
頭,有點(diǎn)禿了.
我是y哥的讀者,已經(jīng)畢業(yè)幾年了,一直在做業(yè)務(wù)開發(fā),最近想要跳槽,自然就會(huì)讀讀y哥寫的對(duì)線面試官系列,畢竟現(xiàn)在面試都得搞八股文啊。
回頭看了下對(duì)線面試官的目錄,竟然已經(jīng)快刷掉一半了,不過到現(xiàn)在好像又已經(jīng)把前面刷過的忘得七七八八了。但不想那么多了,先過一遍吧。
從Java虛擬機(jī)往下就是Spring章節(jié)了,而Spring章節(jié)有三篇文章:Spring基礎(chǔ)、SpringMVC、SpringBean生命周期。沒有SpringBoot和SpringCloud是我預(yù)料之外的,感覺這兩塊也是會(huì)出很常見的面試題,不知道第二季能不能補(bǔ)上呢。對(duì)于Spring這個(gè)章節(jié),我很快就刷完了,大多數(shù)都是概念理解的東西,要是真問到細(xì)節(jié)我也記不住。
《Spring基礎(chǔ)》主要講了什么是iOC和AOP,進(jìn)而引出了SpringBean生命周期,而生命周期大概就是在SpringBean的各個(gè)重要節(jié)點(diǎn)(定義/代理/初始化后/銷毀)上提供hook給我們?nèi)U(kuò)展。
《SpringBean生命周期》中間的那些細(xì)節(jié)我是不太關(guān)心的,反正意思到位了,就是提供擴(kuò)展鉤子嘛,順便理解下循環(huán)依賴是怎么解決的,原來就這么回事。
《SpringMVC》就是Spring的webmvc模塊的內(nèi)容了,主要就是考察個(gè)處理流程,這個(gè)背得朗朗上口了:映射器->適配器->攔截器->真實(shí)調(diào)用->視圖解析器,看源碼后也就這么個(gè)結(jié)論,所以不難。
看完了之后,原來Spring就已經(jīng)提供了這么多擴(kuò)展,原來攔截器是在這個(gè)過程中生效的...總的來說吧,看看這種內(nèi)容對(duì)日常寫代碼還是有點(diǎn)用的,但不多。
Spring章節(jié)后就是Redis章節(jié),Redis是內(nèi)存存儲(chǔ),現(xiàn)在幾乎在后端里是標(biāo)配了。我覺得看Redis比看什么JVM有價(jià)值多了,Redis不會(huì)用會(huì)影響到接口性能,而JVM不會(huì)用也不會(huì)影響到啥。
《Redis基礎(chǔ)》挺簡單的,就介紹了下在線上什么場(chǎng)景用了Redis,這個(gè)我會(huì)套回到自己的項(xiàng)目上的,沒啥好講的。而為什么Redis快,那首要原因肯定是內(nèi)存啊,其次就是非阻塞的IO多路復(fù)用機(jī)制避免上下文切換所帶來的吧。
《Redis持久化》這個(gè)我們?cè)谑褂玫臅r(shí)候一般都不關(guān)注,正如在使用MySQL的時(shí)候不關(guān)心它是怎么落盤的,因?yàn)槲覀冋J(rèn)為就是理所當(dāng)然的。而AOF/RDB持久化一般都是由維護(hù)Redis集群的人所配置的,了解下這個(gè)機(jī)制是可以的,但對(duì)應(yīng)用開發(fā)沒多大的幫助。面試要是真問到了,經(jīng)過這一輪復(fù)習(xí),應(yīng)該也能大致講講。
《Redis主從架構(gòu)》和《Redis分片集群》我覺得這個(gè)還是得懂的,就在公司里Redis的架構(gòu)是怎么樣的,是cluster 集群模式呢,還是主從模式,還是通過proxy做分片呢,不同的架構(gòu)會(huì)影響到我們對(duì)它的使用。
比如,如果我是redis cluster模式,這時(shí)候我使用批量的命令,是不是對(duì)批量所帶來的提升就沒那么大了(畢竟已經(jīng)數(shù)據(jù)已經(jīng)被分配到不同的節(jié)點(diǎn)了,不還是得分發(fā)到不同的節(jié)點(diǎn)中進(jìn)行命令傳遞),這種架構(gòu)下可以做什么來盡可能適配批量的命令?比如說hash tag / 計(jì)算好key的節(jié)點(diǎn)再做并發(fā)啥的,而這些是需要了解Redis部署的架構(gòu)才能理解為啥這樣做的。
《Redis主從架構(gòu)》主要講的是主從架構(gòu)下,數(shù)據(jù)同步(完全和部分同步是怎么做的),如果服務(wù)器出了問題,那哨兵的選舉過程是怎么樣的。這個(gè)我感覺了解就好了,不會(huì)影響到我們正常的使用,出了問題也輪不到我們這些做業(yè)務(wù)開發(fā)的去查。不過可以順著這些功能,想想其他的存儲(chǔ)是不是也類似這么做的。
《Redis分片集群》這種架構(gòu)在互聯(lián)網(wǎng)里是比較常見了,現(xiàn)在基本出去都說什么分布式,分片集群這種模式就算是分布式了。而要實(shí)現(xiàn)數(shù)據(jù)分發(fā)到不同的節(jié)點(diǎn),可以采用官方的Cluster方案,也可以做Proxy,這兩種方案各有各的優(yōu)缺點(diǎn)。原來Cluster方案的Hash槽是16384個(gè),至于為什么這么多,是作者認(rèn)為的合理值,沒有啥大的探討意義。(求面試的時(shí)候別問我這個(gè)玩意,真沒意思),不過在這側(cè)面可以說明節(jié)點(diǎn)之間的網(wǎng)絡(luò)通信確實(shí)是挺大的。
Redis章節(jié)總體看下來,看似都是八股文,但如果懂這些東西,會(huì)給你在使用Redis的時(shí)候有種莫名的信心,即便出了問題也不會(huì)太慌。不過如果深挖細(xì)節(jié),那確實(shí)還是八股文。
Redis章節(jié)后面是消息隊(duì)列,消息隊(duì)列就只有兩篇文章《Kafka基礎(chǔ)》和《使用Kafka會(huì)考慮什么問題》,沒有別的MQ確實(shí)挺可惜的,但是估計(jì)面試也夠用了,一般面試官也不會(huì)各種MQ的,反正都是舉一反三的嘛。不過,看完我覺得不夠細(xì),不夠八股文,沒有那股味道,都是以線上的角度去聊怎么用Kafka的,很多原理性的東西都沒有。雖然我本身不愛看這些東西,但面試就是要啊,希望后面y哥可以補(bǔ)充補(bǔ)充。
《Kafka基礎(chǔ)》主要是講了為啥Kafka那么快,這個(gè)可以盲猜 順序?qū)懞筒僮飨到y(tǒng)cache(我感覺換每種存儲(chǔ)都可以這樣盲猜,反正思想都是一樣的)。。然后再結(jié)合Kafka的天然架構(gòu),多partition,這不就是并行嗎。然后再說說中間的讀寫做了零拷貝,這就是它能這么快的原因了。
不過零拷貝這個(gè)我看完了,也不太好去描述,感覺有點(diǎn)理論性,也挺難記的。知道零拷貝有mmap和sendfile,但描述這個(gè)過程我總感覺嘴瓢。。
《使用Kafka會(huì)考慮什么問題》這個(gè)文章就是針對(duì)消息不丟失,消息順序性,結(jié)合業(yè)務(wù)做的解釋,沒過多的理論在,全憑業(yè)務(wù)在吹水。不過,如何在client實(shí)現(xiàn)至少一次消息,這個(gè)還是可以去看看的。
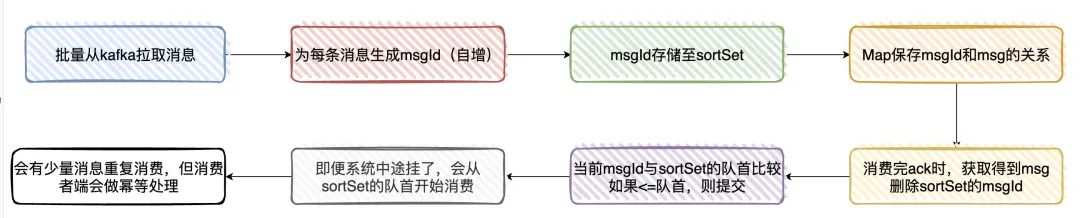
這兩天看的這三章,感覺沒有那么的八股文,但我又想多點(diǎn)八股文的內(nèi)容,真TM的矛盾。產(chǎn)生這種矛盾可能就在于,這些在生產(chǎn)環(huán)境下是真的有在用的,學(xué)了這些真有可能會(huì)讓自己所維護(hù)的程序變得更好,至少不像什么JVM和并發(fā)的八股文,看完用不上就立馬忘了。
最近看這破八股文,頭都大了。