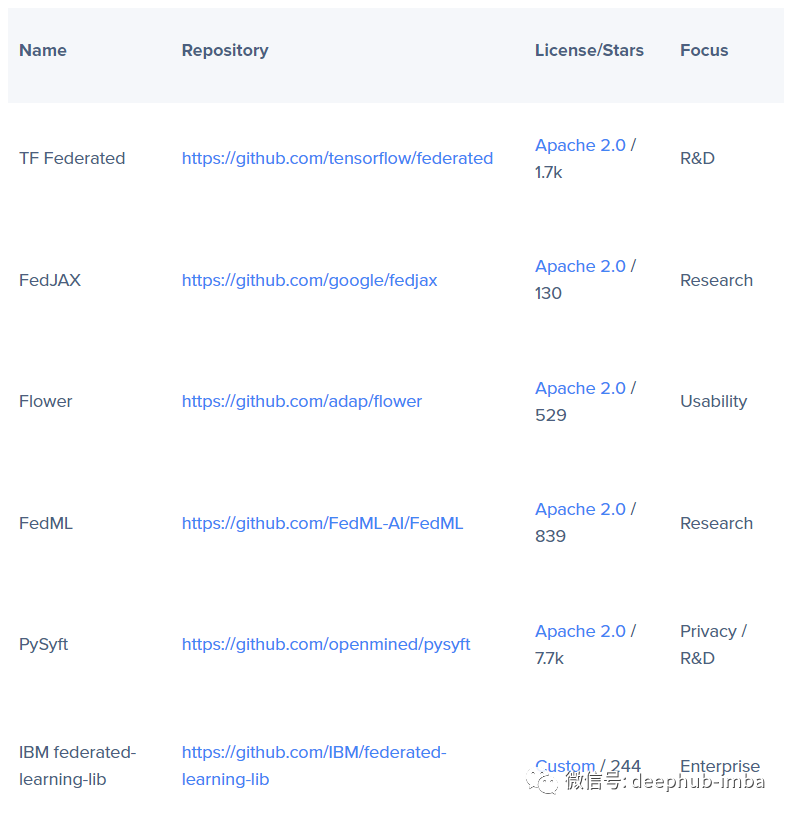
既然我們已經(jīng)知道在何處以及為什么要使用聯(lián)邦學(xué)習(xí),那么讓我們動(dòng)手看看我們?nèi)绾芜@樣做,在這里我們使用鳶尾花數(shù)據(jù)集進(jìn)行聯(lián)邦學(xué)習(xí)。有許多聯(lián)邦學(xué)習(xí)庫(kù)可供選擇,從在 GitHub 上擁有超過(guò) 1700 顆星的更主流的 Tensorflow Federated 到流行且注重隱私的 PySyft,再到面向研究的 FedJAX。下面表中包含流行的聯(lián)邦學(xué)習(xí)存儲(chǔ)庫(kù)的參考列表。在我們的演示中將使用 Flower 庫(kù)。我們選擇這個(gè)庫(kù)的部分原因是它以一種可訪問(wèn)的方式舉例說(shuō)明了基本的聯(lián)邦學(xué)習(xí)概念并且它與框架無(wú)關(guān),F(xiàn)lower 可以整合任何構(gòu)建模型的深度學(xué)習(xí)工具包(他們?cè)谖臋n中有 TensorFlow、PyTorch、MXNet 和 SciKit-Learn 的示例)所以我們將使用 SciKit-Learn 中包含的“iris”數(shù)據(jù)集和Pytorch來(lái)驗(yàn)證它所說(shuō)的與框架無(wú)關(guān)的這個(gè)特性。從高層的角度來(lái)看我們需要設(shè)置一個(gè)服務(wù)器和一個(gè)客戶端,對(duì)于客戶端我們使用不同的訓(xùn)練數(shù)據(jù)集。首先就是設(shè)置中央?yún)f(xié)調(diào)器。
設(shè)置協(xié)調(diào)器的第一步就是定義一個(gè)評(píng)估策略并將其傳遞給 Flower 中的默認(rèn)配置服務(wù)器。但首先讓我們確保設(shè)置了一個(gè)虛擬環(huán)境,其中包含需要的所有依賴項(xiàng)。在 Unix 命令行上:virtualenv flower_env python==python3
source flower_env/bin/activate
pip install flwr==0.17.0# I'm running this example on a laptop (no gpu)
# so I am installing the cpu only version of PyTorch
# follow the instructions at https://pytorch.org/get-started/locally/
# if you want the gpu optionpip install torch==1.9.1+cpu torchvision==0.10.1+cpu \
? -f https://download.pytorch.org/whl/torch_stable.htmlpip install scikit-learn==0.24.0
隨著我們的虛擬環(huán)境啟動(dòng)并運(yùn)行,我們可以編寫(xiě)一個(gè)模塊來(lái)啟動(dòng) Flower 服務(wù)器來(lái)處理聯(lián)邦學(xué)習(xí)。在下面的代碼中,我們包含了 argparse,以便在從命令行調(diào)用服務(wù)器模塊時(shí)更容易地試驗(yàn)不同數(shù)量的訓(xùn)練輪次。我們還定義了一個(gè)生成評(píng)估函數(shù)的函數(shù),這是我們添加到 Flower 服務(wù)器默認(rèn)配置使用的策略中的唯一其他內(nèi)容。以下我們的服務(wù)器模塊文件的內(nèi)容:import argparse
import flwr as fl
import torch
from pt_client import get_data, PTMLPClient
def get_eval_fn(model):
? # This `evaluate` function will be called after every round
? def evaluate(parameters: fl.common.Weights):
? ? ? loss, _, accuracy_dict = model.evaluate(parameters)
? ? ? return loss, accuracy_dict
return evaluate
if __name__ == "__main__":
? parser = argparse.ArgumentParser()
? parser.add_argument("-r", "--rounds", type=int, default=3,\
? ? ? ? ? help="number of rounds to train")
? args = parser.parse_args()
? torch.random.manual_seed(42)
? model = PTMLPClient(split="val")
? strategy = fl.server.strategy.FedAvg( \
? ? ? eval_fn=get_eval_fn(model),\
? ? ? )
? fl.server.start_server("[::]:8080", strategy=strategy, \
? ? ? ? ? config={"num_rounds": args.rounds})
注意上面代碼中調(diào)用的 PTMLPClient。這個(gè)是server模塊用來(lái)定義評(píng)估函數(shù)的,這個(gè)類也是用于訓(xùn)練的模型類并兼作聯(lián)邦學(xué)習(xí)客戶端。接下來(lái)我們將定義 PTMLPClient,并繼承Flower 的 NumPyClient 類和 torch.nn.Module 類,如果您使用 PyTorch,你肯定就熟悉它們。NumPyClient 類處理與服務(wù)器的通信,我們需要實(shí)現(xiàn)4個(gè)抽象函數(shù) set_parameters、get_parameters、fit 和evaluate。torch.nn.Module 類為我們提供了 PyTorch 模型,還有就是使用 PyTorch Adam 優(yōu)化器進(jìn)行訓(xùn)練的能力。我們的 PTMLPClient 類只有 100 多行代碼,所以我們將從 init 開(kāi)始依次介紹每個(gè)類的函數(shù)。請(qǐng)注意,我們從兩個(gè)類繼承。從 nn.Module 繼承意味著我們必須確保使用 super 命令從 nn.Module 調(diào)用 init,但是如果您忘記這樣做,Python 會(huì)立即通知你。除此之外,我們將三個(gè)線性層初始化為矩陣(torch.tensor 數(shù)據(jù)類型),并將一些關(guān)于訓(xùn)練分割和模型維度的信息存儲(chǔ)為類變量。class PTMLPClient(fl.client.NumPyClient, nn.Module):
? def __init__(self, dim_in=4, dim_h=32, \
? ? ? ? ? num_classes=3, lr=3e-4, split="alice"):
? ? ? super(PTMLPClient, self).__init__()
? ? ? self.dim_in = dim_in
? ? ? self.dim_h = dim_h
? ? ? self.num_classes = num_classes
? ? ? self.split = split
? ? ? ?
? ? ? self.w_xh = nn.Parameter(torch.tensor(\
? ? ? ? ? torch.randn(self.dim_in, self.dim_h) \
? ? ? ? ? / np.sqrt(self.dim_in * self.dim_h))\
? ? ? ? ? )
? ? ? self.w_hh = nn.Parameter(torch.tensor(\
? ? ? ? ? torch.randn(self.dim_h, self.dim_h) \
? ? ? ? ? / np.sqrt(self.dim_h * self.dim_h))\
? ? ? ? ? )
? ? ? self.w_hy = nn.Parameter(torch.tensor(\
? ? ? ? ? torch.randn(self.dim_h, self.num_classes) \
? ? ? ? ? / np.sqrt(self.dim_h * self.num_classes))\
? ? ? ? ? )
? ? ? self.lr = lr
接下來(lái)我們將定義 PTMLPClient 類的 get_parameters 和 set_parameters 函數(shù)。這些函數(shù)將所有模型參數(shù)連接為一個(gè)扁平的 numpy 數(shù)組,這是 Flower 的 NumPyClient 類預(yù)期返回和接收的數(shù)據(jù)類型。這符合聯(lián)邦學(xué)習(xí)方案,因?yàn)榉?wù)器將向每個(gè)客戶端發(fā)送初始參數(shù)(使用 set_parameters)并期望返回一組部分訓(xùn)練的權(quán)重(來(lái)自 get_parameters)。這種模式在訓(xùn)練的每輪出現(xiàn)一次。我們還在 set_parameters 中初始化優(yōu)化器和損失函數(shù)。def get_parameters(self):
? ? ? my_parameters = np.append(\
? ? ? ? ? self.w_xh.reshape(-1).detach().numpy(), \
? ? ? ? ? self.w_hh.reshape(-1).detach().numpy() \
? ? ? ? ? )
? ? ? my_parameters = np.append(\
? ? ? my_parameters, \
? ? ? ? ? self.w_hy.reshape(-1).detach().numpy() \
? ? ? ? ? )
? ? ? return my_parameters
def set_parameters(self, parameters):
? ? ? parameters = np.array(parameters)
? ? ? total_params = reduce(lambda a,b: a*b,\
? ? ? ? ? np.array(parameters).shape)
? ? ? expected_params = self.dim_in * self.dim_h \
? ? ? ? ? + self.dim_h**2 \
? ? ? ? ? + self.dim_h * self.num_classes
? ? ? ?
? ? ? start = 0
? ? ? stop = self.dim_in * self.dim_h
? ? ? self.w_xh = nn.Parameter(torch.tensor(\
? ? ? ? ? ? ? parameters[start:stop])\
? ? ? ? ? ? ? .reshape(self.dim_in, self.dim_h).float() \
? ? ? ? ? ? ? )
? ? ? ? ? ? ? ?
? ? ? start = stop
? ? ? stop += self.dim_h**2
? ? ? self.w_hh = nn.Parameter(torch.tensor(\
? ? ? ? ? ? ? parameters[start:stop])\
? ? ? ? ? ? ? .reshape(self.dim_h, self.dim_h).float() \
? ? ? ? ? ? ? )
? ? ? start = stop
? ? ? stop += self.dim_h * self.num_classes
? ? ? self.w_hy = nn.Parameter(torch.tensor(\
? ? ? ? ? ? ? parameters[start:stop])\
? ? ? ? ? ? ? .reshape(self.dim_h, self.num_classes).float()\
? ? ? ? ? ? ? )
? ? ? self.act = torch.relu
? ? ? ?
? ? ? self.optimizer = torch.optim.Adam(self.parameters())
? ? ? self.loss_fn = nn.CrossEntropyLoss()
接下來(lái),我們將定義我們的前向傳遞和一個(gè)用于獲取損失標(biāo)量的函數(shù)。def forward(self, x):
? ? ? x = self.act(torch.matmul(x, self.w_xh))
? ? ? x = self.act(torch.matmul(x, self.w_hh))
? ? ? x = torch.matmul(x, self.w_hy)
? ? ? return x
? ? ? ?
def get_loss(self, x, y):
? ? ? prediction = self.forward(x)
? ? ? loss = self.loss_fn(prediction, y)
? ? ? return loss
我們客戶端還需要的最后幾個(gè)函數(shù)是fit和evaluate。對(duì)于每一輪,每個(gè)客戶端在進(jìn)行幾個(gè)階段的訓(xùn)練之前使用提供給fit方法的參數(shù)初始化它的參數(shù)(在本例中默認(rèn)為10)。evaluate方法在計(jì)算訓(xùn)練數(shù)據(jù)驗(yàn)證的損失和準(zhǔn)確性之前設(shè)置參數(shù)。def fit(self, parameters, config=None, epochs=10):
? ? ? self.set_parameters(parameters)
? ? ? x, y = get_data(split=self.split)
? ? ? x, y = torch.tensor(x).float(), torch.tensor(y).long()
? ? ? self.train()
? ? ? for ii in range(epochs):
? ? ? ? ? self.optimizer.zero_grad()
? ? ? ? ? loss = self.get_loss(x, y)
? ? ? ? ? loss.backward()
? ? ? ? ? self.optimizer.step()
? ? ? ?
? ? ? loss, _, accuracy_dict = self.evaluate(self.get_parameters())
? ? ? return self.get_parameters(), len(y), \
? ? ? ? ? ? ? {"loss": loss, "accuracy": \
? ? ? ? ? ? ? accuracy_dict["accuracy"]}
? def evaluate(self, parameters, config=None):
? ? ? self.set_parameters(parameters)
? ? ? val_x, val_y = get_data(split="val")
? ? ? val_x = torch.tensor(val_x).float()
? ? ? val_y = torch.tensor(val_y).long()
? ? ? ?
? ? ? self.eval()
? ? ? prediction = self.forward(val_x)
? ? ? ?
? ? ? loss = self.loss_fn(prediction, val_y).detach().numpy()
? ? ? ?
? ? ? prediction_class = np.argmax(\
? ? ? ? ? prediction.detach().numpy(), axis=-1)
? ? ? ?
? ? ? accuracy = sklearn.metrics.accuracy_score(\
? ? ? ? ? val_y.numpy(), prediction_class)
? ? ? ?
? ? ? return float(loss), len(val_y), \
? ? ? ? ? {"accuracy":float(accuracy)}
我們的客戶端類中的 fit 和evaluate都調(diào)用了一個(gè)函數(shù) get_data,它只是 SciKit-Learn iris 數(shù)據(jù)集的包裝器。它還將數(shù)據(jù)拆分為訓(xùn)練集和驗(yàn)證集,并進(jìn)一步拆分訓(xùn)練數(shù)據(jù)集(我們稱為“alice”和“bob”)以模擬聯(lián)邦學(xué)習(xí),因?yàn)槁?lián)邦學(xué)習(xí)的客戶端都有自己的數(shù)據(jù)。def get_data(split="all"):
x, y = sklearn.datasets.load_iris(return_X_y=True)
? np.random.seed(42); np.random.shuffle(x)
? np.random.seed(42); np.random.shuffle(y)
? val_split = int(0.2 * x.shape[0])
? train_split = (x.shape[0] - val_split) // 2
? eval_x, eval_y = x[:val_split], y[:val_split] ? ?
? ?
? alice_x, alice_y = x[val_split:val_split + train_split], y[val_split:val_split + train_split]
? ?
? bob_x, bob_y = x[val_split + train_split:], y[val_split + train_split:]
? ?
? train_x, train_y = x[val_split:], y[val_split:]
? ?
? if split == "all":
? ? ? return train_x, train_y
? elif split == "alice":
? ? ? return alice_x, alice_y
? elif split == "bob":
? ? ? return bob_x, bob_y
? elif split == "val":
? ? ? return eval_x, eval_y
? else:
? ? ? print("error: split not recognized.")
? ? ? return None
現(xiàn)在我們只需要在文件底部填充一個(gè) if name == "main": 方法,以便我們可以從命令行將我們的客戶端代碼作為模塊運(yùn)行。if __name__ == "__main__":
? parser = argparse.ArgumentParser()
? parser.add_argument("-s", "--split", type=str, default="alice",\
? help="The training split to use, options are 'alice', 'bob', or 'all'")
? ?
? args = parser.parse_args()
? torch.random.manual_seed(42)
? ?
? fl.client.start_numpy_client("localhost:8080", client=PTMLPClient(split=args.split))
最后,確保在客戶端模塊的頂部導(dǎo)入所需的所有內(nèi)容。import argparse
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.metrics
import torch
import torch.nn as nn
from functools import reduce
import flwr as fl
這就是我們使用 Flower 運(yùn)行聯(lián)邦訓(xùn)練演示所需實(shí)現(xiàn)的全部代碼!要開(kāi)始運(yùn)行聯(lián)邦訓(xùn)練,首先在其命令行終端中啟動(dòng)服務(wù)器。我們將我們的服務(wù)器保存為 pt_server.py,我們的客戶端模塊保存為 pt_client.py,兩者都在我們正在工作的目錄的根目錄中,所以為了啟動(dòng)一個(gè)服務(wù)器并告訴它進(jìn)行40 輪聯(lián)邦學(xué)習(xí),我們使用以下命令。python -m pt_server -r 40
接下來(lái)打開(kāi)一個(gè)新的終端,用“alice”訓(xùn)練分組啟動(dòng)你的第一個(gè)客戶端:python -m pt_client -s alice
啟動(dòng)“bob”訓(xùn)練分組的第二個(gè)客戶端。python -m pt_client -s bob
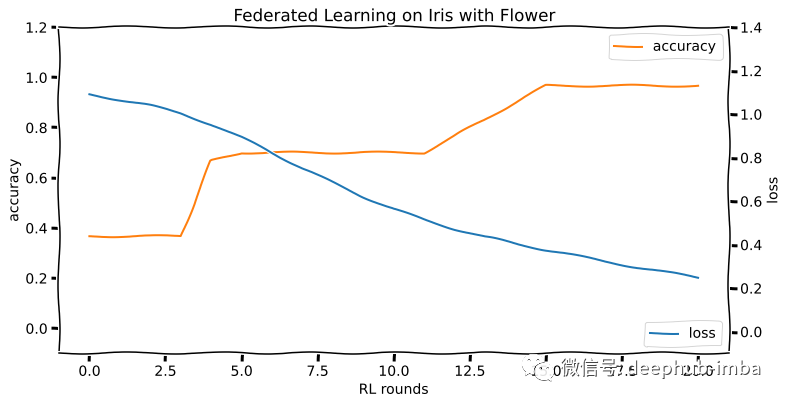
如果一切正常,在運(yùn)行服務(wù)器進(jìn)程的終端中看到訓(xùn)練啟動(dòng)和信息滾動(dòng)。這個(gè)演示在 20 輪訓(xùn)練中達(dá)到了 96% 以上的準(zhǔn)確率。訓(xùn)練運(yùn)行的損失和準(zhǔn)確度曲線如下所示:
聯(lián)邦學(xué)習(xí)的未來(lái)
人們可能會(huì)相信“再也沒(méi)有隱私這種東西了”。這些聲明主要是針對(duì)互聯(lián)網(wǎng)的(這樣的聲明至少?gòu)?999年就開(kāi)始了),但隨著智能家居設(shè)備和愛(ài)管閑事的家用機(jī)器人的迅速普及,你可能覺(jué)得這些言論是正確的。但是請(qǐng)注意是誰(shuí)在做這些聲明,你會(huì)發(fā)現(xiàn)他們中的許多人在你的數(shù)據(jù)被竊取的過(guò)程中是能夠獲得既得利益的。這種“沒(méi)有隱私”的失敗主義態(tài)度不僅是錯(cuò)誤的,而且是危險(xiǎn)的:失去隱私會(huì)使個(gè)人和團(tuán)體以他們可能不會(huì)注意到或承認(rèn)的方式被巧妙地操縱。聯(lián)邦學(xué)習(xí)是伴隨著不斷擴(kuò)大的數(shù)據(jù)量而生的,數(shù)據(jù)無(wú)處不在,聯(lián)邦學(xué)習(xí)的優(yōu)勢(shì)因此獲得了政府、企業(yè)等各界的關(guān)注。聯(lián)邦學(xué)習(xí)能夠有效解決數(shù)據(jù)孤島和數(shù)據(jù)隱私保護(hù)的兩難問(wèn)題。這將會(huì)為未來(lái)人工智能協(xié)作,從而實(shí)現(xiàn)跨越式發(fā)展奠定良好基礎(chǔ),在多行業(yè)、多領(lǐng)域都有廣泛的應(yīng)用前景。編輯:王菁
校對(duì):汪雨晴