
一定要搞懂這些MySQL優(yōu)化技巧
點(diǎn)擊上方“數(shù)據(jù)管道”,選擇“置頂星標(biāo)”公眾號(hào)
干貨福利,第一時(shí)間送達(dá)

SQL 優(yōu)化已經(jīng)成為衡量程序猿優(yōu)秀與否的硬性指標(biāo),甚至在各大廠招聘崗位職能上都有明碼標(biāo)注,如果是你,在這個(gè)問題上能吊打面試官還是會(huì)被吊打呢?
有朋友疑問到,SQL 優(yōu)化真的有這么重要么?如下圖所示,SQL 優(yōu)化在提升系統(tǒng)性能中是:成本最低和優(yōu)化效果最明顯的途徑。
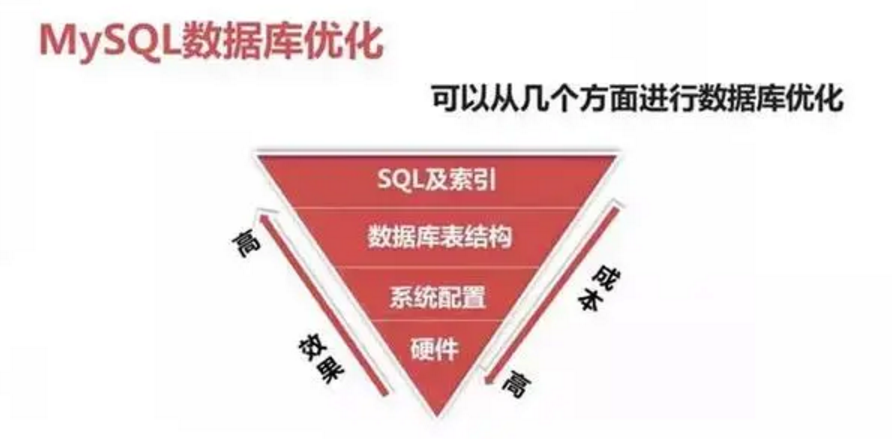
優(yōu)化成本:硬件>系統(tǒng)配置>數(shù)據(jù)庫表結(jié)構(gòu)>SQL 及索引。
優(yōu)化效果:硬件<系統(tǒng)配置<數(shù)據(jù)庫表結(jié)構(gòu)
String?result?=?"嗯,不錯(cuò),";
if?("SQL優(yōu)化經(jīng)驗(yàn)足")?{
????if?("熟悉事務(wù)鎖")?{
????????if?("并發(fā)場(chǎng)景處理666")?{
????????????if?("會(huì)打王者榮耀")?{
????????????????result?+=?"明天入職"?
????????????}
????????}
????}
}?else?{
????result?+=?"先回去等消息吧";
}?
Logger.info("面試官:"?+?result?);
減少數(shù)據(jù)訪問:設(shè)置合理的字段類型,啟用壓縮,通過索引訪問等減少磁盤 IO。
返回更少的數(shù)據(jù):只返回需要的字段和數(shù)據(jù)分頁處理,減少磁盤 IO 及網(wǎng)絡(luò) IO。
減少交互次數(shù):批量 DML 操作,函數(shù)存儲(chǔ)等減少數(shù)據(jù)連接次數(shù)。
減少服務(wù)器 CPU 開銷:盡量減少數(shù)據(jù)庫排序操作以及全表查詢,減少 CPU 內(nèi)存占用。
利用更多資源:使用表分區(qū),可以增加并行操作,更大限度利用 CPU 資源。
最大化利用索引。
盡可能避免全表掃描。
減少無效數(shù)據(jù)的查詢。
SELECT 語句,語法順序如下:
1.?SELECT?
2.?DISTINCT?
3.?FROM?
4.??JOIN?
5.?ON?
6.?WHERE?
7.?GROUP?BY?
8.?HAVING?
9.?ORDER?BY?
10.LIMIT?
SELECT 語句,執(zhí)行順序如下:
FROM
<表名>?#?選取表,將多個(gè)表數(shù)據(jù)通過笛卡爾積變成一個(gè)表。
ON
<篩選條件>?#?對(duì)笛卡爾積的虛表進(jìn)行篩選
JOIN?<join,?left?join,?right?join...>?
<join表>?#?指定join,用于添加數(shù)據(jù)到on之后的虛表中,例如left?join會(huì)將左表的剩余數(shù)據(jù)添加到虛表中
WHERE
<where條件>?#?對(duì)上述虛表進(jìn)行篩選
GROUP?BY
<分組條件>?#?分組
?#?用于having子句進(jìn)行判斷,在書寫上這類聚合函數(shù)是寫在having判斷里面的
HAVING
<分組篩選>?#?對(duì)分組后的結(jié)果進(jìn)行聚合篩選
SELECT
<返回?cái)?shù)據(jù)列表>?#?返回的單列必須在group?by子句中,聚合函數(shù)除外
DISTINCT
#?數(shù)據(jù)除重
ORDER?BY
<排序條件>?#?排序
LIMIT
<行數(shù)限制>
以下 SQL 優(yōu)化策略適用于數(shù)據(jù)量較大的場(chǎng)景下,如果數(shù)據(jù)量較小,沒必要以此為準(zhǔn),以免畫蛇添足。
避免不走索引的場(chǎng)景
SELECT?*?FROM?t?WHERE?username?LIKE?'%陳%'
SELECT?*?FROM?t?WHERE?username?LIKE?'陳%'
使用 MySQL 內(nèi)置函數(shù) INSTR(str,substr)來匹配,作用類似于 Java 中的 indexOf(),查詢字符串出現(xiàn)的角標(biāo)位置。
使用 FullText 全文索引,用 match against 檢索。
數(shù)據(jù)量較大的情況,建議引用 ElasticSearch、Solr,億級(jí)數(shù)據(jù)量檢索速度秒級(jí)。
當(dāng)表數(shù)據(jù)量較少(幾千條兒那種),別整花里胡哨的,直接用 like '%xx%'。
如下:
SELECT?*?FROM?t?WHERE?id?IN?(2,3)
如下:
SELECT?*?FROM?t?WHERE?id?BETWEEN?2?AND?3
如下:
--?不走索引
select?*?from?A?where?A.id?in?(select?id?from?B);
--?走索引
select?*?from?A?where?exists?(select?*?from?B?where?B.id?=?A.id);
如下:
SELECT?*?FROM?t?WHERE?id?=?1?OR?id?=?3
如下:
SELECT?*?FROM?t?WHERE?id?=?1
???UNION
SELECT?*?FROM?t?WHERE?id?=?3
如下:
SELECT?*?FROM?t?WHERE?score?IS?NULL
如下:
SELECT?*?FROM?t?WHERE?score?=?0
--?全表掃描
SELECT?*?FROM?T?WHERE?score/10?=?9
--?走索引
SELECT?*?FROM?T?WHERE?score?=?10*9
如下:
SELECT?username,?age,?sex?FROM?T?WHERE?1=1
⑦查詢條件不能用 <> 或者 !=
如下:復(fù)合(聯(lián)合)索引包含 key_part1,key_part2,key_part3 三列,但 SQL 語句沒有包含索引前置列"key_part1",按照 MySQL 聯(lián)合索引的最左匹配原則,不會(huì)走聯(lián)合索引。
select?col1?from?table?where?key_part2=1?and?key_part3=2
如下 SQL 語句由于索引對(duì)列類型為 varchar,但給定的值為數(shù)值,涉及隱式類型轉(zhuǎn)換,造成不能正確走索引。
select?col1?from?table?where?col_varchar=123;?
如下:
--?不走age索引
SELECT?*?FROM?t?order?by?age;
--?走age索引
SELECT?*?FROM?t?where?age?>?0?order?by?age;
第一步:根據(jù) where 條件和統(tǒng)計(jì)信息生成執(zhí)行計(jì)劃,得到數(shù)據(jù)。
第二步:將得到的數(shù)據(jù)排序。當(dāng)執(zhí)行處理數(shù)據(jù)(order by)時(shí),數(shù)據(jù)庫會(huì)先查看第一步的執(zhí)行計(jì)劃,看 order by 的字段是否在執(zhí)行計(jì)劃中利用了索引。如果是,則可以利用索引順序而直接取得已經(jīng)排好序的數(shù)據(jù)。如果不是,則重新進(jìn)行排序操作。
第三步:返回排序后的數(shù)據(jù)。
USE INDEX 在你查詢語句中表名的后面,添加 USE INDEX 來提供希望 MySQL 去參考的索引列表,就可以讓 MySQL 不再考慮其他可用的索引。
例子: SELECT col1 FROM table USE INDEX (mod_time, name)...
IGNORE INDEX 如果只是單純的想讓 MySQL 忽略一個(gè)或者多個(gè)索引,可以使用 IGNORE INDEX 作為 Hint。
例子: SELECT col1 FROM table IGNORE INDEX (priority) ...
FORCE INDEX 為強(qiáng)制 MySQL 使用一個(gè)特定的索引,可在查詢中使用FORCE INDEX 作為 Hint。
例子: SELECT col1 FROM table FORCE INDEX (mod_time) ...
例如:
SELECT?*?FROM?students?FORCE?INDEX?(idx_class_id)?WHERE?class_id?=?1?ORDER?BY?id?DESC;
SELECT 語句其他優(yōu)化
②避免出現(xiàn)不確定結(jié)果的函數(shù)
③多表關(guān)聯(lián)查詢時(shí),小表在前,大表在后
增刪改 DML 語句優(yōu)化
方法一:
insert?into?T?values(1,2);?
insert?into?T?values(1,3);?
insert?into?T?values(1,4);
方法二:
Insert?into?T?values(1,2),(1,3),(1,4);?
減少 SQL 語句解析的操作,MySQL 沒有類似 Oracle 的 share pool,采用方法二,只需要解析一次就能進(jìn)行數(shù)據(jù)的插入操作。
在特定場(chǎng)景可以減少對(duì) DB 連接次數(shù)。
SQL 語句較短,可以減少網(wǎng)絡(luò)傳輸?shù)?IO。
事務(wù)占用的 undo 數(shù)據(jù)塊。
事務(wù)在 redo log 中記錄的數(shù)據(jù)塊。
釋放事務(wù)施加的,減少鎖爭(zhēng)用影響性能。特別是在需要使用 delete 刪除大量數(shù)據(jù)的時(shí)候,必須分解刪除量并定期 commit。
③避免重復(fù)查詢更新的數(shù)據(jù)
簡(jiǎn)單方法實(shí)現(xiàn):
Update?t1?set?time=now()?where?col1=1;?
Select?time?from?t1?where?id?=1;
使用變量,可以重寫為以下方式:
Update?t1?set?time=now?()?where?col1=1?and?@now:?=?now?();?
Select?@now;?
寫入操作優(yōu)先于讀取操作。
對(duì)某張數(shù)據(jù)表的寫入操作某一時(shí)刻只能發(fā)生一次,寫入請(qǐng)求按照它們到達(dá)的次序來處理。
對(duì)某張數(shù)據(jù)表的多個(gè)讀取操作可以同時(shí)地進(jìn)行。
LOW_PRIORITY 關(guān)鍵字應(yīng)用于 DELETE、INSERT、LOAD DATA、REPLACE 和 UPDATE。
HIGH_PRIORITY 關(guān)鍵字應(yīng)用于 SELECT 和 INSERT 語句。
DELAYED 關(guān)鍵字應(yīng)用于 INSERT 和 REPLACE 語句。
查詢條件優(yōu)化
例如:
SELECT?col1,?col2,?COUNT(*)?FROM?table?GROUP?BY?col1,?col2?ORDER?BY?NULL?;
SELECT?col1?FROM?customerinfo?WHERE?CustomerID?NOT?in?(SELECT?CustomerID?FROM?salesinfo?)
尤其是當(dāng) salesinfo 表中對(duì) CustomerID 建有索引的話,性能將會(huì)更好,查詢?nèi)缦拢?/span>
SELECT?col1?FROM?customerinfo?
???LEFT?JOIN?salesinfoON?customerinfo.CustomerID=salesinfo.CustomerID?
??????WHERE?salesinfo.CustomerID?IS?NULL
高效:
SELECT?COL1,?COL2,?COL3?FROM?TABLE?WHERE?COL1?=?10?
UNION?ALL?
SELECT?COL1,?COL2,?COL3?FROM?TABLE?WHERE?COL3=?'TEST';
低效:
SELECT?COL1,?COL2,?COL3?FROM?TABLE?WHERE?COL1?=?10?
UNION?
SELECT?COL1,?COL2,?COL3?FROM?TABLE?WHERE?COL3=?'TEST';
簡(jiǎn)單的 SQL 容易使用到 MySQL 的 QUERY CACHE。
減少鎖表時(shí)間特別是使用 MyISAM 存儲(chǔ)引擎的表。
可以使用多核 CPU。
案例 1:
select?*?from?t?where?thread_id?=?10000?and?deleted?=?0?
???order?by?gmt_create?asc?limit?0,?15;
select?t.*?from?(select?id?from?t?where?thread_id?=?10000?and?deleted?=?0
???order?by?gmt_create?asc?limit?0,?15)?a,?t?
??????where?a.id?=?t.id;
建表優(yōu)化
②盡量使用數(shù)字型字段(如性別,男:1 女:2),若只含數(shù)值信息的字段盡量不要設(shè)計(jì)為字符型,這會(huì)降低查詢和連接的性能,并會(huì)增加存儲(chǔ)開銷。
這是因?yàn)橐嬖谔幚聿樵兒瓦B接時(shí)會(huì) 逐個(gè)比較字符串中每一個(gè)字符,而對(duì)于數(shù)字型而言只需要比較一次就夠了。
③查詢數(shù)據(jù)量大的表 會(huì)造成查詢緩慢。主要的原因是掃描行數(shù)過多。這個(gè)時(shí)候可以通過程序,分段分頁進(jìn)行查詢,循環(huán)遍歷,將結(jié)果合并處理進(jìn)行展示。
SELECT?*?FROM?(SELECT?ROW_NUMBER()?OVER(ORDER?BY?ID?ASC)?AS?rowid,*?
???FROM?infoTab)t?WHERE?t.rowid?>?100000?AND?t.rowid?<=?100050
作者:_陳哈哈
出處:https://sohu.gg/FGG98i