
在 Go 中恰到好處的內(nèi)存對齊
# 1. 問題
在開始之前,希望你計算一下 Part1 共占用的大小是多少呢?
type?Part1?struct?{
?a?bool
?b?int32
?c?int8
?d?int64
?e?byte
}
運行如下代碼
func?main()?{
?fmt.Printf("bool?size:?%d\n",?unsafe.Sizeof(bool(true)))
?fmt.Printf("int32?size:?%d\n",?unsafe.Sizeof(int32(0)))
?fmt.Printf("int8?size:?%d\n",?unsafe.Sizeof(int8(0)))
?fmt.Printf("int64?size:?%d\n",?unsafe.Sizeof(int64(0)))
?fmt.Printf("byte?size:?%d\n",?unsafe.Sizeof(byte(0)))
?fmt.Printf("string?size:?%d\n",?unsafe.Sizeof("EDDYCJY"))
}
輸出結果:
bool?size:?1
int32?size:?4
int8?size:?1
int64?size:?8
byte?size:?1
string?size:?16
這么一算,Part1 這一個結構體的占用內(nèi)存大小為 1+4+1+8+1 = 15 個字節(jié)。相信有的小伙伴是這么算的,看上去也沒什么毛病
真實情況是怎么樣的呢?我們實際調(diào)用看看,如下:
type?Part1?struct?{
?a?bool
?b?int32
?c?int8
?d?int64
?e?byte
}
func?main()?{
?part1?:=?Part1{}
?fmt.Printf("part1?size:?%d,?align:?%d\n",?unsafe.Sizeof(part1),?unsafe.Alignof(part1))
}
輸出結果:
part1?size:?32,?align:?8
最終輸出為占用 32 個字節(jié)。這與前面所預期的結果完全不一樣。這充分地說明了先前的計算方式是錯誤的。為什么呢?
在這里要提到 “內(nèi)存對齊” 這一概念,才能夠用正確的姿勢去計算,接下來我們詳細的講講它是什么
# 2. 內(nèi)存對齊
有的小伙伴可能會認為內(nèi)存讀取,就是一個簡單的字節(jié)數(shù)組擺放

上圖表示一個坑一個蘿卜的內(nèi)存讀取方式。但實際上 CPU 并不會以一個一個字節(jié)去讀取和寫入內(nèi)存。相反 CPU 讀取內(nèi)存是一塊一塊讀取的,塊的大小可以為 2、4、6、8、16 字節(jié)等大小。塊大小我們稱其為內(nèi)存訪問粒度。如下圖:
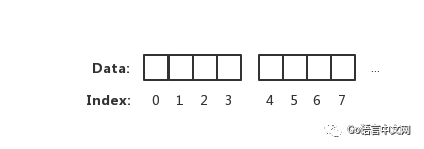
在樣例中,假設訪問粒度為 4。CPU 是以每 4 個字節(jié)大小的訪問粒度去讀取和寫入內(nèi)存的。這才是正確的姿勢
?為什么要關心對齊
你正在編寫的代碼在性能(CPU、Memory)方面有一定的要求
你正在處理向量方面的指令
某些硬件平臺(ARM)體系不支持未對齊的內(nèi)存訪問
另外作為一個工程師,你也很有必要學習這塊知識點哦 :)
?為什么要做對齊
平臺(移植性)原因:不是所有的硬件平臺都能夠訪問任意地址上的任意數(shù)據(jù)。例如:特定的硬件平臺只允許在特定地址獲取特定類型的數(shù)據(jù),否則會導致異常情況
性能原因:若訪問未對齊的內(nèi)存,將會導致 CPU 進行兩次內(nèi)存訪問,并且要花費額外的時鐘周期來處理對齊及運算。而本身就對齊的內(nèi)存僅需要一次訪問就可以完成讀取動作
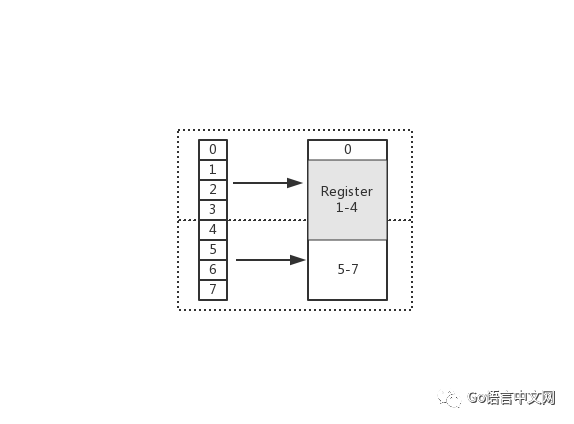
在上圖中,假設從 Index 1 開始讀取,將會出現(xiàn)很崩潰的問題。因為它的內(nèi)存訪問邊界是不對齊的。因此 CPU 會做一些額外的處理工作。如下:
CPU 首次讀取未對齊地址的第一個內(nèi)存塊,讀取 0-3 字節(jié)。并移除不需要的字節(jié) 0
CPU 再次讀取未對齊地址的第二個內(nèi)存塊,讀取 4-7 字節(jié)。并移除不需要的字節(jié) 5、6、7 字節(jié)
合并 1-4 字節(jié)的數(shù)據(jù)
合并后放入寄存器
從上述流程可得出,不做 “內(nèi)存對齊” 是一件有點 “麻煩” 的事。因為它會增加許多耗費時間的動作
而假設做了內(nèi)存對齊,從 Index 0 開始讀取 4 個字節(jié),只需要讀取一次,也不需要額外的運算。這顯然高效很多,是標準的空間換時間做法
?默認系數(shù)
在不同平臺上的編譯器都有自己默認的 “對齊系數(shù)”,可通過預編譯命令 #pragma pack(n) 進行變更,n 就是代指 “對齊系數(shù)”。一般來講,我們常用的平臺的系數(shù)如下:
32 位:4
64 位:8
另外要注意,不同硬件平臺占用的大小和對齊值都可能是不一樣的。因此本文的值不是唯一的,調(diào)試的時候需按本機的實際情況考慮
?成員對齊
func?main()?{
?fmt.Printf("bool?align:?%d\n",?unsafe.Alignof(bool(true)))
?fmt.Printf("int32?align:?%d\n",?unsafe.Alignof(int32(0)))
?fmt.Printf("int8?align:?%d\n",?unsafe.Alignof(int8(0)))
?fmt.Printf("int64?align:?%d\n",?unsafe.Alignof(int64(0)))
?fmt.Printf("byte?align:?%d\n",?unsafe.Alignof(byte(0)))
?fmt.Printf("string?align:?%d\n",?unsafe.Alignof("EDDYCJY"))
?fmt.Printf("map?align:?%d\n",?unsafe.Alignof(map[string]string{}))
}
輸出結果:
bool?align:?1
int32?align:?4
int8?align:?1
int64?align:?8
byte?align:?1
string?align:?8
map?align:?8
在 Go 中可以調(diào)用 unsafe.Alignof 來返回相應類型的對齊系數(shù)。通過觀察輸出結果,可得知基本都是 2^n,最大也不會超過 8。這是因為我手提(64 位)編譯器默認對齊系數(shù)是 8,因此最大值不會超過這個數(shù)
?整體對齊
在上小節(jié)中,提到了結構體中的成員變量要做字節(jié)對齊。那么想當然身為最終結果的結構體,也是需要做字節(jié)對齊的
?對齊規(guī)則
結構體的成員變量,第一個成員變量的偏移量為 0。往后的每個成員變量的對齊值必須為編譯器默認對齊長度(
#pragma pack(n))或當前成員變量類型的長度(unsafe.Sizeof),取最小值作為當前類型的對齊值。其偏移量必須為對齊值的整數(shù)倍結構體本身,對齊值必須為編譯器默認對齊長度(
#pragma pack(n))或結構體的所有成員變量類型中的最大長度,取最大數(shù)的最小整數(shù)倍作為對齊值結合以上兩點,可得知若?編譯器默認對齊長度(
#pragma pack(n))超過結構體內(nèi)成員變量的類型最大長度時,默認對齊長度是沒有任何意義的
# 3. 分析流程
接下來我們一起分析一下,“它” 到底經(jīng)歷了些什么,影響了 “預期” 結果
| 成員變量 | 類型 | 偏移量 | 自身占用 |
|---|---|---|---|
| a | bool | 0 | 1 |
| 字節(jié)對齊 | 無 | 1 | 3 |
| b | int32 | 4 | 4 |
| c | int8 | 8 | 1 |
| 字節(jié)對齊 | 無 | 9 | 7 |
| d | int64 | 16 | 8 |
| e | byte | 24 | 1 |
| 字節(jié)對齊 | 無 | 25 | 7 |
| 總占用大小 | - | - | 32 |
?成員對齊
第一個成員 a 類型為 bool 大小/對齊值為 1 字節(jié) 初始地址,偏移量為 0。占用了第 1 位 第二個成員 b 類型為 int32 大小/對齊值為 4 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 4 的整數(shù)倍。確定偏移量為 4,因此 2-4 位為 Padding。而當前數(shù)值從第 5 位開始填充,到第 8 位。如下:axxx|bbbb 第三個成員 c 類型為 int8 大小/對齊值為 1 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 1 的整數(shù)倍。當前偏移量為 8。不需要額外對齊,填充 1 個字節(jié)到第 9 位。如下:axxx|bbbb|c… 第四個成員 d 類型為 int64 大小/對齊值為 8 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 8 的整數(shù)倍。確定偏移量為 16,因此 9-16 位為 Padding。而當前數(shù)值從第 17 位開始寫入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd 第五個成員 e 類型為 byte 大小/對齊值為 1 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 1 的整數(shù)倍。當前偏移量為 24。不需要額外對齊,填充 1 個字節(jié)到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e…
?整體對齊
在每個成員變量進行對齊后,根據(jù)規(guī)則 2,整個結構體本身也要進行字節(jié)對齊,因為可發(fā)現(xiàn)它可能并不是 2^n,不是偶數(shù)倍。顯然不符合對齊的規(guī)則
根據(jù)規(guī)則 2,可得出對齊值為 8。現(xiàn)在的偏移量為 25,不是 8 的整倍數(shù)。因此確定偏移量為 32。對結構體進行對齊
?結果
Part1 內(nèi)存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
?小結
通過本節(jié)的分析,可得知先前的 “推算” 為什么錯誤?
是因為實際內(nèi)存管理并非 “一個蘿卜一個坑” 的思想。而是一塊一塊。通過空間換時間(效率)的思想來完成這塊讀取、寫入。另外也需要兼顧不同平臺的內(nèi)存操作情況
# 4. 巧妙的結構體
在上一小節(jié),可得知根據(jù)成員變量的類型不同,其結構體的內(nèi)存會產(chǎn)生對齊等動作。那假設字段順序不同,會不會有什么變化呢?我們一起來試試吧 :-)
type?Part1?struct?{
?a?bool
?b?int32
?c?int8
?d?int64
?e?byte
}
type?Part2?struct?{
?e?byte
?c?int8
?a?bool
?b?int32
?d?int64
}
func?main()?{
?part1?:=?Part1{}
?part2?:=?Part2{}
?fmt.Printf("part1?size:?%d,?align:?%d\n",?unsafe.Sizeof(part1),?unsafe.Alignof(part1))
?fmt.Printf("part2?size:?%d,?align:?%d\n",?unsafe.Sizeof(part2),?unsafe.Alignof(part2))
}
輸出結果:
part1?size:?32,?align:?8
part2?size:?16,?align:?8
通過結果可以驚喜的發(fā)現(xiàn),只是 “簡單” 對成員變量的字段順序進行改變,就改變了結構體占用大小
接下來我們一起剖析一下 Part2,看看它的內(nèi)部到底和上一位之間有什么區(qū)別,才導致了這樣的結果?
?分析流程
| 成員變量 | 類型 | 偏移量 | 自身占用 |
|---|---|---|---|
| e | byte | 0 | 1 |
| c | int8 | 1 | 1 |
| a | bool | 2 | 1 |
| 字節(jié)對齊 | 無 | 3 | 1 |
| b | int32 | 4 | 4 |
| d | int64 | 8 | 8 |
| 總占用大小 | - | - | 16 |
成員對齊
第一個成員 e 類型為 byte 大小/對齊值為 1 字節(jié) 初始地址,偏移量為 0。占用了第 1 位 第二個成員 c 類型為 int8 大小/對齊值為 1 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 1 的整數(shù)倍。當前偏移量為 2。不需要額外對齊 第三個成員 a 類型為 bool 大小/對齊值為 1 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 1 的整數(shù)倍。當前偏移量為 3。不需要額外對齊 第四個成員 b 類型為 int32 大小/對齊值為 4 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 4 的整數(shù)倍。確定偏移量為 4,因此第 3 位為 Padding。而當前數(shù)值從第 4 位開始填充,到第 8 位。如下:ecax|bbbb 第五個成員 d 類型為 int64 大小/對齊值為 8 字節(jié) 根據(jù)規(guī)則 1,其偏移量必須為 8 的整數(shù)倍。當前偏移量為 8。不需要額外對齊,從 9-16 位填充 8 個字節(jié)。如下:ecax|bbbb|dddd|dddd
整體對齊
符合規(guī)則 2,不需要額外對齊
結果
Part2 內(nèi)存布局:ecax|bbbb|dddd|dddd
# 5. 總結一下
通過對比 Part1 和 Part2 的內(nèi)存布局,你會發(fā)現(xiàn)兩者有很大的不同。如下:
Part1:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
Part2:ecax|bbbb|dddd|dddd
仔細一看,Part1 存在許多 Padding。顯然它占據(jù)了不少空間,那么 Padding 是怎么出現(xiàn)的呢?
通過本文的介紹,可得知是由于不同類型導致需要進行字節(jié)對齊,以此保證內(nèi)存的訪問邊界
那么也不難理解,為什么調(diào)整結構體內(nèi)成員變量的字段順序就能達到縮小結構體占用大小的疑問了,是因為巧妙地減少了 Padding 的存在。讓它們更 “緊湊” 了。這一點對于加深 Go 的內(nèi)存布局印象和大對象的優(yōu)化非常有幫
當然了,沒什么特殊問題,你可以不關注這一塊。但你要知道這塊知識點 ??
本文作者:煎魚原文鏈接:https://eddycjy.com/posts/go/talk/2018-12-26-go-memory-align/
? ?

???