
百度團隊新作:Spatial Shift MLP
前言
近期,Transformer和MLP結(jié)構(gòu)拋棄了CNN的歸納偏置,沖擊著視覺領(lǐng)域。其中視覺MLP開山作MLP-Mixer拋棄了卷積,自注意力的結(jié)構(gòu),僅使用全連接層。 為了對不同的Patch進行交互,除了常規(guī)的channel-mixing MLP,還引入了額外的token-mixing(也就是將特征圖轉(zhuǎn)置下,再接MLP)。這些方法為了達到優(yōu)異的性能,需要在大型數(shù)據(jù)集上預(yù)訓(xùn)練。
為此我們分析了其中的token-mixing,發(fā)現(xiàn)其等價于一個擁有全局感受野,且空間特異性的Depthwise卷積,但這兩個特性會引入過擬合的風(fēng)險。為此我們提出了Spatial-shift MLP結(jié)構(gòu),我們拋棄了token-mixing的過程,而引入了空間移位操作,它具有局部感受野,并且是spatial-agnostic。
論文地址:https://arxiv.org/abs/2106.07477
回顧MLP-Mixer
這里先簡單介紹下MLP-Mixer的原理
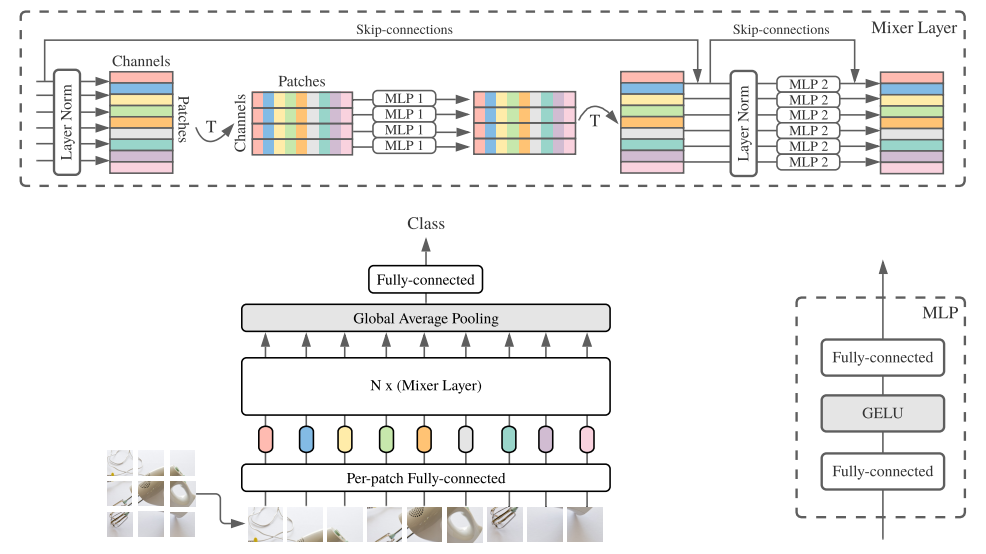
首先跟ViT一樣,把圖片切成多個patch,并進行一個Embedding操作 經(jīng)過一層LayerNorm 對特征圖進行轉(zhuǎn)置,從 N, P, C轉(zhuǎn)置為N, C, P經(jīng)過MLP結(jié)構(gòu),這兩步也叫 token-mixing再轉(zhuǎn)置回來,加入殘差連接 經(jīng)過一層LayerNorm,再經(jīng)過MLP結(jié)構(gòu),這叫 channel-mixing加入殘差連接
整個流程如圖所示:
與Depthwise卷積的聯(lián)系
熟悉Depthwise卷積的同學(xué)都知道,它是分組卷積的一個特例,即每次卷積只對輸入的一個通道進行處理,也就是說與其他通道并沒有交互。
這里簡單畫了個圖,假設(shè)我們輸入時一個4x4的圖片,我們以2x2的patch切下來,并且做轉(zhuǎn)置。
其中P表示Patch,C表示Channel
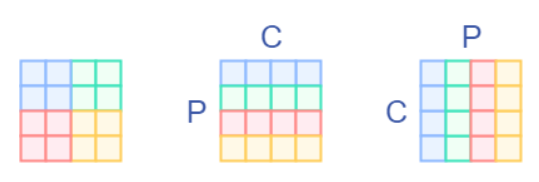
然后我們接如一個全連接層,這里其實就是做一個矩陣乘
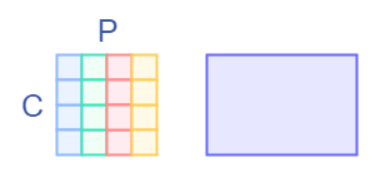
可以看到在做矩陣乘的時候,左邊矩陣參與運算的只有每一行元素,而每一行元素都是單一的通道,這和Depthwise的操作是一致的。
此外,Depthwise卷積也保留了卷積的局部,空間共享性。而token-mixing操作則是引入了全局性質(zhì),不同空間上,對應(yīng)的權(quán)重也不一樣。因此我們可以認為token-mixing是Depthwise的一個變體。
Spatial Shift MLP怎么做?
想要去掉token-mixing操作,那就需要找到一個能夠加強各個Patch間聯(lián)系的操作。受視頻理解模型TSM啟發(fā),TSM通過時序移位操作,建模相鄰幀的時序依賴關(guān)系。Spatial Shift MLP引入空間移位操作,來增強各個Patch的聯(lián)系。
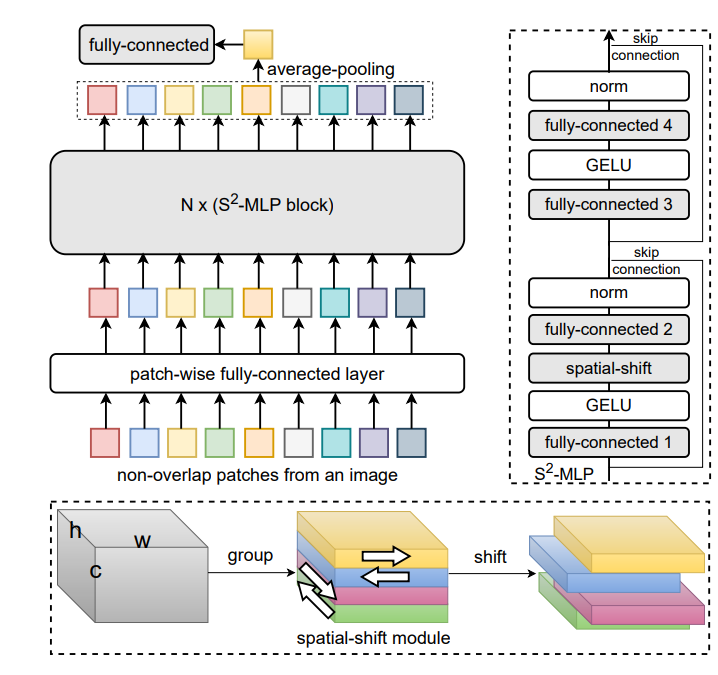
Spatial shift operation
首先我們給定一個輸入X,其形狀為W, H, C
然后將該輸入在通道維度上進行分組,這里我們只移動四個方向,因此分為四組,然后每一組為W, H, C/4。
接著是對每組輸入進行不同方向的移位操作,以第一組為例子,我們在W維度上移一格,第二組在W操作反著移一格。同理另外兩組在H維度上進行相同操作。一段偽代碼如下所示:
def spatial_shift(x):
w,h,c = x.size()
x[1:,:,:c/4] = x[:w-1,:,:c/4]
x[:w-1,:,c/4:c/2] = x[1:,:,c/4:c/2]
x[:,1:,c/2:c*3/4] = x[:,:h-1,c/2:c*3/4]
x[:,:h-1,3*c/4:] = x[:,1:,3*c/4:]
return x
而這四個移位操作,其實等價與四個固定權(quán)重的分組卷積,各卷積核權(quán)重如下所示:
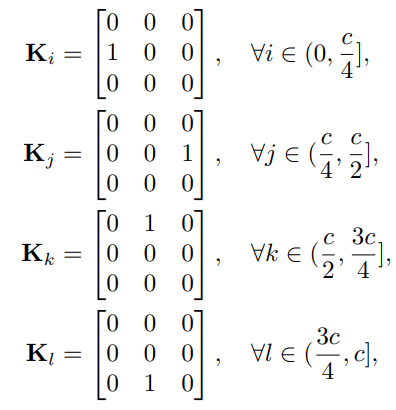
整個Spatial-shift Block和MLP-Mixer的Block差不多,這離不過多闡述,可以參考上面的示意圖。
復(fù)雜度分析
這里只分析整個Block的復(fù)雜度。
給定輸入通道為c, Block中需要擴增維度,我們定義擴增后的維度為
這里全連接層參數(shù)都帶有偏置項
前面兩個全連接層不改變通道數(shù),因此這兩個參數(shù)量為
接著一個全連接層需要擴增維度,參數(shù)量為
最后全連接層將維度恢復(fù)回來,參數(shù)量為:
總的參數(shù)量為:
得到總參數(shù)量,我們可以很容易得到FLOPS,我們假設(shè)輸入特征圖有M個Patch,則一個Block的FLOPS為:
實驗結(jié)果
我們分別設(shè)計了wide和deep兩種結(jié)構(gòu),主要區(qū)別在全連接層通道數(shù)量和Block的數(shù)量
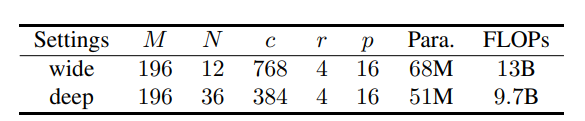
下面是實驗對比,基于ImageNet-1K數(shù)據(jù)集訓(xùn)練
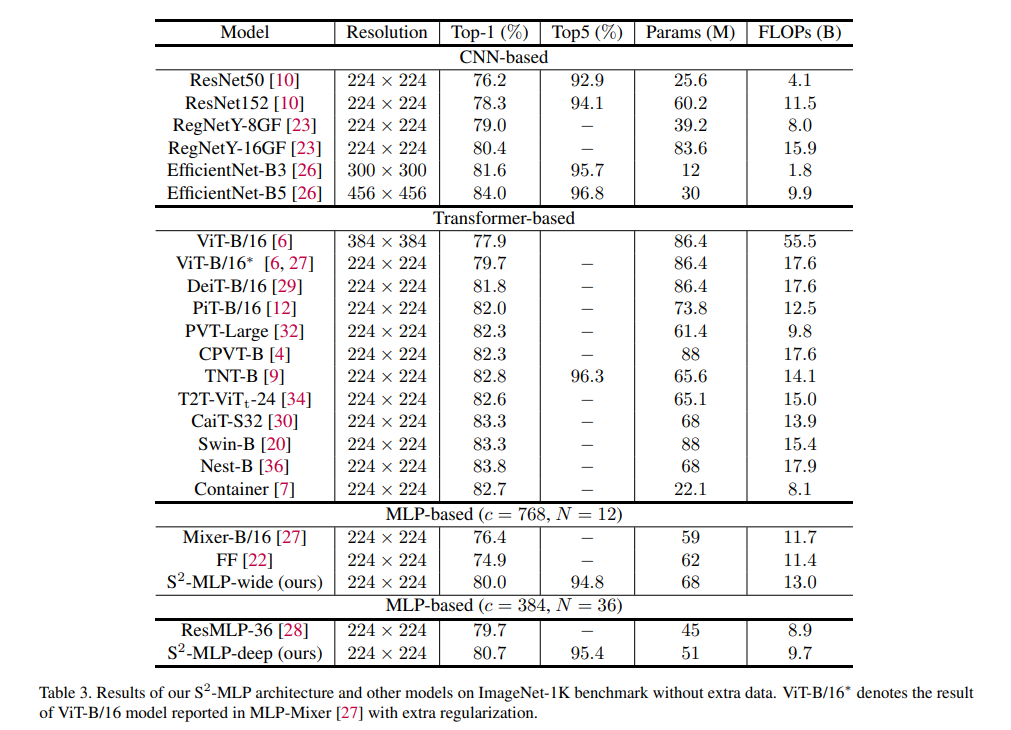
在沒預(yù)訓(xùn)練的情況下,表現(xiàn)還是不錯的
消融實驗
常規(guī)的Block數(shù)目,通道數(shù)的消融實驗這里省略,有興趣的讀者可以翻下原文。我們這里看下其他幾個有意思的實驗。
消融實驗的數(shù)據(jù)集為ImageNet的子集ImageNet100,因此準確率會和前面的結(jié)果不一樣
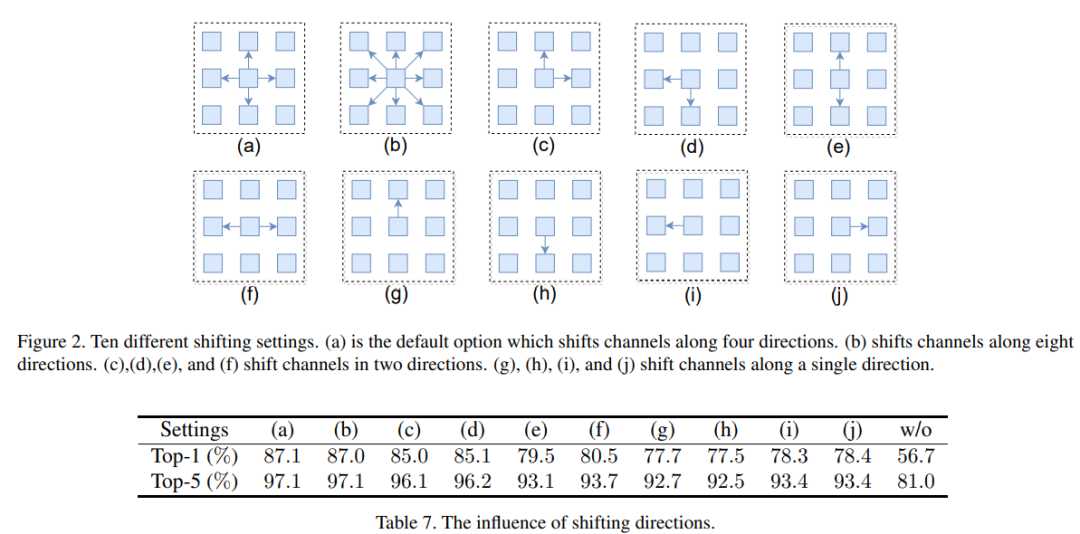
首先是shift操作的消融實驗,作者是基于八個方向shift進行對比,發(fā)現(xiàn)還是上下左右這四個方向移位效果最好
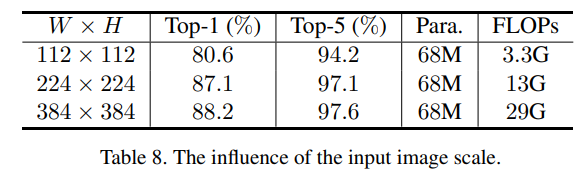
增大輸入圖像尺寸能大幅提升準確率,同時增加很多運算量
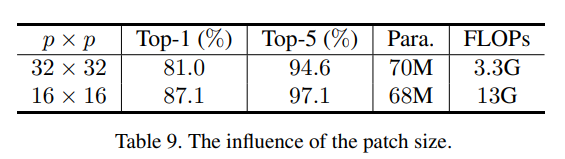
Patchsize變小也能大幅提升準確率,比較小的patch能有助于獲取細節(jié)信息,但是增加了patch數(shù)量,模型FLOPS也大幅增加
總結(jié)
之前沒寫MLP-Mixer是因為我覺得谷歌又玩起那套祖?zhèn)鱆FT預(yù)訓(xùn)練的騷操作,普通人根本玩不了,沒有實用價值。隨著不斷的探索,研究者加入一些適當?shù)钠媚軌驕p少對大數(shù)據(jù)集的依賴(跟ViT那套是不是很相似?)。這篇工作思想也很樸實,借鑒了TSM的移位操作,來給MLP加入空間相關(guān)的偏置,在ImageNet1K也能得到不錯的效果,個人還是希望能有一個更樸實高效的移動端MLP模型供我這種沒卡的窮人使用。
歡迎關(guān)注GiantPandaCV, 在這里你將看到獨家的深度學(xué)習(xí)分享,堅持原創(chuàng),每天分享我們學(xué)習(xí)到的新鮮知識。( ? ?ω?? )?
有對文章相關(guān)的問題,或者想要加入交流群,歡迎添加BBuf微信: