
解析JVM之垃圾收集篇,超詳細!
點擊藍色“程序員的時光 ”關注我 ,標注“星標”,及時閱讀最新技術文章!

小伙伴兒們,大家好!上一次我們了解了JVM基礎知識——全面解析JVM,超詳細!
今天來學習JVM垃圾回收相關內容,作為面試必問的知識點,來深入了解一波!

1,判斷對象是否死亡
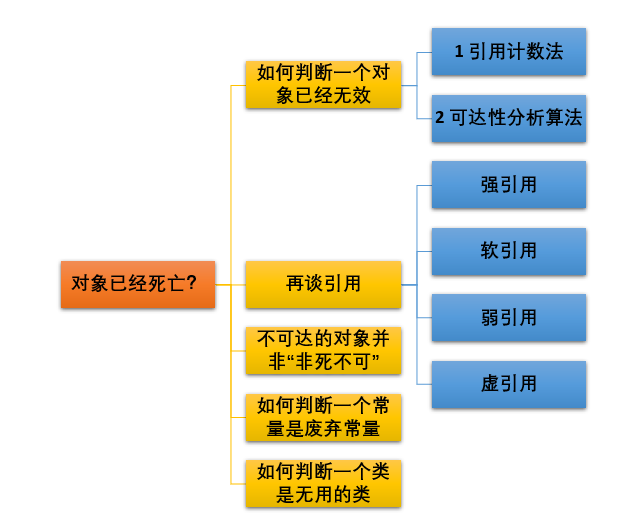
1.1,引用計數(shù)算法
public class ReferenceCountingGc {
public Object instance = null;
public static final int _1MB = 1024*1024;
public static void main(String[] args) {
ReferenceCountingGc objA = new ReferenceCountingGc();
ReferenceCountingGc objB = new ReferenceCountingGc();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
}
}
1.2,可達性分析算法

虛擬機棧(棧幀中的本地變量表)中引用的對象 方法區(qū)中類靜態(tài)屬性引用的對象 方法區(qū)中常量引用的對象 本地方法棧(Native 方法)中引用的對象
2,再談引用
reference 類型的數(shù)據(jù)存儲的數(shù)值代表的是另一塊內存的起始地址,就稱這塊內存代表一個引用。JDK1.2 以后,Java 對引用的概念進行了擴充,將引用分為強引用、軟引用、弱引用、虛引用四種(引用強度逐漸減弱)。2.1,強引用
OutOfMemoryError錯誤,使程序異常終止,也不會靠隨意回收具有強引用的對象來解決內存不足問題。2.2,軟引用
ReferenceQueue)聯(lián)合使用,如果軟引用所引用的對象被垃圾回收,JAVA 虛擬機就會把這個軟引用加入到與之關聯(lián)的引用隊列中。2.3,弱引用
ReferenceQueue)聯(lián)合使用,如果弱引用所引用的對象被垃圾回收,Java 虛擬機就會把這個弱引用加入到與之關聯(lián)的引用隊列中。2.4,虛引用
OutOfMemory)等問題的產生。3,廢棄常量以及無用類
3.1,如何判斷一個常量是廢棄常量?
abc" ,如果當前沒有任何String對象引用該字符串常量的話,就說明常量"abc"就是廢棄常量,如果這時發(fā)生內存回收的話而且有必要的話," abc"就會被系統(tǒng)清理出常量池。3.2,如何判斷一個類是無用的類?
該類所有的實例都已經被回收,也就是 Java 堆中不存在該類的任何實例。 加載該類的 ClassLoader已經被回收。該類對應的 java.lang.Class對象沒有在任何地方被引用,無法在任何地方通過反射訪問該類的方法。
4,垃圾收集算法
4.1,標記--清除算法
效率問題:標記和清除兩個過程的效率都不高; 空間問題:標記清除之后會產生大量不連續(xù)的內存碎片,空間碎片太多可能會導致以后在程序運行過程中需要分配較大對象時,無法找到足夠的連續(xù)內存而不得不提前觸發(fā)另一次垃圾收集動作。

4.2,復制算法

4.3,標記--整理算法
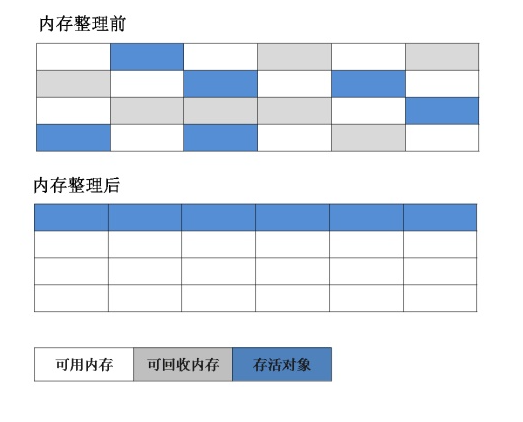
4.4,分代收集算法
5,垃圾收集器
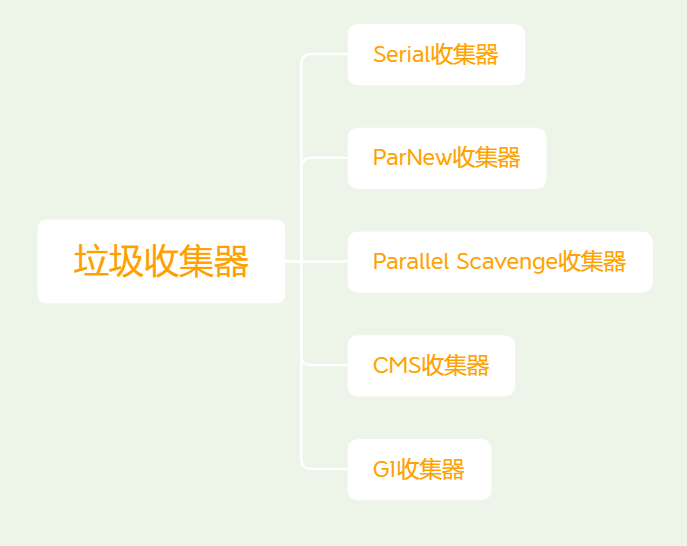
5.1,Serial收集器
Serial收集器是最基本、歷史最悠久的垃圾收集器了。從名字上看是串行的意思,這個收集器是一個單線程的新生代收集器。它的 “單線程” 的意義不僅僅意味著它只會使用一條垃圾收集線程去完成垃圾收集工作,更重要的是它在進行垃圾收集工作的時候必須暫停其他所有的工作線程( "Stop The World" ),直到它收集結束。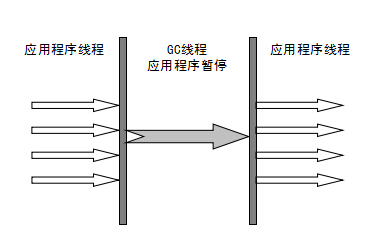
5.2,ParNew收集器
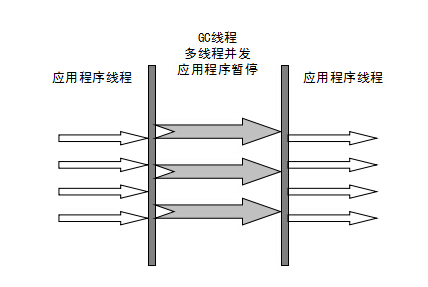
并行(Parallel) :指多條垃圾收集線程并行工作,但此時用戶線程仍然處于等待狀態(tài)。 并發(fā)(Concurrent):指用戶線程與垃圾收集線程同時執(zhí)行(但不一定是并行,可能會交替執(zhí)行),用戶程序在繼續(xù)運行,而垃圾收集器運行在另一個 CPU 上。
5.3,Parallel Scavenge收集器

java -XX:+PrintCommandLineFlags -version命令查看-XX:InitialHeapSize=197918400 -XX:MaxHeapSize=3166694400 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)

Parallel Scavenge + Parallel Old,如果指定了-XX:+UseParallelGC 參數(shù),則默認指定了-XX:+UseParallelOld GC,可以使用-XX:-UseParallelOldGC 來禁用該功能。5.4,Serial Old收集器
5.5,Parallel Old 收集器
5.6,CMS 收集器
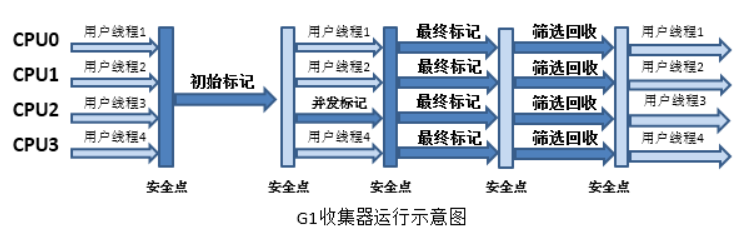
初始標記: 暫停所有的其他線程,并記錄下直接與 root 相連的對象,速度很快 ; 并發(fā)標記: 同時開啟 GC 和用戶線程,用一個閉包結構去記錄可達對象。但在這個階段結束,這個閉包結構并不能保證包含當前所有的可達對象。因為用戶線程可能會不斷的更新引用域,所以 GC 線程無法保證可達性分析的實時性。所以這個算法里會跟蹤記錄這些發(fā)生引用更新的地方。 重新標記: 重新標記階段就是為了修正并發(fā)標記期間因為用戶程序繼續(xù)運行而導致標記產生變動的那一部分對象的標記記錄,這個階段的停頓時間一般會比初始標記階段的時間稍長,遠遠比并發(fā)標記階段時間短 并發(fā)清除: 開啟用戶線程,同時 GC 線程開始對未標記的區(qū)域做清掃。

對 CPU 資源敏感; 無法處理浮動垃圾; 它使用的回收算法-“標記-清除”算法會導致收集結束時會有大量空間碎片產生。
5.7,G1 收集器
并行與并發(fā):G1 能充分利用 CPU、多核環(huán)境下的硬件優(yōu)勢,使用多個 CPU(CPU 或者 CPU 核心)來縮短 Stop-The-World 停頓時間。部分其他收集器原本需要停頓 Java 線程執(zhí)行的 GC 動作,G1 收集器仍然可以通過并發(fā)的方式讓 java 程序繼續(xù)執(zhí)行。 分代收集:雖然 G1 可以不需要其他收集器配合就能獨立管理整個 GC 堆,但是還是保留了分代的概念。 空間整合:與 CMS 的“標記--清理”算法不同,G1 從整體來看是基于“標記整理”算法實現(xiàn)的收集器;從局部上來看是基于“復制”算法實現(xiàn)的。 可預測的停頓:這是 G1 相對于 CMS 的另一個大優(yōu)勢,降低停頓時間是 G1 和 CMS 共同的關注點,但 G1 除了追求低停頓外,還能建立可預測的停頓時間模型,能讓使用者明確指定在一個長度為 M 毫秒的時間片段內。
《深入理解Java虛擬機(第2版).周志明》
https://xiaozhuanlan.com/topic/1847690325#section1java
評論
圖片
表情