
Flink Table Store 入湖 | 基于 Apache Flink Table Store 的全增量一體實時入湖
摘要:本文簡要回顧數據入湖(倉)的發(fā)展階段,針對在數據庫數據入湖中面臨的問題,提出了使用 Flink Table Store 作為全增量一體入湖的解決方案,并輔以開源 Demo 的測試結果作為展示。文章主要內容包括:
數據庫數據集成入湖(倉)的發(fā)展階段及面臨痛點
基于 Apache Flink Table Store 解決全增量一體入湖
總結與展望
數據入湖(倉)發(fā)展階段及面臨痛點
基于數據庫的數據集成過程,簡要來說經歷了如下幾個階段。
1.1 全量 + 定期增量的數據入倉
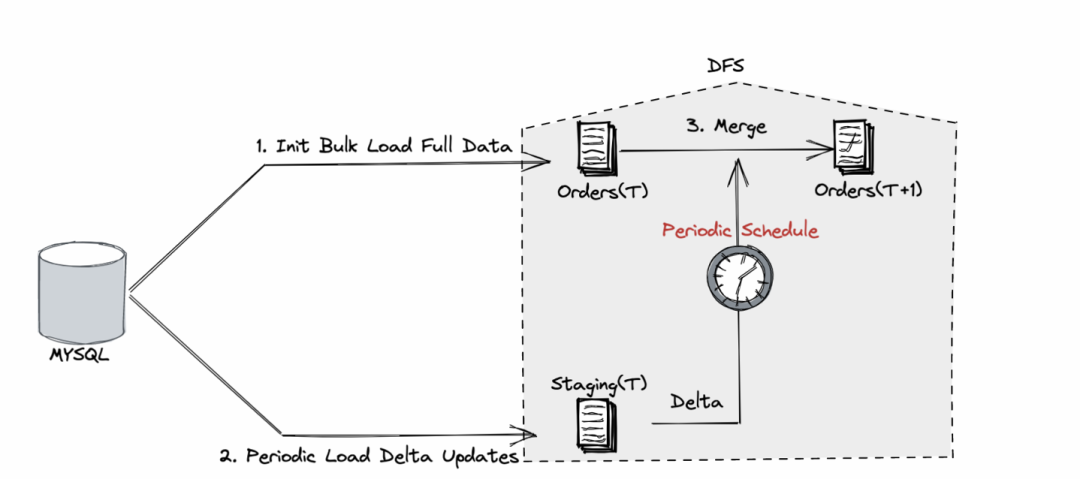
?? 鏈路復雜,時效性差
?? 明細查詢慢,排查問題難
雖然下游會使用各種交互式分析引擎來加速查詢,但基于成本考慮,底表明細數據一般沒有這種待遇,這就導致在數據正確性排查時需要直接查詢明細,特別是需要查詢合并前后全量和增量的明細變化來定位問題。如果業(yè)務變更,導致一批訂單數據需要訂正并要求生成訂正之后的各類指標,則需要手工對原始表及其下游依賴表進行級聯訂正。
1.2 全量 + 實時增量的數據入湖
相對于傳統(tǒng)數據倉庫,數據湖的出現使得數據在以低成本存儲的同時,數據新鮮度有了極大的提升。以 Apache Hudi 為例,它支持先做一次全量 bootstrap 構建基礎表,然后基于新接入的 CDC 數據進行實時構建 [1],如 Fig.2 所示。
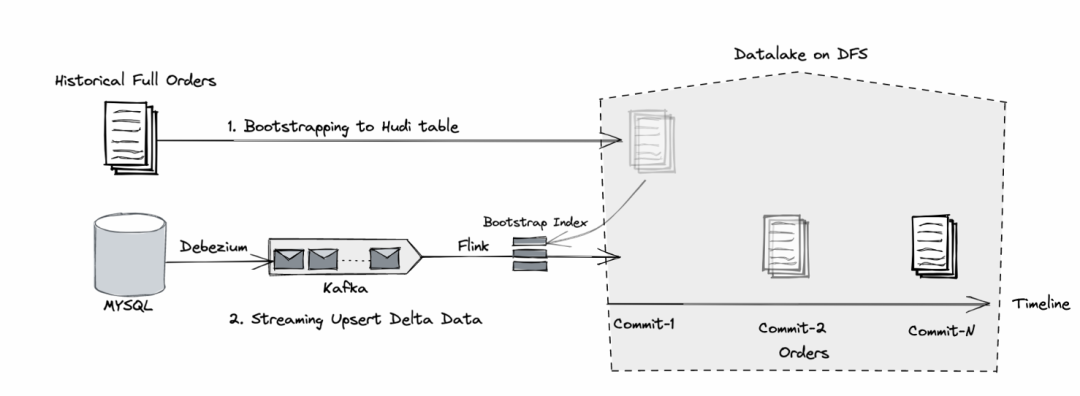
Fig.2 數據入湖: 一次全量+實時增量
由于支持記錄級別的更新及刪除,在存儲側就可以完成主鍵的去重,不再需要額外的合并任務。在數據新鮮度方面,由于流式作業(yè)會定期的觸發(fā) checkpoint 來產生全量與增量合并后的快照,故而數據新鮮度對比第一種方式(以天或小時調度產生合并快照)有了很大提升。
但從另外一方面,我們也發(fā)現這種方式有以下這些問題。
?? Bootstrap Index 超時及 state 膨脹
以流模式啟動 Flink 增量同步作業(yè)后,系統(tǒng)會先將全量表導入到 Flink state 來構建 Hoodie key(即主鍵 + 分區(qū)路徑)到寫入文件的 file group 的索引,此過程會阻塞 checkpoint 完成。而只有在 checkpoint 成功后,寫入的數據才可以變?yōu)榭勺x狀態(tài),故而當全量數據很大時,有可能會出現 checkpoint 一直超時的情況,導致下游讀不到數據。另外,由于索引一直保存在 state 內,在增量同步階段遇到了 insert 類型的記錄也會更新索引,需要合理評估 state TTL,配置太小可能會丟失數據,配置過大可能導致 state 膨脹。
?? 鏈路依然復雜,難以對齊增量點位,自動化運維成本高
此外,我們回顧了一些使用 Hudi 的行業(yè)實踐,發(fā)現用戶需要格外注意各項配置來實現不同需求,這對易用性有一定的傷害。比如 [1] 中提到的需要在平臺層面監(jiān)控用戶的建表語句,防止在大規(guī)模寫入場景配置為 COW(Copy on Write) 模式;全增量切換時用戶必須格外注意 Kafka 消費點位來保證數據準確性,參數配置極大影響了作業(yè)的數據準確性及性能。
基于 Apache Flink Table Store 的全增量一體入湖
隨著基于日志的 CDC 逐步取代基于查詢的 CDC,特別是 Flink SQL CDC 在 source 端已支持全增量一體同步后,全增量一體入湖(使用一個流作業(yè)完成全量同步、并持續(xù)監(jiān)聽增量 changelog)也成為一個新的探索方向。這種方式降低了鏈路復雜度,同時將全增量切換時需要手工對齊 offset 的繁瑣托管給了 Flink CDC 和 checkpoint 機制,讓框架層面去保障數據的最終一致性。但經過調研我們發(fā)現,在使用 Hudi 做這種嘗試時遇到了以下挑戰(zhàn)。
?? 全量同步階段數據亂序嚴重,寫入性能和穩(wěn)定性難以保障
在全量同步階段面臨的一個問題是多并發(fā)同時讀取 chunk 會遇到嚴重的數據亂序,出現同時寫多個分區(qū)的情況,大量的隨機寫入會導致性能回退,出現吞吐毛刺,每個分區(qū)對應的 writer 都要維護各自緩存,很容易發(fā)生 OOM 導致作業(yè)不穩(wěn)定。雖然 Hudi 支持通過 Rate Limit [3] 限制每分鐘的數據寫入來起到一定的平滑效果,但在作業(yè)穩(wěn)定性和性能吞吐之間取得平衡的調優(yōu)過程對于一般用戶來說門檻也較高。
2.1 為什么選擇 Flink Table Store
Apache Table Store [4] 作為 2022 年初開源的 Apache Flink 子項目,目標是打造一個支持更新的據湖存儲,用于實時流式 Changelog 攝取和高性能查詢。
?? 大吞吐量的更新數據攝取,支持全增量一體入湖,一個 Flink 作業(yè)搞定所有
-- 創(chuàng)建并使用 table store catalogCREATE CATALOG `table_store` WITH ('type' = 'table-store','warehouse' = 'hdfs://foo/bar');USE CATALOG `table_store`;-- 定義 mysql-cdc source 表CREATE TEMPORARY TABLE `orders_cdc` (order_id BIGINT NOT NULL,gmt_modified TIMESTAMP(3) NOT NULL,...PRIMARY KEY (`order_id`) NOT ENFORCED) WITH ('connector' = 'mysql-cdc',...);-- 定義 table store ods 表,按日期作分區(qū)CREATE TABLE IF NOT EXISTS `orders` (...PRIMARY KEY (`dt`, `order_id`) NOT ENFORCED) PARTITIONED BY (`dt`);-- streaming 模式下提交作業(yè)SET 'execution.runtime-mode' = 'streaming';-- 設置 1min 的 cp interval,對應 1min 的數據新鮮度SET 'execution.checkpointing.interval' = '1min';-- 一條 SQL 同步全量 + 增量,動態(tài)分區(qū)寫入INSERT INTO `orders`SELECT ..., DATE_FORMAT(gmt_modified, 'yyyy-MM-dd') AS dtFROM `orders_cdc`;
Fig.4 展示了以 dt 作為分區(qū) orders 表的存儲結構,在用戶指定總 bucket 數 N 后,每個分區(qū)下會生成相應的 bucket-${n} 目錄,每個目錄下以列存格式(orc 或 parquet)存放 hash_func(pk) % N == ${n} 的記錄文件。
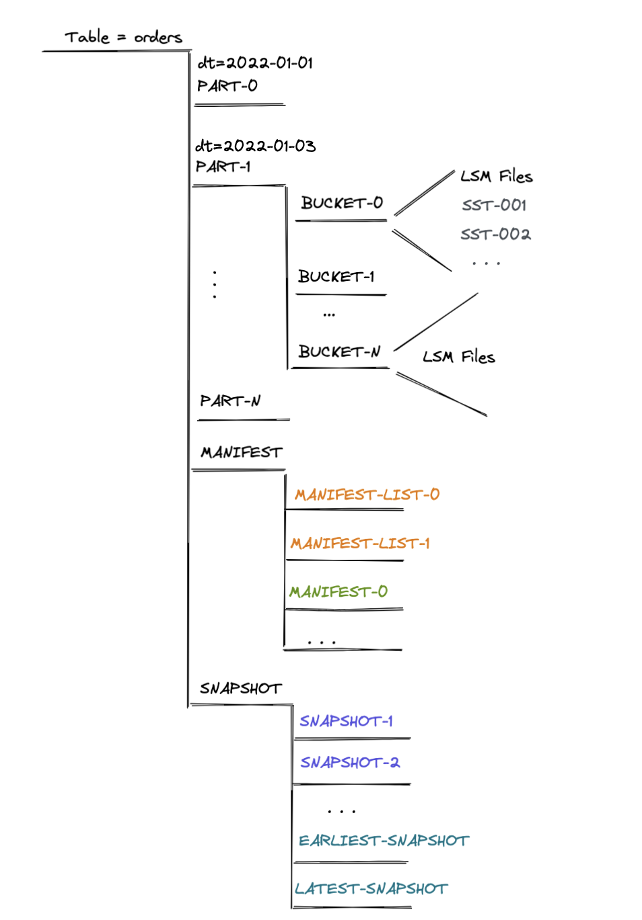
Fig.4 Flink Table Store 表的文件目錄
元數據與數據存儲在表的同一級目錄下,包括 manifest 目錄和 snapshot 目錄。
manifest 目錄下中記錄每次經 checkpoint 觸發(fā)而提交的數據文件變更,包含新增和刪除的數據文件 snapshot 目錄下記錄每次提交產生的 snapshot 文件,內容包括為上一次提交產生的 manifest,加上本次提交產生的 manifest 作為增量
生成當前 table 的一個快照(snapshot)。系統(tǒng)會通過 snapshot pointer file(類似于指針)追蹤最早產生和當前最新的 snapshot 文件
snapshot 文件中包含本次 commit 新增哪些 manifest 文件、刪除哪些 manifest 文件
每個 manifest 文件中記錄了產生了哪些 sst 文件、刪除了哪些 sst 文件,以及每個 sst 文件所包含記錄的主鍵范圍、每個字段的 min/max/null count 等統(tǒng)計信息
每個 sst 文件則包含了按主鍵排好序的、列存格式的記錄。對于 Level 0 的文件,Table Store 會異步地觸發(fā) compact 合并線程來消除主鍵范圍重疊帶來的讀端 merge 開銷
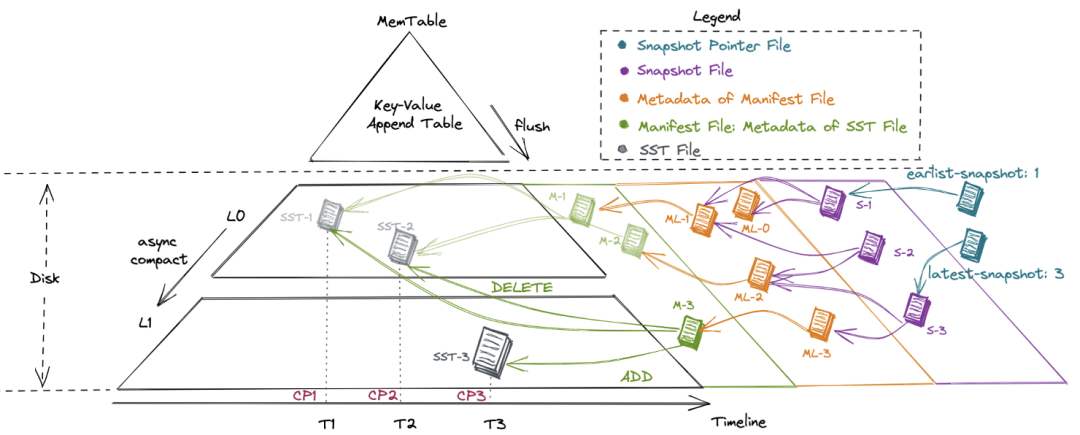
Fig.5 Flink Table Store 表的 LSM 實現
?? 高效 Data Skipping 支持過濾,提供高性能的點查和范圍查詢
雖然沒有額外的索引,但是得益于 meta 的管理和列存格式,manifest 中保存了
文件的主鍵的 min/max 及每個字段的統(tǒng)計信息,這可以在不訪問文件的情況下,進行一些 predicate 的過濾 orc/parquet 格式中,文件的尾部記錄了稀疏索引,每個 chunk 的統(tǒng)計信息和 offset,這可以通過文件的尾部信息,進行一些 predicate 的過濾
讀取 manifest:根據文件的 min/max、分區(qū),執(zhí)行分區(qū)和字段的 predicate,淘汰多余的文件 讀取文件 footer:根據 chunk 的 min/max,過濾不需要讀取的 chunk 讀取剩下與文件以及其中的 chunks
SELECT * FROM orders WHERE dt = '2022-01-01' AND order_id >= 100 AND order_id <= 200;我們同樣基于上述數據集測試了 Flink Table Store 的查詢性能[9],在點查和范圍查詢的場景下,Flink Table Store 表現出眾。從實現原理來說,MOR 的查詢性能低于 COW、COW 的寫入性能低于 MOR 是難以避免的。而在實踐層面,在大規(guī)模寫入場景下建立的 MOR 表也很難一鍵轉換為 COW 來讀取,所以在查詢寫入較多的表(MOR 表)這個前提下,Flink Table Store 的查詢表現還是不俗的。
?? 文件格式支持流讀
-- 進入 SQL CLI,創(chuàng)建 catalog 和 tableCREATE CATALOG table_store WITH ('type' = 'table-store','warehouse' = 'file://foo/bar/' --或 'hdfs://foo/bar');CREATE TABLE IF NOT EXIST my_table (f0 INT,f1 STRING,PRIMARY KEY(f0) NOT ENFORCED);-- 切換到 batch 模式,寫入數據SET 'execution.runtime-mode' = 'batch';INSERT INTO my_table VALUES(1, 'Hello');-- 新打開一個 SQL CLI 中,切換到 streaming 模式,提交流式查詢SET 'execution.runtime-mode' = 'streaming';SET 'sql-client.execution.result-mode' = 'tableau';SELECT * FROM my_table;-- 可以讀到結果如下+----+-------------+--------------------------------+| op | f0 | f1 |+----+-------------+--------------------------------+| +I | 1 | Hello |-- 在第一個 SQL CLI 中,繼續(xù)寫入數據INSERT INTO my_table VALUES(1, 'Bye'), (2, '你好');-- 可以在第二個 SQL CLI 中,觀察到新增輸出 (-U, 1, Hello),(+U, 1, Bye) 和 (+I, 2, 你好)+----+-------------+--------------------------------+| op | f0 | f1 |+----+-------------+--------------------------------+| +I | 1 | Hello || -U | 1 | Hello || +U | 1 | Bye || +I | 2 | 你好 |
2.2 基于 TPC-H 數據集的全增量一體入湖 Demo
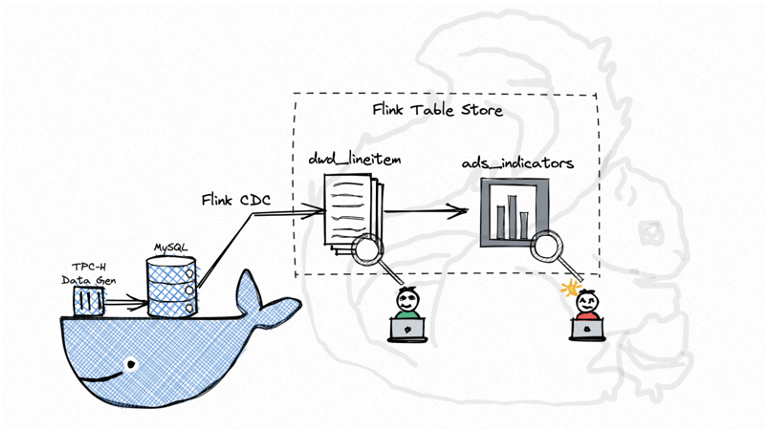
前文對 Flink Table Store 解決全增量一體入湖進行了簡要分析,下面一個實例演示了如何在本地單機環(huán)境下,將近六千萬條訂單記錄作為全量數據從 MySQL 同步到 Flink Table Store,并持續(xù)消費增量更新(由 TPC-H RF1 和 RF2 產生),下游接實時聚合及查詢的過程。
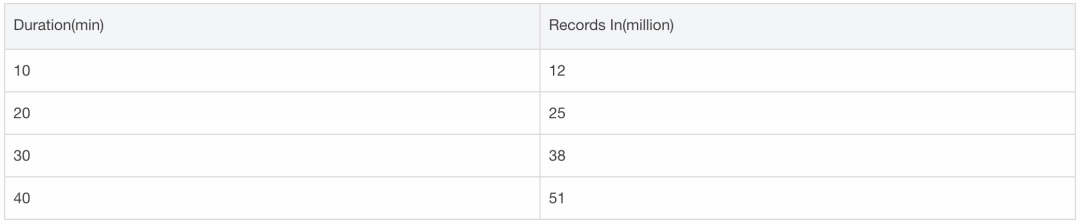
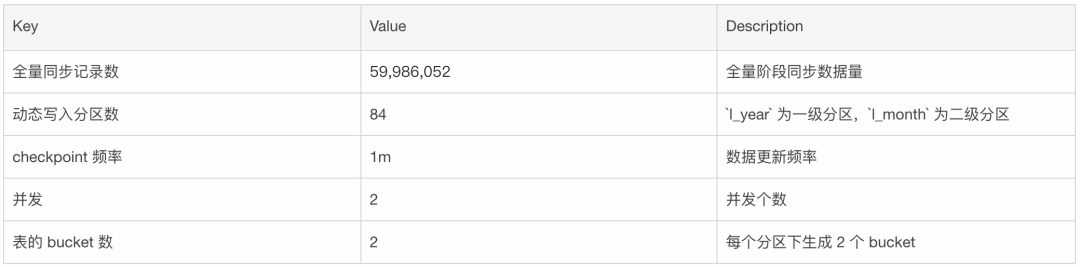
總結與展望
[1] 基于 Hudi 的湖倉一體技術在 Shopee 的實踐
https://mp.weixin.qq.com/s/3nsYTVu9nZCIFaaXP09hiQ
▼ 關注「Apache Flink」,獲取更多技術干貨 ▼