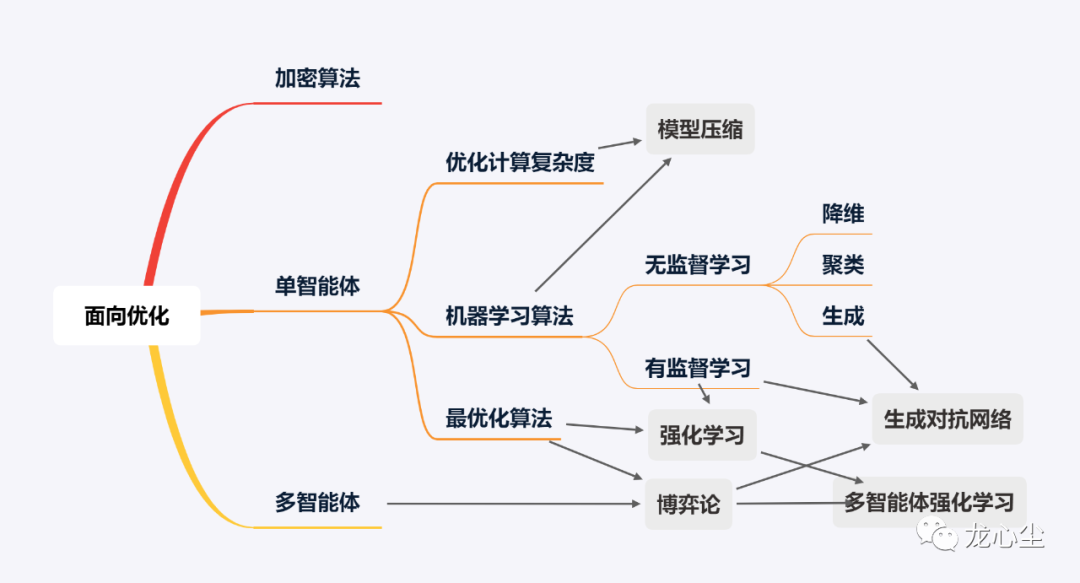
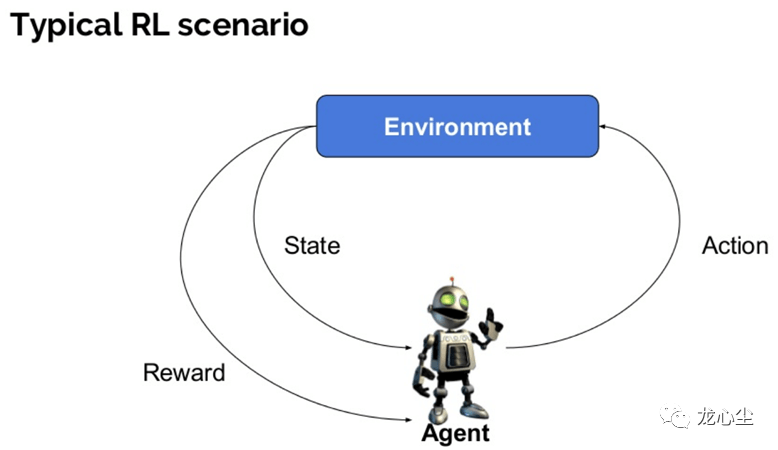
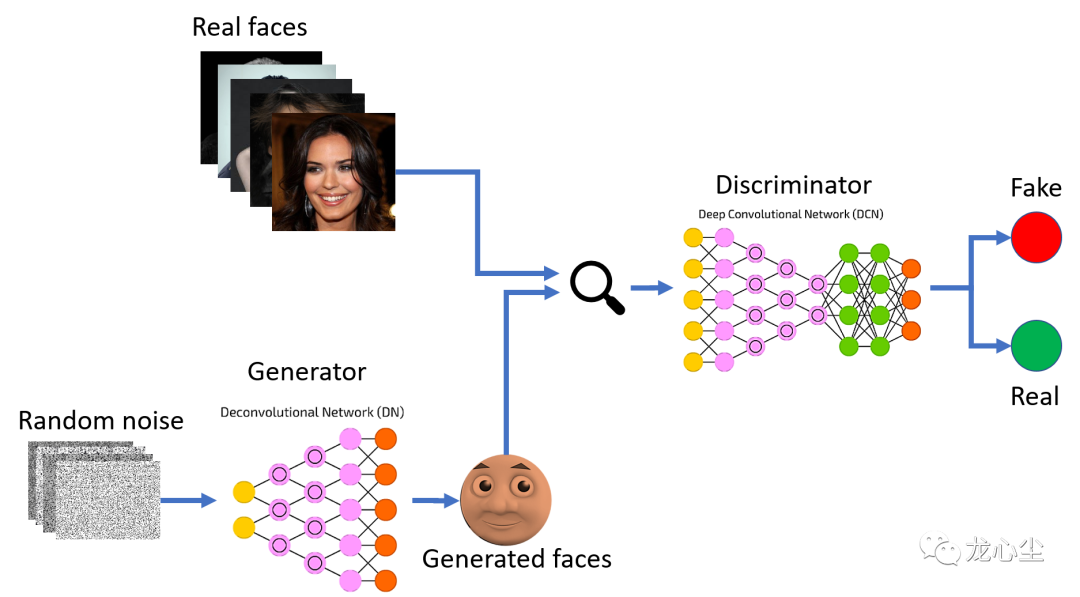
算法工程師到底是做什么的?大數(shù)據(jù)文摘關注共 2633字,需瀏覽 6分鐘 ·2021-02-02 10:38 大數(shù)據(jù)文摘授權轉(zhuǎn)載自龍心辰作者:龍心辰其實這是一個不太好解釋的問題,因為并沒有一個完備的定義。筆者在算法領域遇到了不少同行,發(fā)現(xiàn)各自的工作重點甚至思維方式都很不同。為了給入門的朋友一個清晰的梳理,這里就簡單串一串12個常見的算法。首先,全景圖鎮(zhèn)樓。01?算法與非算法的區(qū)別一般來說,可以把編程工作分為兩種,一種是面向?qū)崿F(xiàn)的,一種是面向優(yōu)化的。前者如實現(xiàn)一個功能、搭建一個服務、實現(xiàn)一種展現(xiàn)交互方式等。更關注的是如何實現(xiàn)功能,如何對于各種復雜甚至小眾的場景都不出錯。互聯(lián)網(wǎng)中典型的后端、前端、平臺、網(wǎng)絡工程師的主要工作是這一類。如果一些功能已經(jīng)實現(xiàn)了,你主要需要優(yōu)化它,那這類工作一般比較偏向算法。其中一個關鍵是你的優(yōu)化目標要是客觀可量化的。比如一些代碼優(yōu)化的工作是提升代碼的可維護性、可讀性和可擴展性。這個優(yōu)化目標具備比較強的主觀性,難以形成量化的指標,屬于設計模式主要關注的問題,一般不納入算法范疇。另一個區(qū)分算法與非算法工作的重要特征是一般涉及數(shù)學知識較多的編程工作更偏向算法。比如對于面向優(yōu)化的編程工作,為了很好地衡量可量化的目標,其數(shù)學定義往往比較明確,相應引入的數(shù)學知識會比較多。那么如果面向?qū)崿F(xiàn)的編程工作也依賴大量數(shù)學知識時是否算作算法呢?其中一個例子是可計算性理論,它涉及到可判定性問題、數(shù)理邏輯等問題都需要大量復雜的數(shù)學知識。這種情況下,它其實更關心何種問題原則上是否可用算法解決,在實際工程領域中并沒有大量的崗位與之相匹配,所以本文暫不將其納入算法工程師考慮的范圍。另一個例子是加密算法。加密算法的目標是保證數(shù)據(jù)的安全通信,保證其加密性、完整性和身份唯一確認。看起來是面向?qū)崿F(xiàn)的。但換一個視角,加密算法設計的指導思想是提高其解密成本,也可以算是面向優(yōu)化的。02?不同種類算法之間的區(qū)別如果你的優(yōu)化目標是要降低程序的時間復雜度與空間復雜度,它們都是能夠比較嚴格地量化定義的,就屬于經(jīng)典的“數(shù)據(jù)結(jié)構(gòu)與算法”中關注的“算法”的問題。LeetCode中大部分Algorithm的題目都屬于此類,也是互聯(lián)網(wǎng)面試中的高頻考點,如常見的分治、遞歸、動態(tài)規(guī)劃等。在實際工作中,特別是一些架構(gòu)師相關的角色,會著重關注這類問題,比如提升增刪改查的速度、降低其內(nèi)存消耗等。相應的數(shù)學理論是計算復雜性理論,依賴的數(shù)學知識包括離散數(shù)學、組合數(shù)學、圖論等。如果你的優(yōu)化目標是要降低在未見過的case上的預測誤差,這是典型的機器學習中的算法問題。這里面涉及到一些核心的概念,包括:泛化誤差、訓練誤差、過擬合、欠擬合、偏差等。相應的算法崗位非常多,圖像算法、語音算法、自然語言處理算法、搜索推薦算法等。機器學習算法還可以根據(jù)優(yōu)化目的的不同進行進一步的細分。如果訓練數(shù)據(jù)帶有標簽,優(yōu)化目標是降低預測標簽的誤差則是最常見的有監(jiān)督學習。如果訓練數(shù)據(jù)不帶標簽,則是無監(jiān)督學習。而如果此時又非要預測對應的標簽,則有降維和聚類兩種算法。如果僅僅是為了擬合訓練數(shù)據(jù)的分布,那就是生成式算法。機器學習算法的數(shù)學理論是計算學習理論,依賴的數(shù)學知識包括概率與統(tǒng)計、最優(yōu)化理論、線性代數(shù)與矩陣論等。當然,最優(yōu)化本身就是一種算法。稍微嚴格一點的表述是在一定的約束條件下控制自變量達到目標函數(shù)最優(yōu)的問題。最優(yōu)化問題也叫作運籌學,在工程界應用非常廣泛。典型的如外賣騎手調(diào)度、網(wǎng)約車調(diào)度、航班調(diào)度、物流路徑調(diào)度、廣告/補貼金額投放等。最優(yōu)化算法的種類也比較多,以自變量是否連續(xù)可分為連續(xù)最優(yōu)化和組合優(yōu)化。很多計算復雜度優(yōu)化算法可以看做一種廣義的組合優(yōu)化問題。機器學習算法一般是連續(xù)最優(yōu)化問題。03?不同算法思路的相互組合其他一些的高階算法可以理解為以上多種算法的組合。比如強化學習算法可以理解成有監(jiān)督學習算法與最優(yōu)化決策算法的組合。也就是智能體根據(jù)其對當前環(huán)境下長期最大收益進行決策(最優(yōu)化),而這個收益的函數(shù)是需要通過大量樣本統(tǒng)計(有監(jiān)督學習)才能得到,并且智能體的當下決策往往影響周圍的環(huán)境狀態(tài)進而進一步影響下一步自身的決策。其典型應用場景是基于用戶實時行為的個性化推薦與搜索,外賣騎手路徑優(yōu)化與訂單分配的在線優(yōu)化等。其實,“強人工智能”如果可行的話,強化學習是其繞不開的學習思路。以上介紹的優(yōu)化算法都是基于單智能體的,而博弈論就將其拓展到多個智能體的最優(yōu)化,視野一下就打開了。多個智能體的優(yōu)化策略是會相互影響的。也就是說它們各自基于自身的優(yōu)化函數(shù)進行優(yōu)化,并且各自的優(yōu)化行動可以影響其他智能體優(yōu)化策略的過程。博弈論算法典型的應用場景是拍賣競價策略。在ACG文化中的《大逃殺》、《賭博默示錄》、《彌留之國的愛麗絲》甚至《JOJO》等作品中都充滿了大量的博弈論場景。有一個小程序的游戲叫作《信任的進化》,簡單玩一下就能夠體會到博弈論的有趣之處。多智能體強化學習則是多個智能體的強化學習得到最優(yōu)策略,并且各自的最優(yōu)策略會影響對方智能體的下一步優(yōu)化策略的過程。或者理解成其認為博弈論收益函數(shù)是不確定的,需要對通過大量樣本統(tǒng)計(長期收益的有監(jiān)督學習)。典型的案例是AlphaGo、AlphaZero之類。生成對抗網(wǎng)絡(GANs)有點特殊,可以理解成有監(jiān)督學習與無監(jiān)督生成式算法的組合,前者(判別器)的優(yōu)化目標是降低生成樣本與真實樣本的區(qū)分難度,后者(生成器)的優(yōu)化目標是提升他們的區(qū)分難度。而這兩個目標是相互對立的,這又借鑒了博弈論的思路。這類算法在圖像生成、圖像修復、風格遷移等場景有非常多的應用。另外,模型壓縮算法可以理解成機器學算法與優(yōu)化計算復雜度算法組合,在一定的誤差容忍范圍下顯著降低模型的空間復雜度和推斷時間復雜度。其典型應用場景是模型的實時運算加速、邊緣部署壓縮等。04?小結(jié)一下這里主要從面向優(yōu)化的角度上串講了以下12種思維方式不同的算法:加密算法、計算復雜度優(yōu)化算法、最優(yōu)化算法、有監(jiān)督學習、無監(jiān)督學習(降維、聚類、生成)、強化學習、博弈論、多智能體強化學習、生成對抗網(wǎng)絡、模型壓縮算法等。因為是科普向,很多細節(jié)沒展開,特別是機器學習算法和優(yōu)化計算復雜度算法的各個流派沒有探討。我們將在接下來的文章中進行更加詳細的介紹。點「在看」的人都變好看了哦! 瀏覽 46點贊 評論 收藏 分享 手機掃一掃分享分享 舉報 評論圖片表情視頻評價全部評論推薦 【HTML】meta 標簽到底是做什么的前端自習課0入行必看:Java到底是做什么的?達內(nèi)JAVA培訓0真實!數(shù)據(jù)分析師到底是做什么的?接地氣學堂0meta標簽到底是做什么的|我竟一無所知程序員成長指北0meta 標簽到底是做什么的,我竟一無所知前端大學0meta標簽到底是做什么的,我竟一無所知Java技術迷0meta標簽到底是做什么的|我竟一無所知前端瓶子君0SRE 到底是干什么的??DevOps技術棧0meta標簽到底是做什么的,你真的了解嗎?web前端開發(fā)0人類學家是做什么的本書生動地介紹了在人類學研究中所采用的獨一無二的方法以及極富創(chuàng)意的想法,這些都擴大的人類學的研究范圍點贊 評論 收藏 分享 手機掃一掃分享分享 舉報



 下載APP
下載APP