
Hive 實踐 | 如何對Hive表小文件進行合并
HDFS不適合大量小文件的存儲,因namenode將文件系統(tǒng)的元數(shù)據(jù)存放在內(nèi)存中,因此存儲的文件數(shù)目受限于 namenode的內(nèi)存大小。HDFS中每個文件、目錄、數(shù)據(jù)塊占用150Bytes。如果存放的文件數(shù)目過多的話會占用很大的內(nèi)存甚至撐爆內(nèi)存。HDFS適用于高吞吐量,而不適合低時間延遲的訪問。如果同時存入大量的小文件會花費很長的時間。本篇文章主要介紹在CDP7.1.6集群中如何對Hive表小文件進行合并。
測試環(huán)境
1.操作系統(tǒng)Redhat7.6
2.CDP7.1.6
3.使用root用戶操作
1.創(chuàng)建分區(qū)測試表
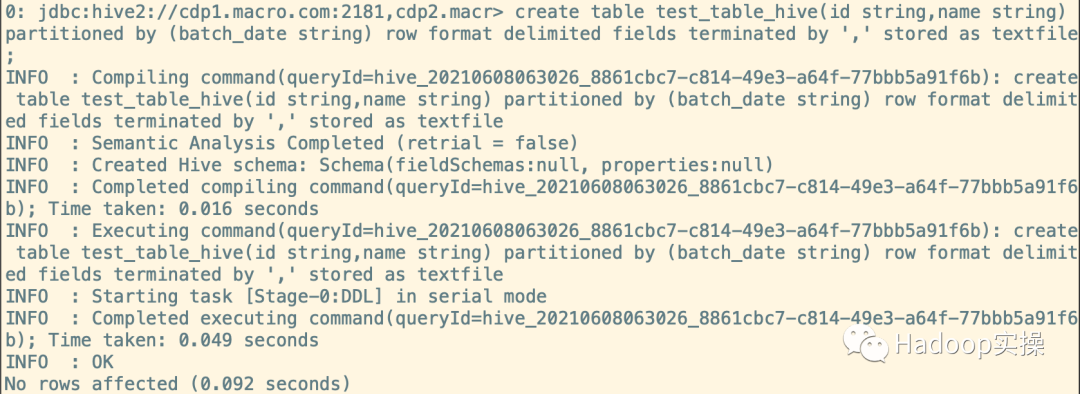
create table test_table_hive(id string,name string) partitioned by (batch_date string) row format delimited fields terminated by ',' stored as textfile;
2.查看表結(jié)構(gòu)
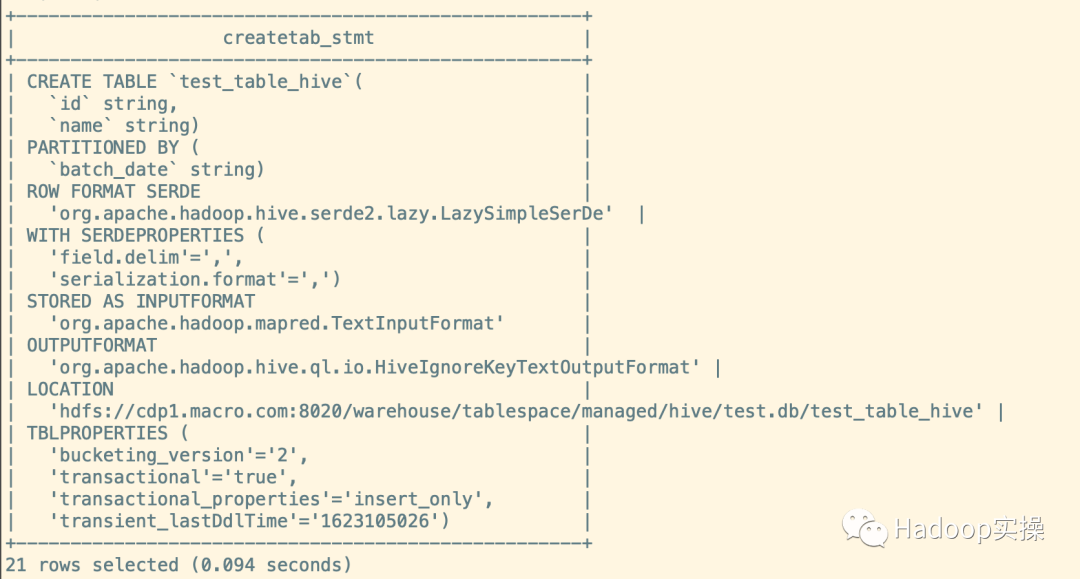
show create table test_table_hive;
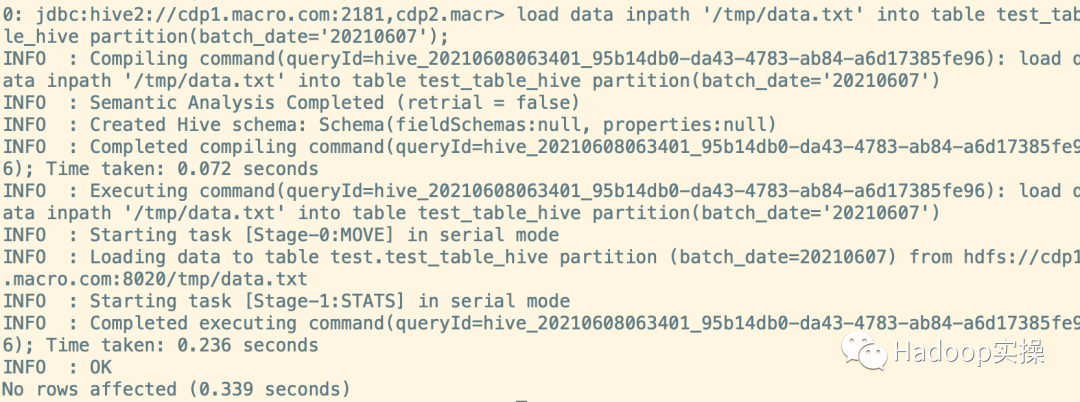
3.像表中導(dǎo)入數(shù)據(jù),并創(chuàng)建分區(qū)。(為了讓小文件數(shù)量和分區(qū)數(shù)達到合并效果,本文進行了多次導(dǎo)入)
load data inpath '/tmp/data.txt' into table test_table_hive partition(batch_date='20210607');
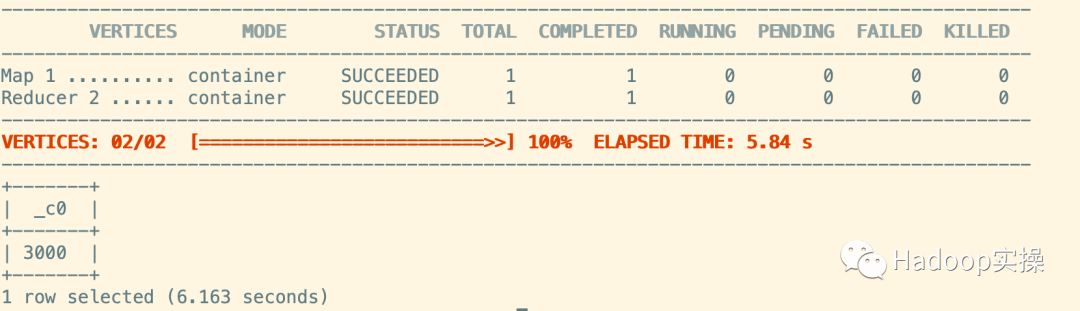
4.查看數(shù)據(jù)量
select count(*) from test_table_hive;
5.查看總分區(qū)數(shù)(可以看到共12個分區(qū))
hdfs dfs -ls /warehouse/tablespace/managed/hive/test.db/test_table_hive/
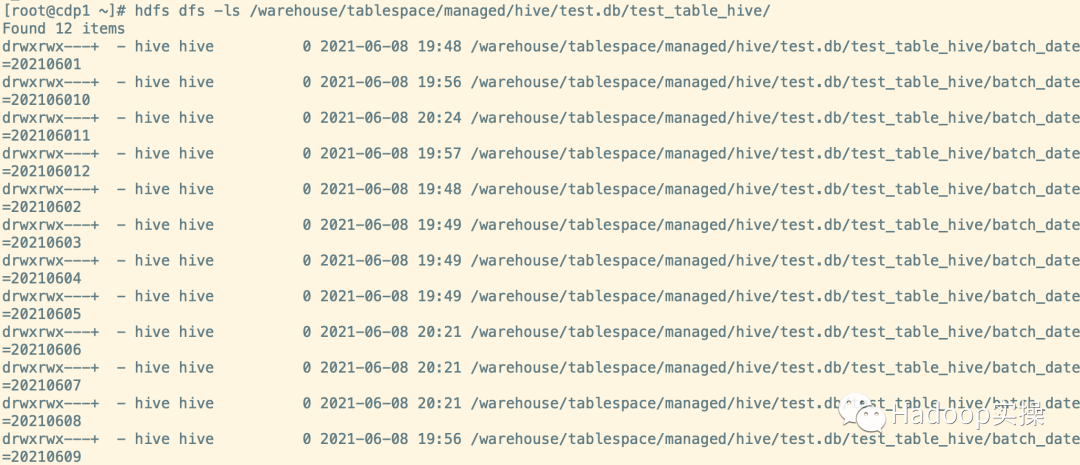
6.總的小文件數(shù)量,和batch_date=20210608分區(qū)的文件數(shù)量
hdfs dfs -count /warehouse/tablespace/managed/hive/test.db/test_table_hive
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive/batch_date=20210608|wc -l
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive/batch_date=20210608
1.創(chuàng)建臨時表(創(chuàng)建臨時表時需和原表的表結(jié)構(gòu)一致)
create table test.test_table_hive_merge like test.test_table_hive;
2.設(shè)置合并文件相關(guān)會話參數(shù)(參數(shù)概述見總結(jié)部分)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=3000;
SET hive.exec.max.dynamic.partitions.pernode=500;
SET hive.merge.tezfiles=true;
SET hive.merge.smallfiles.avgsize=128000000;
SET hive.merge.size.per.task=128000000;
3.合并文件至臨時表中
INSERT OVERWRITE TABLE test.test_table_hive_merge partition(batch_date) SELECT * FROM test.test_table_hive;
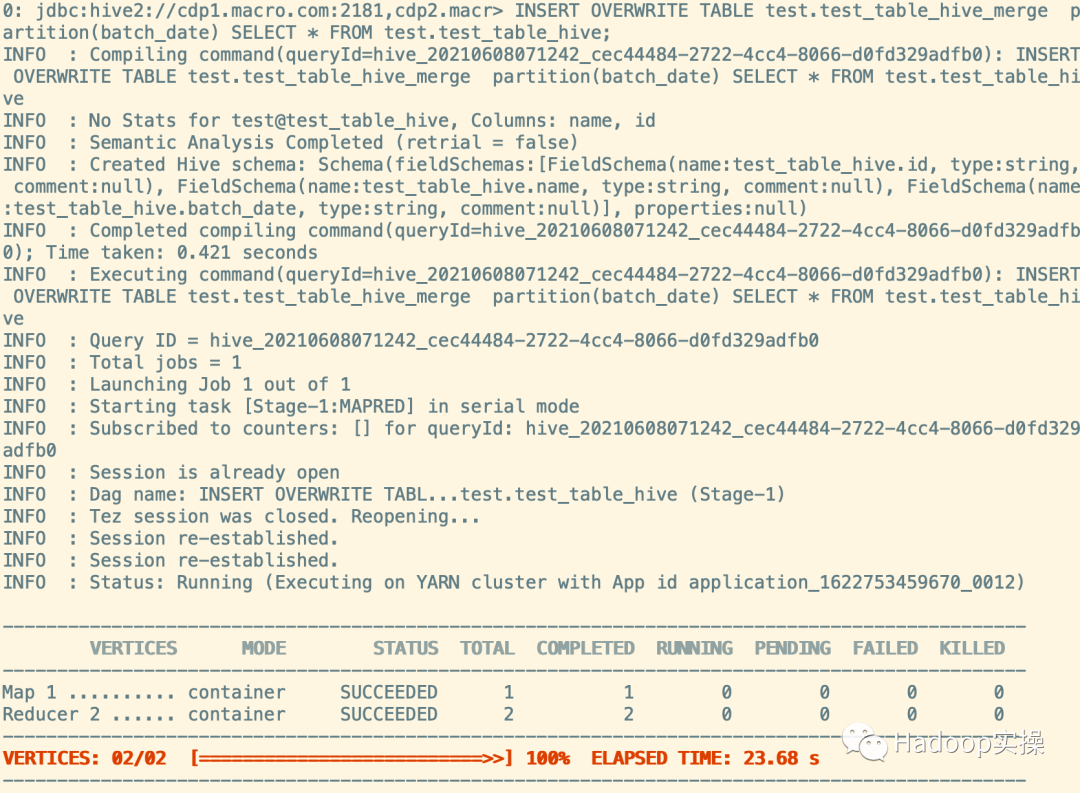
4.查看原表和臨時表數(shù)據(jù)量
SELECT count(*) FROM test.test_table_hive;
SELECT count(*) FROM test.test_table_hive_merge;
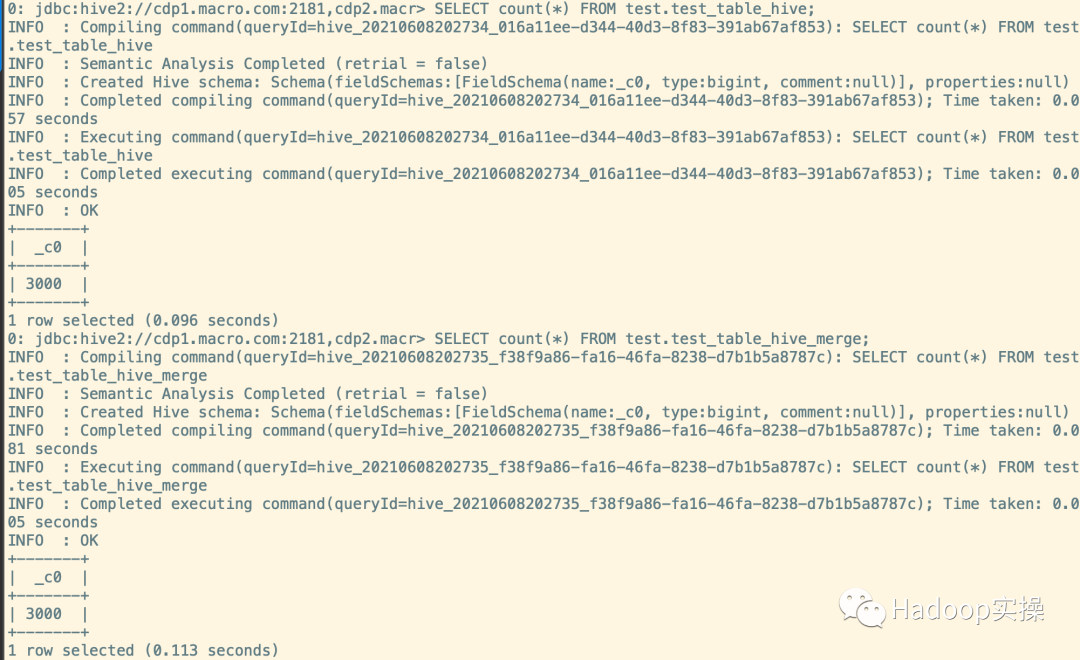
5.查看總分區(qū)數(shù)
hdfs dfs -ls /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/
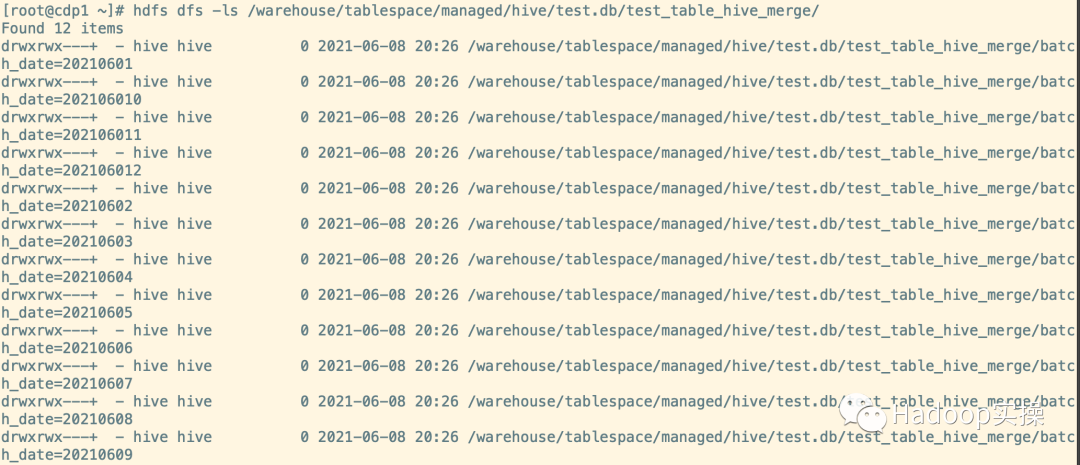
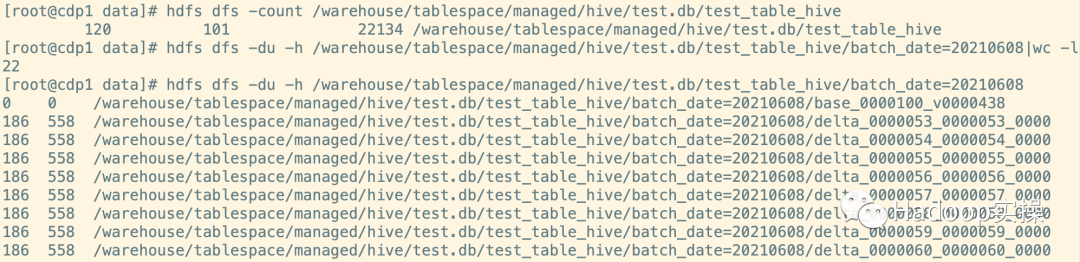
6.查看合并后的分區(qū)數(shù)和小文件數(shù)量
hdfs dfs -count /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/batch_date=20210608
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/batch_date=20210608|wc -l

如上圖101個文件數(shù)合并為12個,共12個分區(qū),每個分區(qū)下的文件被合并為了一個
1.創(chuàng)建備份目錄,把原表數(shù)據(jù)放入備份目錄,并遷移臨時表數(shù)據(jù)到原表。
hdfs dfs -mkdir -p /tmp/hive/test_table_hive_data_backups
hdfs dfs -mv /warehouse/tablespace/managed/hive/test.db/test_table_hive/* /tmp/hive/test_table_hive_data_backups/
hdfs dfs -cp -f /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/* /warehouse/tablespace/managed/hive/test.db/test_table_hive/

2.查看合并后的原表小文件數(shù)量
hdfs dfs -count -v -h /warehouse/tablespace/managed/hive/test.db/test_table_hive

3.查看合并后的原表數(shù)據(jù)
select count(*) from test_table_hive;
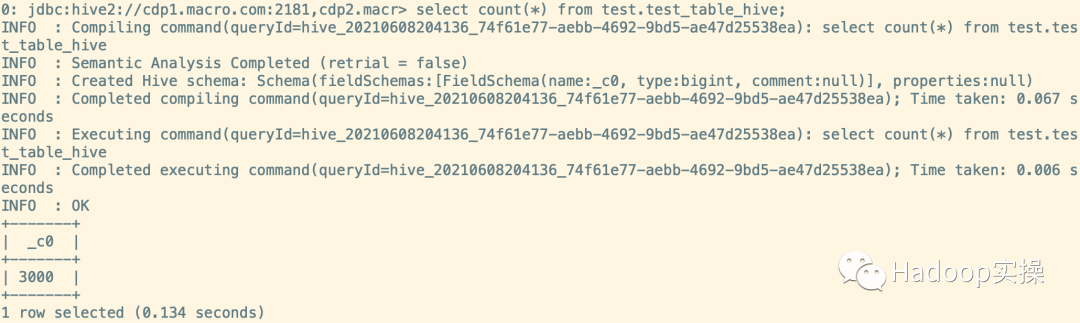
4.清理臨時表
drop table test.test_table_hive_merge;
5.清理備份數(shù)據(jù)(確認合并后數(shù)據(jù)無異常后清理,建議數(shù)據(jù)保留一周)
hdfs dfs -rm -r /tmp/hive/test_table_hive_data_backups

1.本文原表中共12個分區(qū),101個小文件,合并后共12個文件,其每個分區(qū)中一個。
2.在CDP中因為Hive的底層執(zhí)行引擎是TEZ,,所以相比CDH需要修改以前的合并參數(shù)“SET hive.merge.mapfiles=true”為“SET hive.merge.tezfiles=true;”。
3.合并完后清理原表備份的數(shù)據(jù)建議保留一周。
4.參數(shù)含義
SET hive.exec.dynamic.partition=true;
#使用動態(tài)分區(qū)
SET hive.exec.dynamic.partition.mode=nonstrict;
#默認值為srticat,nonstrict模式表示允許所有分區(qū)字段都可以使用動態(tài)分區(qū)
SET hive.exec.max.dynamic.partitions=3000;
#在所有執(zhí)行MR的節(jié)點上,共可以創(chuàng)建多少個動態(tài)分區(qū)
SET hive.exec.max.dynamic.partitions.pernode=500;
#在執(zhí)行MR的單節(jié)點上,最大可以創(chuàng)建多少個分區(qū)
SET hive.merge.tezfiles=true;
#tez任務(wù)結(jié)束時合并小文件
SET hive.merge.smallfiles.avgsize=1280000000;
#當輸出文件平均大小小于該值時。啟用獨立的TEZ任務(wù)進行文件合并
SET hive.merge.size.per.task=1280000000;
#合并文件大小128M