
風(fēng)控ML[16] | 風(fēng)控建模中怎么做拒絕推斷

00 Index
01 什么是拒絕推斷?
02 為什么要做拒絕推斷?
03 什么時(shí)候做拒絕推斷?
04 做拒絕推斷都有哪些方法?
05 驗(yàn)證拒絕推斷效果的方式
06 總結(jié)一下
?? 01 什么是拒絕推斷
拒絕推斷要解決的問題就是去推斷那些被拒絕的客戶,如果放貸的話,后續(xù)的貸后表現(xiàn)是什么樣子,是好樣本,還是壞樣本?并把推斷的結(jié)果,加入到建模樣本中用于豐富樣本的多樣性,縮小與總體分布之間的差異。
?? 02 為什么要做拒絕推斷
在我們的生活中,有很多關(guān)于幸存者偏差的例子,比如我們身邊的同事月收入都是過萬,就誤以為大多數(shù)人都是這樣子,身邊的人都是本科畢業(yè),就以為大多數(shù)人都上過大學(xué)。同樣的,在金融建模領(lǐng)域也會(huì)有這種現(xiàn)象,那就是很多壞客戶可能被我們拒絕準(zhǔn)入了,所以長期以往庫內(nèi)的客戶,都基本上算是不那么差的客戶,那么如果我們直接拿這些數(shù)據(jù)來統(tǒng)計(jì)建模,就會(huì)出現(xiàn)了偏差,也就是用局部樣本代替了全局樣本,從而可能會(huì)得到不太能代表真實(shí)分布的模型,出現(xiàn)了線下回溯效果好,但上生產(chǎn)實(shí)際去跑之后的表現(xiàn)卻不盡人意。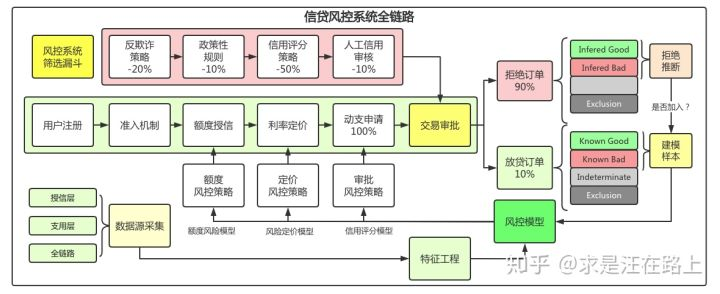 圖:來自于https://zhuanlan.zhihu.com/p/8862498
圖:來自于https://zhuanlan.zhihu.com/p/8862498
這就是我們?yōu)槭裁匆鼍芙^推斷的主要原因,我們需要加入一些“壞客戶”,從而讓我們的抽樣能夠盡可能描述總體的情況,避免出現(xiàn)上述情況。
?? 03 什么時(shí)候做拒絕推斷
一般情況下都不太需要去做拒絕推斷的,但如果很多次模型部署上線后的效果都不太好并且找不到原因的話,那可以考慮走這一步了。當(dāng)然,如果條件不允許拿線上來隨便迭代測試,也可以在建模前,做好庫內(nèi)樣本的分布統(tǒng)計(jì),并且拿著與預(yù)授信環(huán)節(jié)(或者是營銷環(huán)節(jié))的客群分布來對比下模型主要的特征分布,看看兩者是否有比較明顯的差異,如果是的話,有很大概率也是因?yàn)橛辛溯^大的偏差了,這個(gè)需要也需要我們?nèi)プ鼍芙^推斷。
但是有些場景,其實(shí)也沒有太大的做拒絕推斷的必要。比如說,審批通過率很高的場景,這樣子其實(shí)貸后樣本基本上與真實(shí)的客群分布相差無幾;相反地,另一個(gè)極端,比如審批通過率很低的場景,由于拒絕推斷與真實(shí)貸后表現(xiàn)之間會(huì)存在比較大的差異,加入拒絕樣本不太好去控制模型的收斂,或者說模型性能會(huì)很難有較好的提升。
?? 04 做拒絕推斷都有哪些方法
這里的方法介紹,我在知乎上看到汪哥的相關(guān)文章,寫得真的是太棒了!我比較難超越了,就把他的原文鏈接??貼過來,大家可以去看看哦。
《風(fēng)控建模中的樣本偏差與拒絕推斷》https://zhuanlan.zhihu.com/p/88624987
不過我也還是把他文章里的分類體系在這里重點(diǎn)再次分享一下。 其中,數(shù)據(jù)法中提到的3種方式都是比較好理解的。
其中,數(shù)據(jù)法中提到的3種方式都是比較好理解的。
方法一:簡單說就是把模型應(yīng)該拒絕的客戶,按照一定規(guī)則(比如不那么壞的客戶)給予審批通過的決策,后續(xù)觀察其貸后表現(xiàn),給未來的模型提供更豐富的數(shù)據(jù); 方法二:指的是從其他機(jī)構(gòu)或者類似產(chǎn)品中獲得客戶的貸后表現(xiàn)數(shù)據(jù),從而來撈回一些拒絕的客戶,給予這些客戶好壞的標(biāo)簽,用于后續(xù)的建模; 方法三:從人工審核的流程中找到具體的拒絕原因,根據(jù)描述,人工給予拒絕客戶好壞標(biāo)簽。
而對于推斷法就會(huì)相對比較復(fù)雜一點(diǎn),這里就不一一展開來說了,就講一個(gè)比較經(jīng)典的展開法(Augmentation)。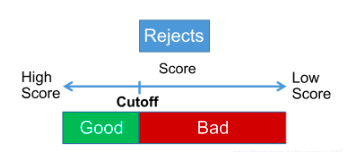
展開法的實(shí)施步驟主要是:
1、拿到貸后的樣本,按照一定的好壞樣本定義規(guī)則打上Y值,接著就是常規(guī)操作,得到 評分卡模型A;
2、拿著評分卡模型A,去對全量樣本(包含拒絕的)進(jìn)行打分,得到每個(gè)樣本的模型分P(good);
3、將拒絕樣本的模型分P進(jìn)行降序,設(shè)置cutoff。cutoff一般按照業(yè)務(wù)經(jīng)驗(yàn)來設(shè)置,就是拒絕樣本中被賦予通過的樣本,其badrate水平,是正常放款樣本中的badrate水平的2~4倍;
4、根據(jù)步驟3設(shè)置的cutoff,高于這個(gè)閾值的賦予good標(biāo)簽,低于閾值則賦予bad標(biāo)簽;
5、最后利用全量樣本(包括拒絕的)進(jìn)行建模,得到新的評分卡模型B。
以上的5個(gè)步驟,就是實(shí)施拒絕推斷中推斷法之一的展開法。
?? 05 驗(yàn)證拒絕推斷效果的方式
最直接的方法就是使用AB Test,將部分訂單使用原模型,部分訂單使用加入拒絕樣本建立的模型,cutoff設(shè)置一樣的badrate,然后線上實(shí)際運(yùn)行進(jìn)行效果評估。如果加入拒絕推斷后的模型可以帶來更好的效果(比如放款率高且壞賬率低),則代表模型有效!
但是,如果我們并沒有這么多時(shí)間或者成本來做測試,也可以通過統(tǒng)計(jì)單變量的IV值來輔助判斷,因?yàn)榻?jīng)驗(yàn)得知,做了拒絕推斷后加入拒絕樣本,可以讓變量IV值帶來提升。
?? 06 總結(jié)一下
本文算是一個(gè)對拒絕推斷的入門介紹了,讓初涉風(fēng)控模型的同學(xué)有一個(gè)相對來說比較清晰的全局認(rèn)識(shí),這里面涉及到的很多算法模型上的細(xì)節(jié)并沒有展開來講,因?yàn)槲矣X得這也會(huì)讓閱讀帶來比較大的負(fù)擔(dān),公眾號(hào)的文章還是要控制在幾分鐘內(nèi)讀完比較合適。不過,我也把相關(guān)其他博主這塊算法模型寫得比較清晰易懂的文章,分享給大家,感興趣的同學(xué)可以抽空到電腦上細(xì)細(xì)研究拜讀嘻嘻,我覺得這十分值得我們花時(shí)間去理解去吸收!
?? Reference
[1] 異常檢測算法分類及經(jīng)典模型概覽
https://blog.csdn.net/cyan_soul/article/details/101702066
[2] 風(fēng)控建模中的樣本偏差與拒絕推斷
https://zhuanlan.zhihu.com/p/88624987
[3] 【模型迭代】拒絕推斷(RI)
https://blog.csdn.net/sunyaowu315/article/details/94830732