
一份完整的數(shù)據(jù)科學(xué)競賽指南!
如今,數(shù)據(jù)科學(xué)競賽(大數(shù)據(jù)競賽,機器學(xué)習(xí)競賽,人工智能算法競賽)已經(jīng)成為各大知名互聯(lián)網(wǎng)企業(yè)征集解決方案和選拔人才的第一選擇,很多同學(xué)為了拿到大廠offer,紛紛加入了數(shù)據(jù)競賽的浪潮之中。遺憾的是,大部分同學(xué)都在激烈的競爭中成為炮灰,許多人不停地上網(wǎng)瀏覽各類競賽開源分享,卻依舊感到困惑迷茫。
在過去幾年時間內(nèi),筆者靠著個人天賦和不懈努力,從0到1地走通了數(shù)據(jù)科學(xué)競賽方法論,培養(yǎng)了一直數(shù)據(jù)科學(xué)競賽的團隊,并作為隊長率多名選手參與了近20次數(shù)據(jù)科學(xué)競賽,獲得前5名5次,前10名8次,賽題方向包括金融、交通、信息安全、廣告推薦、運籌優(yōu)化等。考慮到近幾年在數(shù)據(jù)科學(xué)競賽里取得的豐厚的成果,我將自己的獨門秘笈進行了詳細(xì)總結(jié)并開源之,希望可以幫助更多同學(xué)快速上手相關(guān)比賽。
我認(rèn)為這份競賽秘笈與市面上流傳的各種競賽分享相比,更real,更direct,更cunning。如果你想快速成為競賽高手,這份文檔是你必須要認(rèn)真研究的參考資料。
下面,我將從三個方面來詳細(xì)介紹數(shù)據(jù)科學(xué)競賽,然后在結(jié)尾處談一點個人的感悟。建議不熟悉機器學(xué)習(xí)建模套路的同學(xué)先搞清楚流程,熟悉建模套路的同學(xué),直接看經(jīng)驗干貨即可。

一、數(shù)據(jù)科學(xué)家競賽是什么?
二、為什么要做數(shù)據(jù)科學(xué)競賽?
三、怎樣做數(shù)據(jù)科學(xué)競賽?
3.1 武器庫
3.2 賽題分析
3.3 數(shù)據(jù)探索
3.3.1 數(shù)據(jù)整體認(rèn)知
3.3.2 數(shù)據(jù)質(zhì)量分析
3.3.3 數(shù)據(jù)統(tǒng)計量分析
3.3.4 數(shù)據(jù)分布分析
3.3.5 數(shù)據(jù)探索小結(jié)
3.4 特征工程
3.4.1 數(shù)據(jù)預(yù)處理
3.4.2 特征構(gòu)造
3.4.2.1 思想方法
3.4.2.2 特征構(gòu)造舉例
3.4.2.3 特征構(gòu)造 注意事項
3.4.3 特征選擇
3.4.4 特征工程總結(jié)
3.5 模型選擇
3.6 模型優(yōu)化
3.6.1 評估方法
3.6.2 性能度量
3.6.3 參數(shù)調(diào)整
3.7 模型融合
3.8 迭代策略
3.9 其他
四、總結(jié)
數(shù)據(jù)科學(xué)競賽是由企業(yè)或者研究機構(gòu)通過競賽平臺發(fā)布商業(yè)和科研難題,通過高額獎金的懸賞,吸引全球的數(shù)據(jù)科學(xué)家參與,利用眾包方式解決建模問題的一種游戲。這個游戲本質(zhì)上就是一種打擂臺的玩法,符合各種有限游戲的規(guī)則設(shè)計,不過你同時要與成百上千的人PK。
數(shù)據(jù)科學(xué)競賽一般通過各類數(shù)據(jù)競賽平臺進行發(fā)布,最著名的數(shù)據(jù)科學(xué)競賽平臺是Kaggle和天池,Kaggle的背后是Google,天池的背后是阿里巴巴。當(dāng)然,還有很多公司自己組織的比賽和頂級學(xué)術(shù)會議籌辦的比賽。如果你想做比賽的話,去下面這些平臺上尋找適合自己的比賽即可:
Kaggle,天池
京東智匯平臺,DataFountain,DataCastle,科賽網(wǎng),創(chuàng)新工場AIChallenger等
騰訊,滴滴出行,第四范式,中國平安,融360,中國農(nóng)業(yè)銀行等
SIGKDD,ICDM,CIKM,IJCAI等
第一,讓你100%清楚哪些算法在實際應(yīng)用中更有效。解釋一下,這里的“有效”包括算法的性能和效率。現(xiàn)在很多人往往是看過了周志華的西瓜書,就覺得自己懂機器學(xué)習(xí)了,這是很可笑的。最典型的例子就是很多人覺得SVM是最好用的分類器。包括很多發(fā)過會議論文的同學(xué),其實也是停留在理論的烏托邦,而且論文的results部分有多real也很難判斷。做比賽你可以拿到工業(yè)界的數(shù)據(jù),而且這些數(shù)據(jù)都是頭部互聯(lián)網(wǎng)大廠的實際業(yè)務(wù)數(shù)據(jù),所以在實戰(zhàn)的過程中,我們可以逐漸井底之蛙蛻變?yōu)榘肯柙谔炜盏男埴棧芮宄刂滥男┧惴ê糜茫男┓椒孔V,哪些人在吹逼和忽悠。
第二,結(jié)識朋友,提升人脈。做比賽時如果你運氣比較好,可以和優(yōu)秀的同學(xué)組隊,當(dāng)然前提是你自己足夠牛逼。另外,如果你拿到了某個競賽top5或top10,你的team有可能被邀請去參加線下的答辯,這絕對是認(rèn)識技術(shù)大牛,提升人脈的好機會。比如筆者就去過像阿里云、京東、滴滴、馬上金融,中國平安、中國農(nóng)業(yè)銀行這樣的單位參與線下答辯,在緊張的答辯之余,利用吃吃喝喝的時間進行social,運氣好的話,你還能加到某些公司中高級管理者的微信。截止目前,國內(nèi)競賽圈一半以上的頭部大佬都是我的朋友,有些還在一起玩比賽、做課題。
第三,訓(xùn)練和提高自己快速寫代碼的能力。要知道每場比賽你要在短時間內(nèi)實現(xiàn)很多很多的idea,有時候一天之內(nèi)你要想出三到四個上分的辦法。這個過程講究的是速戰(zhàn)速決,不僅可以訓(xùn)練自己快速寫代碼和實現(xiàn)idea的能力,也可以很好地訓(xùn)練你的判斷力和決策能力。
第四,實習(xí)機會 & 高薪工作。像我之前就拿到過多家大廠的直通終面機會。統(tǒng)計了一下跟我做過比賽的學(xué)弟學(xué)妹的工作情況,目前大部分就職于知名國企和互聯(lián)網(wǎng)企業(yè),比如阿里、騰訊、京東、滴滴、美團、中國農(nóng)業(yè)銀行、中國交通建設(shè)股份有限公司、中國人壽資產(chǎn)管理有限公司、一汽大眾等等。
第五,獎金。一般的比賽都會有獎金,不給錢的比賽就別做了,那種比賽除了練手,沒有任何價值可言。錢是體現(xiàn)賽題困難程度的重要指標(biāo)。具體的錢數(shù),最少1萬起,多則稅前30萬到50萬。但悲哀的是,獎金一般人是拿不到的,因為任何一個圈子都是1%的人賺走了99%的利潤,小白們只能跟著長點見識,苦逼陪跑。
3.1 武器庫
俗話說,臺上一分鐘、臺下十年功。雖然參加數(shù)據(jù)科學(xué)競賽不需要十年的修煉,但還是需要一些基礎(chǔ)的知識技能作為支撐的,我講以下幾個方面。
基礎(chǔ)知識
數(shù)學(xué)基礎(chǔ):微積分、線性代數(shù)、概率論與數(shù)理統(tǒng)計、優(yōu)化理論
機器學(xué)習(xí)理論:周志華《機器學(xué)習(xí)》、李航《統(tǒng)計機器學(xué)習(xí)》、Ian Goodfellow和Youshua Bengo《Deep Learning》、Bishop的PRML
目前國內(nèi)大大小小的課程和博客都在講周志華的西瓜書和李航的書,但這里我想補充一點個人的看法:
我認(rèn)為我看過的最好的講傳統(tǒng)機器學(xué)習(xí)理論的書籍是K. P. Murphy的《Machine learning: A Probabilistic Perspective》,其次是Bishop的PRML
另外,臺大李宏毅老師的網(wǎng)課,真的是十分良心,建議大家去B站學(xué)習(xí)
Python:《Python基礎(chǔ)教程》《利用Python進行數(shù)據(jù)分析》《機器學(xué)習(xí)實戰(zhàn)》
文獻(xiàn)資料
Paper
主要關(guān)注CCF A里的頂級會議論文
arxiv要好好利用
Csdn、知乎、GitHub等開源知識分享平臺
Kaggle、天池里的各種kernel
軟件配置
開發(fā)環(huán)境
Anaconda
Jupyter Notebook
Pycharm
雖然Jupyter Notebook的交互性更好,但個人更喜歡用Pycharm
開源庫
數(shù)據(jù)處理包:Numpy Scipy Matplotlib Pandas等
機器學(xué)習(xí)包:Sklearn XGBoost LightGBM Keras TensorFlow Pytorch等
硬件配置
高性能PC:
強推Macbook Pro,資金不足的話可以自己搭Linux。這個時代Windows也可以了其實,但用起來總有些地方讓你不爽。
早年很多關(guān)鍵的包比如lightgbm不支持Windows,筆者也是畫了一兩個月的時間才熟悉了Linux,用熟了還是很順滑的
服務(wù)器
注:現(xiàn)在越來越多的比賽平臺提供運算資源了,但除非是必須,能不用就不用,因為大家一起搶資源導(dǎo)致寫了代碼不能跑的滋味真的很酸爽
關(guān)于以上這些知識技術(shù)儲備,我建議大家不要一直看書,計算機科學(xué)和機器學(xué)習(xí)的相關(guān)應(yīng)用都是實踐性很強的項目。任何一門有關(guān)編程語言的教材,看一周的時間足夠了。關(guān)鍵在于動手實踐,做項目做比賽,也就是任務(wù)驅(qū)動型學(xué)習(xí)。關(guān)于編程我還想說一個原則,就是“天下文章一大抄,看你會抄不會抄”。在做一個任務(wù)時,你的代碼能復(fù)制粘貼就不要自己敲。這些年我見過很多喜歡耍小聰明的同學(xué),試圖通過自主實現(xiàn)一些算法來證明自己的智商。這其實是一種十分幼稚的心理,編程本質(zhì)上是一個結(jié)果導(dǎo)向十分明顯的活動,解決問題遠(yuǎn)比證明你自己有多么優(yōu)秀更重要。
除了以上這些武器之外,你還需要知道做比賽的流程。參與一個數(shù)據(jù)科學(xué)競賽,大致需要這么幾個步驟:賽題分析,數(shù)據(jù)探索,數(shù)據(jù)預(yù)處理,特征構(gòu)造,特征選擇,模型選擇,模型優(yōu)化,模型融合,預(yù)測提交。其中數(shù)據(jù)預(yù)處理、特征構(gòu)造、特征選擇合起來可以稱之為特征工程。然后,還需要一個有效的迭代策略來管理你的idea和代碼。做比賽之前一定要將此流程牢記于心并一步一步地進行,下面就讓我為大家介紹圖中的每一步具體是如何操作的。
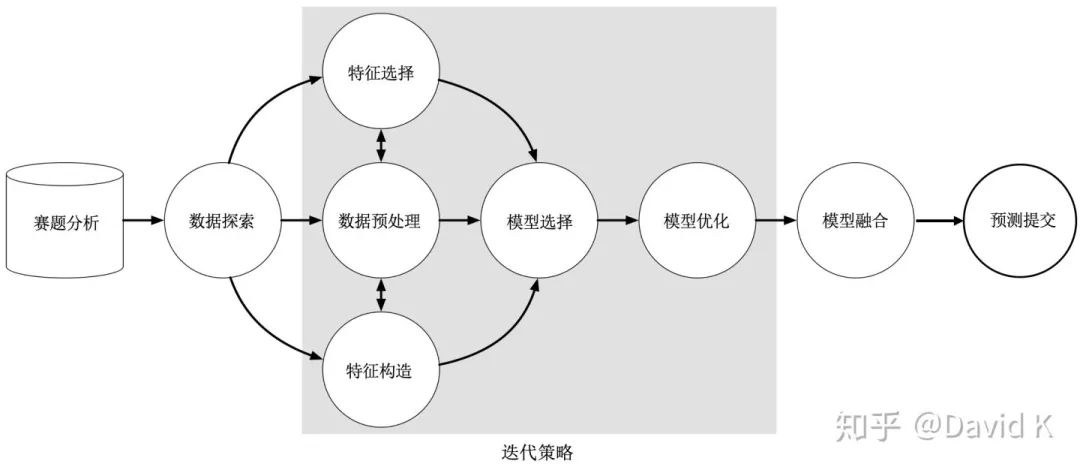
3.2 賽題分析
在我看來啊,賽題分析其實是在解決戰(zhàn)略層面的問題,這一塊其實是非常重要的,但市面上的很多開源的經(jīng)驗分享往往有意回避這一塊內(nèi)容,只談各種具體的方法和技巧。殊不知,真正做成一件事,不僅需要“術(shù)”,還需要“道”,但可惜的是,懂“道”的人實在是不多。為了讓大家更好地理解數(shù)據(jù)科學(xué)競賽中的“道”,我將賽題分析部分總結(jié)為以下這些內(nèi)容,包括對賽題背景的理解,對重要時間的把握,組隊的規(guī)則,評測機會的多少,以及對賽方提供訓(xùn)練數(shù)據(jù)的理解。
關(guān)于賽題背景。你需要仔細(xì)閱讀官方給出的賽題背景,然后查閱相關(guān)資料,對問題場景做深入的理解。因為對于我們這些學(xué)生來講,我們可能對機器學(xué)習(xí)和數(shù)據(jù)挖掘的理論知識掌握的很好,但缺乏對具體的問題場景理解。這就好比你只會做算術(shù)題卻不會做應(yīng)用題。希望大家記住一句話,解決問題的第一步是認(rèn)識問題。你只有把問題背景認(rèn)識清楚,看清出題者的動機,才有可能在比賽中取得好成績。
關(guān)于重要時間。一個數(shù)據(jù)科學(xué)競賽一般要持續(xù)兩到三個月甚至更長的時間,你在這么長的時間內(nèi)肯定還會有其他的事情要做,所以時間管理是很重要的。所以要根據(jù)賽方給出的重要時間節(jié)點(包括初賽開始時間、組隊完成時間、復(fù)賽開始時間、復(fù)賽結(jié)束時間、線下答辯時間),規(guī)劃好比賽與其他工作的時間安排。這里要插一句,其實并行工作是很難的,也是很扯淡的。如果你想取的好成績,還是需要專注在一件事上。
關(guān)于組隊規(guī)則。你一定要想清楚和什么樣的人組隊。我真心想告訴大家的一句話是,不怕神一樣的對手,就怕豬一樣的隊友。這句話什么意思大家應(yīng)該很清楚了。希望大家不拒絕豬隊友,也不要當(dāng)豬隊友坑別人。還有一點就是,搞清楚這個比賽能不能利用小號。每多一個小號,意味著多一倍的評測機會。你的評測機會越多,你上分的可能性越大。因此,每場比賽都會有很多人拿不同的手機號去注冊競賽平臺的賬號以求增加自己的評測機會,排行榜上也存在大量的小號。有時候你雖然線上測評的分?jǐn)?shù)在提高,但名次依然再下降,這時候不要灰心,說不定是前排大佬的小號把你踢了下來。
關(guān)于評測機會。搞清楚每天有幾次評測機會、幾點開始評測。較大的比賽受限于計算資源,每天只有一次評測機會,這種情況下還是得好好做線下的測試,珍惜每一次提交的機會。同時,基于評測次數(shù),設(shè)計每天的模型迭代策略。另外要注意的是,評測次數(shù)多不一定是好事,因為次數(shù)多了之后對自己有利,但對手也有利。所以在同樣的游戲規(guī)則下,如何充分利用各方面的條件提高自己的排名,的確是個需要你認(rèn)真琢磨的事情。
關(guān)于賽題數(shù)據(jù)。你需要搞清楚,賽方提供了什么數(shù)據(jù)?要解決的問題:分類問題 or 回歸問題?用什么軟件工具:個人PC or 官方計算平臺?提交什么樣的結(jié)果?也就是結(jié)果的數(shù)據(jù)格式要求。我在剛剛做比賽的時候經(jīng)常出現(xiàn)因為提交數(shù)據(jù)文件格式不正確而浪費評測機會。
3.3 數(shù)據(jù)探索
主要包括四個方面:數(shù)據(jù)整體認(rèn)知、數(shù)據(jù)質(zhì)量分析、數(shù)據(jù)統(tǒng)計量分析、數(shù)據(jù)分布分析
3.3.1 數(shù)據(jù)整體認(rèn)知
所謂的整體認(rèn)知就是,研究訓(xùn)練集、測試集、表數(shù)、記錄數(shù)、用戶數(shù)、變量數(shù)、變量類型、變量屬性值、標(biāo)簽等內(nèi)容,然后繪制實體-關(guān)系圖。實體-關(guān)系圖(E-R圖)包括三個組成部分:實體、屬性、關(guān)系。學(xué)過數(shù)據(jù)庫的同學(xué)應(yīng)該熟悉E-R圖這個概念。
比如我在做IJCAI2018阿里媽媽國際廣告算法大賽時,就繪制了如下圖的實體關(guān)系圖來幫助我們理解數(shù)據(jù)。

把這個圖畫出來之后,對每個屬性變量,施以哲學(xué)中的三大靈魂拷問:
你是誰?
你從哪兒來?
你要到哪里去?
也就是搞清楚每一個變量包含了什么信息,搞清楚它的來龍去脈,搞清楚變量和變量之間的關(guān)系。通過這個過程,讓你對整個問題背景和原始數(shù)據(jù)有一個深入地了解,為后續(xù)工作做準(zhǔn)備。
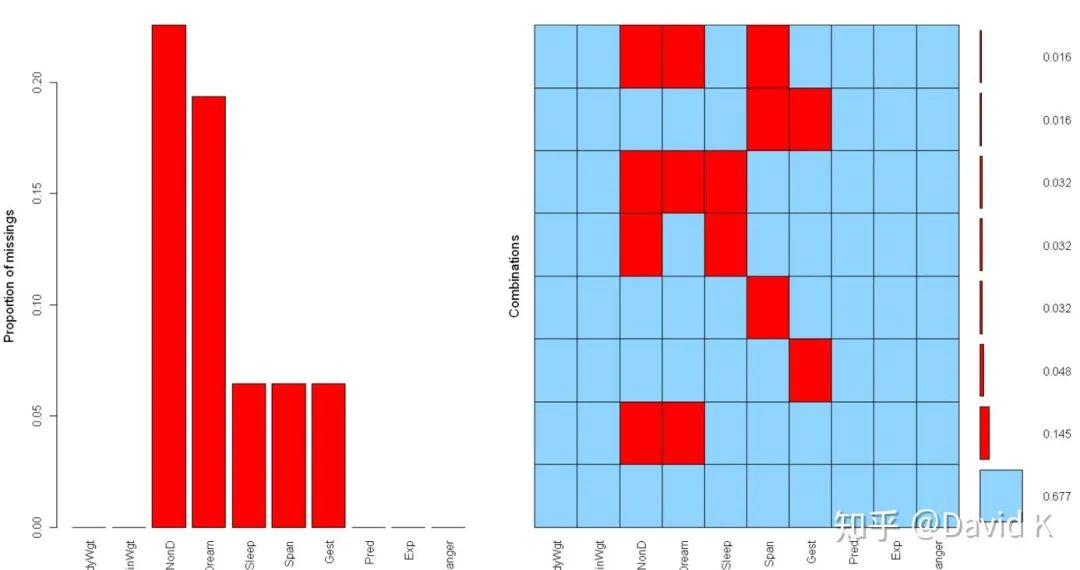
3.3.2 數(shù)據(jù)質(zhì)量分析
所謂數(shù)據(jù)質(zhì)量分析,就是分析數(shù)據(jù)的缺失值、重復(fù)值、異常值、歧義值、正負(fù)樣本比例(樣本不平衡)等特性。由于這些東西都會影響到模型的學(xué)習(xí)效果,所以在后面做數(shù)據(jù)預(yù)處理時需要做相應(yīng)的工作。
3.3.3 數(shù)據(jù)統(tǒng)計量分析
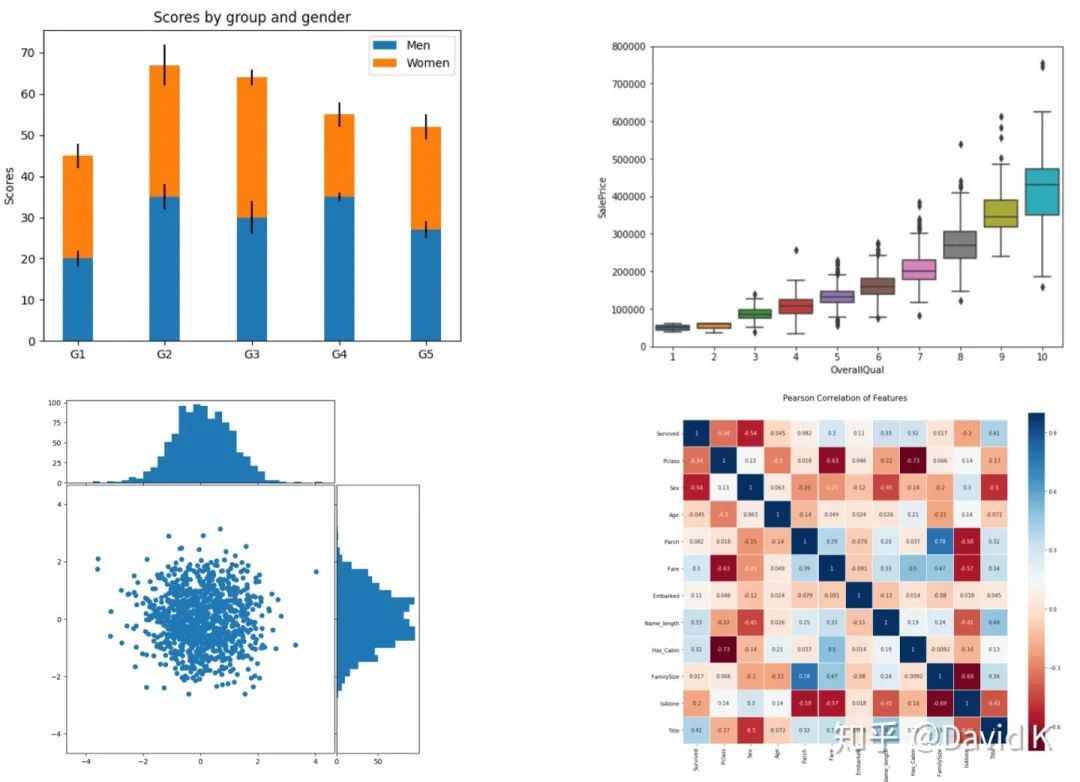
數(shù)據(jù)統(tǒng)計量分析主要分為三塊:
第一,對單個變量的統(tǒng)計分析。比如考察單個變量的均值、中位數(shù)、眾數(shù)、分位數(shù)、方差、變異系數(shù)等。常用的工具有:直方圖、箱線圖、小提琴圖等。
第二,對兩個變量的統(tǒng)計分析。這里主要考察的是兩個變量統(tǒng)計分布之間的關(guān)系。常用的工具包括散點圖、相關(guān)性分析圖、熱力圖等。
第三,對多個變量的統(tǒng)計分析。可以使用彩色的散點圖,或者RadViz(詳見scikit-yb.org/en/latest)。
3.3.4 數(shù)據(jù)分布分析
數(shù)據(jù)分布分析指的是考察某個字段或某些字段的統(tǒng)計分布。包括頻數(shù)、時間、空間三個方面。
頻數(shù)統(tǒng)計。用概率論的語言講叫累積分布函數(shù)CDF。比如在IJCAI2018阿里媽媽國際廣告算法大賽中,我們就統(tǒng)計了不同點擊次數(shù)下各有多少用戶。基于類似的累積分布函數(shù)圖我們就可以知道用戶行為的分布情況,進而可以幫助我們充分理解數(shù)據(jù)。
時間維度上的統(tǒng)計分布。我們可以觀察事件發(fā)生的趨勢和周期性,這里會涉及不少時間序列的知識。比如下圖所示的“每天的點擊數(shù)趨勢”,就是在時間維度上考察點擊數(shù)的變化情況。
空間維度上的統(tǒng)計分布,我們可以尋找某個變量在地理位置上的相關(guān)關(guān)系。比如2020年以來我們十分熟悉的疫情地圖,就是一種空間上的分布分析。
另外,以上三種分析常常結(jié)合分組or聚類方法,對細(xì)分的業(yè)務(wù)場景進行考察,為后面的數(shù)據(jù)建模做鋪墊。
3.3.5 數(shù)據(jù)探索小結(jié)
對于數(shù)據(jù)探索,我總結(jié)了幾個需要牢記在心的關(guān)鍵點,分別是:對比,分組,頻數(shù),抓大放小和可視化。
所謂對比,指的是在做數(shù)據(jù)探索時,考慮對比訓(xùn)練集不同樣本之間的特征分布,還要考慮對比訓(xùn)練集和測試集中每一個特征的分布。
所謂分組,就是在做數(shù)據(jù)探索時,常常用到按類別標(biāo)簽、某個離散變量的不同取值groupby后的sum、unique。
所謂頻數(shù),就是要注意考察并自行計算某些變量的概率累積分布。諸如“事件發(fā)生次數(shù)”這樣的的統(tǒng)計量需要自己計算;有時還要關(guān)注“同id下某個事件多次發(fā)生”的統(tǒng)計。
所謂抓大放小,就是對于那些特征重要性較高的變量,要做重點分析。因為這些變量對你模型預(yù)測能力的影響是較大的。
所謂可視化,就是建議大家在做數(shù)據(jù)探索的時候多畫圖(尤其是各種趨勢圖、分布圖),圖形給人的沖擊力往往是要大于數(shù)字本身的。
3.4 特征工程
下面我們來講特征工程。這也是做數(shù)據(jù)競賽時最重要的一項內(nèi)容。
首先說一下為什么要做特征工程。
在我們解決一個機器學(xué)習(xí)問題時,輸入機器學(xué)習(xí)模型的數(shù)據(jù)必須是標(biāo)準(zhǔn)的向量形式。但當(dāng)我們處理現(xiàn)實世界的數(shù)據(jù)時,數(shù)據(jù)并不會以格式規(guī)范的特征向量的形式呈現(xiàn)在我們面前。相反,呈現(xiàn)給我們的數(shù)據(jù)是數(shù)據(jù)庫記錄、時間序列、圖像、音頻、文字等形式,同時還存著在大量的噪聲數(shù)據(jù)。所以我們需要一定的方法把非結(jié)構(gòu)化的數(shù)據(jù)轉(zhuǎn)化為結(jié)構(gòu)化的數(shù)據(jù)。
結(jié)合維基百科,我給特征和特征工程做了如下定義:
特征:An variable useful for your modeling task,which describe/represent our data
特征工程:A process of using domain knowledge, techniques, experiences or even tricks to create features that make machine learning algorithms work well.
為了說明特征工程的重要性,這里聚一個小例子。下圖中有一些藍(lán)色的點和一些綠色的點,在直角坐標(biāo)系下它們的分布如左圖所示,肉眼看上去,它們顯然是屬于兩個類別,但是如果你想用一個機器學(xué)習(xí)的線性分類器去做分類的話是很困難的。但是你把這些點轉(zhuǎn)移到極坐標(biāo)系下,它們就可以很容易用一個線性分類器做分類了。從這個地方我們就能看出數(shù)據(jù)的表示方式對機器學(xué)習(xí)模型的效果的影響還是很大的。
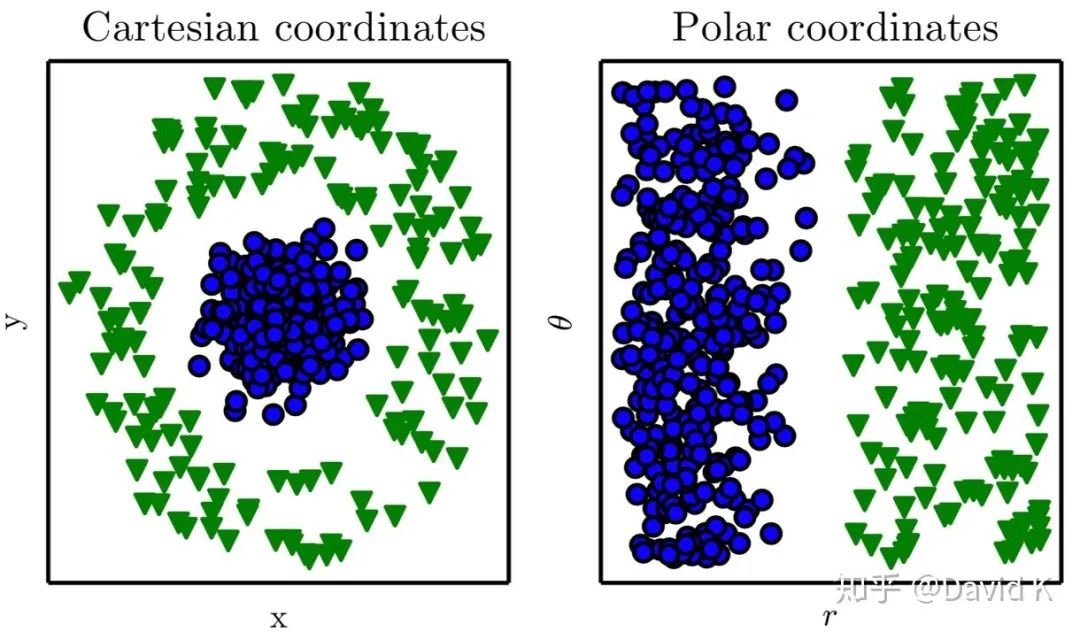
我希望大家記住一點,就是在解決一個機器學(xué)習(xí)問題時,最關(guān)鍵的就是去研究如何表示你的樣本,而特征工程解決的就是representation的問題,F(xiàn)eature engineering is a?representation?problem。這里把傳統(tǒng)的軟件開發(fā)和機器學(xué)習(xí)項目做一個簡單的比較:在編程開發(fā)項目中,很關(guān)鍵的地方在于如何優(yōu)化你的代碼;而在機器學(xué)習(xí)項目中,關(guān)注點變成了表示。也就是說,開發(fā)者通過添加和改善特征來調(diào)整模型。
所以,這也是我們?nèi)?nèi)經(jīng)常說的,“數(shù)據(jù)和特征決定了機器學(xué)習(xí)的上限,而模型和算法只能去逼近這個上限”。我希望大家應(yīng)該牢牢地記住這句話。不管是做機器學(xué)習(xí)的比賽還是實際的項目,特征工程都是最最重要的一部分。這里引用了兩句英文來進一步證明這個道理:
Coming up with features is difficult, time-consuming, requires expert knowledge. "Applied machine learning" is basically feature engineering.
—?吳恩達(dá)Andrew Ng, Machine Learning and AI via Brain simulations
“...some machine learning projects succeed and some fail. What makes thedifference? Easily the most important factor is the features used.”
—《終極算法:機器學(xué)習(xí)和人工智能如何重塑世界》作者 Pedro Domingos
我將特征工程分為三個部分,分別是數(shù)據(jù)預(yù)處理、特征構(gòu)造和特征選擇。下面分別介紹這些內(nèi)容。
3.4.1 數(shù)據(jù)預(yù)處理
首先來說一下為什么要做數(shù)據(jù)預(yù)處理。首先,考慮到海量原始數(shù)據(jù)中存在大量信息缺失、不一致、冗余值、異常值等,會影響我們模型的學(xué)習(xí)效果。另外,在用各種模型算法時也要牢記監(jiān)督學(xué)習(xí)的假設(shè),即正負(fù)樣本要平衡且訓(xùn)練集和測試集樣本是獨立同分布的。第三,在模型訓(xùn)練時,數(shù)據(jù)規(guī)范化的操作可以讓梯度下降算法收斂得更快,也就是更快地找到最優(yōu)超參數(shù)。
傳統(tǒng)意義上的數(shù)據(jù)預(yù)處理一般包括數(shù)據(jù)清洗、數(shù)據(jù)集成、數(shù)據(jù)重采樣、數(shù)據(jù)變換(特征編碼)和數(shù)據(jù)規(guī)范化(特征縮放),這一塊的內(nèi)容也是網(wǎng)絡(luò)上流傳最廣、介紹最多的數(shù)據(jù)分析技巧,因此我不做具體的解釋,僅僅把各自常用的處理技巧羅列一下。
數(shù)據(jù)清洗
缺失值插補
均值、中位數(shù)、眾數(shù)插補
固定值插補
最近鄰插補
離群值
直接刪除
替換法
異常、冗余值
直接刪除
小技巧:用訓(xùn)練集數(shù)據(jù)學(xué)習(xí)一個模型,然后用它預(yù)測訓(xùn)練集的標(biāo)簽,刪除預(yù)測結(jié)果偏差較大的樣本
數(shù)據(jù)集成
多表數(shù)據(jù)整合
一對一
一對多
多對一
多對多
數(shù)據(jù)重采樣
滑窗法:
對于時間序列數(shù)據(jù),選取不同的時間窗間隔,可以得到多份訓(xùn)練數(shù)據(jù)集
該方法可以增加訓(xùn)練樣本,也方便做交叉驗證實驗
非平衡重采樣:調(diào)整正負(fù)樣本量
欠采樣
過采樣
組合采樣
數(shù)據(jù)變換
連續(xù)變量離散化(分箱)
等頻
等寬
聚類
離散變量編碼
One-hot Encoding
Label Encoding
長尾分布
Ln、Log
數(shù)據(jù)規(guī)范化
Min-Max
Z-score
MaxAbs
網(wǎng)絡(luò)上羅列的這些方法,如何更高效地使用,詳見t.zsxq.com/IMfe2vB。
3.4.2 特征構(gòu)造
在一個機器學(xué)習(xí)比賽中,很多的有效特征都不是直接給出的,需要自己去挖掘。不要以為實際中的訓(xùn)練數(shù)據(jù)都像UCI開源的數(shù)據(jù)集那樣簡單直接好用。
我把基于對原始數(shù)據(jù)的數(shù)據(jù)探索,不斷構(gòu)造新特征的過程定義為特征構(gòu)造(Feature Construction)。在這個過程中,你需要深入了解場景知識,并做大量開腦洞的工作。但僅憑開腦洞和無腦地堆砌并不能真正解決問題,如果你想構(gòu)造出具有可解釋性且豐富的特征,需要一套思想方法。
在此我給出一種特征構(gòu)造的思想方法,希望能給大家一定的啟發(fā)。
3.4.2.1 思想方法
理解字段
抽取實體
分析實體關(guān)系
設(shè)計特征群
按特征群分別構(gòu)造特征
考察特征群關(guān)系,進一步構(gòu)造新特征
3.4.2.2 特征構(gòu)造舉例
t.zsxq.com/IMfe2vB
3.4.2.3 特征構(gòu)造 注意事項
t.zsxq.com/IMfe2vB
3.4.3 特征選擇
前面你構(gòu)造了很多特征,但這些特征不一定都是有用的,需要用特征選擇的辦法把有用的特征選出來。Feature selection is a process that chooses an optimal subset of features。特征選擇可以幫你篩選有效特征,消除冗余信息,提高訓(xùn)練效率,避免模型發(fā)生過擬合。
常用的特征選擇方法如下圖所示:
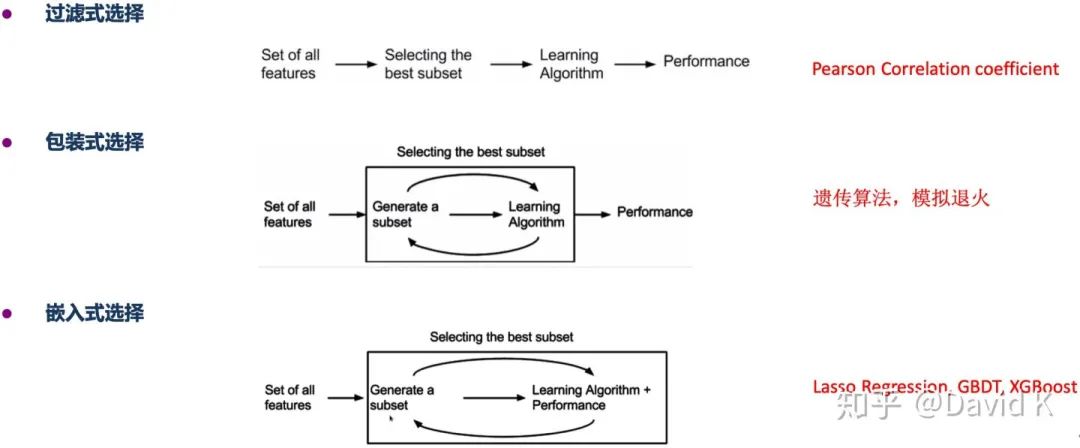
我一直覺得特征選擇是那種爛大街的知識。可問題是,這些方法都要用嗎?哪個好用?哪個效率最高?t.zsxq.com/IMfe2vB
3.4.4 特征工程總結(jié)
這樣整個特征工程部分就講完了。我最后想提醒大家,在數(shù)據(jù)科學(xué)競賽中,特征工程是一個需要不斷迭代測試的過程,也就是說,數(shù)據(jù)探索、數(shù)據(jù)預(yù)處理、特征工程要反復(fù)多次進行。所以,一定要把75%以上的時間放在特征工程的工作上。
3.5 模型選擇
我知道每個機器學(xué)習(xí)小白在做比賽前都把周志華的西瓜書和李航的《統(tǒng)計機器學(xué)習(xí)》翻了一遍又一遍。那我想問大家一個問題:書上講的算法模型,比如LR,GLM,SVM,KNN,NN,Tree,RF,Adaboost,在機器學(xué)習(xí)比賽中,到底用什么,哪個好用,哪個效率最高?
答:都不用!!!!!!!!
我想這個答案可能有點出乎大家的意料吧。畢竟大家學(xué)了大半學(xué)期的機器學(xué)習(xí),都是在講這些玩意兒的原理。你是不是忽然覺得有些迷茫了呢?自己學(xué)了大半學(xué)期的書本竟然像垃圾一樣沒用。
然后我想告訴大家,數(shù)據(jù)科學(xué)競賽的模型大殺器是:基于決策樹的集成學(xué)習(xí)模型,例如LightGBM、XGBoost、CatBoost等。
從好用程度上來看:LightGBM > XGBoost > CatBoost。你甚至可以只用LightGBM來學(xué)習(xí)你的訓(xùn)練數(shù)據(jù)。
下面我想解釋兩個問題:
一,為什么梯度提升樹打數(shù)據(jù)挖掘競賽優(yōu)勢明顯?
看一個機器學(xué)習(xí)模型的開源工具好不好用,主要是看訓(xùn)練效率和學(xué)習(xí)能力的trade-off。像LightGBM這樣的模型,訓(xùn)練速度快,效率高,還支持并行和GPU計算;同時能夠處理大規(guī)模的數(shù)據(jù),算法的學(xué)習(xí)能力更強,預(yù)測精確度高。
二、為什么深度學(xué)習(xí)模型打數(shù)據(jù)挖掘競賽優(yōu)勢不大?
在此引用吳恩達(dá)老師在Coursera公開課中的一張圖。
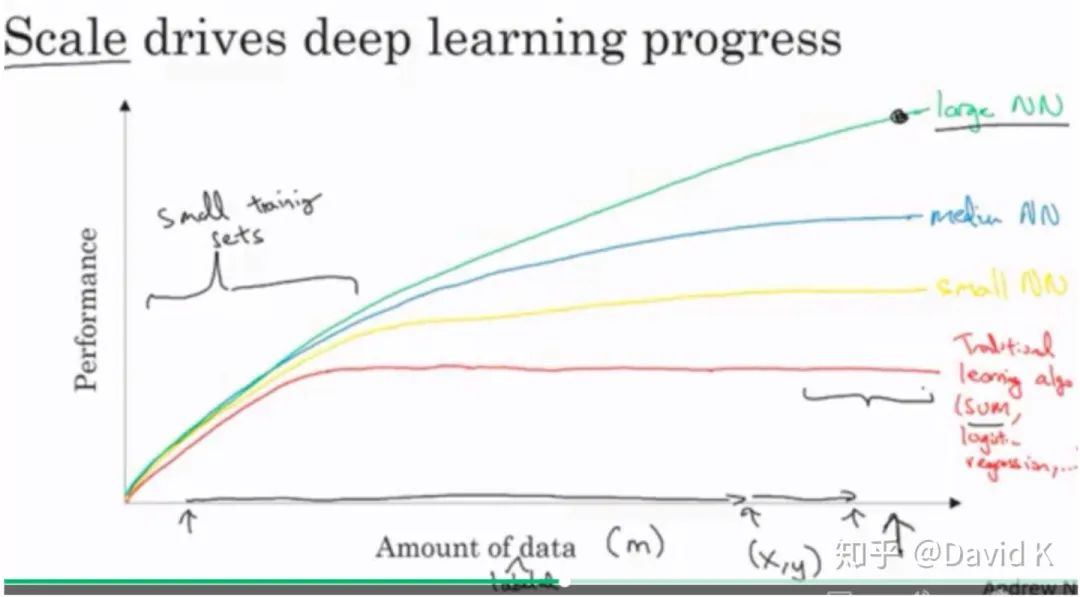
該圖橫軸表示的是訓(xùn)練數(shù)據(jù)的條數(shù),縱軸顯示的是多種模型的學(xué)習(xí)效果。從這個圖可以看出,當(dāng)你的數(shù)據(jù)規(guī)模比較小時,深度學(xué)習(xí)模型的效果甚至還不如普通的機器學(xué)習(xí)模型。所謂的數(shù)據(jù)規(guī)模比較小,我給一個判斷標(biāo)準(zhǔn):2000萬訓(xùn)練樣本。也就是說,沒有兩千萬的訓(xùn)練樣本,深度學(xué)習(xí)模型根本無法施展它的威力。所以在傳統(tǒng)的機器學(xué)習(xí)比賽中,我們還是用lightGBM這種集成樹,簡單粗暴卻又威力無窮。
3.6 模型優(yōu)化
模型優(yōu)化主要分為三塊,在此以一個思維導(dǎo)圖呈現(xiàn):
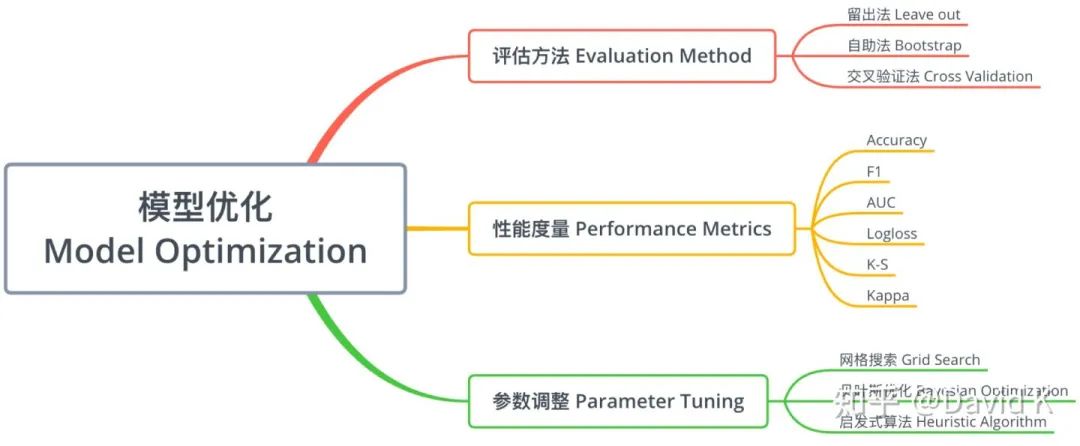
3.6.1 評估方法
周志華老師的西瓜書中討論了三種模型優(yōu)化的方法,分別是留出法,自助法和交叉驗證法。在我看來這也屬于爛大街的知識。還是老問題,在打比賽時,我們應(yīng)該如何使用這些方法,有哪些關(guān)鍵性的技巧?這里有幾條經(jīng)驗跟大家分享。
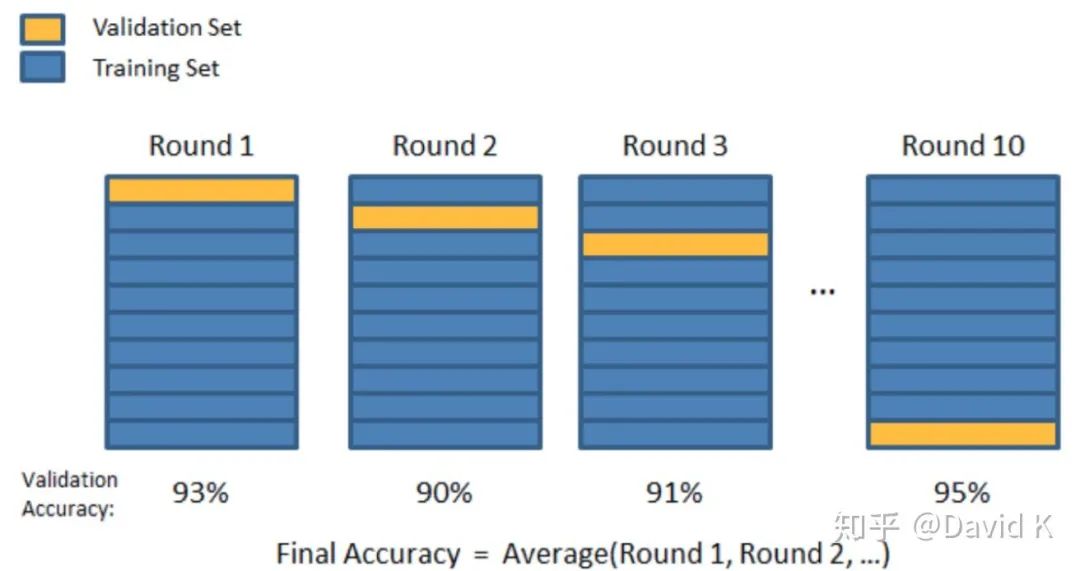
來點干貨:
比賽中最常用的模型評估方法是留出法和K折交叉驗證法。
t.zsxq.com/IMfe2vB
3.6.2 性能度量
在比賽中常見的指標(biāo)(性能度量)包括AUC、Logloss、K-S、F1、Kappa系數(shù)等,這些指標(biāo)都是綜合考量模型對正類和負(fù)類的預(yù)測能力,更具有說服力。
來點干貨:
線下測試時,應(yīng)多使用幾種指標(biāo),單刷賽題給定的指標(biāo)容易發(fā)生過擬合
如果幾個指標(biāo)同時上漲,則可以證明你的特征&模型取得了實質(zhì)性的改進
針對賽題使用的性能度量指標(biāo),推導(dǎo)其數(shù)學(xué)原理,思考特殊的優(yōu)化策略
3.6.3 參數(shù)調(diào)整
主要方法:
網(wǎng)格搜索(Grid Search)
貝葉斯優(yōu)化(Bayesian Optimization)
啟發(fā)式算法(Heuristic Algorithms,如GA、模擬退火,PSO)
工具包:Hyperopt等
關(guān)于調(diào)參我實在不想講太多東西,雖然網(wǎng)上這一塊可能扯的很多。但一般扯的越多的東西,一般都是扯淡。事實上,用一用網(wǎng)格搜索就足夠了。
來點干貨:t.zsxq.com/IMfe2vB
3.7 模型融合
所謂的模型融合,主要是指對不同子模型的預(yù)測結(jié)果的融合。江湖上有人說,“Feature決定了模型效果的上限,而ensemble就是讓你更接近這個上限”。
模型融合的方法網(wǎng)上有很多,在此我簡單羅列一下。
方法:
簡單加權(quán)平均:0.5*result_1+0.5*result_2
Bagging:對訓(xùn)練集隨機采樣,訓(xùn)練不同的base model,然后投票;可以減少方差,提升模型的穩(wěn)定性(隨機森林就是這個原理)
Boosting:弱分類器提升為強分類器,并做模型的加權(quán)融合;可以減少學(xué)習(xí)誤差,但容易過擬合
Blending:拆分訓(xùn)練集,使用不重疊或者部分重疊的數(shù)據(jù)訓(xùn)練不同的base model,然后分別預(yù)測test數(shù)據(jù),并加權(quán)融合(這是個好辦法)
Stacking:網(wǎng)上講的很多,但極易造成過擬合,尤其是數(shù)據(jù)量小時過擬合嚴(yán)重,不建議使用
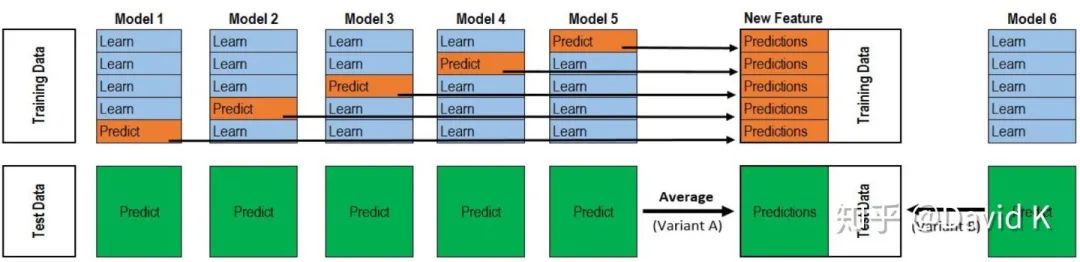
其實網(wǎng)上的資料總會給你各種誤導(dǎo),所以我想直接講干貨,告訴你如何更高效地用這些方法。
t.zsxq.com/IMfe2vB
3.8 迭代策略
t.zsxq.com/IMfe2vB
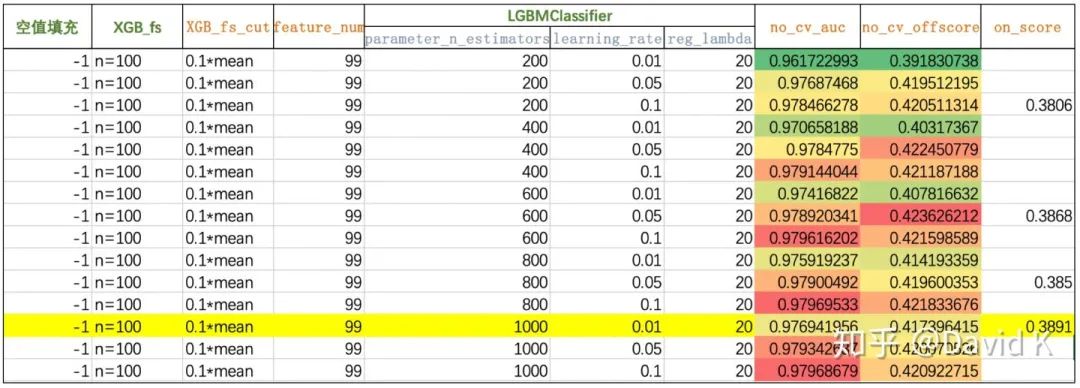
3.9 其他
還有一些內(nèi)容是我想強調(diào)的,這些東西依然是戰(zhàn)略層面的。不得不說,它們對你很重要。
第一,做比賽的第一步是完成一個從0到1的原型設(shè)計。這是一種原型思維。也就是說,你要先做出一版能提交的結(jié)果,并提交成功。走完這一步,你才算剛剛上路。做任何事,完成從0到1的過程都是最重要的。
第二,一定保證自己的代碼是正確的,所謂正確指的是,正確地表達(dá)了你的idea而不僅僅是沒有語法邏輯bug。這一點也是小白常常犯的錯誤。
第三,寫一個較為自動化的、高效率的代碼框架。在數(shù)據(jù)預(yù)處理的部分,一定要少用暴力的for循環(huán)。一個入門級的baseline在這里:github.com/yzkang/My-Da,大家可以直接基于此代碼做特征工程即可。
第四,關(guān)于時間和精力的分配。做比賽是一件很辛苦的事情,每天壓力很大,常常晝夜顛倒,沒日沒夜地寫代碼。所以,一定要善于抓住主要矛盾。數(shù)據(jù)探索+特征工程的部分要分配75%的時間和精力。模型優(yōu)化及調(diào)參占15%,模型融合占10%。另外,珍惜你的每一次提交機會。
第五,在閑暇時間,及時更新你的武器庫,多閱讀開源經(jīng)驗分享,多跟大佬們請教和學(xué)習(xí)。
最后我想談一談自己這幾年做比賽、做項目、做論文、做團隊的一點收獲,希望大家批評指正。
首先,我認(rèn)為不管是在學(xué)校做事情還是在公司做事情,結(jié)果導(dǎo)向、以終為始是十分重要的思維方式。牢記鄧公所講的黑貓白貓論,通過不斷地磨練讓自己成為一只好貓。當(dāng)然,這種思維方式可能不太適合體制內(nèi)的工作人員。
其次,編程的目的不是秀自己的智商,而是蓋一棟房子,解決一個問題,實現(xiàn)一個目標(biāo)。所以不重復(fù)造輪子是很重要的,我一直堅持的一個觀點是,能抄別人的代碼堅決不自己寫,不到萬不得已堅決不自己寫。我們的手機,每個零件都有專門的廠家進行加工,編程做比賽也是一個道理。如果華為不購買別人家的芯片,一百年也造不出一個手機。通過借鑒吸收別人的經(jīng)驗成果,安全避坑,高效率地完成自己的目標(biāo),才是快速創(chuàng)造價值的真諦。
第三,很多事情都是實踐出真知。就拿編程來講,你把編程語言的課本翻爛也學(xué)不會編程。機器學(xué)習(xí)的理論學(xué)的再好,你依然不會解決實際問題。很多工科性質(zhì)的知識,你看過但沒有用過,跟沒看過一樣。如果你是工科生,一定要注意多動手,多實踐。
第四,有競爭的地方就有江湖。在江湖上混,打鐵還需自身硬。希望你知道,優(yōu)秀的人只會和優(yōu)秀的人合作,想升級你做事的圈子,先把自己搞成相對優(yōu)秀的人。世界上絕大多數(shù)的合作都是強強聯(lián)合。
第五,靠天賦、努力還是運氣?我認(rèn)為做比賽最需要的是強烈的興趣和自我驅(qū)動力,和智商的高低其實沒有太大關(guān)系。一個比賽,你想做到Top50,我猜用這份資料講述的經(jīng)驗應(yīng)該足夠了。你想做到Top10,需要堅持不懈的努力。你想做到Top5,多多少少還是需要一點運氣的,畢竟在一個比賽的最后幾天,提交機會相對越來越少,怎么把握這些提交機會,還是需要你與生俱來的判斷力。
最后,送給大家一句話吧:勝利后的復(fù)盤可能非常精彩,但實現(xiàn)的過程則枯燥而艱難。
祝大家都能在數(shù)據(jù)科學(xué)競賽中取得好成績!
附:我的競賽成績總結(jié)
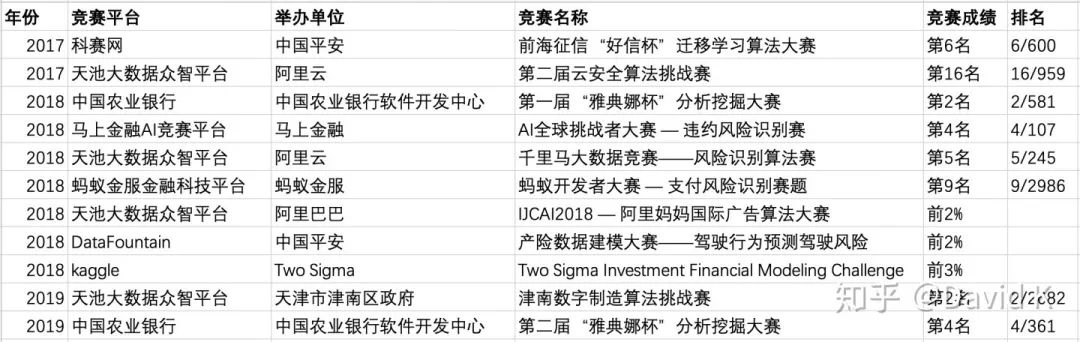
部分未完成競賽

?