
Python循環(huán)、列表生成器、filter效率對(duì)比試驗(yàn)

本篇閱讀時(shí)間約為 5 分鐘。
前言
在編程的過(guò)程中,大家肯定會(huì)遇到一個(gè)場(chǎng)景,就是類(lèi)似在 list、set、tuple 中根據(jù)某些條件進(jìn)行過(guò)濾,篩選過(guò)后生成新的元素列表。
對(duì)于這個(gè)場(chǎng)景而言,在 Python 中有許多中不同的方案可以去解決,那么哪一種才是效率最高的?今天就來(lái)小小的做個(gè)實(shí)驗(yàn)體驗(yàn)下。
環(huán)境介紹
兩臺(tái) windows 電腦,Python 版本均為 3.0+ 。代碼相同,不同的是 CPU。
筆者 CPU 型號(hào):
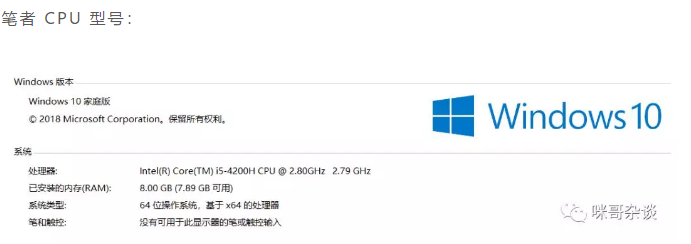
同學(xué) CPU 型號(hào):

測(cè)試場(chǎng)景代碼
假設(shè)現(xiàn)在的場(chǎng)景是有一個(gè)含有 1000 個(gè)數(shù)字的列表,其中這個(gè)列表中包含正數(shù)和負(fù)數(shù),如果讓你將所有正數(shù)挑選出來(lái)并且生成新的列表,如何解決?(如果看過(guò)筆者之前小課堂的示例,就知道方案都介紹過(guò)。)
生成 1000 個(gè) -100 到 100 的隨機(jī)list:
from timeit import timeit import random random.seed(10)??#?為了讓每次隨機(jī)結(jié)果相同,設(shè)置隨機(jī)種子 x_list = [random.randint(-100, 100) for _ in range(1000)]
思考過(guò)后再往下看:
方案一,最常規(guī)寫(xiě)法 for 遍歷:
def for_func():
""" for 循環(huán)測(cè)試 """
new_list = []
for x in x_list:
if x > 0:
new_list.append(x)
return new_list
方案二,列表生成式:
new_list = [x?for?x?in?x_list?if?x?>?0]
方案三,filter高級(jí)函數(shù):
new_list = list(filter(lambda x: x > 0, x_list))
測(cè)試效率
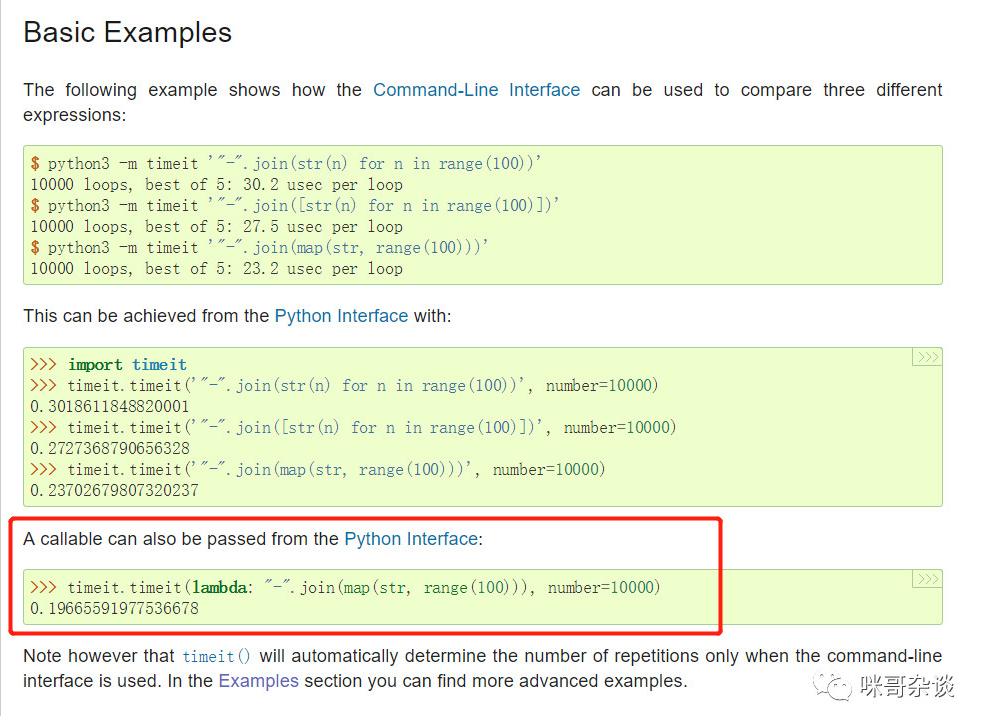
在 Python 中,有一個(gè)模塊叫 timeit,此模塊可以直接進(jìn)行效率測(cè)速,來(lái)簡(jiǎn)單的看下官方文檔如何介紹的:
如果大家有所了解,Python 解釋器是有不同版本的,平時(shí)我們用的是 CPython 解釋器,上面的方法即 CPython 的用法。若是在 IPython 中,則可以直接用 timeit xxxx 來(lái)進(jìn)行使用。
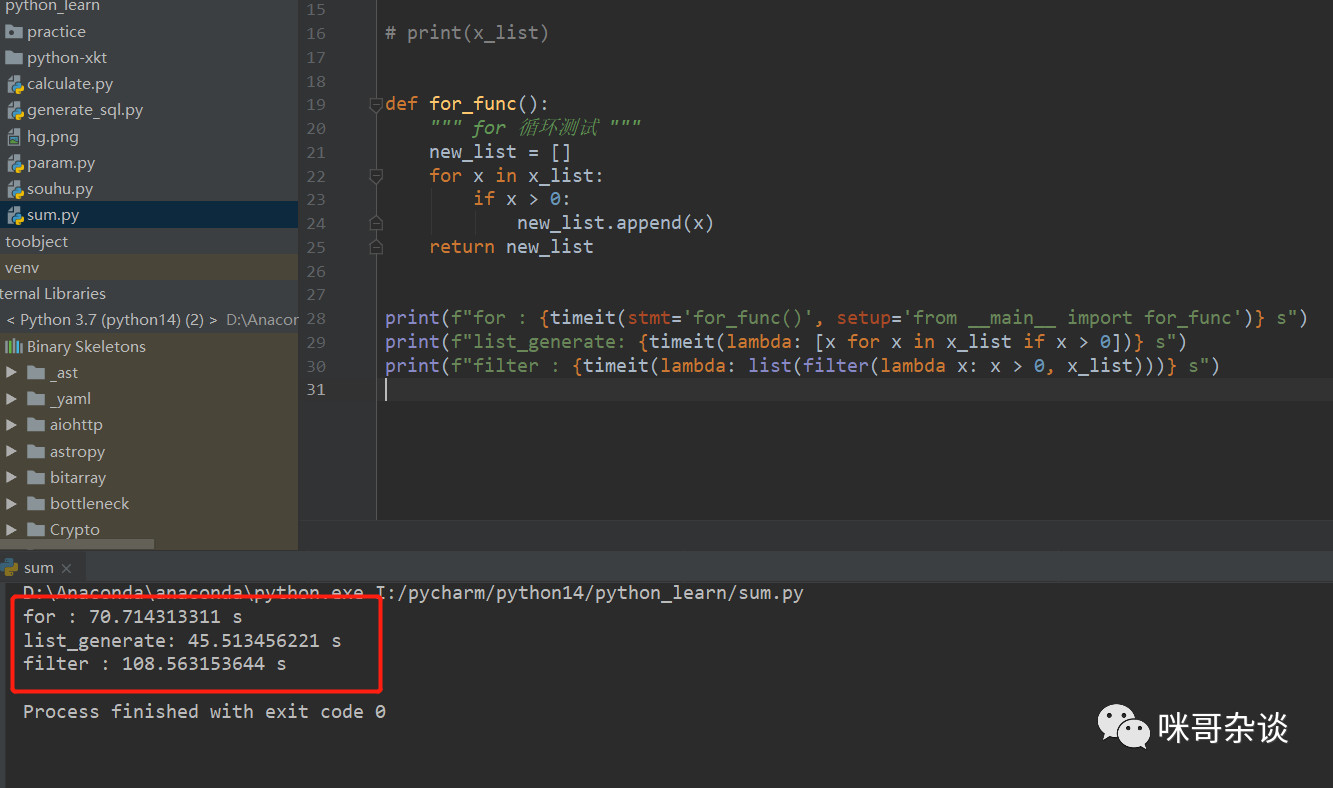
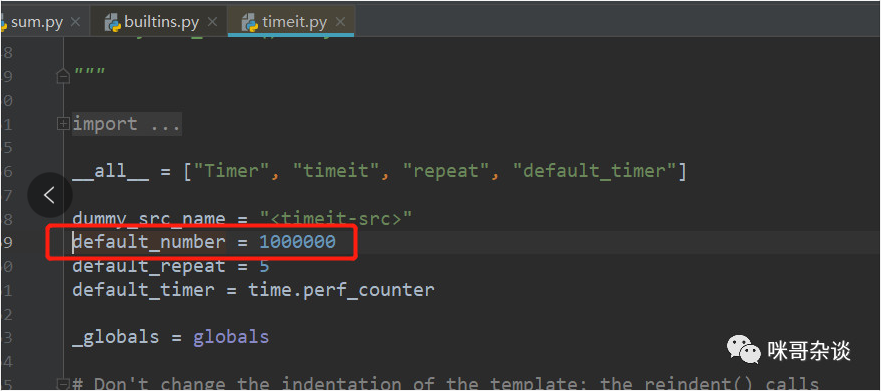
在 CPython 中,我選擇的是圖中紅框部分的示例代碼來(lái)做演示:
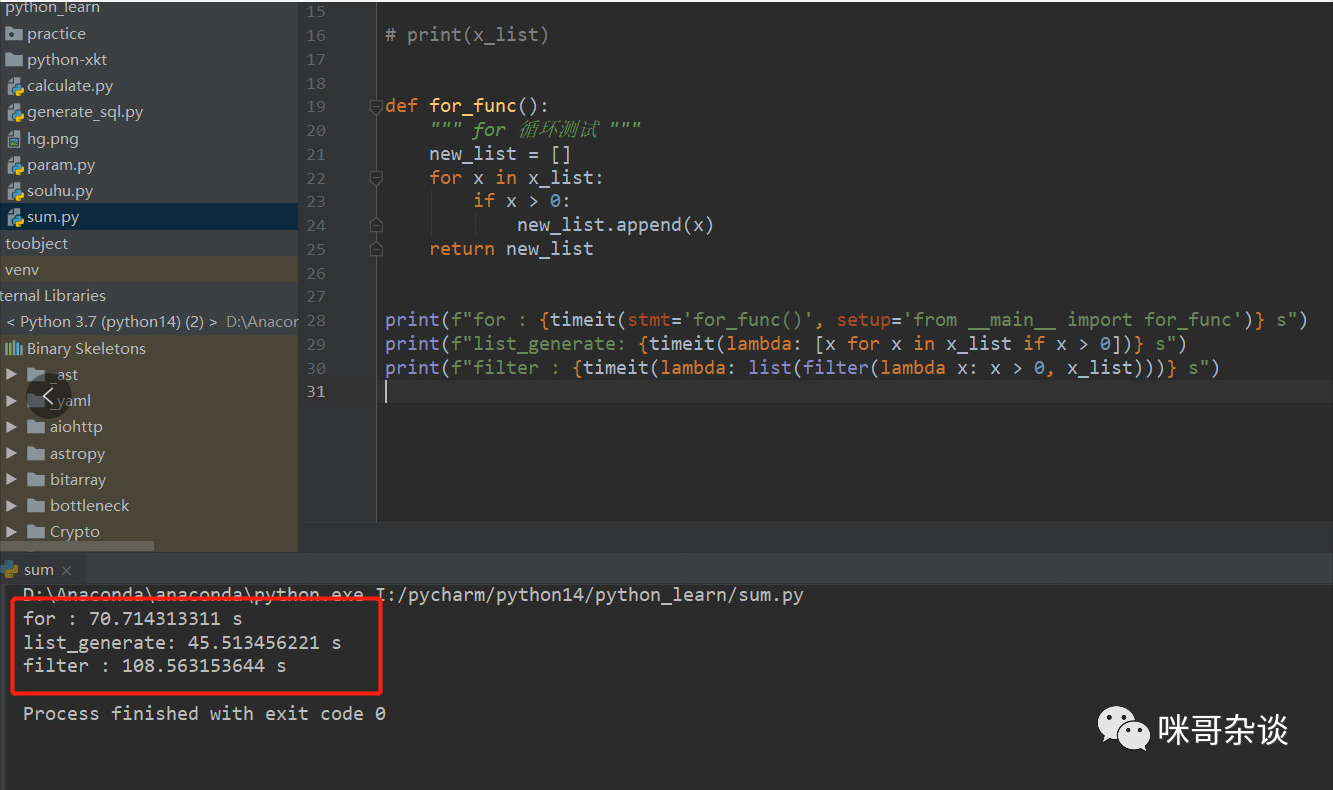
如果 number 參數(shù)不寫(xiě)的話(huà),默認(rèn)是循環(huán) 100000 次來(lái)執(zhí)行。在測(cè)試用例中,number 默認(rèn),可以進(jìn)源碼查看:
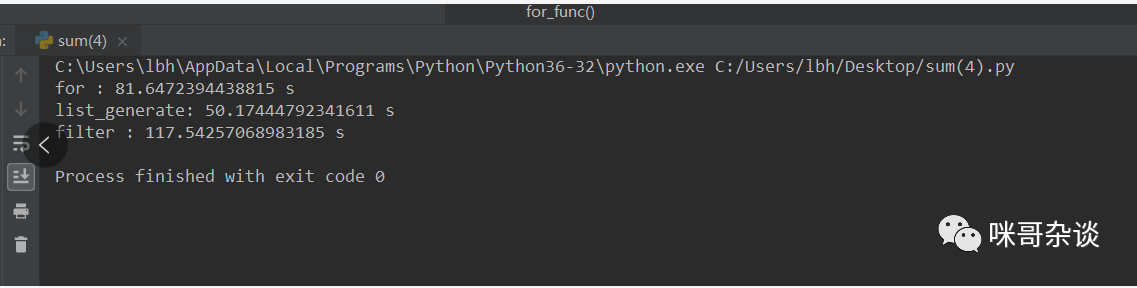
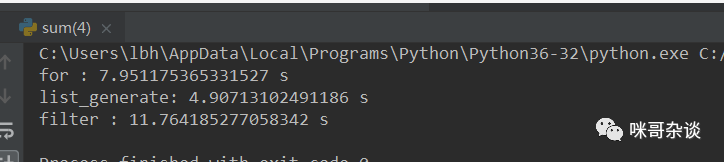
測(cè)試用例元素個(gè)數(shù) 1000 ,每種寫(xiě)法循環(huán)測(cè)試 100000 次。
結(jié)果,
我的:
同學(xué)的:
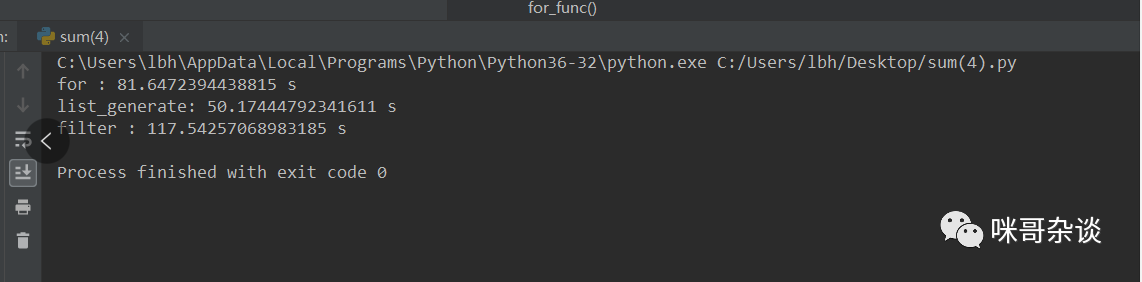
測(cè)試用例元素個(gè)數(shù) 100 ,每種寫(xiě)法循環(huán)測(cè)試 100000 次。
結(jié)果,
我的:
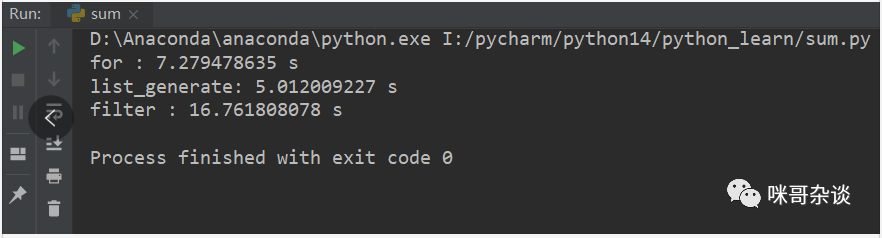
同學(xué)的:
拓展
關(guān)于字典和集合,也是可以使用生成器形式來(lái)進(jìn)行此場(chǎng)景過(guò)濾的,回顧:python小課堂34 - 推導(dǎo)式與生成器
總結(jié)
綜上所述,在此場(chǎng)景下,效率最高的列表推導(dǎo)式,若是簡(jiǎn)單的邏輯,推薦大家使用列表推導(dǎo)式寫(xiě)法,如果推導(dǎo)式滿(mǎn)足不了需求,在考慮另外兩種。