
還在搜百度圖片?太LOW了!

文 | 閑歡
來源:Python 技術(shù)「ID: pythonall」
感分割線")
你現(xiàn)在還去什么圖片網(wǎng)站搜圖片嗎?
你現(xiàn)在還在百度圖片等圖片網(wǎng)站搜素材嗎?
今天給大家分享一種全新的方式來獲取圖片素材,你想要的這里全都有!
它就是新浪微博!全新一代的超級流量入口,甚至好多人現(xiàn)在將其作為替代百度搜索的工具,以前是有事問度娘,現(xiàn)在是有事搜微博。
比如,某宅男想要看清純少女圖片,越多越好的那種。他會這樣搜:
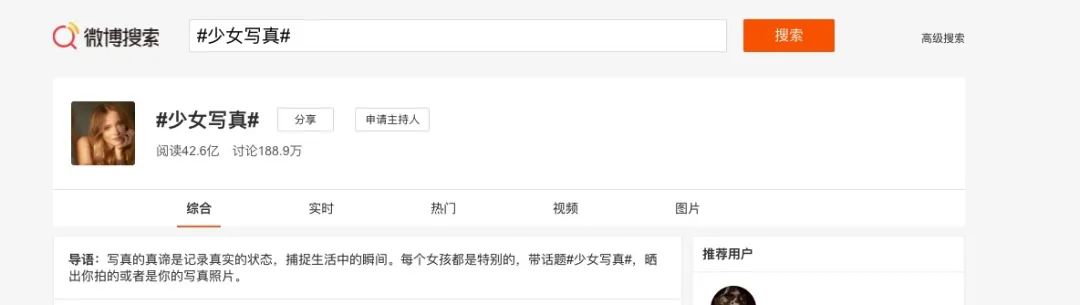
然后,他會一頁一頁地翻閱欣賞這樣的養(yǎng)眼圖片,遇到特別喜歡的還會下載大圖到本地保存。
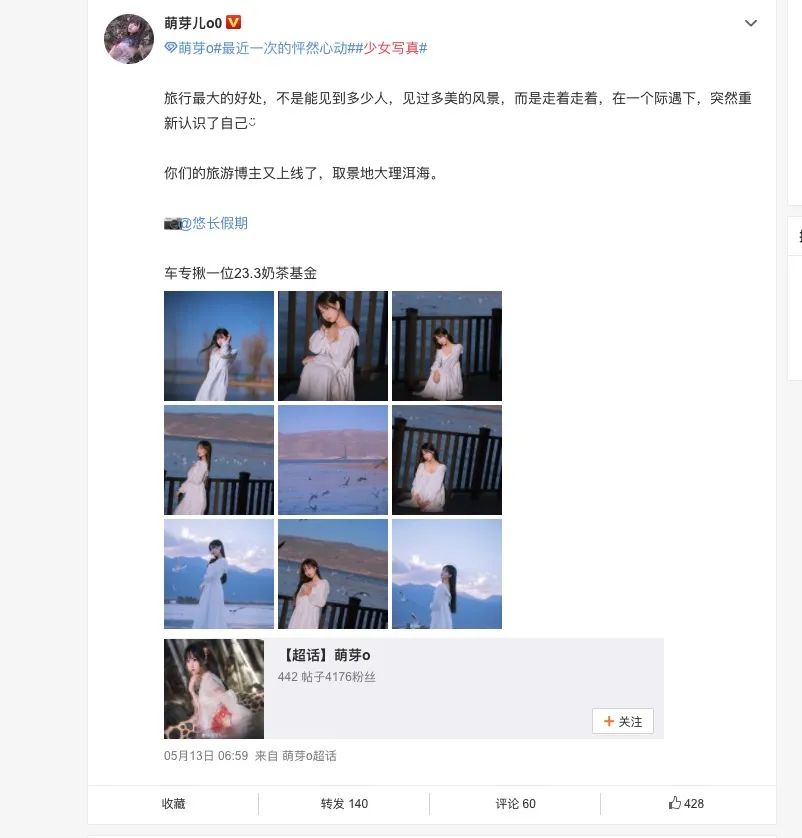
作為一個 python 程序員,我是懶得這樣一頁又一頁的翻的,我喜歡全部下載下來慢慢欣賞,撐爆硬盤的那種!類似下面這樣:
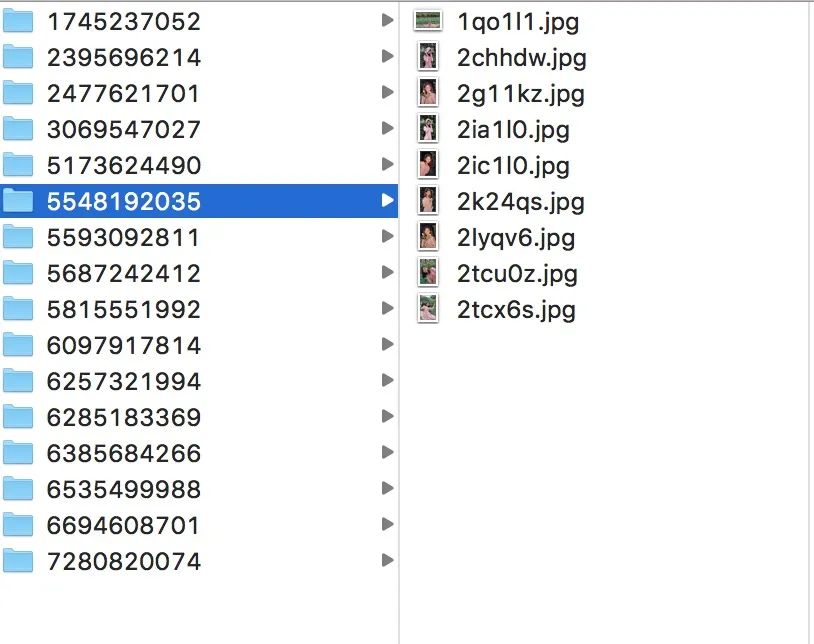
這種簡單問題對于我們會寫爬蟲的 pythoner 來說,簡直易如反掌,何樂而不為呢?下面直接給大家分享一下。
分析目標(biāo)網(wǎng)站
微博這個搜索結(jié)果是分頁的,所以我們的思路肯定是按分頁來處理,逐頁解析。
我們先來看看搜索結(jié)果:
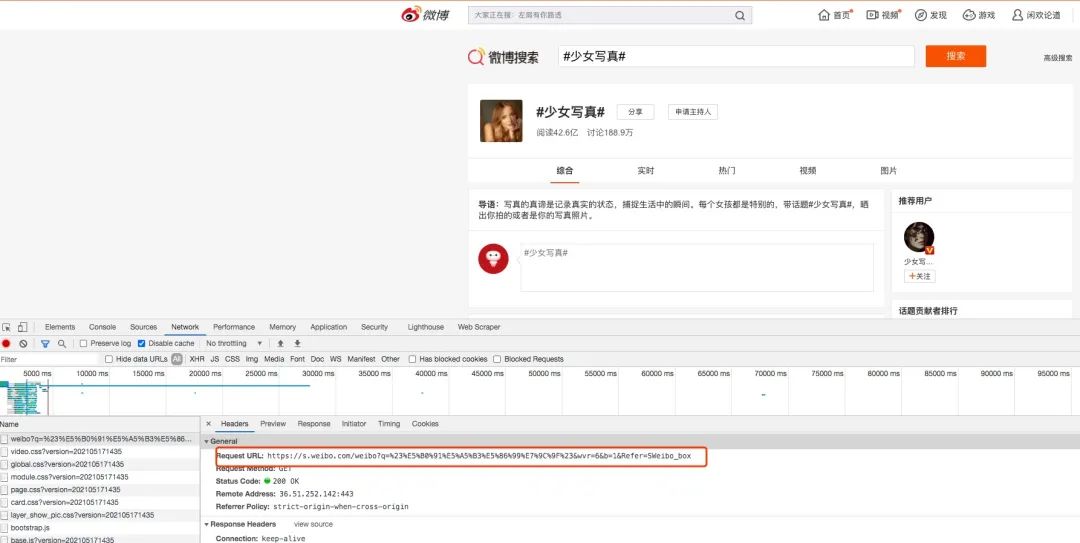
我們點(diǎn)擊“搜索”按鈕后,很容易就可以發(fā)現(xiàn)這個搜索的請求,這里網(wǎng)頁呈現(xiàn)的是第一頁的結(jié)果。
接著我們點(diǎn)擊“下一頁”,可以發(fā)現(xiàn)請求變成下面這樣:
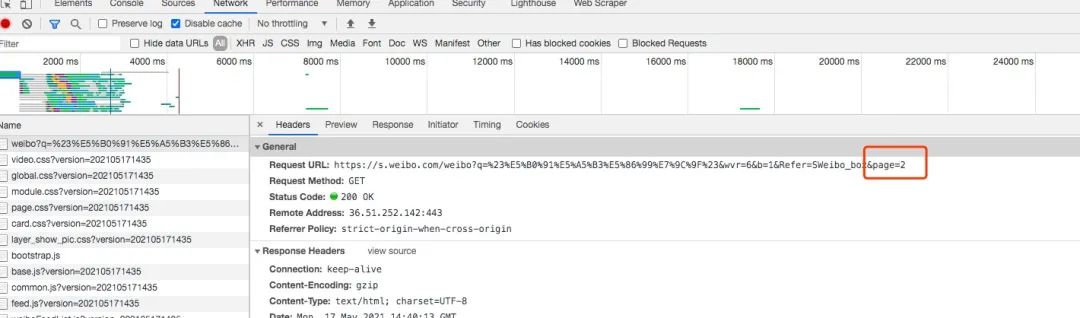
細(xì)心的你可能一眼就發(fā)現(xiàn)了,請求后面多了一個page參數(shù),它指的是頁碼,這樣就很容易了,我們只需要改變這個頁碼就可以請求到相應(yīng)頁面的內(nèi)容。
由于這個請求返回的是一個 HTML 頁面,所以我們需要在這個頁面上下功夫,找到圖片的鏈接。我們隨便使用頁面元素檢查來定位一張圖片,就會看到下面的效果:
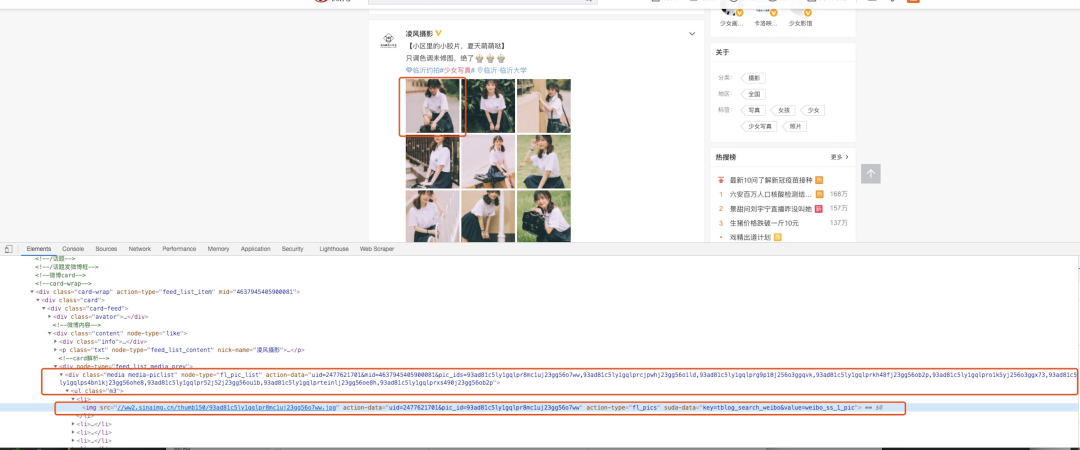
我們可以看到這個 div 里面的 action-data 是一個合集,而下面的 li 里面的 img 的 action-data 是單個圖片的數(shù)據(jù)。
接下來,我們點(diǎn)擊“查看大圖”按鈕,瀏覽器會跳轉(zhuǎn)到新頁面,頁面內(nèi)容就是一張大圖。
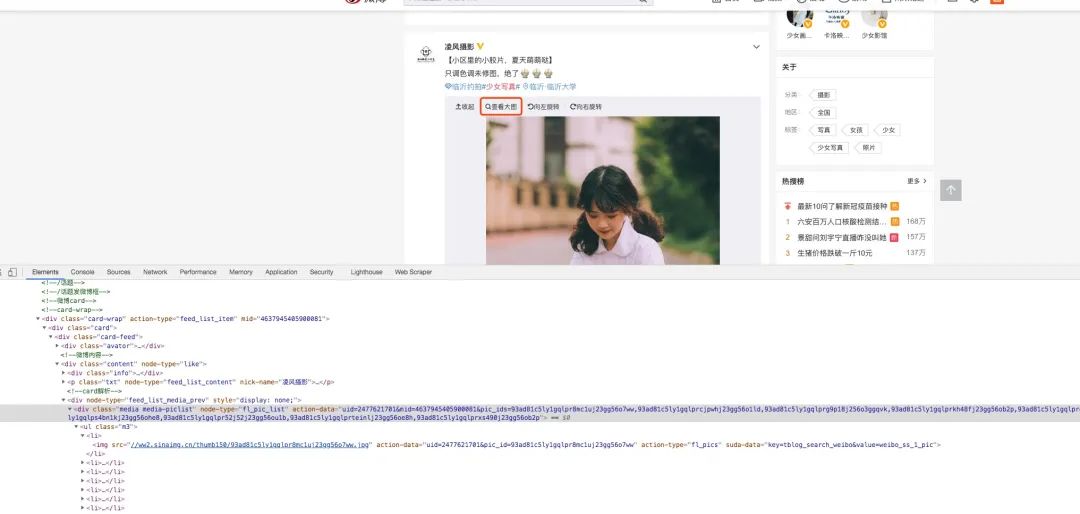
從請求的 URL 中順著找下來,我找到了這個:
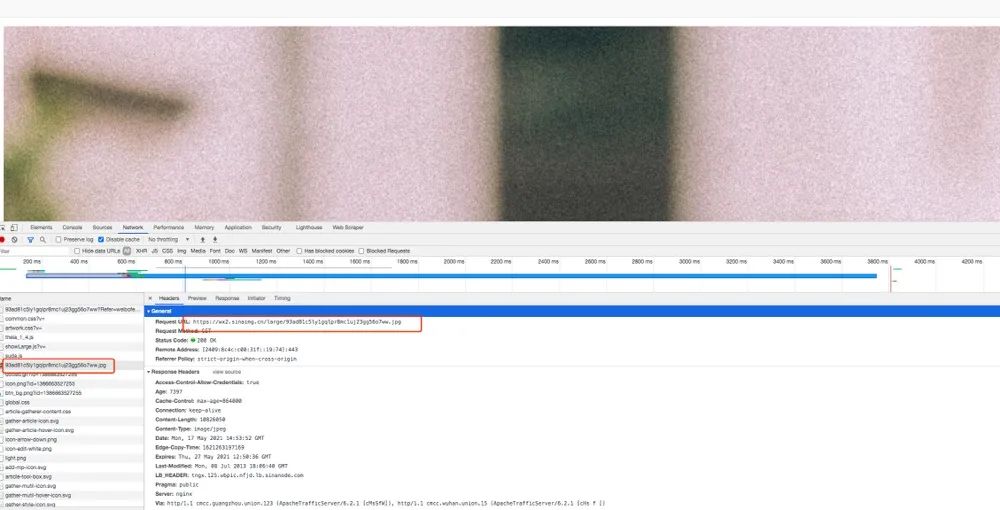
我復(fù)制這個 URL 到瀏覽器請求,發(fā)現(xiàn)這正是我們需要的大圖。我們也很容易看到這個 URL 的特點(diǎn),就是在最后把我們上面的 action-data 里面的 pic_id 加進(jìn)去了。
這樣一來,我們的思路就很清晰了,下面是獲取一頁圖片的思路:
獲取到頁面內(nèi)容; 在頁面內(nèi)容中找到圖片的ID; 拼接查看大圖的 URL 進(jìn)行請求,獲得圖片; 將圖片寫到本地。
碼代碼
思路理清楚了,需要碼代碼來驗(yàn)證。由于代碼相對簡單,這里就一次性呈現(xiàn)給大家了。
import requests
import re
import os
import time
cookie = {
'Cookie': 'your cookie'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4144.2 Safari/537.36'
}
get_order = input('是否啟動程序? yes or no: ')
number = 1
store_path = 'your path'
while True:
if get_order != 'no':
print('抓取中......') # 下面的鏈接填寫微博搜索的鏈接
url = f'https://s.weibo.com/weibo?q=%23%E5%B0%91%E5%A5%B3%E5%86%99%E7%9C%9F%23&wvr=6&b=1&Refer=SWeibo_box&page={number}'
response = requests.get(url, cookies=cookie)
result = response.text
print(result)
detail = re.findall('data="uid=(.*?)&mid=(.*?)&pic_ids=(.*?)">', result)
for part in detail:
uid = part[0]
mid = part[1]
pids = part[2]
for picid in pids.split(','):
url_x = f'https://wx1.sinaimg.cn/large/%s.jpg'%picid # 這里就是大圖鏈接了
response_photo = requests.get(url_x, headers=header)
file_name = url_x[-10:]
if not os.path.exists(store_path+uid):
os.mkdir(store_path+uid)
with open(store_path+uid + '/' + file_name, 'ab') as f: # 保存文件
f.write(response_photo.content)
time.sleep(0.5)
print('獲取完畢')
get_order = input('是否繼續(xù)獲取下一頁? Y:yes N:no: ')
if get_order != 'no':
number += 1
else:
print('程序結(jié)束')
break
else:
print('程序結(jié)束')
break
我這里使用了逐頁斷點(diǎn)的形式,目的是方便調(diào)試,大家如果想一次性獲取所有頁的圖片,可以去掉這些輸入判斷,直接一次性跑完。代碼里面的 cookie 和 圖片存放路徑需要大家替換成自己本地的。
跑完的結(jié)果如下:
這里面我把圖片按照微博分了文件夾,如果你覺得不直觀,想把所有圖片都放在一個目錄下,可以去掉這一層文件夾。
總結(jié)
本篇介紹了如何通過簡單爬蟲來獲取微博圖片搜索結(jié)果,代碼量相當(dāng)少,但是對某些人來說卻很有幫助,省時省力。大家也可以擴(kuò)展一下,除了圖片,也可以去獲取其他的搜索內(nèi)容,比如微博正文、視屏、購物鏈接等等。
PS:公號內(nèi)回復(fù)「Python」即可進(jìn)入Python 新手學(xué)習(xí)交流群,一起 100 天計(jì)劃!
老規(guī)矩,兄弟們還記得么,右下角的 “在看” 點(diǎn)一下,如果感覺文章內(nèi)容不錯的話,記得分享朋友圈讓更多的人知道!


【代碼獲取方式】