
大模型系列 | 兩張3090顯卡就可以玩起來醫(yī)療SAM-LST大模型
點(diǎn)擊下方卡片,關(guān)注「集智書童」公眾號

最近,引入了基于計(jì)算機(jī)視覺領(lǐng)域的各種任務(wù)的基礎(chǔ)模型。這些模型,比如Segment Anything Model (SAM),是使用大規(guī)模數(shù)據(jù)集進(jìn)行訓(xùn)練的通用模型。目前,正在進(jìn)行的研究聚焦于探索如何有效地利用這些通用模型應(yīng)用于特定領(lǐng)域,比如醫(yī)學(xué)影像。
然而,在醫(yī)學(xué)影像領(lǐng)域,由于隱私問題和其他因素導(dǎo)致缺乏訓(xùn)練樣本,這對將這些通用模型應(yīng)用于醫(yī)學(xué)圖像分割任務(wù)構(gòu)成了重大挑戰(zhàn)。
為了解決這個問題,有效地微調(diào)這些模型對于確保它們的最佳利用至關(guān)重要。在本研究中提出結(jié)合一個互補(bǔ)的卷積神經(jīng)網(wǎng)絡(luò)(CNN)和標(biāo)準(zhǔn)的SAM網(wǎng)絡(luò)進(jìn)行醫(yī)學(xué)圖像分割。為了減輕對大型基礎(chǔ)模型進(jìn)行精細(xì)調(diào)整的負(fù)擔(dān)并實(shí)現(xiàn)成本高效的訓(xùn)練方案,本文僅集中于對額外的CNN網(wǎng)絡(luò)和SAM解碼器部分進(jìn)行微調(diào)。這種策略顯著減少了訓(xùn)練時間,并在公開可用的數(shù)據(jù)集上取得了競爭性的結(jié)果。
代碼:https://github.com/11yxk/SAM-LST
1、簡介
醫(yī)學(xué)圖像分割在醫(yī)療保健領(lǐng)域中起著至關(guān)重要的作用。它旨在使用各種醫(yī)學(xué)成像模態(tài)(如X射線、CT掃描、MRI掃描或超聲圖像)對肝臟、腦部和病變等各種人體器官進(jìn)行分割。因此,它在診斷、治療計(jì)劃和治療后監(jiān)測方面對臨床醫(yī)生有很大幫助。
在過去的十年中,卷積神經(jīng)網(wǎng)絡(luò)(CNN)在計(jì)算機(jī)視覺任務(wù)中變得流行起來。最近,Long等人提出了全卷積網(wǎng)絡(luò)(FCN)。這種方法通過用卷積層替換全連接層,使得能夠處理任意大小的輸入圖像并生成分割結(jié)果。U-Net是由Ronneberger等人開發(fā)的用于醫(yī)學(xué)圖像分割的最廣泛使用的架構(gòu)。它包括一個編碼器和一個解碼器,并且在相應(yīng)層之間有Shortcut以保留重要的特征。編碼器路徑對輸入圖像進(jìn)行下采樣,同時捕捉High-Level特征。而解碼器路徑則對特征圖進(jìn)行上采樣以預(yù)測分割結(jié)果。Zhou等人通過引入嵌套的Shortcut方案擴(kuò)展了U-Net架構(gòu),這允許捕捉多尺度的上下文信息和更好地集成不同Level的特征。Chen等人提出了Deeplab系列模型,其中包括空洞卷積操作和全連接的條件隨機(jī)場的概念。
最近,Transformer已經(jīng)被引入到計(jì)算機(jī)視覺(CV)領(lǐng)域,它最初是為自然語言處理(NLP)而設(shè)計(jì)的。與傳統(tǒng)的CNN架構(gòu)相比,Transformer可以捕捉到遠(yuǎn)程依賴關(guān)系。多索維茨基等提出了基于自注意力機(jī)制的圖像分類視覺Transformer(ViT)。隨后,Chen等人提出了使用ViT進(jìn)行分割任務(wù)的TransUNet。TransUNet聯(lián)合利用CNN和ViT從輸入圖像中獲取局部和全局上下文特征。Tang等人提出了采用ViT模型作為特征提取的主要編碼器的Swin UNETR。Zhou等人提出了一個純Transformer框架,它在編碼器和解碼器部分都使用ViT。Cao等人提出了采用雙Transformer架構(gòu)進(jìn)行分割任務(wù)的雙-unet。
目前,基礎(chǔ)模型在自然語言處理領(lǐng)域已經(jīng)證明了其能力。目前,SAM被引入用于各種計(jì)算機(jī)視覺任務(wù)。在SAM中,使用基礎(chǔ)模型的prompt學(xué)習(xí)的概念可以在看不見的圖像上執(zhí)行多個任務(wù)。它允許通過有效的prompt工程將zero-shot轉(zhuǎn)移到各種任務(wù)中。雖然將SAM模型直接應(yīng)用于特定領(lǐng)域的任務(wù),如醫(yī)學(xué)圖像分割,通常不能產(chǎn)生令人滿意的性能。盡管SAM使用的是超過1100萬張圖像和10億張GT Mask,但由于醫(yī)學(xué)圖像與真實(shí)圖像相比的獨(dú)特特征,其在醫(yī)學(xué)圖像分割中的應(yīng)用帶來了挑戰(zhàn)。此外,醫(yī)療數(shù)據(jù)的缺乏也是調(diào)整SAM的一個主要問題。因此,對醫(yī)學(xué)圖像數(shù)據(jù)集的SAM進(jìn)行有效的微調(diào)是非常必要的。
如今,已經(jīng)引入了各種微調(diào)方法來優(yōu)化在不同領(lǐng)域中的SAM。一些方法對SAM網(wǎng)絡(luò)進(jìn)行基于適配器的微調(diào)。然而,這些基于適配器的方法通常需要大量的訓(xùn)練模型的工作和資源成本。與以往的研究不同,本文的工作通過在SAM架構(gòu)中結(jié)合一個額外的CNN作為補(bǔ)充編碼器,引入了一種新穎的方法。
本文的方法受到了用于Transformer的Ladder-Side Tuning (LST)網(wǎng)絡(luò)的啟發(fā)。本文提出的方法能夠靈活地集成額外的網(wǎng)絡(luò),同時避免在整個大模型(即SAM編碼器)上進(jìn)行反向傳播,從而加快了訓(xùn)練速度并降低了資源成本。額外的CNN網(wǎng)絡(luò)可以根據(jù)具體任務(wù)需求輕松替換為其他設(shè)計(jì),包括基于Transformer的設(shè)計(jì)。
本文將預(yù)訓(xùn)練的ResNet18作為額外的網(wǎng)絡(luò)進(jìn)行了融合。在訓(xùn)練過程中,只有額外的CNN和解碼器部分的參數(shù)進(jìn)行微調(diào),而保持原始的SAM編碼器參數(shù)不變。
本文的貢獻(xiàn)可以總結(jié)如下:
-
本文提出了在醫(yī)學(xué)圖像分割任務(wù)中,結(jié)合額外的CNN進(jìn)行SAM微調(diào)的方法; -
所提出的方法在設(shè)計(jì)額外網(wǎng)絡(luò)時提供了靈活性,同時通過避免在整個模型上進(jìn)行反向傳播來最大程度地減少資源成本; -
在一個公開可用的多器官分割數(shù)據(jù)集上,本文的方法在不使用任何prompt的情況下取得了與最先進(jìn)方法相媲美的結(jié)果。
2、相關(guān)工作
2.1 醫(yī)學(xué)圖像分割
精確可靠的醫(yī)學(xué)圖像分割對于輔助醫(yī)學(xué)診斷至關(guān)重要。在過去的幾年中,已經(jīng)提出了許多分割方法。特別是基于CNN的網(wǎng)絡(luò)在這個任務(wù)中取得了顯著的成功。最近,一些基于Transformer的High-Level網(wǎng)絡(luò)也被提出來,在這個任務(wù)中取得了新的里程碑。盡管在醫(yī)學(xué)圖像分割方面取得了顯著進(jìn)展,但由于數(shù)據(jù)有限和需要臨床專家對數(shù)據(jù)進(jìn)行注釋的要求等因素,它仍然是一個具有挑戰(zhàn)性的任務(wù)。這些因素通常導(dǎo)致模型的泛化能力較差。
2.2 基礎(chǔ)模型
基礎(chǔ)模型是指在廣泛數(shù)據(jù)上訓(xùn)練并可適應(yīng)各種下游任務(wù)的模型。這種范式通常包含一些其他技術(shù),比如自監(jiān)督學(xué)習(xí)、遷移學(xué)習(xí)和prompt學(xué)習(xí)。一個基礎(chǔ)模型的例子是生成式預(yù)訓(xùn)練Transformer (GPT) 系列,這些模型在來自各種來源的大量文本數(shù)據(jù)上進(jìn)行了預(yù)訓(xùn)練。這些模型在自然語言處理 (NLP) 的進(jìn)展中做出了重大貢獻(xiàn)。
具體而言,GPT-3是其中一個參數(shù)達(dá)到1750億的大型語言模型 (LLM),可以應(yīng)用于廣泛的任務(wù),包括翻譯、問答和完形填空等。另一個值得注意的工作是對比語言圖像預(yù)訓(xùn)練 (CLIP) ,它使用了一組大規(guī)模的帶有圖像和相應(yīng)文本描述的數(shù)據(jù)集。CLIP能夠根據(jù)給定的文本prompt有效地檢索圖像,這在圖像分類和圖像生成等領(lǐng)域有許多應(yīng)用。這些基礎(chǔ)模型已經(jīng)取得了最先進(jìn)的性能。它們在各個領(lǐng)域的發(fā)展方向廣闊。
2.3 Parameter-Efficient Fine-Tuning
盡管基礎(chǔ)模型取得了顯著的成就,但它們?nèi)匀幻媾R一些限制,比如需要大量標(biāo)記數(shù)據(jù)進(jìn)行訓(xùn)練和龐大的計(jì)算資源需求,這歸因于它們巨大的參數(shù)數(shù)量。
為了降低巨大的計(jì)算成本,引入了參數(shù)高效微調(diào)(PEFT)的方法,通過訓(xùn)練現(xiàn)有模型中的一小部分參數(shù)或在架構(gòu)中訓(xùn)練新添加的參數(shù)。Houlsby等人提出在原始基礎(chǔ)模型中添加一個小的子網(wǎng)絡(luò),稱為“適配器”。Lester等人提出在原始模型輸入之前添加一個可訓(xùn)練的張量。Sung等人引入了一種新穎的階梯側(cè)調(diào)整(LST)范式,僅對原始模型旁邊嵌入的一個小型Transformer網(wǎng)絡(luò)進(jìn)行微調(diào)。
在這種架構(gòu)設(shè)計(jì)中,只更新新添加網(wǎng)絡(luò)的參數(shù)以節(jié)省計(jì)算成本。Ben-Zaken等人建議僅訓(xùn)練原始網(wǎng)絡(luò)的偏置,這也是一種簡單而有效的方法。總體而言,基于PEFT的方法對GPU友好,在有限的計(jì)算資源下可以應(yīng)用基礎(chǔ)模型于各種下游任務(wù)中。
3、本文方法
3.1 Segment Anything Model
Segment Anything Model(SAM)是基礎(chǔ)模型在分割任務(wù)中的首次嘗試。
SAM由3個組件構(gòu)成:
-
image編碼器
-
prompt編碼器
-
mask解碼器
image編碼器采用了MAE 預(yù)訓(xùn)練的ViT網(wǎng)絡(luò)來提取圖像特征。
prompt編碼器支持4種類型的prompt輸入:點(diǎn)、框、文本和Mask。點(diǎn)和框通過位置編碼進(jìn)行嵌入,而文本則使用CLIP中的文本編碼器進(jìn)行嵌入。Mask則使用卷積操作進(jìn)行嵌入。
Mask解碼器以輕量級的方式將圖像嵌入和prompt嵌入進(jìn)行映射。這兩種嵌入類型通過交叉注意力模塊進(jìn)行交互,其中一個嵌入作為query向量,而另一個嵌入作為key向量和value向量。最后,使用轉(zhuǎn)置卷積來上采樣特征。Mask解碼器具有生成多個結(jié)果的能力,因?yàn)樘峁┑膒rompt可能存在歧義。默認(rèn)輸出數(shù)量設(shè)置為三個。
值得一提的是,image編碼器只需對每個輸入圖像提取一次圖像特征。之后,輕量級的prompt編碼器和Mask解碼器可以根據(jù)不同的輸入prompt在Web瀏覽器中與用戶實(shí)時交互。
SAM使用超過1100萬張圖像和10億個Mask進(jìn)行訓(xùn)練。實(shí)驗(yàn)結(jié)果表明其出色的零樣本遷移能力。正如其名稱所暗示的,該模型幾乎可以分割任何東西,甚至是以前未見過的情況(未知的測試樣本)。
3.2 Ladder-Side Tuning with SAM
在這里,本文描述了本文提出的方案和集成網(wǎng)絡(luò)。概述如圖1所示。為了有效地應(yīng)用于醫(yī)學(xué)圖像分割任務(wù)的SAM模型,本文建議添加一個輕量級的側(cè)網(wǎng)絡(luò),同時避免通過整個SAM模型進(jìn)行反向傳播。
本文只更新SAM解碼器和集成CNN網(wǎng)絡(luò)的參數(shù),以在醫(yī)學(xué)數(shù)據(jù)集上微調(diào)SAM。形式上,給定輸入樣本 ,其中 表示高度、寬度和通道數(shù)。輸入圖像首先同時輸入到SAM image編碼器和CNN編碼器中:

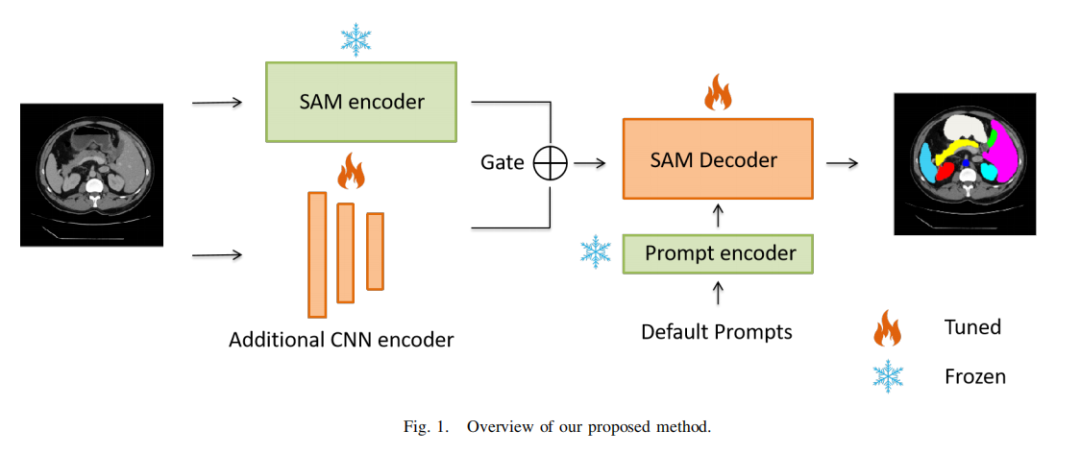
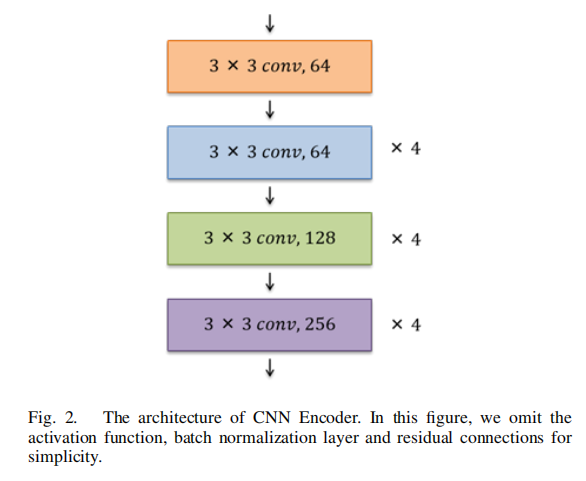
CNN編碼器的架構(gòu)如圖2所示。設(shè)計(jì)遵循ResNet18,其中包括Shortcut連接。然而,為了生成與SAM編碼器相同大小的特征圖,網(wǎng)絡(luò)被修改為僅使用13層,而不是全部使用18層(ResNet18包含18個卷積層)。為了確定從SAM和集成CNN中提取的特征的重要性,本文提出在組合這兩個提取的特征圖時加入一個可學(xué)習(xí)的門(權(quán)重參數(shù))
: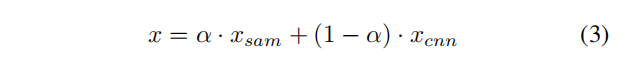
3.3 損失函數(shù)
本文使用交叉熵?fù)p失和Dice損失的組合來對網(wǎng)絡(luò)進(jìn)行微調(diào)。
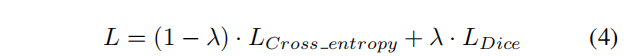
其中 是一個超參數(shù),根據(jù)本文的實(shí)驗(yàn)將其值設(shè)置為0.8。
4、實(shí)驗(yàn)
4.1 數(shù)據(jù)集
本文使用Synapse數(shù)據(jù)集進(jìn)行評估,這是MICCAI 2015多圖譜腹部標(biāo)記挑戰(zhàn)的一個公開可用的多器官分割數(shù)據(jù)集。它包括30個腹部CT掃描。根據(jù)之前的工作,總共使用18個案例進(jìn)行訓(xùn)練,12個案例用于測試。本文以Dice相似系數(shù)(DSC)和95% Hausdorff距離(HD95)的指標(biāo)報告在8個腹部器官(即主動脈、膽囊、脾臟、左腎、右腎、肝臟、胰腺、胃)上的結(jié)果。
4.2 實(shí)施細(xì)節(jié)
輸入圖像的分辨率設(shè)置為224×224。本文使用隨機(jī)旋轉(zhuǎn)和翻轉(zhuǎn)操作進(jìn)行數(shù)據(jù)增強(qiáng)。本文使用ViT-B SAM模型作為基礎(chǔ)Backbone模型。本文不微調(diào)SAM編碼器和prompt編碼器,而只微調(diào)SAM解碼器的“輸出上采樣”部分,以避免過擬合。集成的CNN編碼器在PyTorch Torchvision庫提供的ImageNet上進(jìn)行了預(yù)訓(xùn)練。該框架使用批量大小為24的Adam優(yōu)化器進(jìn)行200個epochs訓(xùn)練。學(xué)習(xí)率設(shè)置為0.001。在前250個迭代中采用了warmup策略。實(shí)驗(yàn)使用了2個RTX 3090顯卡進(jìn)行。
4.3 實(shí)驗(yàn)結(jié)果
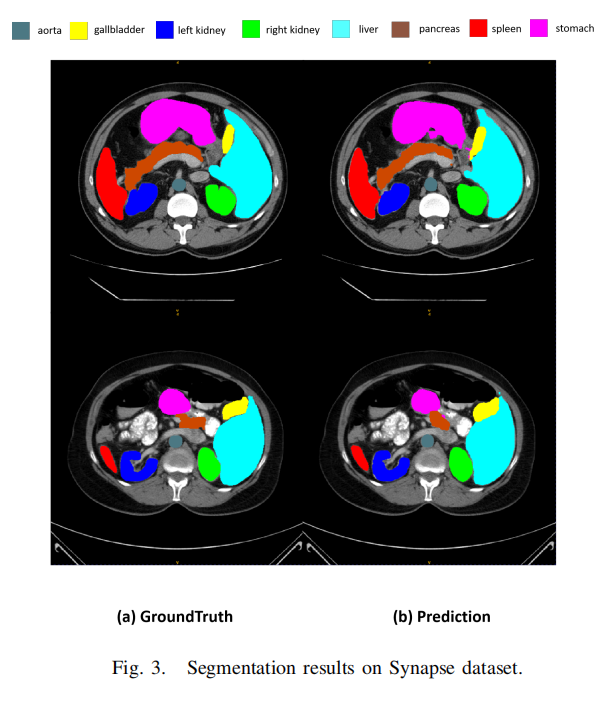
表I報告了實(shí)驗(yàn)結(jié)果,并與其他最先進(jìn)的方法進(jìn)行了比較。本文提出的方法實(shí)現(xiàn)了79.45%的DSC和35.35mm的HD95分?jǐn)?shù)。本文還觀察到可學(xué)習(xí)權(quán)重參數(shù)的值為0.44。本文的方法在超過大多數(shù)最先進(jìn)方法的同時取得了競爭性的得分。
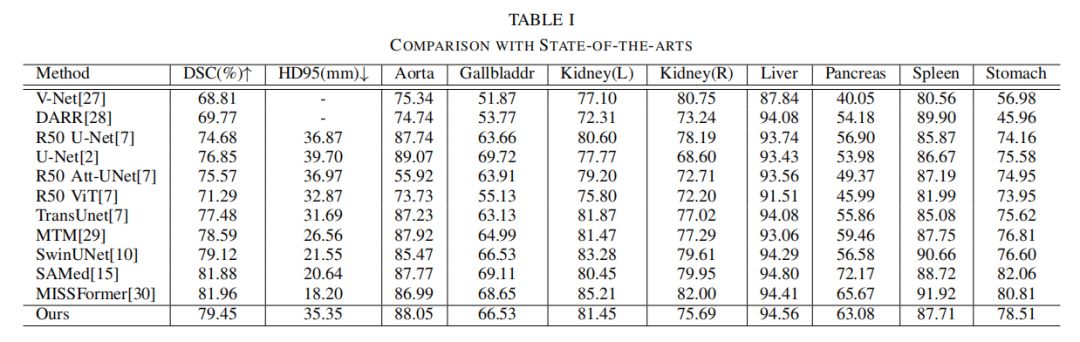
圖3展示了一些分割結(jié)果。然而,集成CNN編碼器和可學(xué)習(xí)權(quán)重參數(shù)的設(shè)計(jì)可以進(jìn)行修改,以分析和評估所提出方法的性能。本文相信利用Transformer或其他有效的網(wǎng)絡(luò)設(shè)計(jì)將會獲得更高的性能。在未來,本文將探索更先進(jìn)的設(shè)計(jì)選擇,以達(dá)到最佳結(jié)果。
4.4 消融實(shí)驗(yàn)
本文進(jìn)行了消融實(shí)驗(yàn)來評估將CNN編碼器與SAM編碼器集成的有效性。
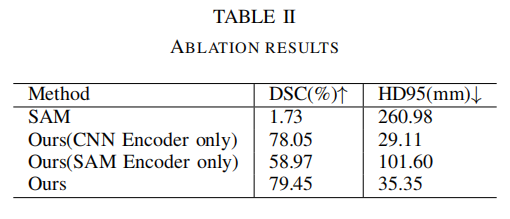
表II表明,SAM模型在沒有對醫(yī)學(xué)圖像進(jìn)行微調(diào)的情況下,僅實(shí)現(xiàn)了1.73%的Dice分?jǐn)?shù)。需要注意的是,在此訓(xùn)練和評估過程中沒有使用prompt,因此由于直接應(yīng)用了通用模型,得分較低。通過對整個SAM應(yīng)用微調(diào)方法,準(zhǔn)確性提高到58.97的Dice分?jǐn)?shù)。同樣,當(dāng)將CNN編碼器與SAM解碼器模塊相結(jié)合時,性能保持在78.05的Dice分?jǐn)?shù)。這凸顯了有效微調(diào)方法的必要性。
然而,通過將CNN編碼器與SAM網(wǎng)絡(luò)集成并利用可學(xué)習(xí)的門(權(quán)重參數(shù)),準(zhǔn)確性顯著提高至79.45的Dice分?jǐn)?shù)。此外,本文還觀察到訓(xùn)練時間顯著減少,與其他微調(diào)方法相比,減少了約30%到40%。本文提出的方法在資源利用方面更具成本效益。
5、參考
[1].Ladder Fine-tuning approach for SAM integrating complementary network.
6、推薦閱讀
南科大提出ORCTrack | 解決DeepSORT等跟蹤方法的遮擋問題,即插即用真的很香
CSUNet | 完美縫合Transformer和CNN,性能達(dá)到UNet家族的巔峰!

InstructionGPT-4 | 200個數(shù)據(jù)集微調(diào),源于MiniGPT-4又高于MiniGPT-4

掃碼加入??「集智書童」交流群
(備注:方向+學(xué)校/公司+昵稱)




前沿AI視覺感知全棧知識??「分類、檢測、分割、關(guān)鍵點(diǎn)、車道線檢測、3D視覺(分割、檢測)、多模態(tài)、目標(biāo)跟蹤、NerF」
歡迎掃描上方二維碼,加入「集智書童-知識星球」,日常分享論文、學(xué)習(xí)筆記、問題解決方案、部署方案以及全棧式答疑,期待交流!