
記錄一次生產(chǎn)環(huán)境中Redis內(nèi)存增長異常排查全流程!

作者:z小趙
★?一枚用心堅(jiān)持寫原創(chuàng)的“無趣”程序猿,在自身受益的同時(shí)也讓朋友們?cè)诩夹g(shù)上有所提升。
最近 DBA 反饋線上的一個(gè) Redis 資源已經(jīng)超過了預(yù)先設(shè)計(jì)時(shí)的容量,并且已經(jīng)進(jìn)行了兩次擴(kuò)容,內(nèi)存增長還在持續(xù)中,希望業(yè)務(wù)方排查一下容量增長是否正常,若正常則期望重新評(píng)估資源的使用情況,若不正常請(qǐng)盡快查明問題并給出解決方案進(jìn)行處理。
問題現(xiàn)象
下面是當(dāng)時(shí)資源容量使用和 key 數(shù)量的監(jiān)控情況:
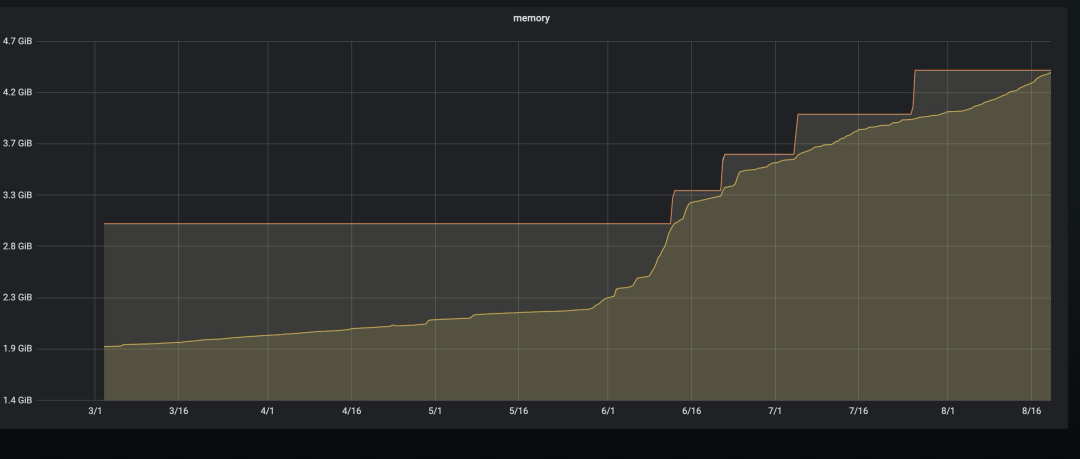
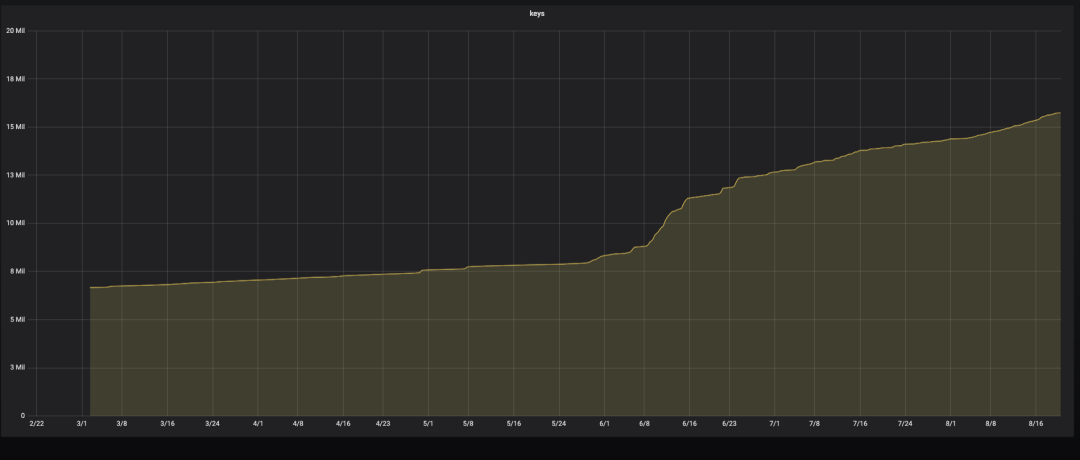
從監(jiān)控可以看出,6.1 號(hào)開始容量和 keys 的增長陡增。首先懷疑是有惡意刷量的操作導(dǎo)致 key 數(shù)量增加比較多,經(jīng)過代碼排查后發(fā)現(xiàn),確實(shí)有代碼漏洞導(dǎo)致可以惡意刷量,后經(jīng)過 bug 修復(fù)后上線。你以為到這里就完事了?天真,要不然寫這篇文章還有什么用?
但是從接口的請(qǐng)求量來看的話,刷量的情況并沒有那么明顯,下面是接口請(qǐng)求的 qps:

繼續(xù)排查存儲(chǔ)設(shè)計(jì)發(fā)現(xiàn),存儲(chǔ)使用了 Set 結(jié)構(gòu)(由于產(chǎn)品最開始沒有明確說明一個(gè) key 下存儲(chǔ)多少元素,所以采用了 Set,這也為后續(xù)容量異常增長打下了 堅(jiān)實(shí)的基礎(chǔ) ),實(shí)際每個(gè) Set 中只存儲(chǔ)了一個(gè)元素,但實(shí)際容量卻增長了 30M,根據(jù)容量計(jì)算公式 9w * 14(key 長度) * 1(元素個(gè)數(shù)) * 10(元素長度)= 8.4M,實(shí)際容量卻超出了近 4 倍。
到此,產(chǎn)生了兩個(gè)懷疑點(diǎn),其一:實(shí)際存儲(chǔ)的數(shù)據(jù)占用內(nèi)存大小有問題,其二:容量評(píng)估公式有問題。
疑點(diǎn)一:實(shí)際存儲(chǔ)的數(shù)據(jù)占用內(nèi)存大小有問題
查看 Redis 的 Set 底層存儲(chǔ)結(jié)構(gòu)發(fā)現(xiàn),Set 集合采用了整數(shù)集合和字典兩種方式來實(shí)現(xiàn)的,當(dāng)滿足如下兩個(gè)條件的時(shí)候,采用整數(shù)集合實(shí)現(xiàn);一旦有一個(gè)條件不滿足時(shí)則采用字典來實(shí)現(xiàn)。
Set 集合中的所有元素都為整數(shù) Set 集合中的元素個(gè)數(shù)不大于 512(默認(rèn) 512,可以通過修改 set-max-intset-entries 配置調(diào)整集合大小)
關(guān)于詳細(xì)內(nèi)容,可以查看作者寫過的這篇內(nèi)容:連底層存儲(chǔ)你都不知道,敢說 Redis 用的很溜
排查到這里,按照正常情況的話,其應(yīng)該采用的是整數(shù)集合存儲(chǔ)的才對(duì)啊,但是登陸到機(jī)器上,使用 memory usage key 命令查看內(nèi)存的使用情況發(fā)現(xiàn),單個(gè) key 的內(nèi)存占用竟然達(dá)到了 218B :

是不是覺得不可思議,只是存儲(chǔ)一個(gè) 10 位的數(shù)據(jù)且內(nèi)容是數(shù)字,為什么會(huì)占用這么大的內(nèi)存呢?
到此我們開始懷疑是不是序列化的方式有問題導(dǎo)致實(shí)際寫入 Redis 的內(nèi)容不是一個(gè)數(shù)字,所以接著查數(shù)據(jù)實(shí)際寫入時(shí)用的序列化方式。經(jīng)過排查發(fā)現(xiàn)寫入的 value 被序列化以后變成了一個(gè)十六進(jìn)制的數(shù)據(jù),到這里這個(gè)疑點(diǎn)基本就真相大白了,因?yàn)榇藭r(shí) Redis 認(rèn)為存儲(chǔ)的內(nèi)容已經(jīng)不適用于整數(shù)集合存儲(chǔ)了,而改為字典存儲(chǔ)。將序列化方式修改以后,測(cè)試添加一個(gè)元素進(jìn)去,發(fā)現(xiàn)實(shí)際內(nèi)存占用只有 72B,縮減為原來的 1/3:

疑點(diǎn)二:容量評(píng)估公式有問題
容量評(píng)估公式忽略了 Redis 對(duì)于不同的情況下內(nèi)存的占用情況,統(tǒng)一按照元素的大小去計(jì)算,導(dǎo)致實(shí)際內(nèi)容占用過小。
到此,整個(gè) Redis 內(nèi)存容量增長異常基本上可以告一段路了,接下來就是修改正確的序列化和反序列化方式,然后進(jìn)行洗庫操作,經(jīng)業(yè)務(wù)調(diào)查發(fā)現(xiàn),目前的實(shí)際使用方式可以改為 KV 結(jié)構(gòu),所以將底層存儲(chǔ)進(jìn)行了改造。
洗庫流程介紹
上線雙寫邏輯 同步歷史數(shù)據(jù) 切換讀取新數(shù)據(jù)源 觀察線上業(yè)務(wù)是否正常 關(guān)閉舊存儲(chǔ)的寫入 刪除舊資源 下線舊的讀寫邏輯
關(guān)于新數(shù)據(jù)的存儲(chǔ)位置有兩種選擇,
第一種方式是:舊數(shù)據(jù)正常寫舊資源,新數(shù)據(jù)寫到新部署的資源下。此種方式的優(yōu)點(diǎn)是,將舊數(shù)據(jù)全量洗入新資源后,然后下線舊資源就可以了;缺點(diǎn)是,需要在代碼層重新寫一套到資源的配置,DBA 也需要新部署一個(gè)資源。 第二種方式是:新舊數(shù)據(jù)都寫到舊資源里面,然后將舊數(shù)據(jù)映射到新數(shù)據(jù)結(jié)構(gòu)上,然后全量洗入舊資源。此種方式的優(yōu)點(diǎn)是,不需要重新寫一套到資源的配置,DBA 也不需要新部署資源,只需要將舊資源的內(nèi)存進(jìn)行擴(kuò)容操作即可;缺點(diǎn)是,全量數(shù)據(jù)洗入完成后,需要手動(dòng)剔除舊數(shù)據(jù)。
兩種方案都可行,可以根據(jù)自己的喜好來選擇,我們最終選擇了第二種方案進(jìn)行數(shù)據(jù)清洗操作。
上線雙寫邏輯
在資源存儲(chǔ)層,對(duì)上下行讀寫操作分別增加 switcher(開關(guān)),然后增加讀寫新存儲(chǔ)的邏輯,代碼測(cè)試通過后上線。
這一步的流程在于開關(guān),可以選擇熱部署的任何方式來修改標(biāo)志位,從而控制代碼流程的執(zhí)行,另外需要注意的一點(diǎn)是:開關(guān)狀態(tài)的修改不能被工程上下線所影響。
同步歷史數(shù)據(jù)
上線完成后,導(dǎo)出線上庫的 RDB 文件,解析出所有 key(關(guān)于 RDB 文件的解析,如果有專門的 DBA 同事,可以讓 DBA 同事給解析好,如果沒有的話,可以自己在網(wǎng)上查查 RDB 文件解析的工具,也不是很難);依次遍歷解析出來的 key,查詢 key 對(duì)應(yīng)的舊數(shù)據(jù),將舊數(shù)據(jù)映射到新數(shù)據(jù)結(jié)構(gòu)下,最后寫入到新的存儲(chǔ)下。
關(guān)于同步歷史數(shù)據(jù),需要根據(jù)自身實(shí)際的業(yè)務(wù)場(chǎng)景去做適當(dāng)?shù)恼{(diào)整,這里只提供一個(gè)思路。下面是洗數(shù)據(jù)可以使用的小工具,需要的朋友可以適當(dāng)調(diào)整代碼邏輯就可以使用了:
public class fixData {
public static void main(String[] args) {
String fileName = "test.txt";
int rate = 500;
int size = 200;
if (args != null) {
fileName = args[0];
rate = Integer.parseInt(args[1]);
size = Integer.parseInt(args[2]);
}
RateLimiter rateLimiter = RateLimiter.create(rate);
ThreadPoolExecutor executorService = new ThreadPoolExecutor(size, size, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue());
executorService.prestartAllCoreThreads();
try {
FileReader fr = new FileReader(fileName);
LineNumberReader br = new LineNumberReader(fr);
String line;
while ((line = br.readLine()) != null) {
try {
rateLimiter.acquire();
executorService.submit(() -> {
// TODO 編寫自己的數(shù)據(jù)處理邏輯
});
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
}
切換讀取新數(shù)據(jù)源
歷史所以數(shù)據(jù)同步完成后,將讀操作的開關(guān)關(guān)閉,讓其走讀新存儲(chǔ)的邏輯
這一步需要注意的是,此時(shí)只修改下行讀取數(shù)據(jù)的開關(guān)狀態(tài),讓其讀取新數(shù)據(jù)源,上行寫入數(shù)據(jù)開關(guān)不動(dòng),依舊讓其進(jìn)行雙寫操作,防止下行切到新數(shù)據(jù)源有問題需要回滾導(dǎo)致新舊數(shù)據(jù)不一致的尷尬情況發(fā)生。
觀察線上業(yè)務(wù)是否正常
切到讀新存儲(chǔ)的邏輯下,觀察線上業(yè)務(wù),有無用戶投訴數(shù)據(jù)異常的情況
關(guān)閉就存儲(chǔ)的寫入
線上業(yè)務(wù)無異常情況,將寫操作也切到只寫新存儲(chǔ)的邏輯下,停止舊資源的寫入
刪除舊資源
將寫上所有舊 key 全部剔除,剔除舊數(shù)據(jù)的操作方式可以復(fù)用洗數(shù)據(jù)的流程即可。
下線舊的讀寫邏輯
將線上就的讀寫邏輯代碼全部下線,最終完成整個(gè)數(shù)據(jù)清洗的全流程
總結(jié)
以上,是一次完整的真實(shí)生產(chǎn)環(huán)境中問題排查及數(shù)據(jù)清洗全過程,通過本次問題的排查,也進(jìn)一步加深了對(duì) Redis 的底層實(shí)現(xiàn)的認(rèn)識(shí)和理解;
同時(shí),透過本次事故需要我們反思的是,面對(duì)親手寫下的每一行代碼,都需要懷著一顆敬畏心理,永遠(yuǎn)不要輕視,有可能一個(gè)不小心就會(huì)釀成一個(gè)災(zāi)難性的事故。文章到此就先告一段落了,但是排查問題的腳步還在繼續(xù),歡迎關(guān)注我學(xué)習(xí)更多有干貨的知識(shí)。