
Redis奪命十二問,差點(diǎn)沒抗住!
大家好,我是二哥呀。
Redis 是面試中繞不過的檻,只要在簡歷中寫了用過 Redis,肯定逃不過。今天我們就來模擬一下面試官在 Redis 這個(gè)話題上是如何一步一步深入,全面考察候選人對于 Redis 的掌握情況。
小二:面試官,你好。我是來參加面試的。
面試官:你好,小二。我看了你的簡歷,熟練掌握 Redis,那么我就隨便問你幾個(gè) Redis 相關(guān)的問題吧。首先我的問題是,Redis 是單線程還是多線程呢?
小二:
Redis 不同版本之間采用的線程模型是不一樣的,在 Redis4.0 版本之前使用的是單線程模型,在 4.0 版本之后增加了多線程的支持。
在 4.0 之前雖然我們說 Redis 是單線程,也只是說它的網(wǎng)絡(luò) I/O 線程以及 Set 和 Get 操作是由一個(gè)線程完成的。但是 Redis 的持久化、集群同步還是使用其他線程來完成。
4.0 之后添加了多線程的支持,主要是體現(xiàn)在大數(shù)據(jù)的異步刪除功能上,例如 unlink key、flushdb async、flushall async 等
面試官:回答的很好,那為什么 Redis 在 4.0 之前會(huì)選擇使用單線程?而且使用單線程還那么快?
小二:
選擇單線程個(gè)人覺得主要是使用簡單,不存在鎖競爭,可以在無鎖的情況下完成所有操作,不存在死鎖和線程切換帶來的性能和時(shí)間上的開銷,但同時(shí)單線程也不能完全發(fā)揮出多核 CPU 的性能。
至于為什么單線程那么快我覺得主要有以下幾個(gè)原因:
Redis 的大部分操作都在內(nèi)存中完成,內(nèi)存中的執(zhí)行效率本身就很快,并且采用了高效的數(shù)據(jù)結(jié)構(gòu),比如哈希表和跳表。 使用單線程避免了多線程的競爭,省去了多線程切換帶來的時(shí)間和性能開銷,并且不會(huì)出現(xiàn)死鎖。 采用 I/O 多路復(fù)用機(jī)制處理大量客戶端的 Socket 請求,因?yàn)檫@是基于非阻塞的 I/O 模型,這就讓 Redis 可以高效地進(jìn)行網(wǎng)絡(luò)通信,I/O 的讀寫流程也不再阻塞。
面試官:不錯(cuò),那 Redis 是如何實(shí)現(xiàn)數(shù)據(jù)不丟失的呢?
小二:
Redis 數(shù)據(jù)是存儲(chǔ)在內(nèi)存中的,為了保證 Redis 數(shù)據(jù)不丟失,那就要把數(shù)據(jù)從內(nèi)存存儲(chǔ)到磁盤上,以便在服務(wù)器重啟后還能夠從磁盤中恢復(fù)原有數(shù)據(jù),這就是 Redis 的數(shù)據(jù)持久化。Redis 數(shù)據(jù)持久化有三種方式。
1)AOF 日志(Append Only File,文件追加方式):記錄所有的操作命令,并以文本的形式追加到文件中。
2)RDB 快照(Redis DataBase):將某一個(gè)時(shí)刻的內(nèi)存數(shù)據(jù),以二進(jìn)制的方式寫入磁盤。
3)混合持久化方式:Redis 4.0 新增了混合持久化的方式,集成了 RDB 和 AOF 的優(yōu)點(diǎn)。
面試官:那你分別說說 AOF 和 RDB 的實(shí)現(xiàn)原理吧。
小二:
AOF 采用的是寫后日志的方式,Redis 先執(zhí)行命令把數(shù)據(jù)寫入內(nèi)存,然后再記錄日志到文件中。AOF 日志記錄的是操作命令,不是實(shí)際的數(shù)據(jù),如果采用 AOF 方法做故障恢復(fù)時(shí)需要將全量日志都執(zhí)行一遍。
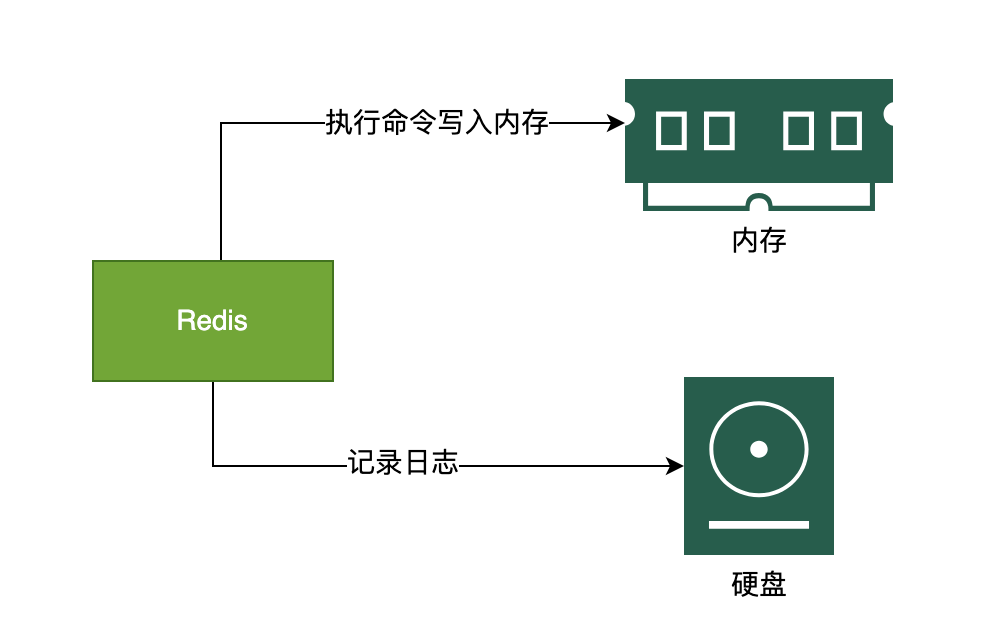
RDB 采用的是內(nèi)存快照的方式,它記錄的是某一時(shí)刻的數(shù)據(jù),而不是操作,所以采用 RDB 方法做故障恢復(fù)時(shí)只需要直接把 RDB 文件讀入內(nèi)存即可,實(shí)現(xiàn)快速恢復(fù)。
面試官:你剛提到了 AOF 采用的是 “寫后日志” 的方式,我們平時(shí)用的 MySQL 則采用的是 “寫前日志”,那 Redis 為什么要先執(zhí)行命令,再把數(shù)據(jù)寫入日志呢?
小二:這個(gè)主要是由于 Redis 在寫入日志之前,不對命令進(jìn)行語法檢查,所以只記錄執(zhí)行成功的命令,避免出現(xiàn)記錄錯(cuò)誤命令的情況,而且在命令執(zhí)行后再寫日志不會(huì)阻塞當(dāng)前的寫操作。
面試官:那后寫日志又有什么風(fēng)險(xiǎn)呢?
小二:我... 這個(gè)我不會(huì)。
面試官:
好吧,后寫日志主要有兩個(gè)風(fēng)險(xiǎn)可能會(huì)發(fā)生:
數(shù)據(jù)可能會(huì)丟失:如果 Redis 剛執(zhí)行完命令,此時(shí)發(fā)生故障宕機(jī),會(huì)導(dǎo)致這條命令存在丟失的風(fēng)險(xiǎn)。 可能阻塞其他操作:AOF 日志其實(shí)也是在主線程中執(zhí)行,所以當(dāng) Redis 把日志文件寫入磁盤的時(shí)候,還是會(huì)阻塞后續(xù)的操作無法執(zhí)行。
我還有個(gè)問題是 RDB 做快照時(shí)會(huì)阻塞線程嗎?
小二:Redis 提供了兩個(gè)命令來生成 RDB 快照文件,分別是 save 和 bgsave。save 命令在主線程中執(zhí)行,會(huì)導(dǎo)致阻塞。而 bgsave 命令則會(huì)創(chuàng)建一個(gè)子進(jìn)程,用于寫入 RDB 文件的操作,避免了對主線程的阻塞,這也是 Redis RDB 的默認(rèn)配置。
面試官:RDB 做快照的時(shí)候數(shù)據(jù)能修改嗎?
小二:save 是同步的會(huì)阻塞客戶端命令,bgsave 的時(shí)候是可以修改的。
面試官:那 Redis 是怎么解決在 bgsave 做快照的時(shí)候允許數(shù)據(jù)修改呢?
小二:額,這個(gè)我不太清楚...

面試官:
這里主要是利用 bgsave 的子線程實(shí)現(xiàn)的,具體操作如下:
如果主線程執(zhí)行讀操作,則主線程和 bgsave 子進(jìn)程互相不影響; 如果主線程執(zhí)行寫操作,則被修改的數(shù)據(jù)會(huì)復(fù)制一份副本,然后 bgsave 子進(jìn)程會(huì)把該副本數(shù)據(jù)寫入 RDB 文件,在這個(gè)過程中,主線程仍然可以直接修改原來的數(shù)據(jù)。
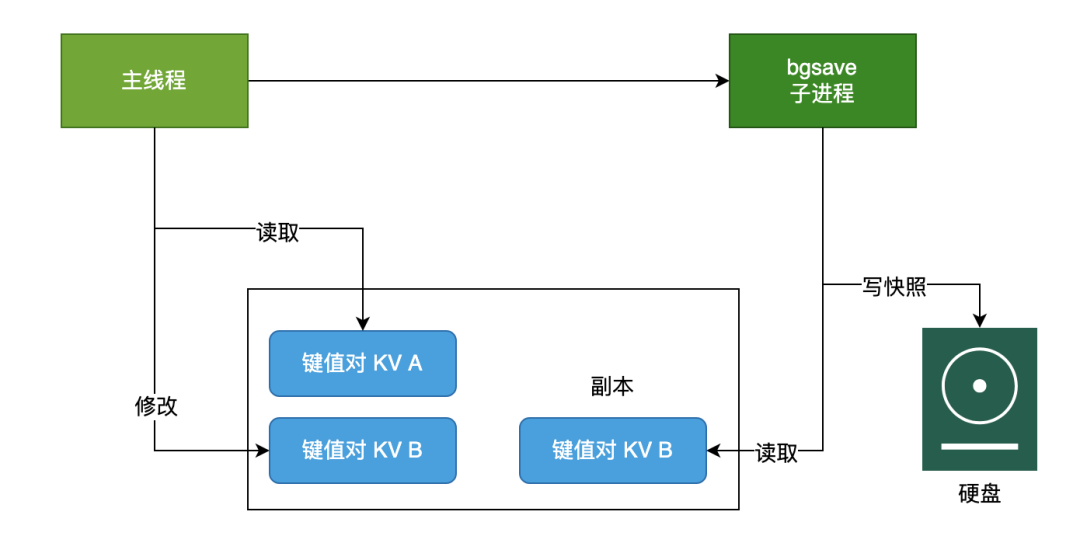
要注意,Redis 對 RDB 的執(zhí)行頻率非常重要,因?yàn)檫@會(huì)影響快照數(shù)據(jù)的完整性以及 Redis 的穩(wěn)定性,所以在 Redis 4.0 后,增加了 AOF 和 RDB 混合的數(shù)據(jù)持久化機(jī)制:把數(shù)據(jù)以 RDB 的方式寫入文件,再將后續(xù)的操作命令以 AOF 的格式存入文件,既保證了 Redis 重啟速度,又降低數(shù)據(jù)丟失風(fēng)險(xiǎn)。
小二:學(xué)到了學(xué)到了。
面試官:那你再跟我說說 Redis 如何實(shí)現(xiàn)高可用吧?
小二:Redis 實(shí)現(xiàn)高可用主要有三種方式:主從復(fù)制、哨兵模式,以及 Redis 集群。
1)主從復(fù)制
將從前的一臺(tái) Redis 服務(wù)器,同步數(shù)據(jù)到多臺(tái)從 Redis 服務(wù)器上,即一主多從的模式,這個(gè)跟 MySQL 主從復(fù)制的原理一樣。

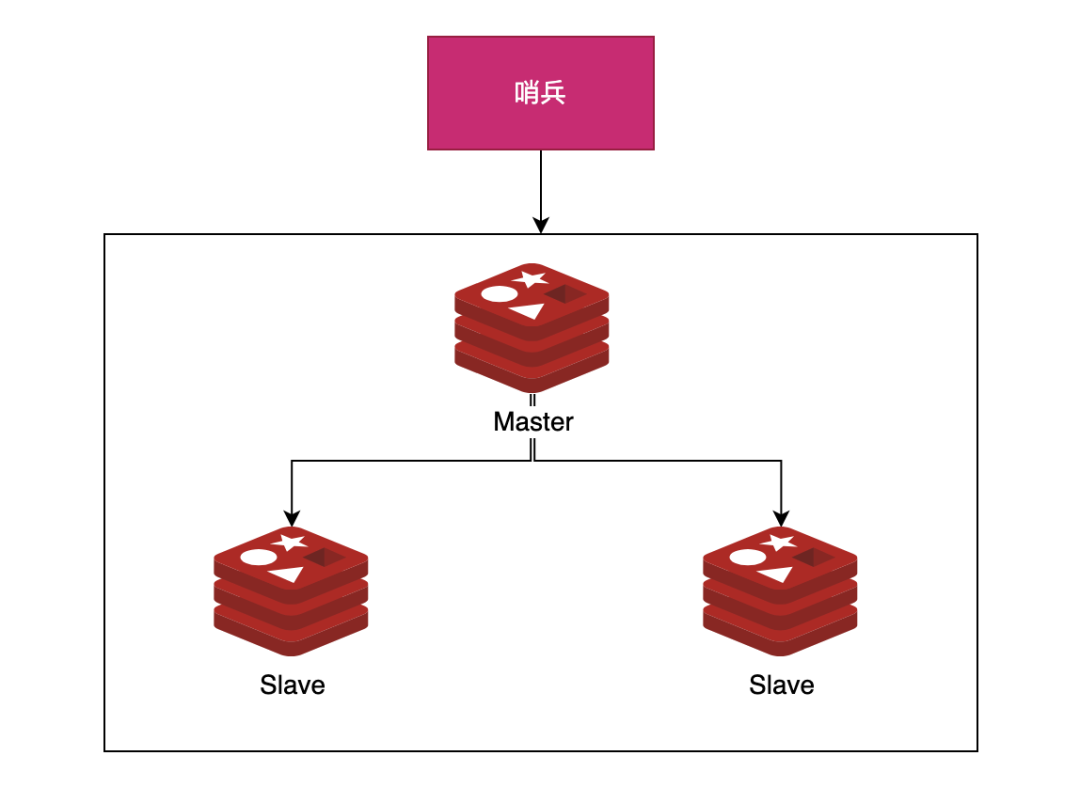
2)哨兵模式
使用 Redis 主從服務(wù)的時(shí)候,會(huì)有一個(gè)問題,就是當(dāng) Redis 的主從服務(wù)器出現(xiàn)故障宕機(jī)時(shí),需要手動(dòng)進(jìn)行恢復(fù),為了解決這個(gè)問題,Redis 增加了哨兵模式(因?yàn)樯诒J阶龅搅丝梢员O(jiān)控主從服務(wù)器,并且提供自動(dòng)容災(zāi)恢復(fù)的功能)。
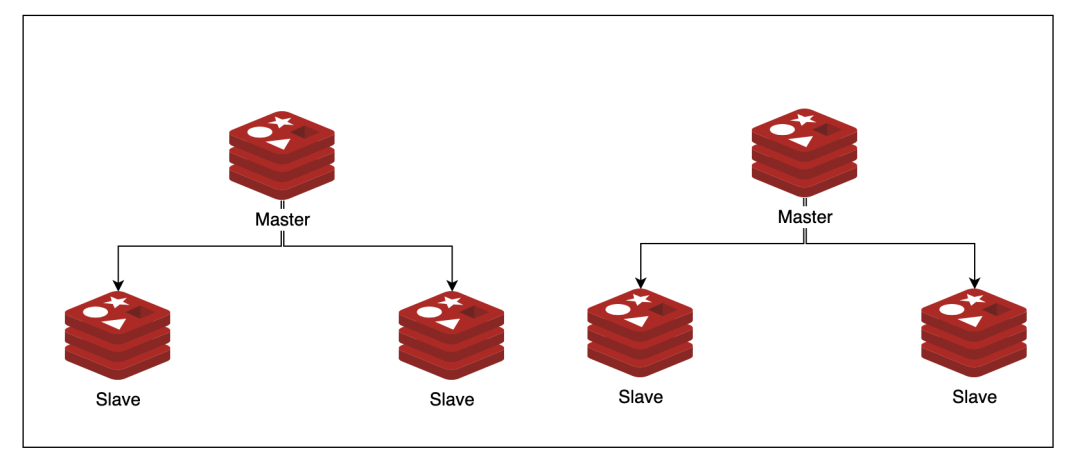
3)Redis Cluster(集群)
Redis Cluster 是一種分布式去中心化的運(yùn)行模式,是在 Redis 3.0 版本中推出的 Redis 集群方案,它將數(shù)據(jù)分布在不同的服務(wù)器上,以此來降低系統(tǒng)對單主節(jié)點(diǎn)的依賴,從而提高 Redis 服務(wù)的讀寫性能。
面試官:使用哨兵模式在數(shù)據(jù)上有副本數(shù)據(jù)做保證,在可用性上又有哨兵監(jiān)控,一旦 master 宕機(jī)會(huì)選舉 salve 節(jié)點(diǎn)為 master 節(jié)點(diǎn),這種已經(jīng)滿足了我們的生產(chǎn)環(huán)境需要,那為什么還需要使用集群模式呢?
小二:哨兵模式歸根節(jié)點(diǎn)還是主從模式,在主從模式下我們可以通過增加 salve 節(jié)點(diǎn)來擴(kuò)展讀并發(fā)能力,但是沒辦法擴(kuò)展寫能力和存儲(chǔ)能力,存儲(chǔ)能力只能是 master 節(jié)點(diǎn)能夠承載的上限。所以為了擴(kuò)展寫能力和存儲(chǔ)能力,我們就需要引入集群模式。
面試官:集群中那么多 Master 節(jié)點(diǎn),Redis Cluster 在存儲(chǔ)的時(shí)候如何確定選擇哪個(gè)節(jié)點(diǎn)呢?
小二:這應(yīng)該是使用了某種 hash 算法,但是我不太清楚。。。

面試官:那好,今天的面試就到這里吧,你先回去等我們的面試通知。
小二:好的,謝謝面試官,你能告訴我 Redis Cluster 怎么實(shí)現(xiàn)節(jié)點(diǎn)選擇的嗎?
面試官:
Redis Cluster 采用的是類一致性哈希算法實(shí)現(xiàn)節(jié)點(diǎn)選擇的,至于什么是一致性哈希算法你自己回去看看。
Redis Cluster 將自己分成了 16384 個(gè) Slot(槽位),哈希槽類似于數(shù)據(jù)分區(qū),每個(gè)鍵值對都會(huì)根據(jù)它的 key,被映射到一個(gè)哈希槽中,具體執(zhí)行過程分為兩大步。
1)根據(jù)鍵值對的 key,按照 CRC16 算法計(jì)算一個(gè) 16 bit 的值。
2)再用 16bit 值對 16384 取模,得到 0~16383 范圍內(nèi)的模數(shù),每個(gè)模數(shù)代表一個(gè)相應(yīng)編號的哈希槽。
每個(gè) Redis 節(jié)點(diǎn)負(fù)責(zé)處理一部分槽位,假如你有三個(gè) master 節(jié)點(diǎn) ABC,每個(gè)節(jié)點(diǎn)負(fù)責(zé)的槽位如下:
| 節(jié)點(diǎn) | 處理槽位 |
|---|---|
| A | 0-5000 |
| B | 5001 - 10000 |
| C | 10001 - 16383 |
這樣就實(shí)現(xiàn)了 cluster 節(jié)點(diǎn)的選擇。
好了,今天關(guān)于 Redis 的面試就到這里了,你們覺得如何,都能答對嗎?
本篇已收錄至 GitHub 上星標(biāo) 1.4k+ star 的開源專欄《Java 程序員進(jìn)階之路》,該專欄風(fēng)趣幽默、通俗易懂,對 Java 愛好者極度友好和舒適??,內(nèi)容包括但不限于 Java 基礎(chǔ)、Java 集合框架、Java IO、Java 并發(fā)編程、Java 虛擬機(jī)、Java 企業(yè)級開發(fā)(Git、SSM、Spring Boot)等核心知識點(diǎn)。
https://github.com/itwanger/toBeBetterJavaer
star 了這個(gè)倉庫就等于你擁有了成為了一名優(yōu)秀 Java 工程師的潛力。
「閱讀原文」可以跳轉(zhuǎn)到《Java 程序員進(jìn)階之路》的官網(wǎng)網(wǎng)址,開始愉快的學(xué)習(xí)之旅吧。

沒有什么使我停留——除了目的,縱然岸旁有玫瑰、有綠蔭、有寧靜的港灣,我是不系之舟。