
Simnet | 神經(jīng)網(wǎng)絡(luò)語義匹配技術(shù)
寫在最前面:分享下 simnet 模型,可用于搜索中 query-title 匹配,也可用在推薦中基于 query 語義進(jìn)行相關(guān)召回。雖然 13 年就有了,但還是很經(jīng)典。
一、序言
文本匹配是自然語言處理中一個(gè)重要的基礎(chǔ)問題,自然語言處理中的許多任務(wù)都可以抽象為文本匹配任務(wù)。例如網(wǎng)頁搜索可抽象為網(wǎng)頁同用戶搜索 Query 的一個(gè)相關(guān)性匹配問題,自動(dòng)問答可抽象為候選答案與問題的滿足度匹配問題,文本去重可以抽象為文本與文本的相似度匹配問題。
傳統(tǒng)的文本匹配技術(shù)如信息檢索中的向量空間模型 VSM、BM25 等算法,主要解決詞匯層面的匹配問題,或者說詞匯層面的相似度問題。而實(shí)際上,基于詞匯重合度的匹配算法有很大的局限性,原因包括:
1)語言的多義同義問題
相同的詞在不同語境下,可以表達(dá)不同的語義,例如「蘋果」既表示水果,也表示一家科技公司。同理,相同的語義也可由不同的詞表達(dá),例如「的士」、「taxi」都表示出租車。
2)語言的組合結(jié)構(gòu)問題
相同的詞組成的短語或句子,不同的語序可表達(dá)不同的語義,例如「深度學(xué)習(xí)」和「學(xué)習(xí)深度」。更進(jìn)一步,還存在句法結(jié)構(gòu)問題,例如「從北京到上海高鐵」和「從上海到北京高鐵「雖然含有的詞語完全相同,但其語義完全不同。而「北京隊(duì)打敗了廣東隊(duì)」和「廣東隊(duì)被北京隊(duì)打敗了」又語義完全相同。
3)匹配的非對稱問題
文本匹配類的任務(wù),并不單單是文本相似度問題。一方面不一定要求語言上的相似,例如網(wǎng)頁搜索任務(wù)中 query 端的語言表述形式和網(wǎng)頁端往往具有很大的差別,至少在長度上就差距很大。另一方面也不一定要求語義上的相同,例如問答任務(wù)中,待匹配的兩段文本并不要求同義,而是看候選答案是否真正回答了問題。
這表明,對文本匹配任務(wù),不能只停留在字面匹配層面,更需要語義層面的匹配,不僅是相似度匹配,還包括更廣泛意義上的匹配。
針對前述問題,有各種改進(jìn)工作。比如基于統(tǒng)計(jì)機(jī)器翻譯方法,挖掘同義詞或同義片段來解決 mismatch 問題;從語義緊密度、詞語間隔等度量出發(fā)來規(guī)避結(jié)構(gòu)轉(zhuǎn)義問題;從對網(wǎng)頁打關(guān)鍵詞標(biāo)簽、點(diǎn)擊關(guān)聯(lián)計(jì)算等來一定程度解決非對稱匹配問題等。這些方法,都有一定效果,但整體上造成策略邏輯非常復(fù)雜,還是沒有完全解決具體任務(wù)下語義層面的匹配問題。
而語義層面的匹配,首先面臨語義如何表示、如何計(jì)算問題。
上世紀(jì) 90 年代流行起來的潛在語義分析技術(shù)(Latent Semantic Analysis,LSA),開辟了一個(gè)新思路,將詞句映射到等長的低維連續(xù)空間,可在此隱式的「潛在語義」空間上進(jìn)行相似度計(jì)算。此后又有 PLSA(Probabilistic Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)等更高級的概率模型被設(shè)計(jì)出來,逐漸形成非常火熱的主題模型技術(shù)方向。這些技術(shù)對文本的語義表示形式簡潔、運(yùn)算方便,較好的彌補(bǔ)了傳統(tǒng)詞匯匹配方法的不足。不過從效果上來看,這些技術(shù)都無法替代字面匹配技術(shù),只能作為字面匹配的有效補(bǔ)充。
深度學(xué)習(xí)技術(shù)興起后,基于神經(jīng)網(wǎng)絡(luò)訓(xùn)練出的 Word Embedding 來進(jìn)行文本匹配計(jì)算引起了廣泛的興趣。Word Embedding 的訓(xùn)練方式更加簡潔,而且所得的詞語向量表示的語義可計(jì)算性進(jìn)一步加強(qiáng)。但是,只利用無標(biāo)注數(shù)據(jù)訓(xùn)練得到的 Word Embedding 在匹配度計(jì)算的實(shí)用效果上和主題模型技術(shù)相差不大,它們本質(zhì)上都是基于共現(xiàn)信息的訓(xùn)練。另外,Word Embedding 本身沒有解決短語、句子的語義表示問題,也沒有解決匹配的非對稱性問題。
我們于 2013 年設(shè)計(jì)研發(fā)了一種有監(jiān)督的神經(jīng)網(wǎng)絡(luò)語義匹配模型 SimNet,大幅度提升了語義匹配計(jì)算的效果。SimNet 在語義表示上沿襲了隱式連續(xù)向量表示的方式,但對語義匹配問題在深度學(xué)習(xí)框架下進(jìn)行了 End-to-End 的建模,將詞語的 Embedding 表示與句篇的語義表示、語義的向量表示與匹配度計(jì)算、文本對的匹配度計(jì)算與 pair-wise 的有監(jiān)督學(xué)習(xí)全部統(tǒng)一在一個(gè)整體框架內(nèi)。在實(shí)際應(yīng)用場景下,海量的用戶點(diǎn)擊行為數(shù)據(jù)可以轉(zhuǎn)化大規(guī)模的弱標(biāo)記數(shù)據(jù),搭配我們研發(fā)的高效并行訓(xùn)練算法,大數(shù)據(jù)訓(xùn)練的 SimNet 顯著超越了主題模型類算法的效果,并首次實(shí)現(xiàn)了可完全取代基于字面匹配的策略,而且可以直接建模非相似度類的匹配問題。在網(wǎng)頁搜索任務(wù)上的初次使用即展現(xiàn)出極大威力,帶來了相關(guān)性的明顯提升。
近年來,學(xué)術(shù)界相關(guān)的研究也逐漸增多。像 Microsoft Research 提出的 DSSM 模型(Deep Structured Semantic Model)即和 SimNet 初版在模型框架上非常類似,只是在訓(xùn)練手段上有所區(qū)別。華為 NOAH'S ARK LAB 也提出了一些新的神經(jīng)網(wǎng)絡(luò)匹配模型變體,如基于二維交互匹配的卷積匹配模型。中科院等研究機(jī)構(gòu)也提出了諸如多視角循環(huán)神經(jīng)網(wǎng)絡(luò)匹配模型(MV-LSTM)、基于矩陣匹配的的層次化匹配模型 MatchPyramid 等更加精致的神經(jīng)網(wǎng)絡(luò)文本匹配模型。
與此同時(shí),我們也在 SimNet 基礎(chǔ)上進(jìn)行了持續(xù)優(yōu)化改進(jìn),模型效果持續(xù)提升,適用場景不斷擴(kuò)大。除網(wǎng)頁搜索產(chǎn)品外,還成功應(yīng)用到了廣告、新聞推薦、機(jī)器翻譯、深度問答等多個(gè)產(chǎn)品線和應(yīng)用系統(tǒng)中,并取得了顯著效果。特別需要指出的是,與學(xué)術(shù)界的一些研究工作相比,我們除了模型算法本身的優(yōu)化改進(jìn)之外,還特別注重了深度學(xué)習(xí)模型與自然語言處理基礎(chǔ)技術(shù)的結(jié)合,尤其深入考慮了中文的語言特性,更多從實(shí)用性角度提升了神經(jīng)網(wǎng)絡(luò)語義匹配技術(shù)的應(yīng)用效果。
下面,首先整體介紹一下 SimNet 框架及模型算法變體,然后著重從文本特性出發(fā)和 NLP 方法更好結(jié)合的角度介紹一些改進(jìn)策略,最后談一下實(shí)際應(yīng)用中需要考量的一些因素。
二、SimNet 框架
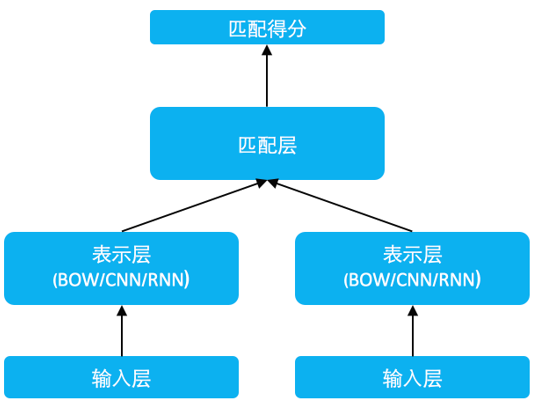
圖 1 SimNet 框架
SimNet 框架如上圖所示,主要分為輸入層、表示層和匹配層。
1.輸入層
該層通過 look up table 將文本詞序列轉(zhuǎn)換為 word embedding 序列。
2.表示層
該層主要功能是由詞到句的表示構(gòu)建,或者說將序列的孤立的詞語的 embedding 表示,轉(zhuǎn)換為具有全局信息的一個(gè)或多個(gè)低維稠密的語義向量。最簡單的是 Bag of Words(BOW)的累加方法,除此之外,我們還在 SimNet 框架下研發(fā)了對應(yīng)的序列卷積網(wǎng)絡(luò)(CNN)、循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)等多種表示技術(shù)。當(dāng)然,在得到句子的表示向量后,也可以繼續(xù)累加更多層全連接網(wǎng)絡(luò),進(jìn)一步提升表示效果。
3.匹配層
該層利用文本的表示向量進(jìn)行交互計(jì)算,根據(jù)應(yīng)用的場景不同,我們研發(fā)了兩種匹配算法。
1)Representation-based Match
該方式下,更側(cè)重對表示層的構(gòu)建,盡可能充分地將待匹配的兩端都轉(zhuǎn)換到等長的語義表示向量里。然后在兩端對應(yīng)的兩個(gè)語義表示向量基礎(chǔ)上,進(jìn)行匹配度計(jì)算,我們設(shè)計(jì)了兩種計(jì)算方法:一種是通過固定的度量函數(shù)計(jì)算,實(shí)際中最常用的就是 cosine 函數(shù),這種方式簡單高效,并且得分區(qū)間可控意義明確;還有就是將兩個(gè)向量再過一個(gè)多層感知器網(wǎng)絡(luò)(MLP),通過數(shù)據(jù)訓(xùn)練擬合出一個(gè)匹配度得分,這種方式更加靈活擬合能力更強(qiáng),但對訓(xùn)練的要求也更高。

2)Interaction-based Match
該方式更強(qiáng)調(diào)待匹配兩端更充分的交互,以及交互基礎(chǔ)上的匹配。所以不會(huì)在表示層將文本轉(zhuǎn)換成唯一的一個(gè)整體表示向量,而一般會(huì)保留和詞位置相對應(yīng)的一組表示向量。下面介紹該方式下我們實(shí)際應(yīng)用的一種的 SimNet 模型變體。首先基于表示層采用雙向 RNN 得到的文本中間位置表示,和詞位置對應(yīng)的每個(gè)向量體現(xiàn)了以本詞語為核心的一定的全局信息;然后對兩段文本按詞對應(yīng)交互,由此構(gòu)建兩段文本之間的 matching matrix(當(dāng)然也可以構(gòu)建多組 matrix,形成 tensor),這里面包括了更細(xì)致更局部的文本交互信息;基于該局部匹配特征矩陣,我們進(jìn)一步使用卷積來提取高級的從單詞到 N-Gram 多層次的匹配特征,再經(jīng)過 pooling 和 MLP 得到最終匹配得分。
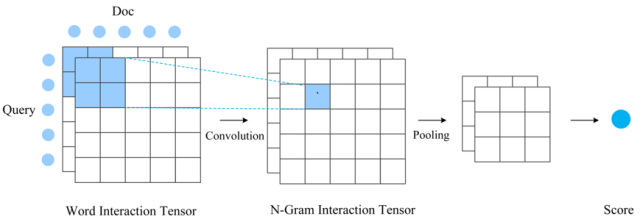
圖 4 Interaction-based match 方法
Interaction-based Match 匹配方法匹配建模更加細(xì)致、充分,一般來說效果更好一些,但計(jì)算成本會(huì)增加非常多,適合一些效果精度要求高但對計(jì)算性能要求不高的應(yīng)用場景。大部分場景下我們都會(huì)選擇更加簡潔高效的 Representation-based 匹配方式。
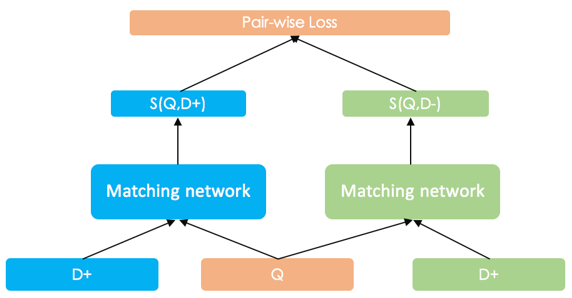
圖 5 Pair-wise 的 SimNet 訓(xùn)練框架
我們采用了 pair-wise Ranking Loss 來進(jìn)行 SimNet 的訓(xùn)練。以網(wǎng)頁搜索任務(wù)為例,假設(shè)搜索查詢文本為 Q,相關(guān)的一篇文檔為 D+,不相關(guān)的一篇文檔為 D-,二者經(jīng)過 SimNet 網(wǎng)絡(luò)得到的和 Q 的匹配度得分分別為 S(Q,D+) 和 S(Q,D-),而訓(xùn)練的優(yōu)化目標(biāo)就是使得 S(Q,D+)>S(Q,D-)。實(shí)際中,我們一般采用 Max-Margin 的 Hinge Loss:
max?{0,margin-(S(Q,D+)-S(Q,D-))}
這種 loss 簡潔、高效,還可以通過 margin 的不同設(shè)定,來調(diào)節(jié)模型得分的區(qū)分度。
三、文本任務(wù)下的特色改進(jìn)
SimNet 的匹配框架非常普適。特別是 Representation-based 模式,其實(shí)很早在圖像中就有類似應(yīng)用。九十年代即有利用 Siamese Networks 來進(jìn)行簽名真?zhèn)纹ヅ涞墓ぷ鳌5珜τ谖谋救蝿?wù)來講,語言的一些特殊性還是需要我們有一些更多針對性的考慮。
針對文本的一維序列的特性,在表示層需要有更針對性的建模。比如我們實(shí)現(xiàn)的一維序列卷積網(wǎng)絡(luò)和長短時(shí)記憶網(wǎng)絡(luò) LSTM,都充分考慮到了文本的特性。
此外,從輸入信號角度我們也充分考慮到文本的特點(diǎn)。SimNet 作為一種 End-to-End 的語義匹配框架,極大地降低了特征設(shè)計(jì)的代價(jià),直接輸入文本的詞序列即可。但對中文而言,由于基本語言單位是字,所以仍需要切詞這個(gè)步驟,但切詞本身就是個(gè)難題,而且詞語的粒度本身也沒有嚴(yán)格的定義,所以 SimNet 框架下需要降低對精準(zhǔn)切詞的依賴,或者說要考慮如何從切詞角度來進(jìn)一步提升匹配效果。另一方面,雖然不再需要進(jìn)一步的復(fù)雜的特征設(shè)計(jì),但一些基本的 NLP 技術(shù)的產(chǎn)出,如高頻共現(xiàn)片段和句法結(jié)構(gòu)信息,能否作為先驗(yàn)知識(shí)融入 SimNet 框架發(fā)揮作用,也是值得探索的方向。
1. 中文字粒度匹配和多切分粒度融合
我們首先驗(yàn)證了字粒度的匹配。由于中文字的數(shù)量遠(yuǎn)小于詞的數(shù)量(可達(dá)百萬量級),即使將 embedding 的維度適當(dāng)擴(kuò)充,整個(gè)模型的大小也會(huì)大大降低。我們在 SimNet-RNN 模式下,經(jīng)過精致設(shè)計(jì),字粒度輸入是可以比較接近詞粒度下的匹配效果的。當(dāng)然在大部分 SimNet 變體下,字粒度較詞粒度效果上有一定的差距,但是差距并不太大。這就使得,在一些內(nèi)存緊張或者沒有切詞模塊的場景下,可以直接使用字粒度模型,也可以達(dá)到較好的效果。
此外,我們還發(fā)現(xiàn)字粒度下有很好的泛化性,能很好的彌補(bǔ)詞粒度輸入的不足,如切詞的錯(cuò)誤和未登錄詞 OOV 問題。這也提示我們可以將字粒度和詞粒度進(jìn)行融合互補(bǔ)。另一方面,由于切詞自身不存在唯一客觀標(biāo)準(zhǔn),實(shí)際上不同的切分方式也可以實(shí)現(xiàn)互補(bǔ),比如可以同時(shí)使用大粒度切詞和細(xì)粒度切詞。這樣一來,我們對單一切詞的精度要求就可以不那么高了。這也從某種意義上降低了語義匹配任務(wù)對切詞的高度依賴。
從最終結(jié)果上來看,多切分粒度的融合帶來了實(shí)際應(yīng)用中的顯著效果提升。但是,多切分粒度如何融合,并沒有一個(gè)唯一模式。在 SimNet 框架下,多切分粒度融合在輸入層、表示層和匹配層都可以設(shè)計(jì)實(shí)現(xiàn)。
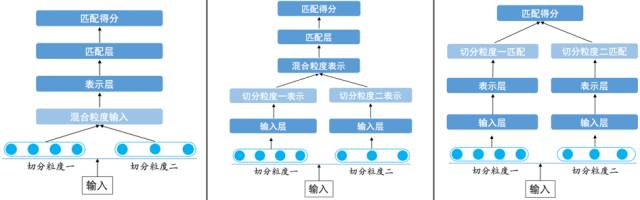
圖 6 多切分粒度在 SimNet 框架下融合方式
輸入層的融合要考慮到表示層網(wǎng)絡(luò)的特點(diǎn)。對于 BOW 這種無序的表示結(jié)構(gòu),我們可以把多種切分粒度直接當(dāng)輸入灌入模型。而對于 CNN/RNN 這些有序的表示結(jié)構(gòu),輸入層的融合則需要一些「技巧」,比如說需要考慮粒度在字層面對齊的問題。
表示層的融合會(huì)更加靈活方便些。神經(jīng)網(wǎng)絡(luò)有非常多有效的方式能把多個(gè)定長向量融合為一個(gè),簡單的如拼接或者逐位相加,復(fù)雜的也可以加入 Gate 機(jī)制。那么,我們可以容易地把多切分粒度生成的多表示向量進(jìn)行融合,再通過融合后的語義表示層得到最終的匹配相似度。
匹配層的融合可以用最簡單直觀的方式實(shí)現(xiàn),即不同表示粒度的匹配得分上做加權(quán)和。這樣有些像不同粒度的匹配模型的 Ensemble,區(qū)別是這里所有粒度是同時(shí)訓(xùn)練的。此種模式下參數(shù)量和計(jì)算量也是最大的。
經(jīng)驗(yàn)表明,越早進(jìn)行粒度融合,最終的效果會(huì)越好。這也應(yīng)該是因?yàn)槭沟昧6戎g的互補(bǔ)性能更早更充分地發(fā)揮作用。
2. 高頻 Bigram 和 Collocation 片段引入
比基本切詞更大的短語片段粒度會(huì)不會(huì)進(jìn)一步提升效果?理論上越大的文本片段,表義越精確,但也越稀疏。詞語粒度下的詞表已可達(dá)百萬量級,再增加更大片段壓力太大,而且還會(huì)面臨訓(xùn)練不充分問題。我們設(shè)計(jì)了一種巧妙的統(tǒng)計(jì)量度量方式,基于大數(shù)據(jù)只挑選少量對匹配任務(wù)有很好信息量的高頻共現(xiàn) Term 組合,作為 Bigram 詞加入字典,進(jìn)一步顯著提升了模型效果。
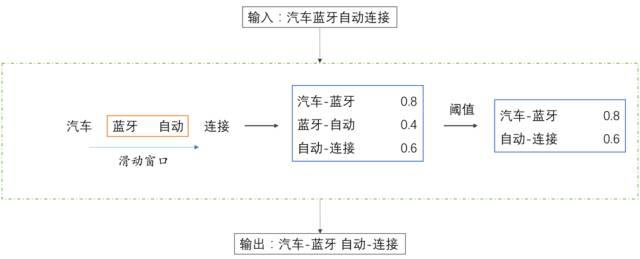
舉個(gè)例子,我們輸入語料「汽車藍(lán)牙自動(dòng)連接」,利用基本分詞工具,可以把序列分割為「汽車 藍(lán)牙 自動(dòng) 連接」四個(gè) Term。此時(shí),我們依據(jù)大數(shù)據(jù)下的統(tǒng)計(jì)分析,可以發(fā)現(xiàn)「汽車-藍(lán)牙」的統(tǒng)計(jì)量得分最高,「自動(dòng)-連接」次之,「藍(lán)牙-自動(dòng)」最小,那么依照設(shè)定的統(tǒng)計(jì)量閾值,我們就得到了基于 Bigram 粒度的輸出。
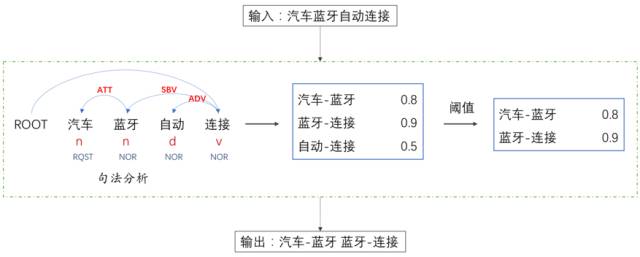
以上方式比較適合于連續(xù) Term 共現(xiàn)組合,而對文本語義來講,有時(shí)候一些跨詞的 Collocation 搭配也非常重要。我們使用依存句法分析工具來獲得相應(yīng)的 Collocation 片段。還是上面的例子,輸入語料「汽車藍(lán)牙自動(dòng)連接」。此時(shí),我們對輸入語料構(gòu)建依存分析樹,統(tǒng)計(jì)父節(jié)點(diǎn)和子節(jié)點(diǎn)共現(xiàn)頻率,最終認(rèn)為「藍(lán)牙-連接」顯得比「自動(dòng)-連接」重要,因此最終輸出就成了「汽車-藍(lán)牙 藍(lán)牙-連接」。
不論是 Bigram 還是 Collocation,都相當(dāng)于使用 NLP 基礎(chǔ)技術(shù),用簡潔地方式引入了一些先驗(yàn)信息到模型里面,降低了模型學(xué)習(xí)的難度,在很多場景下都較明顯地提升了語義匹配的效果。
以上探索表明,針對文本任務(wù)的特點(diǎn)、語言本身特色,我們除了從神經(jīng)網(wǎng)絡(luò)模型更好地設(shè)計(jì)選型之外,也可以將一些基礎(chǔ) NLP 分析技術(shù)更好地和模型融合,以更高效地獲取更好的效果。
四、實(shí)際應(yīng)用中的考量因素
在實(shí)際應(yīng)用中,除了模型算法之外,還有很多因素會(huì)對最終效果產(chǎn)生很大的影響。其中最重要的就是數(shù)據(jù),還有就是應(yīng)用場景的特點(diǎn)。
對深度學(xué)習(xí)模型來講,數(shù)據(jù)的規(guī)模是非常關(guān)鍵的。在網(wǎng)頁搜索應(yīng)用上的成功,有個(gè)很重要的因素就是有海量的用戶點(diǎn)擊數(shù)據(jù)。但是光有數(shù)量還不夠,還要看數(shù)據(jù)如何篩選,正例負(fù)例如何設(shè)定,特別是負(fù)例如何選擇的問題。例如在網(wǎng)頁搜索應(yīng)用中,如果不考慮頻次問題,可能訓(xùn)練數(shù)據(jù)的絕大部分構(gòu)成都是高頻 Query 數(shù)據(jù),但高頻 Query 的搜索效果一般是比較好的了。另外,有的 Query 有點(diǎn)擊的網(wǎng)頁很多,有的很少,能組成的正負(fù) pair 數(shù)差別會(huì)很大,這時(shí)候如何處理?而對于負(fù)例,數(shù)量和質(zhì)量上還應(yīng)該考慮哪些因素?這些問題都至關(guān)重要,不同的數(shù)據(jù)設(shè)計(jì)方式會(huì)極大地影響最后效果。
應(yīng)用場景同樣很重要。比如最終匹配度得分就是最終的結(jié)果,還是作為下一層模型的特征輸入?如果作為下一層輸入的話,對得分的可比性有沒有要求?最終的任務(wù)是分類還是排序,是排序的話排序的優(yōu)化目標(biāo)和訓(xùn)練中的優(yōu)化目標(biāo)如何可以做的更一致?這其中有一些會(huì)影響到對數(shù)據(jù)的組織方式,有一些需要針對性的對一些模型超參數(shù)做調(diào)整。例如前文 loss 中 margin 的具體設(shè)定,會(huì)影響到準(zhǔn)確率指標(biāo)和得分區(qū)分性之間的一些折中變化。
當(dāng)然,訓(xùn)練中諸如學(xué)習(xí)率等因素對任務(wù)成敗也有很大影響,但這些設(shè)定和調(diào)整的難易也取決于具體的訓(xùn)練程序和平臺(tái)。