
聊一聊“超大模型”
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


文 | 金雪鋒
源 | 知乎
最近經(jīng)常被問,你看“萬億的模型都出來了,你們訓(xùn)練的千億模型是不是落伍了?”我想說:“雖然都叫超大模型,但是類型是不一樣的,雖說每一類模型訓(xùn)出來都不容易,不過澄清一下概念還是必要的”。
大概盤算了一下,一年多來,業(yè)界發(fā)布了非常多的大模型,從去年OpenAI GPT-3 1750億參數(shù)開始,到年初華為盤古大模型 1000億,鵬程盤古-α 2000億參數(shù),Google switch transformer 1.6萬億;及近期的智源悟道2.0 1.75萬億參數(shù) MoE,快手1.9萬億參數(shù)推薦精排模型,阿里達(dá)摩院M6 1萬億參數(shù)等;很多小伙伴看的是眼花繚亂,那究竟這些模型有沒有差異?如果有差異,差異在哪里?
首先我想說這些模型都是基于Transformer結(jié)構(gòu),但是在模型擴(kuò)展上有非常大的不同。
從計(jì)算角度看,我們可以把這些大模分成3類
稠密Transformer: OpenAI GPT-3,華為盤古/鵬程盤古α(MindSpore支撐);模型規(guī)模的擴(kuò)展是全結(jié)構(gòu)的擴(kuò)容; 稀疏MoE結(jié)構(gòu)Transformer: Google Switch Transformer,智源悟道2.0,阿里M6。一般來說是選擇一個(gè)基礎(chǔ)的稠密模型,通過MoE稀疏結(jié)構(gòu)擴(kuò)展FFN部分,以此來達(dá)成模型的擴(kuò)容; 高維稀疏特征推薦模型: 快手推薦精排,我理解主要是推薦的高維稀疏特征Embedding需要超大參數(shù);
推薦類模型是一個(gè)比較獨(dú)立的計(jì)算特征網(wǎng)絡(luò),這個(gè)我們最后分析。其中相似性非常大的是稠密Transformer和稀疏MoE結(jié)構(gòu)Transformer,下面我們以Google Switch Transformer來對(duì)比兩者的差異。
下面兩張圖是Google Switch Transformer論文中和T5的對(duì)比,Switch Transformer是基于T5,通過MoE稀疏結(jié)構(gòu)擴(kuò)展。我們用Switch-Base作為這次分析對(duì)比基準(zhǔn)。
Switch-Base是基于T5-Base的MoE稀疏擴(kuò)展,模型參數(shù)規(guī)模比T5-Base大33倍,從計(jì)算角度看,內(nèi)存開銷是T5的33倍,算力開銷和T5-Base一致。同時(shí),我們拿Switch-Base和T5-Large做一個(gè)對(duì)比。Switch-Base參數(shù)規(guī)模是T5-Large的10倍,也就是說內(nèi)存開銷是T5的10倍,算力開銷是T5-Large的29%;
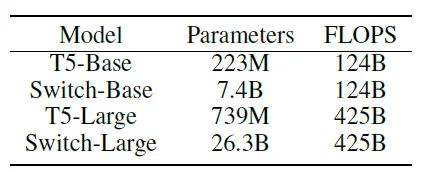
從下面這個(gè)表格的下游任務(wù)對(duì)比來看,在同樣的算力開銷下,Switch-Base的效果比T5-Base整體上要好,這個(gè)優(yōu)勢(shì)是通過33倍的內(nèi)存開銷換取的;但是同時(shí),Switch-Base在參數(shù)量比T5-Large大了10倍的情況下,效果比T5-Large要差一些。
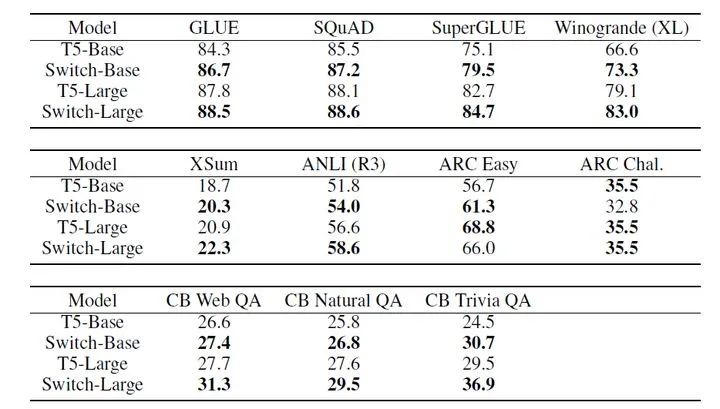
所以我們不能單純從參數(shù)規(guī)模來衡量一個(gè)網(wǎng)絡(luò)的效果,需要通過參數(shù)量和計(jì)算量來綜合對(duì)比,需要我們探索一種新的指標(biāo),綜合考慮內(nèi)存和算力開銷來評(píng)估一個(gè)模型。
另外,從Switch Transformer 1.6萬億模型來看,其計(jì)算量只有稠密T5 130億參數(shù)的10%,參數(shù)量是其100倍;如果從每個(gè)參數(shù)消耗的算力來計(jì)算,1.6萬億稀疏模型只是稠密的千分之一,即1.6萬億參數(shù)的Switch Transformer的計(jì)算量相當(dāng)于10億參數(shù)的稠密的Transformer。
那么從訓(xùn)練角度來看,MoE大模型的計(jì)算量較少,重點(diǎn)是做好模型參數(shù)的切分,從switch transformer的實(shí)踐看,主要使用數(shù)據(jù)并行+MoE并行的組合;而稠密的Transformer計(jì)算和通信量非常大,所以盤古-α需要在2K張卡上進(jìn)行訓(xùn)練,同時(shí)也需要復(fù)雜的pipeline并行/算子級(jí)模型并行/數(shù)據(jù)并行等并行切分策略來確保2k集群的算力能被充分利用,個(gè)人認(rèn)為訓(xùn)練挑戰(zhàn)更大。
從推理的角度看,MoE的模型參數(shù)量非常大,我覺得可能需要通過蒸餾/量化等手段進(jìn)行壓縮才更適合使用,挑戰(zhàn)很大,也是MoE模型推廣面臨的障礙。

快手的1.9萬億參數(shù)網(wǎng)絡(luò),是一種高維稀疏推薦網(wǎng)絡(luò),拿Google Wide&Deep來對(duì)比更為恰當(dāng)。快手推薦網(wǎng)絡(luò)的優(yōu)化,應(yīng)該是在后面的DNN層用了Transformer結(jié)構(gòu),而模型頭部的Embedding部分還是保持和傳統(tǒng)深度學(xué)習(xí)推薦網(wǎng)絡(luò)類似(沒有找到相關(guān)論文,不對(duì)請(qǐng)指正)。這類型網(wǎng)絡(luò),為了表達(dá)高維稀疏特征,會(huì)有一個(gè)超級(jí)大的Embedding,參數(shù)主要是集中在頭部的特征Embedding部分。這種類型網(wǎng)絡(luò)的訓(xùn)練方式和前面講的完全不同,核心技術(shù)是Embedding的模型并行,以及CPU/NPU的協(xié)同計(jì)算和存儲(chǔ)。華為諾亞實(shí)驗(yàn)室在今年SIGIR 2021上發(fā)表的“ScaleFreeCTR: MixCache-based Distributed Training System for CTR Models with Huge Embedding Table”是目前一種最好的訓(xùn)練方案之一,也將會(huì)在MindSpore上開源。這里就不再展開分析。
除了Transformer這種算法結(jié)構(gòu)外,還是有CNN類的超大模型,也可以分成兩類,這兩類模型也是稠密的,參數(shù)量和計(jì)算量是成正比。
超大分類層:超大規(guī)模人臉識(shí)別、圖像分類網(wǎng)絡(luò),其典型特征是CNN特征抽取之后的FC分類層超級(jí)大。例如千萬ID的人臉識(shí)別,F(xiàn)C層的參數(shù)規(guī)模就達(dá)到了50億。 超大Activation:遙感和超高分辨率圖像處理,這類網(wǎng)絡(luò)參數(shù)量不大,和傳統(tǒng)CNN的參數(shù)量類似,在百M(fèi)級(jí)別。但是這種模型的輸入數(shù)據(jù)以及計(jì)算過程中的Activation非常大。以遙感為例,平均輸入樣本的分辨率就有[30000, 30000, 4],一個(gè)樣本就有3.6GB,大的圖像有10GB以上,中間層Activation也是GB級(jí)別的大小。
所以,總的來說在NLP、多模態(tài)、推薦、圖像處理領(lǐng)域都有大模型,目前業(yè)界比較火熱討論的主要是基于Transformer+MoE結(jié)構(gòu)的NLP及多模態(tài)大模型,我們期望通過這篇文章,讓小伙伴能了解這些模型在計(jì)算上的差異。
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營維護(hù)的號(hào),大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!