
CUDA 并行計算優(yōu)化策略總結(jié)

極市導(dǎo)讀
?并行計算為了提高算法運行效率,本文通過以矩陣乘法(C = A * B)的各種實現(xiàn)思路以及優(yōu)化方法總結(jié)為例子,過一遍cuda的幾個基礎(chǔ)優(yōu)化策略。?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
本文脈絡(luò)
關(guān)于矩陣乘法的問題描述 關(guān)于矩陣乘法的問題描述
優(yōu)化策略的核心思想
例子
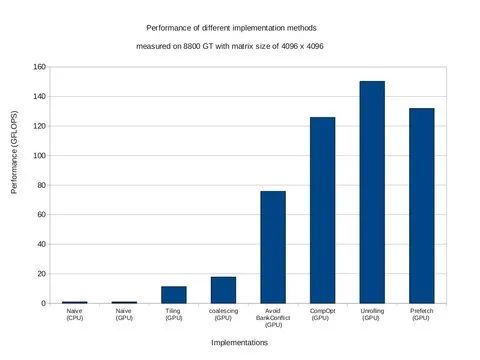
CPU上的代碼實現(xiàn):https://github.com/hova88/cuda-template/blob/main/src/matmul/naive.cu GPU上的代碼實現(xiàn):https://github.com/hova88/cuda-template/blob/main/src/matmul/naive.cu 優(yōu)化策略一:https://github.com/hova88/cuda-template/blob/main/src/matmul/tiling.cu 優(yōu)化策略二:https://github.com/hova88/cuda-template/blob/main/src/matmul/coalescing.cu 優(yōu)化策略三:No Bank Conflict 優(yōu)化策略四:https://github.com/hova88/cuda-template/blob/main/src/matmul/comopt.cu 優(yōu)化策略五:https://github.com/hova88/cuda-template/blob/main/src/matmul/unroll.cu 優(yōu)化策略六:Prefetching
1 關(guān)于矩陣乘法的問題描述
參照NVIDIA官網(wǎng)教程——https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
首先解決矩陣乘法問題更具體來說是解決GEMM(GEneral Matrix to Matrix Multiplication,通用矩陣乘法)問題。即C=αA*B+βC。其中A、B和C是矩陣。A是M×K矩陣,B是K×N矩陣,C是M×N矩陣。為了方便說明,后續(xù)的例子中假設(shè)標(biāo)量alpha=beta=1。
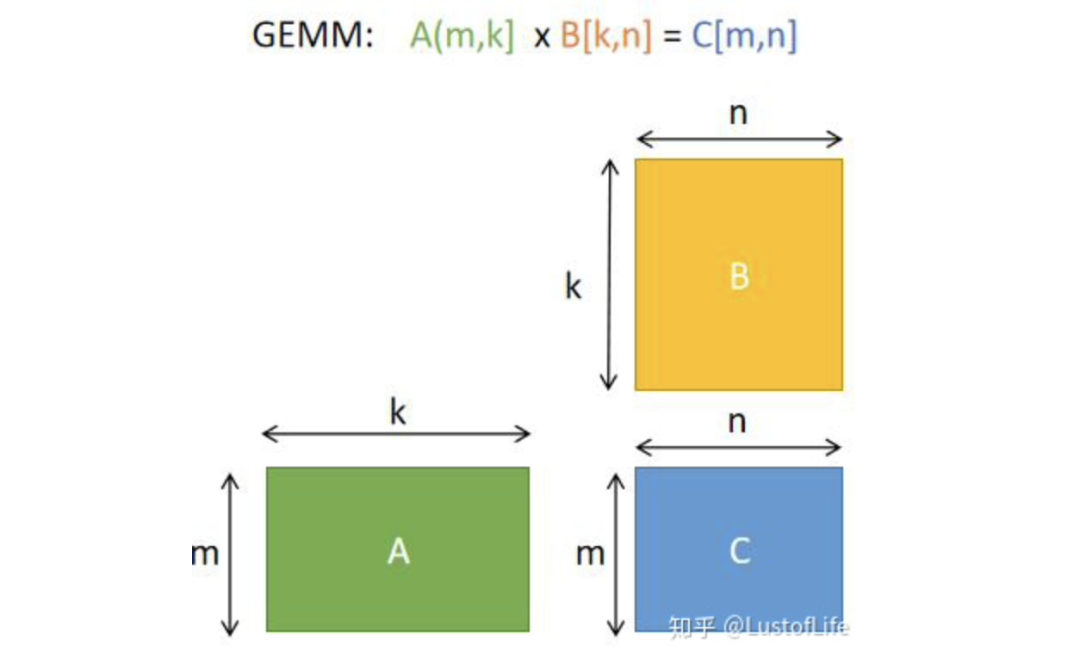
那么如何更高效的進(jìn)行GEMM呢?
2:優(yōu)化策略的核心思想
1.減小緩存(cached) 2.使寫入速度跟上指令的計算速度
對于GEMM計算,最直接的想法就是loop,elements相乘再相加
for?(int?i?=?0;?i?遍歷A的行,行id記做i
????for?(int?j?=?0;?j?遍歷B的列,列id記做j
???????for?(int?k?=?0;?k?在行列i,j確定的前提下,進(jìn)行對應(yīng)元素的?相乘?和?加和?,元素id記做k?
????????????C[i][j]?+=?A[i][k]?*?B[k][j];?????//---->最后輸出到C的第i,j個元素
對于M=N=K的大型方陣,矩陣乘積中的數(shù)學(xué)運算數(shù)為O(N^3),而所需的數(shù)據(jù)量為O(N^2),從而產(chǎn)生N階的計算強度。然而,利用理論計算強度(heoretical compute intensity)需要將重復(fù)使用每個元素O(N)。但是,上面的內(nèi)積算法依賴于緩存(fast on-chip caches)中保存一個大的工作集,這會導(dǎo)致隨著M、N和K增長時,CPU需要來回搬運數(shù)據(jù),會累的要死。(不符合減小緩存的思想)
PS:一般來說,求兩矩陣內(nèi)積,K的維度數(shù)要遠(yuǎn)大于N,M(例如SVM中的核函數(shù)技巧),所以將大計算量的K維放在內(nèi)循環(huán)不是一個聰明的決定。
一個更好的公式是通過構(gòu)造K維上的循環(huán)作為最外層的循環(huán)來置換循環(huán)嵌套。這種形式的計算一次加載a列和B行,計算其外積,并將此外積的結(jié)果累加到矩陣C中。此后,a列和B行的結(jié)果將不再使用。
for?(int?k?=?0;?k?????for?(int?i?=?0;?i?????????for?(int?j?=?0;?j?????????????C[i][j]?+=?A[i][k]?*?B[k][j];
更進(jìn)一步思考,如何進(jìn)一步減少寄存空間的緩存大小?
上述方法的一個問題是,它要求矩陣C的所有M-by-N元素都是激活的,以存儲每個乘法累加指令的結(jié)果。這樣很難保證內(nèi)存中的寫入速度能夠跟上CPU中的計算速度。
而如何去使得內(nèi)存的寫入速度與計算乘法累加指令的速度一樣快呢?
-- 采用分塊(Tile)的策略
重點來了,
首先 ,我們可以通過將矩陣C的工作空間Partitioning為大小為(M*tile-by-N*tile)的Tile來矩陣C的工作空間大小(the working set size of C), 這些Tile的大小需要與存儲器(on-chip memory)相適應(yīng)。
然后,我們將用外積代替內(nèi)積的策略應(yīng)用到每一塊Tile上。就像以下循環(huán)嵌套這樣。
for?(int?m?=?0;?m?????for?(int?n?=?0;?n?????????for?(int?k?=?0;?k??like?above?example
????????????for?(int?i?=?0;?i?????????????????for?(int?j?=?0;?j?????????????????????int?row?=?m?+?i;
????????????????????int?col?=?n?+?j;
????????????????????C[row][col]?+=?A[row][k]?*?B[k][col];
????????????????}
對于C上的每一塊Tile,都只取了一次A和B中的Tiles,使其達(dá)到*O(N)*的計算強度。示意圖就類似下面這樣。(如果對 global memory / shared memory / register file/ SM cores 不太清楚的話,還是建議好好研究研究一下,對后續(xù)的優(yōu)化策略理解很有幫助!)
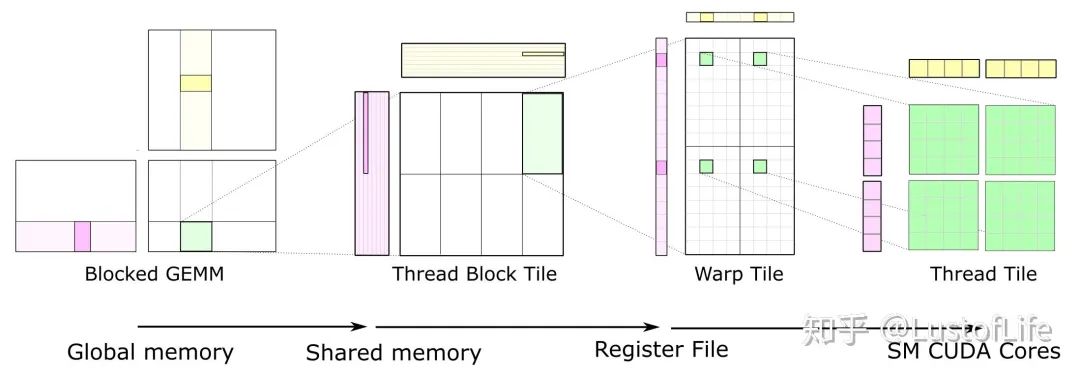
對于GPU來說,The size of each tile of C may be chosen to match the capacity of the L1 cache or registers of the target processor, and the outer loops of the nest may be trivially parallelized. This is a great improvement !
Here, you can see data movement from global memory to shared memory (matrix to thread block tile), from shared memory to the register file (thread block tile to warp tile), and from the register file to the CUDA cores for computation (warp tile to thread tile).
參考鏈接
Matrix Multiplication CUDA——https://ecatue.gitlab.io/gpu2018/pages/Cookbook/matrix_multiplication_cuda.html
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“transformer”獲取最新Transformer綜述論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
