
Kylin、Druid、ClickHouse核心技術(shù)對(duì)比
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




導(dǎo)讀 Kylin、Druid、ClickHouse 是目前主流的 OLAP 引擎,本文嘗試從數(shù)據(jù)模型和索引結(jié)構(gòu)兩個(gè)角度,分析這幾個(gè)引擎的核心技術(shù),并做簡單對(duì)比。在閱讀本文之前希望能對(duì) Kylin、Druid、ClickHouse 有所理解。
Kylin 數(shù)據(jù)模型
Kylin 的數(shù)據(jù)模型本質(zhì)上是將二維表(Hive 表)轉(zhuǎn)換為 Cube,然后將 Cube 存儲(chǔ)到 HBase 表中,也就是兩次轉(zhuǎn)換。
第一次轉(zhuǎn)換,其實(shí)就是傳統(tǒng)數(shù)據(jù)庫的 Cube 化,Cube 由 CuboId 組成,下圖每個(gè)節(jié)點(diǎn)都被稱為一個(gè) CuboId,CuboId 表示固定列的數(shù)據(jù)數(shù)據(jù)集合,比如“ AB” 兩個(gè)維度組成的 CuboId 的數(shù)據(jù)集合等價(jià)于以下 SQL 的數(shù)據(jù)集合:
select A, B, sum(M), sum(N) from table group by A, B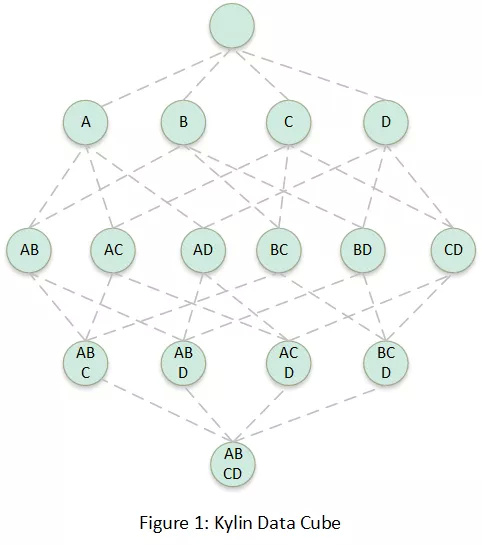
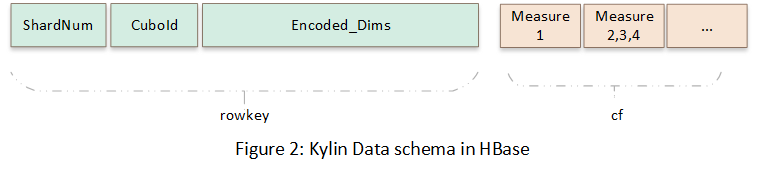
第二次轉(zhuǎn)換,是將 Cube 中的數(shù)據(jù)存儲(chǔ)到 HBase 中,轉(zhuǎn)換的時(shí)候 CuboId 和維度信息序列化到 rowkey,度量列組成列簇。在轉(zhuǎn)換的時(shí)候數(shù)據(jù)進(jìn)行了預(yù)聚合。下圖展示了 Cube 數(shù)據(jù)在 HBase 中的存儲(chǔ)方式。
Kylin 索引結(jié)構(gòu)
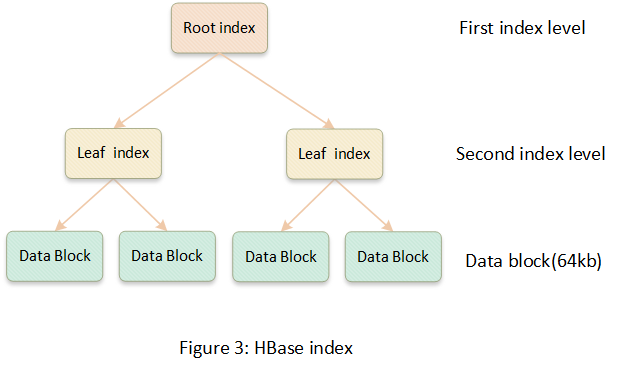
因?yàn)?Kylin 將數(shù)據(jù)存儲(chǔ)到 HBase 中,所以 kylin 的數(shù)據(jù)索引就是 HBase 的索引。HBase 的索引是簡化版本的 B+樹,相比于 B+樹,HFile 沒有對(duì)數(shù)據(jù)文件的更新操作。
HFile 的索引是按照 rowkey 排序的聚簇索引,索引樹一般為二層或者三層,索引節(jié)點(diǎn)比 MySQL 的 B+樹大,默認(rèn)是 64KB。數(shù)據(jù)查找的時(shí)候通過樹形結(jié)構(gòu)定位到節(jié)點(diǎn),節(jié)點(diǎn)內(nèi)部數(shù)據(jù)是按照 rowkey 有序的,可以通過二分查找快速定位到目標(biāo)。
Kylin 小結(jié):適用于聚合查詢場(chǎng)景;因?yàn)閿?shù)據(jù)預(yù)聚合,Kylin 可以說是最快的查詢引擎(group-by 查詢這樣的復(fù)雜查詢,可能只需要掃描 1 條數(shù)據(jù));kylin 查詢效率取決于是否命中 CuboId,查詢波動(dòng)較大;HBase 索引有點(diǎn)類似 MySQL 中的聯(lián)合索引,維度在 rowkey 中的排序和查詢維度組合對(duì)查詢效率影響巨大;所以 Kylin 建表需要業(yè)務(wù)專家參與。
Druid 數(shù)據(jù)模型
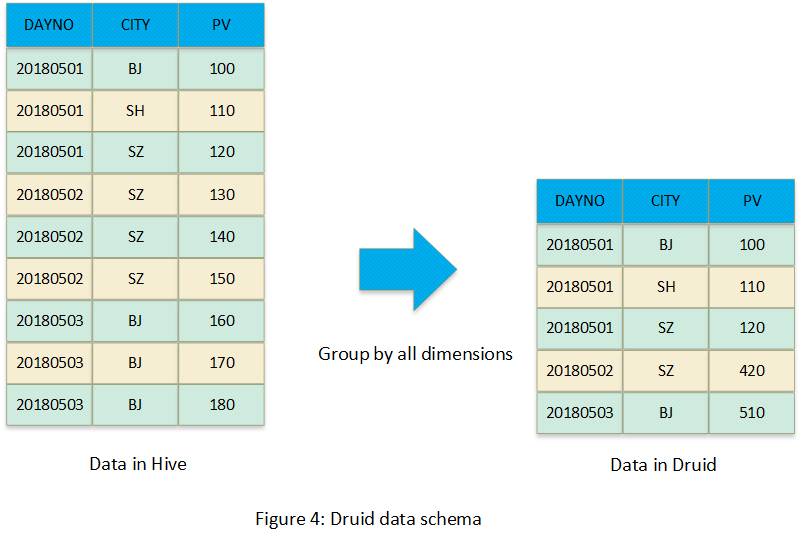
Druid 數(shù)據(jù)模型比較簡單,它將數(shù)據(jù)進(jìn)行預(yù)聚合,只不過預(yù)聚合的方式與 Kylin 不同,kylin 是 Cube 化,Druid 的預(yù)聚合方式是將所有維度進(jìn)行 Group-by,可以參考下圖:
Druid 索引結(jié)構(gòu)
Druid 索引結(jié)構(gòu)使用自定義的數(shù)據(jù)結(jié)構(gòu),整體上它是一種列式存儲(chǔ)結(jié)構(gòu),每個(gè)列獨(dú)立一個(gè)邏輯文件(實(shí)際上是一個(gè)物理文件,在物理文件內(nèi)部標(biāo)記了每個(gè)列的 start 和 offset)。對(duì)于維度列設(shè)計(jì)了索引,它的索引以 Bitmap 為核心。下圖為“city”列的索引結(jié)構(gòu):
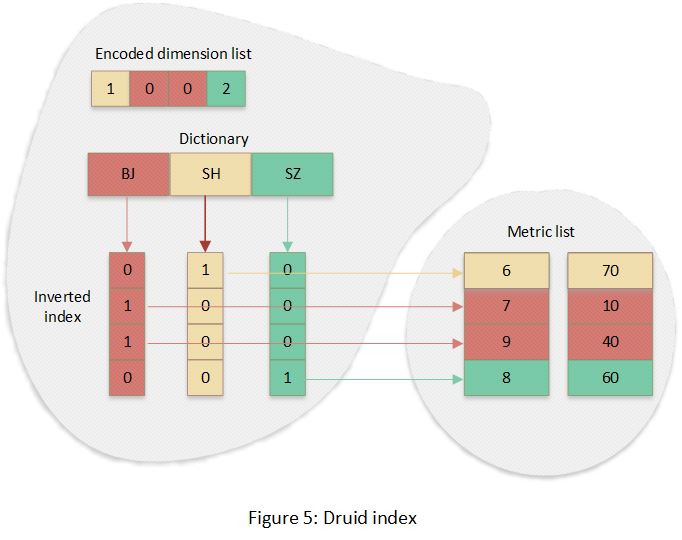
首先將該列所有的唯一值排序,并生成一個(gè)字典,然后對(duì)于每個(gè)唯一值生成一個(gè) Bitmap,Bitmap 的長度為數(shù)據(jù)集的總行數(shù),每個(gè) bit 代表對(duì)應(yīng)的行的數(shù)據(jù)是否是該值。Bitmap 的下標(biāo)位置和行號(hào)是一一對(duì)應(yīng)的,所以可以定位到度量列,Bitmap 可以說是反向索引。同時(shí)數(shù)據(jù)結(jié)構(gòu)中保留了字典編碼后的所有列值,其為正向的索引。
那么查詢?nèi)绾问褂盟饕兀恳砸韵虏樵優(yōu)槔?/p>
select site, sum(pv) from xx where date=2020-01-01 and city='bj' group by sitecity列中二分查找dictionary并找到’bj’對(duì)應(yīng)的bitmap
遍歷city列,對(duì)于每一個(gè)字典值對(duì)應(yīng)的bitmap與’bj’的bitmap做與操作
每個(gè)相與后的bitmap即為city='bj’查詢條件下的site的一個(gè)group的pv的索引
通過索引在pv列中查找到相應(yīng)的行,并做agg
后續(xù)計(jì)算
Druid 小結(jié):Druid 適用于聚合查詢場(chǎng)景但是不適合有超高基維度的場(chǎng)景;存儲(chǔ)全維度 group-by 后的數(shù)據(jù),相當(dāng)于只存儲(chǔ)了 KYLIN Cube 的 Base-CuboID;每個(gè)維度都有創(chuàng)建索引,所以每個(gè)查詢都很快,并且沒有類似 KYLIN 的巨大的查詢效率波動(dòng)。
ClickHouse 索引結(jié)構(gòu) (只討論 MergeTree 引擎)
因?yàn)?Clickhouse 數(shù)據(jù)模型就是普通二維表,這里不做介紹,只討論索引結(jié)構(gòu)。整體上 Clickhouse 的索引也是列式索引結(jié)構(gòu),每個(gè)列一個(gè)文件。Clickhouse 索引的大致思路是:首先選取部分列作為索引列,整個(gè)數(shù)據(jù)文件的數(shù)據(jù)按照索引列有序,這點(diǎn)類似 MySQL 的聯(lián)合索引;其次將排序后的數(shù)據(jù)每隔 8192 行選取出一行,記錄其索引值和序號(hào),注意這里的序號(hào)不是行號(hào),序號(hào)是從零開始并遞增的,Clickhouse 中序號(hào)被稱作 Mark’s number;然后對(duì)于每個(gè)列(索引列和非索引列),記錄 Mark’s number 與對(duì)應(yīng)行的數(shù)據(jù)的 offset。
下圖中以一個(gè)二維表(date, city, action)為例介紹了整個(gè)索引結(jié)構(gòu),其中(date,city)是索引列。
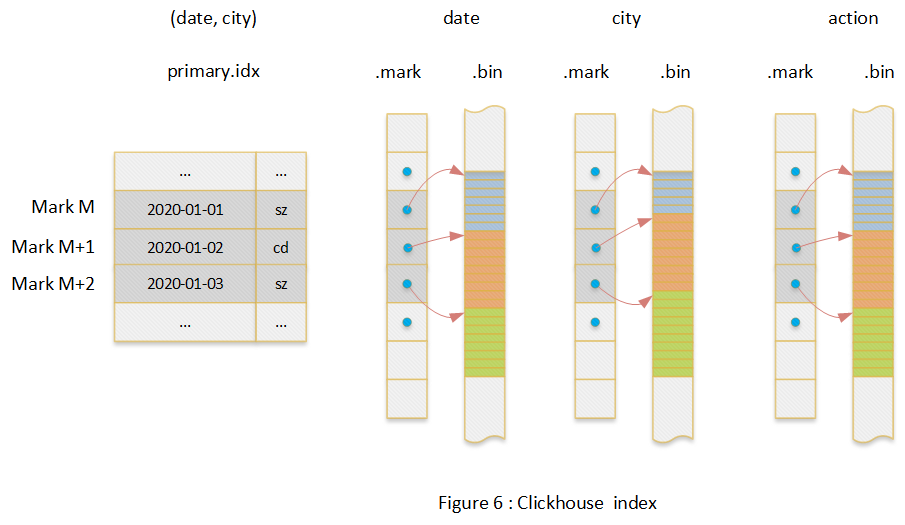
那么查詢?nèi)绾问褂盟饕兀恳砸韵虏樵優(yōu)槔?/p>
select count(distinct action) where date=toDate(2020-01-01) and city=’bj’二分查找primary.idx并找到對(duì)應(yīng)的mark’s number集合(即數(shù)據(jù)block集合)
在上一步驟中的 block中,在date和city列中查找對(duì)應(yīng)的值的行號(hào)集合,并做交集,確認(rèn)行號(hào)集合
將行號(hào)轉(zhuǎn)換為mark’s number 和 offset in block(注意這里的offset以行為單位而不是byte)
在action列中,根據(jù)mark’s number和.mark文件確認(rèn)數(shù)據(jù)block在bin文件中的offset,然后根據(jù)offset in block定位到具體的列值。
后續(xù)計(jì)算
該實(shí)例中包含了對(duì)于列的正反兩個(gè)方向的查找過程。反向:查找 date=toDate(2020-01-01) and city=’bj’數(shù)據(jù)的行號(hào);正向:根據(jù)行號(hào)查找 action 列的值。對(duì)于反向查找,只有在查找條件匹配最左前綴的時(shí)候,才能剪枝掉大量數(shù)據(jù),其它時(shí)候并不高效。
Clickhouse 小結(jié):MergeTree Family 作為主要引擎系列,其中包含適合明細(xì)數(shù)據(jù)的場(chǎng)景和適合聚合數(shù)據(jù)的場(chǎng)景;Clickhouse 的索引有點(diǎn)類似 MySQL 的聯(lián)合索引,當(dāng)查詢前綴元組能命中的時(shí)候效率最高,可是一旦不能命中,幾乎會(huì)掃描整個(gè)表,效率波動(dòng)巨大;所以建表需要業(yè)務(wù)專家,這一點(diǎn)跟 kylin 類似。
06 小結(jié)
Kylin、Druid只適合聚合場(chǎng)景,ClickHouse適合明細(xì)和聚合場(chǎng)景
聚合場(chǎng)景,查詢效率排序:Kylin > Druid > ClickHouse
Kylin、ClickHouse建表都需要業(yè)務(wù)專家參與
Kylin、ClickHouse查詢效率都可能產(chǎn)生巨大差異
ClickHouse在向量化方面做得的最好,Druid少量算子支持向量化、Kylin目前還不支持向量化計(jì)算。


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??