
強大易用!新一代爬蟲利器 Playwright
Playwright 是微軟在 2020 年初開源的新一代自動化測試工具,它的功能類似于 Selenium、Pyppeteer 等,都可以驅(qū)動瀏覽器進行各種自動化操作。它的功能也非常強大,對市面上的主流瀏覽器都提供了支持,API 功能簡潔又強大。雖然誕生比較晚,但是現(xiàn)在發(fā)展得非常火熱。
因為 Playwright 是一個類似 Selenium 一樣可以支持網(wǎng)頁頁面渲染的工具,再加上其強大又簡潔的 API,Playwright 同時也可以作為網(wǎng)絡(luò)爬蟲的一個爬取利器。

1. Playwright 的特點
Playwright 支持當前所有主流瀏覽器,包括 Chrome 和 Edge(基于 Chromium)、Firefox、Safari(基于 WebKit) ,提供完善的自動化控制的 API。 Playwright 支持移動端頁面測試,使用設(shè)備模擬技術(shù)可以使我們在移動 Web 瀏覽器中測試響應式 Web 應用程序。 Playwright 支持所有瀏覽器的 Headless 模式和非 Headless 模式的測試。 Playwright 的安裝和配置非常簡單,安裝過程中會自動安裝對應的瀏覽器和驅(qū)動,不需要額外配置 WebDriver 等。 Playwright 提供了自動等待相關(guān)的 API,當頁面加載的時候會自動等待對應的節(jié)點加載,大大簡化了 API 編寫復雜度。
下面我們就來了解下 Playwright 的使用方法。
2. 安裝
Playwright 目前提供了 Python 和 Node.js 的 API,下面我們針對 Python 版的 Playwright 進行介紹。
要使用 Playwright,需要 Python 3.7 版本及以上,請確保 Python 的版本符合要求。
要安裝 Playwright,可以直接使用 pip3,命令如下:
pip3?install?playwright
安裝完成之后需要進行一些初始化操作:
playwright?install
這時候 Playwrigth 會安裝 Chromium, Firefox and WebKit 瀏覽器并配置一些驅(qū)動,我們不必關(guān)心中間配置的過程,Playwright 會為我們配置好。
具體的安裝說明可以參考:https://setup.scrape.center/playwright。
安裝完成之后,我們便可以使用 Playwright 啟動 Chromium 或 Firefox 或 WebKit 瀏覽器來進行自動化操作了。
3. 基本使用
Playwright 支持兩種編寫模式,一種是類似 Pyppetter 一樣的異步模式,另一種是像 Selenium 一樣的同步模式,我們可以根據(jù)實際需要選擇使用不同的模式。
我們先來看一個基本同步模式的例子:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????for?browser_type?in?[p.chromium,?p.firefox,?p.webkit]:
????????browser?=?browser_type.launch(headless=False)
????????page?=?browser.new_page()
????????page.goto('https://www.baidu.com')
????????page.screenshot(path=f'screenshot-{browser_type.name}.png')
????????print(page.title())
????????browser.close()
首先我們導入了 sync_playwright 方法,然后直接調(diào)用了這個方法,該方法返回的是一個 PlaywrightContextManager 對象,可以理解是一個瀏覽器上下文管理器,我們將其賦值為變量 p。
接著我們調(diào)用了 PlaywrightContextManager 對象的 chromium、firefox、webkit 屬性依次創(chuàng)建了一個 Chromium、Firefox 以及 Webkit 瀏覽器實例,接著用一個 for 循環(huán)依次執(zhí)行了它們的 launch 方法,同時設(shè)置了 headless 參數(shù)為 False。
“注意:如果不設(shè)置為 False,默認是無頭模式啟動瀏覽器,我們看不到任何窗口。
”
launch 方法返回的是一個 Browser 對象,我們將其賦值為 browser 變量。然后調(diào)用 browser 的 new_page 方法,相當于新建了一個選項卡,返回的是一個 Page 對象,將其賦值為 page,這整個過程其實和 Pyppeteer 非常類似。接著我們就可以調(diào)用 page 的一系列 API 來進行各種自動化操作了,比如調(diào)用 goto,就是加載某個頁面,這里我們訪問的是百度的首頁。接著我們調(diào)用了 page 的 screenshot 方法,參數(shù)傳一個文件名稱,這樣截圖就會自動保存為該圖片名稱,這里名稱中我們加入了 browser_type 的 name 屬性,代表瀏覽器的類型,結(jié)果分別就是 chromium, firefox, webkit。另外我們還調(diào)用了 title 方法,該方法會返回頁面的標題,即 HTML 中 ?title 節(jié)點中的文字,也就是選項卡上的文字,我們將該結(jié)果打印輸出到控制臺。最后操作完畢,調(diào)用 browser 的 close 方法關(guān)閉整個瀏覽器,運行結(jié)束。
運行一下,這時候我們可以看到有三個瀏覽器依次啟動并加載了百度這個頁面,分別是 Chromium、Firefox 和 Webkit 三個瀏覽器,頁面加載完成之后,生成截圖、控制臺打印結(jié)果就退出了。
這時候當前目錄便會生成三個截圖文件,都是百度的首頁,文件名中都帶有了瀏覽器的名稱,如圖所示:

控制臺運行結(jié)果如下:
百度一下,你就知道
百度一下,你就知道
百度一下,你就知道
通過運行結(jié)果我們可以發(fā)現(xiàn),我們非常方便地啟動了三種瀏覽器并完成了自動化操作,并通過幾個 API 就完成了截圖和數(shù)據(jù)的獲取,整個運行速度是非常快的,者就是 Playwright 最最基本的用法。
當然除了同步模式,Playwright 還提供異步的 API,如果我們項目里面使用了 asyncio,那就應該使用異步模式,寫法如下:
import?asyncio
from?playwright.async_api?import?async_playwright
async?def?main():
????async?with?async_playwright()?as?p:
????????for?browser_type?in?[p.chromium,?p.firefox,?p.webkit]:
????????????browser?=?await?browser_type.launch()
????????????page?=?await?browser.new_page()
????????????await?page.goto('https://www.baidu.com')
????????????await?page.screenshot(path=f'screenshot-{browser_type.name}.png')
????????????print(await?page.title())
????????????await?browser.close()
asyncio.run(main())
可以看到整個寫法和同步模式基本類似,導入的時候使用的是 async_playwright 方法,而不再是 sync_playwright 方法。寫法上添加了 async/await 關(guān)鍵字的使用,最后的運行效果是一樣的。
另外我們注意到,這例子中使用了 with as 語句,with 用于上下文對象的管理,它可以返回一個上下文管理器,也就對應一個 PlaywrightContextManager 對象,無論運行期間是否拋出異常,它能夠幫助我們自動分配并且釋放 Playwright 的資源。
4. 代碼生成
Playwright 還有一個強大的功能,那就是可以錄制我們在瀏覽器中的操作并將代碼自動生成出來,有了這個功能,我們甚至都不用寫任何一行代碼,這個功能可以通過 playwright 命令行調(diào)用 codegen 來實現(xiàn),我們先來看看 codegen 命令都有什么參數(shù),輸入如下命令:
playwright?codegen?--help
結(jié)果類似如下:
Usage:?npx?playwright?codegen?[options]?[url]
open?page?and?generate?code?for?user?actions
Options:
??-o,?--output??????saves?the?generated?script?to?a?file
??--target???????????language?to?use,?one?of?javascript,?python,?python-async,?csharp?(default:?"python")
??-b,?--browser???browser?to?use,?one?of?cr,?chromium,?ff,?firefox,?wk,?webkit?(default:?"chromium")
??--channel???????????Chromium?distribution?channel,?"chrome",?"chrome-beta",?"msedge-dev",?etc
??--color-scheme???????emulate?preferred?color?scheme,?"light"?or?"dark"
??--device?????????emulate?device,?for?example??"iPhone?11"
??--geolocation???specify?geolocation?coordinates,?for?example?"37.819722,-122.478611"
??--load-storage?????load?context?storage?state?from?the?file,?previously?saved?with?--save-storage
??--lang?????????????specify?language?/?locale,?for?example?"en-GB"
??--proxy-server????????specify?proxy?server,?for?example?"http://myproxy:3128"?or?"socks5://myproxy:8080"
??--save-storage?????save?context?storage?state?at?the?end,?for?later?use?with?--load-storage
??--timezone????????time?zone?to?emulate,?for?example?"Europe/Rome"
??--timeout???????????timeout?for?Playwright?actions?in?milliseconds?(default:?"10000")
??--user-agent??????specify?user?agent?string
??--viewport-size????????specify?browser?viewport?size?in?pixels,?for?example?"1280,?720"
??-h,?--help???????????????????display?help?for?command
Examples:
??$?codegen
??$?codegen?--target=python
??$?codegen?-b?webkit?https://example.com
可以看到這里有幾個選項,比如 -o 代表輸出的代碼文件的名稱;--target 代表使用的語言,默認是 python,即會生成同步模式的操作代碼,如果傳入 python-async 就會生成異步模式的代碼;-b 代表的是使用的瀏覽器,默認是 Chromium,其他還有很多設(shè)置,比如 --device 可以模擬使用手機瀏覽器,比如 iPhone 11,--lang 代表設(shè)置瀏覽器的語言,--timeout 可以設(shè)置頁面加載超時時間。
好,了解了這些用法,那我們就來嘗試啟動一個 Firefox 瀏覽器,然后將操作結(jié)果輸出到 script.py 文件,命令如下:
playwright?codegen?-o?script.py?-b?firefox
這時候就彈出了一個 Firefox 瀏覽器,同時右側(cè)會輸出一個腳本窗口,實時顯示當前操作對應的代碼。
我們可以在瀏覽器中做任何操作,比如打開百度,然后點擊輸入框并輸入 nba,然后再點擊搜索按鈕,瀏覽器窗口如下:
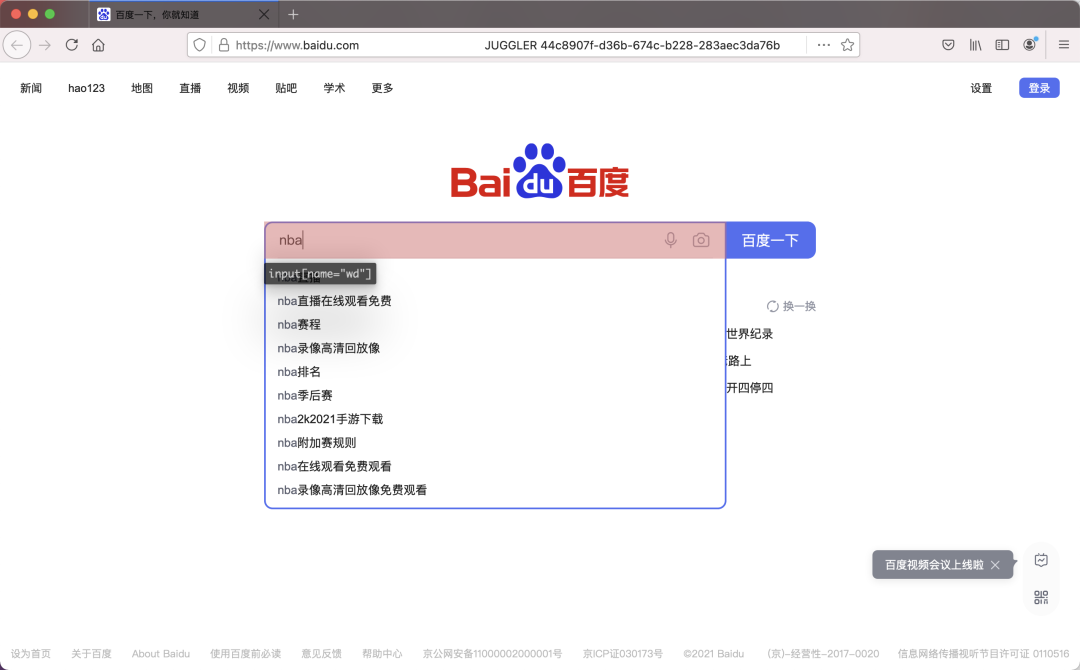
可以看見瀏覽器中還會高亮顯示我們正在操作的頁面節(jié)點,同時還顯示了對應的選擇器字符串 input[name="wd"],右側(cè)的窗口如圖所示:
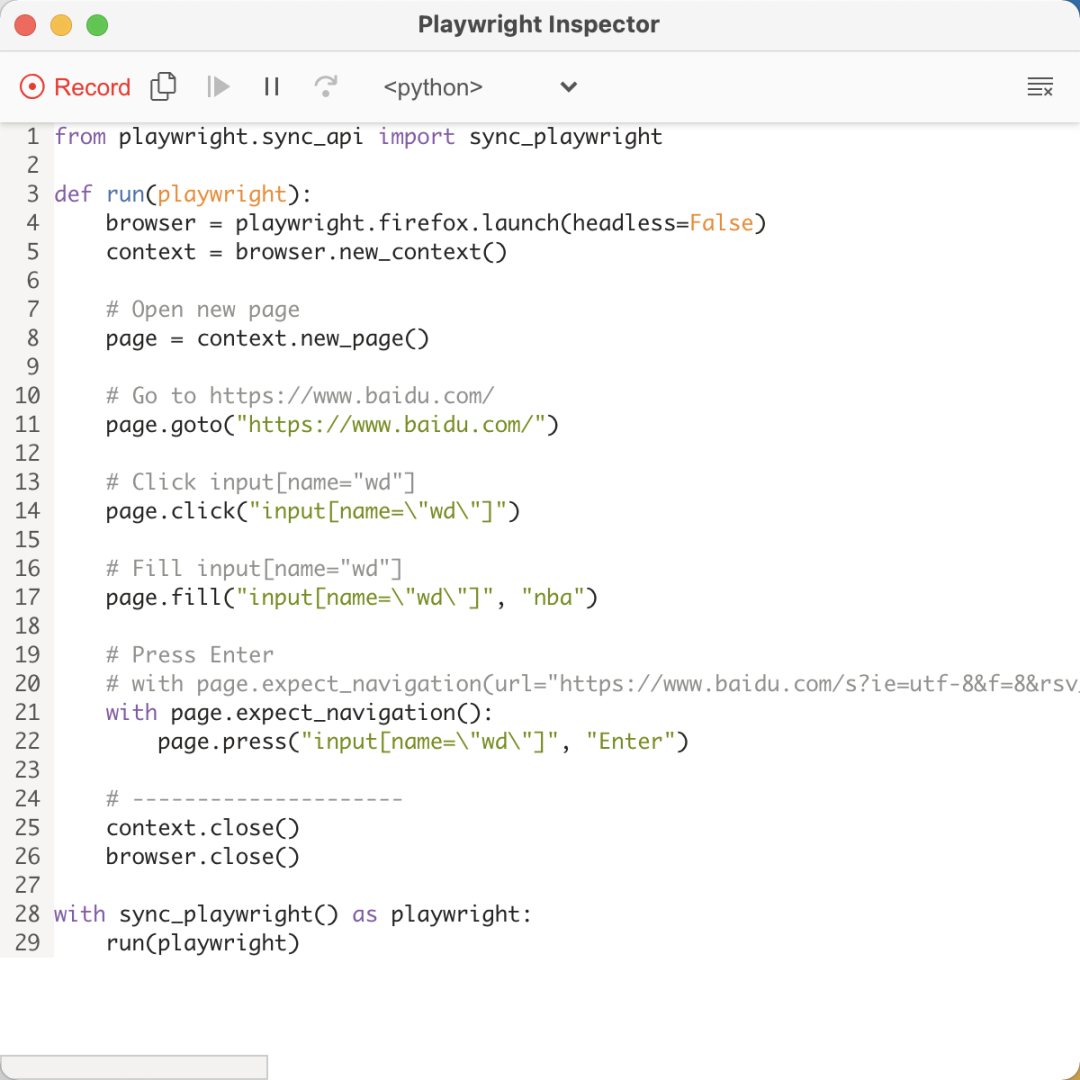
在操作過程中,該窗口中的代碼就實時變化,可以看到這里生成了我們一系列操作的對應代碼,比如在搜索框中輸入 nba,就對應如下代碼:
page.fill("input[name=\"wd\"]",?"nba")
操作完畢之后,關(guān)閉瀏覽器,Playwright 會生成一個 script.py 文件,內(nèi)容如下:
from?playwright.sync_api?import?sync_playwright
def?run(playwright):
????browser?=?playwright.firefox.launch(headless=False)
????context?=?browser.new_context()
????#?Open?new?page
????page?=?context.new_page()
????#?Go?to?https://www.baidu.com/
????page.goto("https://www.baidu.com/")
????#?Click?input[name="wd"]
????page.click("input[name=\"wd\"]")
????#?Fill?input[name="wd"]
????page.fill("input[name=\"wd\"]",?"nba")
????#?Click?text=百度一下
????with?page.expect_navigation():
????????page.click("text=百度一下")
????context.close()
????browser.close()
with?sync_playwright()?as?playwright:
????run(playwright)
可以看到這里生成的代碼和我們之前寫的示例代碼幾乎差不多,而且也是完全可以運行的,運行之后就可以看到它又可以復現(xiàn)我們剛才所做的操作了。
所以,有了這個功能,我們甚至都不用編寫任何代碼,只通過簡單的可視化點擊就能把代碼生成出來,可謂是非常方便了!
另外這里有一個值得注意的點,仔細觀察下生成的代碼,和前面的例子不同的是,這里 new_page 方法并不是直接通過 browser 調(diào)用的,而是通過 context 變量調(diào)用的,這個 context 又是由 browser 通過調(diào)用 new_context 方法生成的。有讀者可能就會問了,這個 context 究竟是做什么的呢?
其實這個 context 變量對應的是一個 BrowserContext 對象,BrowserContext 是一個類似隱身模式的獨立上下文環(huán)境,其運行資源是單獨隔離的,在做一些自動化測試過程中,每個測試用例我們都可以單獨創(chuàng)建一個 BrowserContext 對象,這樣可以保證每個測試用例之間互不干擾,具體的 API 可以參考 https://playwright.dev/python/docs/api/class-browsercontext。
5. 移動端瀏覽器支持
Playwright 另外一個特色功能就是可以支持移動端瀏覽器的模擬,比如模擬打開 iPhone 12 Pro Max 上的 Safari 瀏覽器,然后手動設(shè)置定位,并打開百度地圖并截圖。首先我們可以選定一個經(jīng)緯度,比如故宮的經(jīng)緯度是 39.913904, 116.39014,我們可以通過 geolocation 參數(shù)傳遞給 Webkit 瀏覽器并初始化。
示例代碼如下:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????iphone_12_pro_max?=?p.devices['iPhone?12?Pro?Max']
????browser?=?p.webkit.launch(headless=False)
????context?=?browser.new_context(
????????**iphone_12_pro_max,
????????locale='zh-CN',
????????geolocation={'longitude':?116.39014,?'latitude':?39.913904},
????????permissions=['geolocation']
????)
????page?=?context.new_page()
????page.goto('https://amap.com')
????page.wait_for_load_state(state='networkidle')
????page.screenshot(path='location-iphone.png')
????browser.close()
這里我們先用 PlaywrightContextManager 對象的 devices 屬性指定了一臺移動設(shè)備,這里傳入的是手機的型號,比如 iPhone 12 Pro Max,當然也可以傳其他名稱,比如 iPhone 8,Pixel 2 等。
前面我們已經(jīng)了解了 BrowserContext 對象,BrowserContext 對象也可以用來模擬移動端瀏覽器,初始化一些移動設(shè)備信息、語言、權(quán)限、位置等信息,這里我們就用它來創(chuàng)建了一個移動端 BrowserContext 對象,通過 geolocation 參數(shù)傳入了經(jīng)緯度信息,通過 permissions 參數(shù)傳入了賦予的權(quán)限信息,最后將得到的 BrowserContext 對象賦值為 context 變量。
接著我們就可以用 BrowserContext 對象來新建一個頁面,還是調(diào)用 new_page 方法創(chuàng)建一個新的選項卡,然后跳轉(zhuǎn)到高德地圖,并調(diào)用了 wait_for_load_state 方法等待頁面某個狀態(tài)完成,這里我們傳入的 state 是 networkidle,也就是網(wǎng)絡(luò)空閑狀態(tài)。因為在頁面初始化和加載過程中,肯定是伴隨有網(wǎng)絡(luò)請求的,所以加載過程中肯定不算 networkidle 狀態(tài),所以這里我們傳入 networkidle 就可以標識當前頁面和數(shù)據(jù)加載完成的狀態(tài)。加載完成之后,我們再調(diào)用 screenshot 方法獲取當前頁面截圖,最后關(guān)閉瀏覽器。
運行下代碼,可以發(fā)現(xiàn)這里就彈出了一個移動版瀏覽器,然后加載了高德地圖,并定位到了故宮的位置,如圖所示:
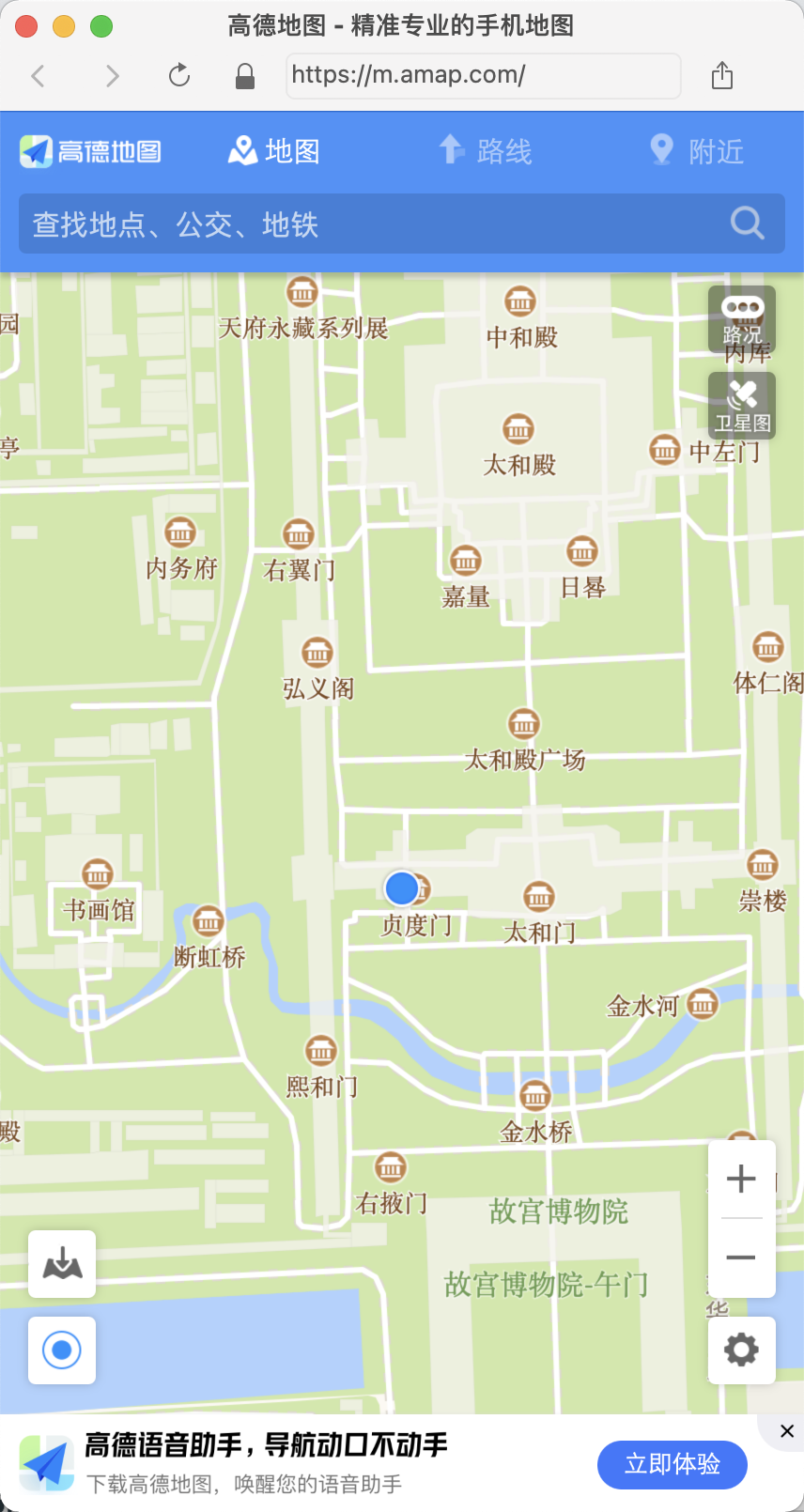
輸出的截圖也是瀏覽器中顯示的結(jié)果。
所以這樣我們就成功實現(xiàn)了移動端瀏覽器的模擬和一些設(shè)置,其操作 API 和 PC 版瀏覽器是完全一樣的。
6. 選擇器
前面我們注意到 click 和 fill 等方法都傳入了一個字符串,這些字符串有的符合 CSS 選擇器的語法,有的又是 text= 開頭的,感覺似乎沒太有規(guī)律的樣子,它到底支持怎樣的匹配規(guī)則呢?下面我們來了解下。
傳入的這個字符串,我們可以稱之為 Element Selector,它不僅僅支持 CSS 選擇器、XPath,Playwright 還擴展了一些方便好用的規(guī)則,比如直接根據(jù)文本內(nèi)容篩選,根據(jù)節(jié)點層級結(jié)構(gòu)篩選等等。
文本選擇
文本選擇支持直接使用 text= 這樣的語法進行篩選,示例如下:
page.click("text=Log?in")
這就代表選擇文本是 Log in 的節(jié)點,并點擊。
CSS 選擇器
CSS 選擇器之前也介紹過了,比如根據(jù) id 或者 class 篩選:
page.click("button")
page.click("#nav-bar?.contact-us-item")
根據(jù)特定的節(jié)點屬性篩選:
page.click("[data-test=login-button]")
page.click("[aria-label='Sign?in']")
CSS 選擇器 + 文本
我們還可以使用 CSS 選擇器結(jié)合文本值進行海選,比較常用的就是 has-text 和 text,前者代表包含指定的字符串,后者代表字符串完全匹配,示例如下:
page.click("article:has-text('Playwright')")
page.click("#nav-bar?:text('Contact?us')")
第一個就是選擇文本中包含 Playwright 的 article 節(jié)點,第二個就是選擇 id 為 nav-bar 節(jié)點中文本值等于 Contact us 的節(jié)點。
CSS 選擇器 + 節(jié)點關(guān)系
還可以結(jié)合節(jié)點關(guān)系來篩選節(jié)點,比如使用 has 來指定另外一個選擇器,示例如下:
page.click(".item-description:has(.item-promo-banner)")
比如這里選擇的就是選擇 class 為 item-description 的節(jié)點,且該節(jié)點還要包含 class 為 item-promo-banner 的子節(jié)點。
另外還有一些相對位置關(guān)系,比如 right-of 可以指定位于某個節(jié)點右側(cè)的節(jié)點,示例如下:
page.click("input:right-of(:text('Username'))")
這里選擇的就是一個 input 節(jié)點,并且該 input 節(jié)點要位于文本值為 Username 的節(jié)點的右側(cè)。
XPath
當然 XPath 也是支持的,不過 xpath 這個關(guān)鍵字需要我們自行制定,示例如下:
page.click("xpath=//button")
這里需要在開頭指定 xpath= 字符串,代表后面是一個 XPath 表達式。
關(guān)于更多選擇器的用法和最佳實踐,可以參考官方文檔:https://playwright.dev/python/docs/selectors。
7. 常用操作方法
上面我們了解了瀏覽器的一些初始化設(shè)置和基本的操作實例,下面我們再對一些常用的操作 API 進行說明。
常見的一些 API 如點擊 click,輸入 fill 等操作,這些方法都是屬于 Page 對象的,所以所有的方法都從 Page 對象的 API 文檔查找就好了,文檔地址:https://playwright.dev/python/docs/api/class-page。
下面介紹幾個常見的 API 用法。
事件監(jiān)聽
Page 對象提供了一個 on 方法,它可以用來監(jiān)聽頁面中發(fā)生的各個事件,比如 close、console、load、request、response 等等。
比如這里我們可以監(jiān)聽 response 事件,response 事件可以在每次網(wǎng)絡(luò)請求得到響應的時候觸發(fā),我們可以設(shè)置對應的回調(diào)方法獲取到對應 Response 的全部信息,示例如下:
from?playwright.sync_api?import?sync_playwright
def?on_response(response):
????print(f'Statue?{response.status}:?{response.url}')
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????page.on('response',?on_response)
????page.goto('https://spa6.scrape.center/')
????page.wait_for_load_state('networkidle')
????browser.close()
這里我們在創(chuàng)建 Page 對象之后,就開始監(jiān)聽 response 事件,同時將回調(diào)方法設(shè)置為 on_response,on_response 對象接收一個參數(shù),然后把 Response 的狀態(tài)碼和鏈接都輸出出來了。
運行之后,可以看到控制臺輸出結(jié)果如下:
Statue?200:?https://spa6.scrape.center/
Statue?200:?https://spa6.scrape.center/css/app.ea9d802a.css
Statue?200:?https://spa6.scrape.center/js/app.5ef0d454.js
Statue?200:?https://spa6.scrape.center/js/chunk-vendors.77daf991.js
Statue?200:?https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css
...
Statue?200:?https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css
Statue?200:?https://spa6.scrape.center/js/chunk-19c920f8.c3a1129d.js
Statue?200:?https://spa6.scrape.center/img/logo.a508a8f0.png
Statue?200:?https://spa6.scrape.center/fonts/element-icons.535877f5.woff
Statue?301:?https://spa6.scrape.center/api/movie?limit=10&offset=0&token=NGMwMzFhNGEzMTFiMzJkOGE0ZTQ1YjUzMTc2OWNiYTI1Yzk0ZDM3MSwxNjIyOTE4NTE5
Statue?200:?https://spa6.scrape.center/api/movie/?limit=10&offset=0&token=NGMwMzFhNGEzMTFiMzJkOGE0ZTQ1YjUzMTc2OWNiYTI1Yzk0ZDM3MSwxNjIyOTE4NTE5
Statue?200:?https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@464w_644h_1e_1c
Statue?200:?https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c
....
Statue?200:?https://p1.meituan.net/movie/b607fba7513e7f15eab170aac1e1400d878112.jpg@464w_644h_1e_1c
“注意:這里省略了部分重復的內(nèi)容。
”
可以看到,這里的輸出結(jié)果其實正好對應瀏覽器 Network 面板中所有的請求和響應內(nèi)容,和下圖是一一對應的:

這個網(wǎng)站我們之前分析過,其真實的數(shù)據(jù)都是 Ajax 加載的,同時 Ajax 請求中還帶有加密參數(shù),不好輕易獲取。
但有了這個方法,這里如果我們想要截獲 Ajax 請求,豈不是就非常容易了?
改寫一下判定條件,輸出對應的 JSON 結(jié)果,改寫如下:
from?playwright.sync_api?import?sync_playwright
def?on_response(response):
????if?'/api/movie/'?in?response.url?and?response.status?==?200:
????????print(response.json())
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????page.on('response',?on_response)
????page.goto('https://spa6.scrape.center/')
????page.wait_for_load_state('networkidle')
????browser.close()
控制臺輸入如下:
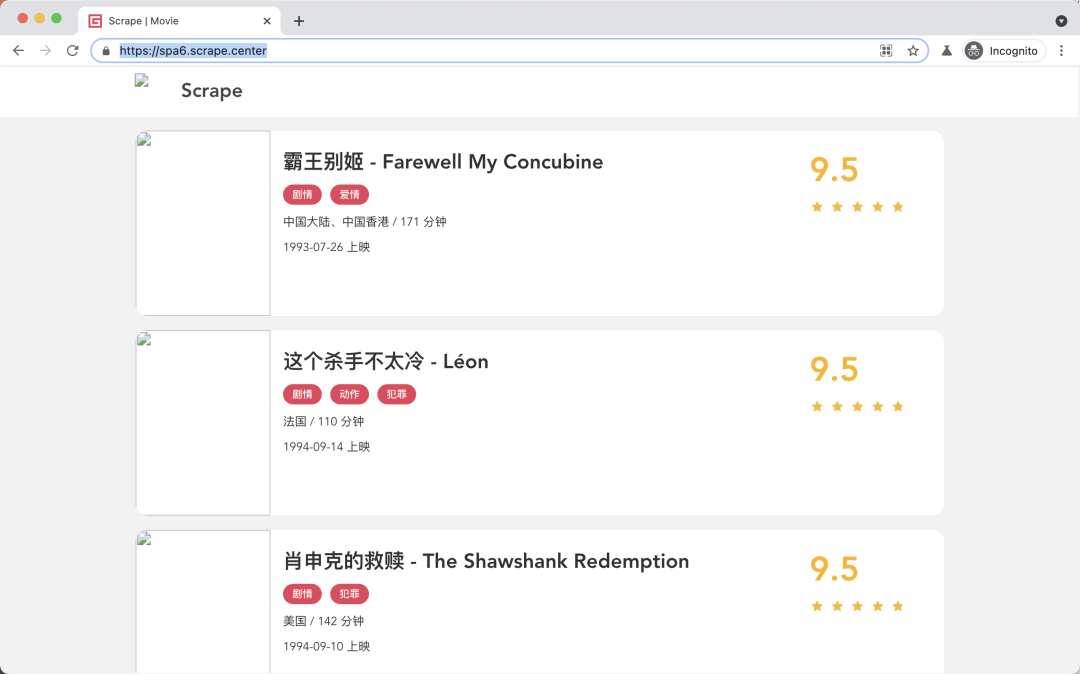
{'count':?100,?'results':?[{'id':?1,?'name':?'霸王別姬',?'alias':?'Farewell?My?Concubine',?'cover':?'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c',?'categories':?['劇情',?'愛情'],?'published_at':?'1993-07-26',?'minute':?171,?'score':?9.5,?'regions':?['中國大陸',?'中國香港']},?
...
'published_at':?None,?'minute':?103,?'score':?9.0,?'regions':?['美國']},?{'id':?10,?'name':?'獅子王',?'alias':?'The?Lion?King',?'cover':?'https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e1438406.jpg@464w_644h_1e_1c',?'categories':?['動畫',?'歌舞',?'冒險'],?'published_at':?'1995-07-15',?'minute':?89,?'score':?9.0,?'regions':?['美國']}]}
簡直是得來全不費工夫,我們直接通過這個方法攔截了 Ajax 請求,直接把響應結(jié)果拿到了,即使這個 Ajax 請求有加密參數(shù),我們也不用關(guān)心,因為我們直接截獲了 Ajax 最后響應的結(jié)果,這對數(shù)據(jù)爬取來說實在是太方便了。
另外還有很多其他的事件監(jiān)聽,這里不再一一介紹了,可以查閱官方文檔,參考類似的寫法實現(xiàn)。
獲取頁面源碼
要獲取頁面的 HTML 代碼其實很簡單,我們直接通過 content 方法獲取即可,用法如下:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????page.goto('https://spa6.scrape.center/')
????page.wait_for_load_state('networkidle')
????html?=?page.content()
????print(html)
????browser.close()
運行結(jié)果就是頁面的 HTML 代碼。獲取了 HTML 代碼之后,我們通過一些解析工具就可以提取想要的信息了。
頁面點擊
剛才我們通過示例也了解了頁面點擊的方法,那就是 click,這里詳細說一下其使用方法。
頁面點擊的 API 定義如下:
page.click(selector,?**kwargs)
這里可以看到必傳的參數(shù)是 selector,其他的參數(shù)都是可選的。第一個 selector 就代表選擇器,可以用來匹配想要點擊的節(jié)點,如果傳入的選擇器匹配了多個節(jié)點,那么只會用第一個節(jié)點。
這個方法的內(nèi)部執(zhí)行邏輯如下:
根據(jù) selector 找到匹配的節(jié)點,如果沒有找到,那就一直等待直到超時,超時時間可以由額外的 timeout 參數(shù)設(shè)置,默認是 30 秒。 等待對該節(jié)點的可操作性檢查的結(jié)果,比如說如果某個按鈕設(shè)置了不可點擊,那它會等待該按鈕變成了可點擊的時候才去點擊,除非通過 force 參數(shù)設(shè)置跳過可操作性檢查步驟強制點擊。 如果需要的話,就滾動下頁面,將需要被點擊的節(jié)點呈現(xiàn)出來。 調(diào)用 page 對象的 mouse 方法,點擊節(jié)點中心的位置,如果指定了 position 參數(shù),那就點擊指定的位置。
click 方法的一些比較重要的參數(shù)如下:
click_count:點擊次數(shù),默認為 1。 timeout:等待要點擊的節(jié)點的超時時間,默認是 30 秒。 position:需要傳入一個字典,帶有 x 和 y 屬性,代表點擊位置相對節(jié)點左上角的偏移位置。 force:即使不可點擊,那也強制點擊。默認是 False。
具體的 API 設(shè)置參數(shù)可以參考官方文檔:https://playwright.dev/python/docs/api/class-page/#pageclickselector-kwargs。
文本輸入
文本輸入對應的方法是 fill,API 定義如下:
page.fill(selector,?value,?**kwargs)
這個方法有兩個必傳參數(shù),第一個參數(shù)也是 selector,第二個參數(shù)是 value,代表輸入的內(nèi)容,另外還可以通過 timeout 參數(shù)指定對應節(jié)點的最長等待時間。
獲取節(jié)點屬性
除了對節(jié)點進行操作,我們還可以獲取節(jié)點的屬性,方法就是 get_attribute,API 定義如下:
page.get_attribute(selector,?name,?**kwargs)
這個方法有兩個必傳參數(shù),第一個參數(shù)也是 selector,第二個參數(shù)是 name,代表要獲取的屬性名稱,另外還可以通過 timeout 參數(shù)指定對應節(jié)點的最長等待時間。
示例如下:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????page.goto('https://spa6.scrape.center/')
????page.wait_for_load_state('networkidle')
????href?=?page.get_attribute('a.name',?'href')
????print(href)
????browser.close()
這里我們調(diào)用了 get_attribute 方法,傳入的 selector 是 a.name,選定了 class 為 name 的 a 節(jié)點,然后第二個參數(shù)傳入了 href,獲取超鏈接的內(nèi)容,輸出結(jié)果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
可以看到對應 href 屬性就獲取出來了,但這里只有一條結(jié)果,因為這里有個條件,那就是如果傳入的選擇器匹配了多個節(jié)點,那么只會用第一個節(jié)點。
那怎么獲取所有的節(jié)點呢?
獲取多個節(jié)點
獲取所有節(jié)點可以使用 query_selector_all 方法,它可以返回節(jié)點列表,通過遍歷獲取到單個節(jié)點之后,我們可以接著調(diào)用單個節(jié)點的方法來進行一些操作和屬性獲取,示例如下:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????page.goto('https://spa6.scrape.center/')
????page.wait_for_load_state('networkidle')
????elements?=?page.query_selector_all('a.name')
????for?element?in?elements:
????????print(element.get_attribute('href'))
????????print(element.text_content())
????browser.close()
這里我們通過 query_selector_all 方法獲取了所有匹配到的節(jié)點,每個節(jié)點對應的是一個 ElementHandle 對象,然后 ElementHandle 對象也有 get_attribute 方法來獲取節(jié)點屬性,另外還可以通過 text_content 方法獲取節(jié)點文本。
運行結(jié)果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
霸王別姬?-?Farewell?My?Concubine
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIy
這個殺手不太冷?-?Léon
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIz
肖申克的救贖?-?The?Shawshank?Redemption
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI0
泰坦尼克號?-?Titanic
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI1
羅馬假日?-?Roman?Holiday
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2
唐伯虎點秋香?-?Flirting?Scholar
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI3
亂世佳人?-?Gone?with?the?Wind
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI4
喜劇之王?-?The?King?of?Comedy
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI5
楚門的世界?-?The?Truman?Show
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIxMA==
獅子王?-?The?Lion?King
獲取單個節(jié)點
獲取單個節(jié)點也有特定的方法,就是 query_selector,如果傳入的選擇器匹配到多個節(jié)點,那它只會返回第一個節(jié)點,示例如下:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????page.goto('https://spa6.scrape.center/')
????page.wait_for_load_state('networkidle')
????element?=?page.query_selector('a.name')
????print(element.get_attribute('href'))
????print(element.text_content())
????browser.close()
運行結(jié)果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
霸王別姬?-?Farewell?My?Concubine
可以看到這里只輸出了第一個匹配節(jié)點的信息。
網(wǎng)絡(luò)劫持
最后再介紹一個實用的方法 route,利用 route 方法,我們可以實現(xiàn)一些網(wǎng)絡(luò)劫持和修改操作,比如修改 request 的屬性,修改 response 響應結(jié)果等。
看一個實例:
from?playwright.sync_api?import?sync_playwright
import?re
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????def?cancel_request(route,?request):
????????route.abort()
????page.route(re.compile(r"(\.png)|(\.jpg)"),?cancel_request)
????page.goto("https://spa6.scrape.center/")
????page.wait_for_load_state('networkidle')
????page.screenshot(path='no_picture.png')
????browser.close()
這里我們調(diào)用了 route 方法,第一個參數(shù)通過正則表達式傳入了匹配的 URL 路徑,這里代表的是任何包含 .png 或 .jpg ?的鏈接,遇到這樣的請求,會回調(diào) cancel_request 方法處理,cancel_request 方法可以接收兩個參數(shù),一個是 route,代表一個 CallableRoute 對象,另外一個是 request,代表 Request 對象。這里我們直接調(diào)用了 route 的 abort 方法,取消了這次請求,所以最終導致的結(jié)果就是圖片的加載全部取消了。
觀察下運行結(jié)果,如圖所示:
可以看到圖片全都加載失敗了。
這個設(shè)置有什么用呢?其實是有用的,因為圖片資源都是二進制文件,而我們在做爬取過程中可能并不想關(guān)心其具體的二進制文件的內(nèi)容,可能只關(guān)心圖片的 URL 是什么,所以在瀏覽器中是否把圖片加載出來就不重要了。所以如此設(shè)置之后,我們可以提高整個頁面的加載速度,提高爬取效率。
另外,利用這個功能,我們還可以將一些響應內(nèi)容進行修改,比如直接修改 Response 的結(jié)果為自定義的文本文件內(nèi)容。
首先這里定義一個 HTML 文本文件,命名為 custom_response.html,內(nèi)容如下:
html>
<html>
??<head>
????<title>Hack?Responsetitle>
??head>
??<body>
????<h1>Hack?Responseh1>
??body>
html>
代碼編寫如下:
from?playwright.sync_api?import?sync_playwright
with?sync_playwright()?as?p:
????browser?=?p.chromium.launch(headless=False)
????page?=?browser.new_page()
????def?modify_response(route,?request):
????????route.fulfill(path="./custom_response.html")
????page.route('/',?modify_response)
????page.goto("https://spa6.scrape.center/")
????browser.close()
這里我們使用 route 的 fulfill 方法指定了一個本地文件,就是剛才我們定義的 HTML 文件,運行結(jié)果如下:
可以看到,Response 的運行結(jié)果就被我們修改了,URL 還是不變的,但是結(jié)果已經(jīng)成了我們修改的 HTML 代碼。
所以通過 route 方法,我們可以靈活地控制請求和響應的內(nèi)容,從而在某些場景下達成某些目的。
8. 總結(jié)
本文介紹了 Playwright 的基本用法。它是一款自動化測試工具,其 API 強大又易于使用,同時具備很多 Selenium、Pyppeteer 不具備的更好用的 API,所以可以用來抓取復雜的?JavaScript 渲染頁面,可謂是新一代的爬取利器。
本文相關(guān)代碼下載:https://github.com/Python3WebSpider/PlaywrightTest
如果文章對你有幫助,歡迎轉(zhuǎn)發(fā)/點贊/收藏~
作者:崔慶才
_往期文章推薦_