
面試官:簡述MySQL中order by的實(shí)現(xiàn)原理
你知道的越多,不知道的就越多,業(yè)余的像一棵小草!
你來,我們一起精進(jìn)!你不來,我和你的競爭對(duì)手一起精進(jìn)!
編輯:業(yè)余草
推薦:https://www.xttblog.com/?p=5167
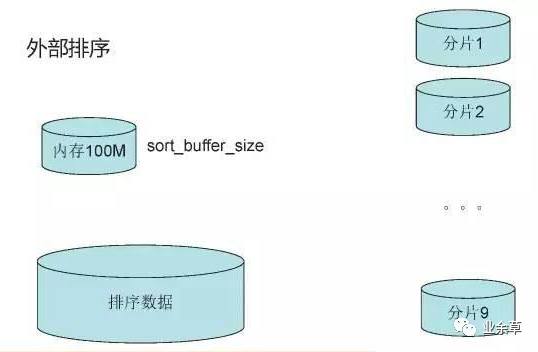
全字段排序
MySQL會(huì)給每個(gè)線程分配一塊內(nèi)存用于排序,稱為sort_buffer。
語句的執(zhí)行流程:
(1)初始化sort_buffer,確定放入select的字段
(2)找到滿足條件的行取出select的字段存入sort_buffer中
(3)一直查找到不滿足條件的為止
(4)對(duì)sort_buffer中的數(shù)據(jù)按照排序的字段做排序
sort_buffer_size可以設(shè)置sort_buffer的大小。如果要排序的數(shù)據(jù)量小于 sort_buffer_size,排序就在內(nèi)存中完成。但如果排序數(shù)據(jù)量太大,內(nèi)存放不下,則不得不利用磁盤臨時(shí)文件輔助排序。
rowid排序
max_length_for_sort_data,是 MySQL 中專門控制用于排序的行數(shù)據(jù)的長度的一個(gè)參數(shù)。它的意思是,如果單行的長度超過這個(gè)值,MySQL 就認(rèn)為單行太大,要換一個(gè)算法。
語句執(zhí)行流程:
(1)初始化sort_buffer,確定放入id和要排序的字段
(2)找到滿足條件的行取出這兩個(gè)字段存入sort_buffer中
(3)一直查找到不滿足條件的為止
(4)對(duì)sort_buffer中的數(shù)據(jù)按照排序的字段做排序
(5)遍歷排序結(jié)果,并按照id的值回表取出select的字段
如果MySQL認(rèn)為內(nèi)存足夠大就會(huì)使用全字段排序,否則會(huì)使用rowid排序。對(duì)于 InnoDB 表來說,rowid 排序會(huì)要求回表多造成磁盤大量隨機(jī)讀,因此不會(huì)被優(yōu)先選擇。