
Batch Normalization的詛咒
點擊上方藍(lán)字,關(guān)注公眾號,選擇加“星標(biāo)“或“置頂”
作者:Sahil Uppal
編譯:ronghuaiyang
batch normalization時的一些缺陷。

Batch Normalization確實是深度學(xué)習(xí)領(lǐng)域的重大突破之一,也是近年來研究人員討論的熱點之一。Batch Normalization是一種被廣泛采用的技術(shù),使訓(xùn)練更加快速和穩(wěn)定,已成為最有影響力的方法之一。然而,盡管它具有多種功能,但仍有一些地方阻礙了該方法的發(fā)展,正如我們將在本文中討論的那樣,這表明做歸一化的方法仍有改進(jìn)的余地。
我們?yōu)槭裁匆肂atch Normalization?
在討論任何事情之前,首先,我們應(yīng)該知道Batch Normalization是什么,它是如何工作的,并討論它的用例。
什么是Batch Normalization
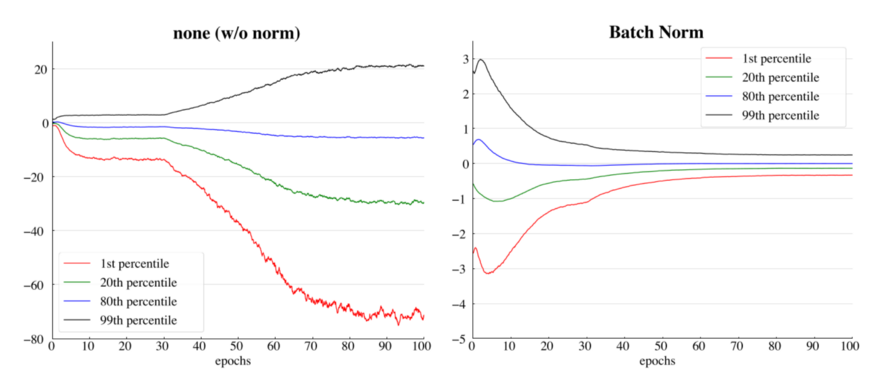
在訓(xùn)練過程中,當(dāng)我們更新之前的權(quán)值時,每個中間激活層的輸出分布會在每次迭代時發(fā)生變化。這種現(xiàn)象稱為內(nèi)部協(xié)變量移位(ICS)。所以很自然的一件事,如果我想防止這種情況發(fā)生,就是修正所有的分布。簡單地說,如果我的分布變動了,我會限制住這個分布,不讓它移動,以幫助梯度優(yōu)化和防止梯度消失,這將幫助我的神經(jīng)網(wǎng)絡(luò)訓(xùn)練更快。因此減少這種內(nèi)部協(xié)變量位移是推動batch normalization發(fā)展的關(guān)鍵原則。
它如何工作
Batch Normalization通過在batch上減去經(jīng)驗平均值除以經(jīng)驗標(biāo)準(zhǔn)差來對前一個輸出層的輸出進(jìn)行歸一化。這將使數(shù)據(jù)看起來像高斯分布。
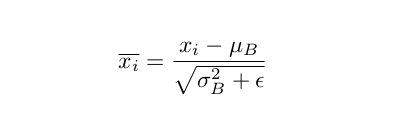
其中μ和*σ^2^*分別為批均值和批方差。
并且,我們學(xué)習(xí)了一個新的平均值和協(xié)方差γ和β。所以,簡而言之,你可以認(rèn)為batch normalization是幫助你控制batch分布的一階和二階動量。
優(yōu)點
我將列舉使用batch normalization的一些好處,但是我不會詳細(xì)介紹,因為已經(jīng)有很多文章討論了這個問題。
更快的收斂。 降低初始權(quán)重的重要性。 魯棒的超參數(shù)。 需要較少的數(shù)據(jù)進(jìn)行泛化。
Batch Normalization的詛咒
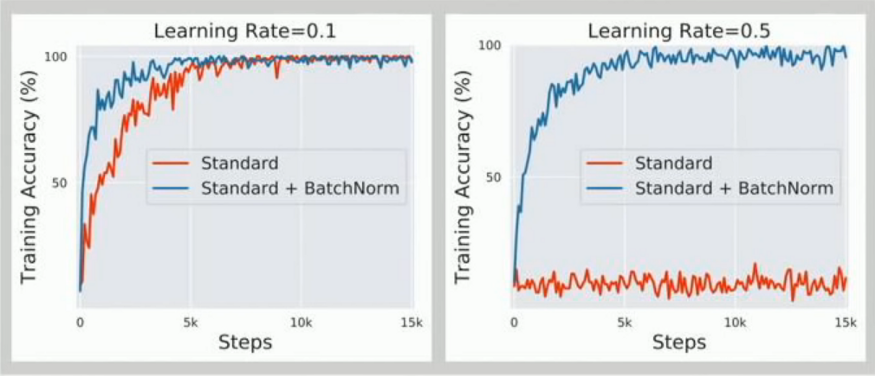
好,讓我們回到本文的出發(fā)點,在許多情況下batch normalization開始傷害性能或根本不起作用。
在使用小batch size的時候不穩(wěn)定
如上所述,batch normalization必須計算平均值和方差,以便在batch中對之前的輸出進(jìn)行歸一化。如果batch大小比較大的話,這種統(tǒng)計估計是比較準(zhǔn)確的,而隨著batch大小的減少,估計的準(zhǔn)確性持續(xù)減小。
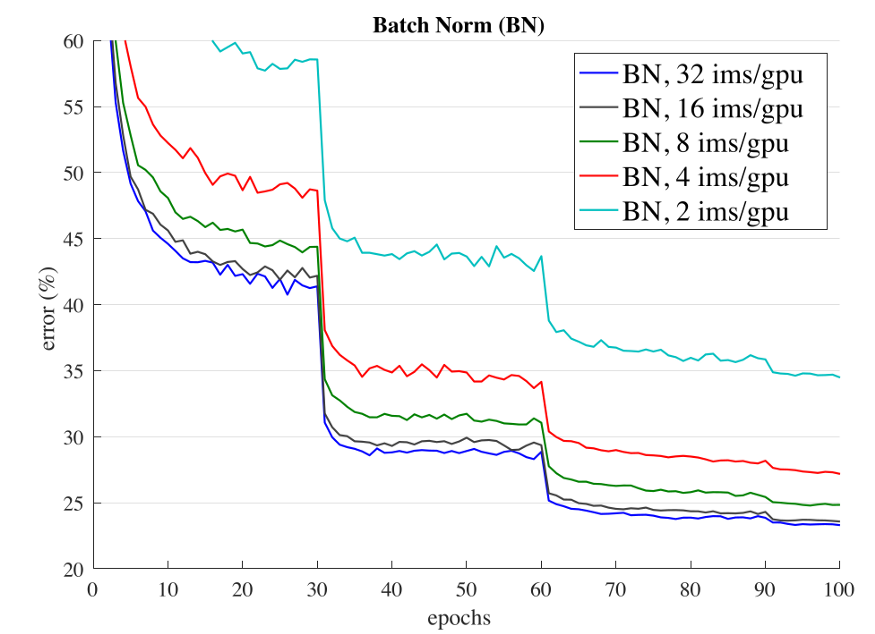
以上是ResNet-50的驗證錯誤圖。可以推斷,如果batch大小保持為32,它的最終驗證誤差在23左右,并且隨著batch大小的減小,誤差會繼續(xù)減小(batch大小不能為1,因為它本身就是平均值)。損失有很大的不同(大約10%)。
如果batch大小是一個問題,為什么我們不使用更大的batch?我們不能在每種情況下都使用更大的batch。在finetune的時候,我們不能使用大的batch,以免過高的梯度對模型造成傷害。在分布式訓(xùn)練的時候,大的batch最終將作為一組小batch分布在各個實例中。
導(dǎo)致訓(xùn)練時間的增加
NVIDIA和卡耐基梅隆大學(xué)進(jìn)行的實驗結(jié)果表明,“盡管Batch Normalization不是計算密集型,而且收斂所需的總迭代次數(shù)也減少了。”但是每個迭代的時間顯著增加了,而且還隨著batch大小的增加而進(jìn)一步增加。
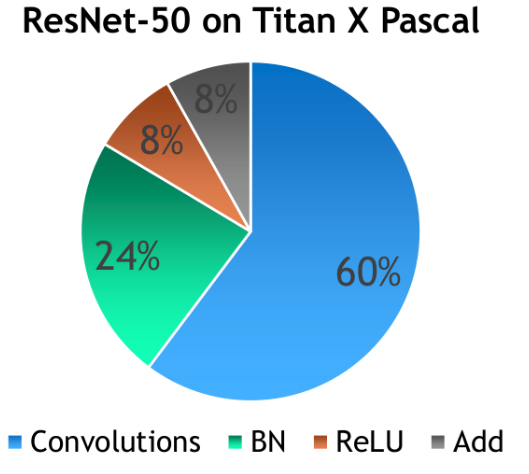
你可以看到,batch normalization消耗了總訓(xùn)練時間的1/4。原因是batch normalization需要通過輸入數(shù)據(jù)進(jìn)行兩次迭代,一次用于計算batch統(tǒng)計信息,另一次用于歸一化輸出。
訓(xùn)練和推理時不一樣的結(jié)果
例如,在真實世界中做“物體檢測”。在訓(xùn)練一個物體檢測器時,我們通常使用大batch(YOLOv4和Faster-RCNN都是在默認(rèn)batch大小= 64的情況下訓(xùn)練的)。但在投入生產(chǎn)后,這些模型的工作并不像訓(xùn)練時那么好。這是因為它們接受的是大batch的訓(xùn)練,而在實時情況下,它們的batch大小等于1,因為它必須一幀幀處理。考慮到這個限制,一些實現(xiàn)傾向于基于訓(xùn)練集上使用預(yù)先計算的平均值和方差。另一種可能是基于你的測試集分布計算平均值和方差值。
對于在線學(xué)習(xí)不好
與batch學(xué)習(xí)相比,在線學(xué)習(xí)是一種學(xué)習(xí)技術(shù),在這種技術(shù)中,系統(tǒng)通過依次向其提供數(shù)據(jù)實例來逐步接受訓(xùn)練,可以是單獨的,也可以是通過稱為mini-batch的小組進(jìn)行。每個學(xué)習(xí)步驟都是快速和便宜的,所以系統(tǒng)可以在新的數(shù)據(jù)到達(dá)時實時學(xué)習(xí)。
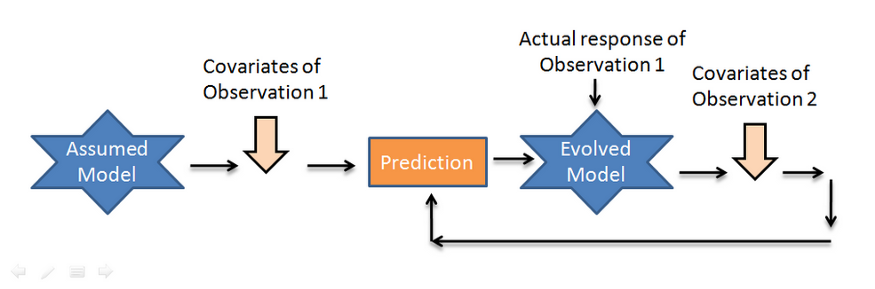
由于它依賴于外部數(shù)據(jù)源,數(shù)據(jù)可能單獨或批量到達(dá)。由于每次迭代中batch大小的變化,對輸入數(shù)據(jù)的尺度和偏移的泛化能力不好,最終影響了性能。
對于循環(huán)神經(jīng)網(wǎng)絡(luò)不好
雖然batch normalization可以顯著提高卷積神經(jīng)網(wǎng)絡(luò)的訓(xùn)練和泛化速度,但它們很難應(yīng)用于遞歸結(jié)構(gòu)。batch normalization可以應(yīng)用于RNN堆棧之間,其中歸一化是“垂直”應(yīng)用的,即每個RNN的輸出。但是它不能“水平地”應(yīng)用,例如在時間步之間,因為它會因為重復(fù)的重新縮放而產(chǎn)生爆炸性的梯度而傷害到訓(xùn)練。
[^注]: 一些研究實驗表明,batch normalization使得神經(jīng)網(wǎng)絡(luò)容易出現(xiàn)對抗漏洞,但我們沒有放入這一點,因為缺乏研究和證據(jù)。
可替換的方法
這就是使用batch normalization的一些缺點。在batch normalization無法很好工作的情況下,有幾種替代方法。
Layer Normalization Instance Normalization Group Normalization (+ weight standardization) Synchronous Batch Normalization
總結(jié)
所以,看起來訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)很簡單,但我不認(rèn)為它很容易。從這個意義上說,我可以選擇的架構(gòu)很少,每個模型都有固定的學(xué)習(xí)速度,固定的優(yōu)化器和固定的技巧。這些技巧是通過自然選擇選擇的,就像有人想出了一些技巧,人們引入之后如果有效,就會保留,如果無效,人們最終會忘記,并沒有人再去使用它。除此之外,batch normalization是深度學(xué)習(xí)發(fā)展中的一個里程碑技術(shù)。然而,正如前面所討論的,沿著batch 維度進(jìn)行歸一化引入了一些問題,這表明歸一化技術(shù)仍有改進(jìn)的空間。

英文原文:https://towardsdatascience.com/curse-of-batch-normalization-8e6dd20bc304

喜歡的話,請給我個在看吧!![]()