
數(shù)據(jù)倉庫實踐-拉鏈表設計
1 寫在開頭的話
拉鏈表,學名叫緩慢變化維(Slowly Changing Dimensions),簡稱漸變維(SCD),俗稱拉鏈表,是為了記錄關鍵字段的歷史變化而設計出來的一種數(shù)據(jù)存儲模型,常見于維度表設計,在數(shù)據(jù)倉庫相關的面試中,也經(jīng)常有被問到。但是在工程實踐中,拉鏈表真是太麻煩了,而且是在模型設計、初始化、ETL 開發(fā)、運維、日常取數(shù)等各個環(huán)節(jié)都很麻煩,而麻煩的設計通常都容易出錯,或者對團隊成員能力要求高些。
使用拉鏈表,需要考慮的問題很多,我先簡單列幾個,大家可以先思考下,真的必須用拉鏈表嗎?
新建的拉鏈表,歷史數(shù)據(jù)要不要補充;
新建的拉鏈表,主鍵怎么設置,需要引入代理鍵嗎;
構建好的拉鏈表,更新的時候只能逐天往后計算,中間有一天計算錯誤,后續(xù)的都得重刷;
運維的時候,更新的時候如果部分數(shù)據(jù) update 錯誤,如何更正?
關系型數(shù)據(jù)庫還好可以 update,那大數(shù)據(jù)環(huán)境下呢,如何處理增量數(shù)據(jù)?
使用的時候,什么時候取最新快照,什么時候取歷史某一時刻的數(shù)據(jù)?
使用的時候,事實表關聯(lián)拉鏈表,join 該怎么寫,會不會寫錯?
2 先分享一篇類似的文章
漫談數(shù)據(jù)倉庫之拉鏈表(原理、設計以及在Hive中的實現(xiàn))
https://blog.csdn.net/zhaodedong/article/details/54177686
上邊是木東居士在前些年分享在 CSDN 的一篇文章,目前已有 3.9 萬瀏覽。寫的非常棒,思路清晰、簡單易懂,也是是網(wǎng)絡上流傳的常規(guī)拉鏈表設計思路。
3 對于變化數(shù)據(jù)的處理方案
我們常說,數(shù)據(jù)模型設計一定要切合實際業(yè)務需求。對于變化數(shù)據(jù)的處理,常見需求有以下三種:
需求一:保護第一個值
在廣告投放的業(yè)務場景中,有個很重要的概念叫廣告歸因,這就是一個典型的必須保護第一個值的案例。就是說一個安裝歸屬到渠道 1 后,就應該永遠綁定在該渠道上。
該需求實現(xiàn)最簡單,只需要追加新數(shù)據(jù)就好了。
需求二:保留最新值
當我們不需要記錄歷史變化的時候,就可以只保留最新值。比如用戶修改了出生日期,有可能之前給的是系統(tǒng)默認值。
該需求處理會稍微復雜,需要 update 用戶維表,同時如果有對于用戶年齡相關的分析,還要重刷相關的事實表數(shù)據(jù)。
需求三:記錄歷史變化
我們需要回溯主體歷史某一時點的狀態(tài)的時候,就必須記錄歷史變化了。比如某一天,某業(yè)務員轉崗了,那么部門業(yè)績月度匯總的時候,就需要知道該業(yè)務員過去在哪些部門待過以及起始日期。
需求三處理起來比較麻煩,方案如下:
方案一:每天記錄一份快照,快照在木東居士文章里稱為切片。
方案二:增加新的列,比如只需要存最近 3 次變化,那么我們新增三列就好了。
方案三:增加新的行,核心屬性變化一次,新增一條,同時新增 2 列(數(shù)據(jù)開始日期、數(shù)據(jù)截止日期)。
方案一:
好處是寫入和查詢特別方便。但如果數(shù)據(jù)量巨大,數(shù)倉場景,您至少得存三年吧,由此帶來存儲、計算成本,都將是非常巨大的。
互聯(lián)網(wǎng)時代的快餐模式,大家都沒時間建模了,同時主流大數(shù)據(jù)數(shù)倉組件基本不支持 Update ,或者目前的存儲還吃的消,又或者數(shù)據(jù)量沒那么大,因此該方案被采用的還是比多的。
方案二:? ? ?
對于某些特定的使用場景,該方案還是蠻香的。再次強調,數(shù)據(jù)開發(fā)者一定要懂業(yè)務,許多技術上實現(xiàn)非常復雜的,換一種業(yè)務角度會簡單太多了,
方案三:? ? ? ? ? ?
這是多數(shù)人都能想到的處理思路,即拉鏈表。適用場景必須是緩慢變化,例如一張表有 10 億數(shù)據(jù),每天變化的只有幾萬、幾十萬才能稱為緩慢變化,反之如果 10 億的表每天有 7 億都會發(fā)生變化,那這還適合用拉鏈表嗎?
拉鏈表的優(yōu)點是,相對于快照表可以極大的節(jié)省存儲空間,缺點也很明顯就是太麻煩了。
4 實現(xiàn)方法
大數(shù)據(jù)數(shù)倉不支持 Update ,因此跟傳統(tǒng)數(shù)倉實現(xiàn)還是有區(qū)別的。(當然這是個偽命題,因為 ODPS 從 2021 年 3 月份已經(jīng)開始支持 Update,雖然是試用階段但未來可期。)
另外,有些需求,純 SQL 實現(xiàn)確實很難。大家不要太迷戀 SQL,時代不同了,拉鏈表的計算,有時候寫 MR 反而更容易理解。有時候多寫幾個 UDF、UDAF、UDTF,SQL 寫起來反而更方便、執(zhí)行效率反而會更好。
4.1 數(shù)據(jù)模型設計-傳統(tǒng)數(shù)倉設計方案
因為數(shù)量不大,通常也就幾萬幾十萬的數(shù)據(jù)量,業(yè)務系統(tǒng)和數(shù)倉 ODS 層也不太需要啟用數(shù)據(jù)刪除策略。因此不用考慮分區(qū)設計。
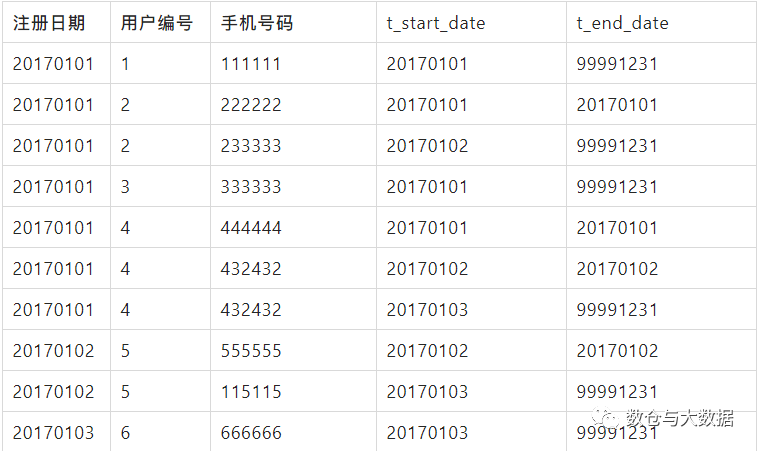
4.2 數(shù)據(jù)模型設計-大數(shù)據(jù)數(shù)倉設計方案
網(wǎng)絡上分享出來的文章,還是沿用關系型數(shù)據(jù)的模型設計思路。所有數(shù)據(jù)都放一個分區(qū)或者干脆不建分區(qū),往往會帶來一系列問題。比如:
隨著存儲時間的拉長,這張表勢必會越來越大,查詢效率會越來越底,然而大部分查詢場景只需要查詢快照或者最近一段時間的歷史變化。
如果某次更新,由于誤操作造成拉鏈表數(shù)據(jù)錯誤,已經(jīng)存放五年歷史變化的拉鏈表該怎么恢復?存儲備份肯定是不可能的,如果我們每次都將全量數(shù)據(jù)寫入新的分區(qū),至少得存近三天的全量拉鏈表數(shù)據(jù)吧?這又會帶來存儲空間的消耗。
例如,
有這么一個場景,需要存儲 SDK 上報的手機硬件信息,主鍵是設備 ID,關鍵的設備屬性大概 30 個,設備數(shù)量 40 億,在只存儲一份快照的情況下,需占用 400 G 存儲空間,一開始用的是快照表方式,考慮存儲開銷我們只存最近 7 天快照,帶來的問題是設備歷史變化的 imei 、mac、os、品牌、機型等重要屬性都會丟失。所以,最好的方案應該是使用拉鏈表。由于數(shù)據(jù)已經(jīng)累積了三四年,使用拉鏈表數(shù)據(jù)的話,數(shù)據(jù)條數(shù)會從 40 億膨脹到 60 億,需占 600 G 存儲空間。
==========設計思路、更新辦法=======================
分區(qū)列:
day comment '生成日期。如果 is_latest_row=0,則 day=t_end_date。如果 is_latest_row=1,則day='99991231'。如果day=t_start_date,則說明該用戶是今日新增的。'
is_latest_row comment '是否最新一條數(shù)據(jù)。1是0否。如果標記為 0 說明該條數(shù)據(jù)不會再被更新'
20170101 這一天的數(shù)據(jù)
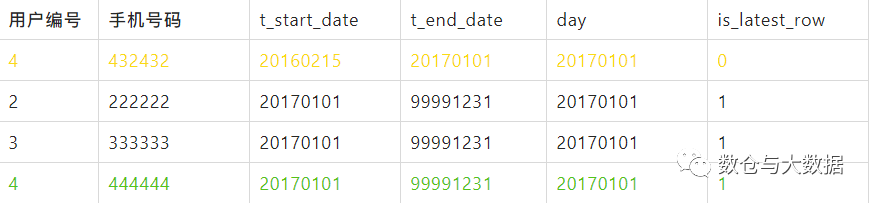
相比于前一天,用戶2、3沒變化,用戶4更新了手機號。
用戶2、用戶3沒變化,直接從前一天的分區(qū)里移過來放到當天的 is_latest_row='1' 分區(qū)下。
用戶4 修改了手機號碼,更新庫里已有的那條數(shù)據(jù) t_end_date='20170101',然后放入當天的 is_latest_row='0' 分區(qū)下,說明該條數(shù)據(jù)因為失效被歸檔了。新增的那條用戶4 數(shù)據(jù) t_start_date='20170101' ,t_end_date='99991231',放入當天的 is_latest_row='1' 分區(qū)下。
20170102 這一天生成的數(shù)據(jù)
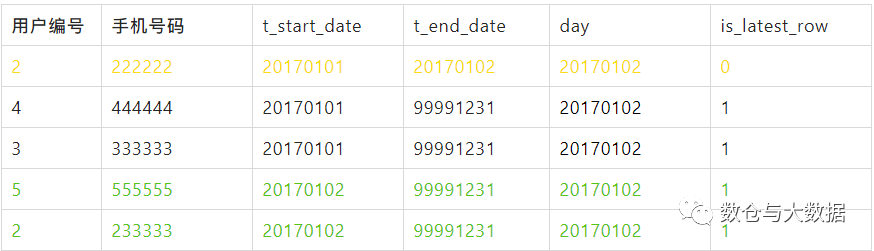
用戶5是新增的,該條數(shù)據(jù)的失效日期是永久,所以 is_latest_row = '1'。? ? ?相比于前一天,新增了用戶5,同時更新了用戶2的手機號碼,用戶3、4無變化。
用戶3、4沒變化,直接從前一天的分區(qū)里移過來放到當天的 is_latest_row='1' 分區(qū)下。
用戶2 修改了手機號碼,更新庫里已有的那條數(shù)據(jù) t_end_date='20170102',然后放入當天的 is_latest_row='0' 分區(qū)下,說明該條數(shù)據(jù)因為失效被歸檔了。新增的那條用戶2 數(shù)據(jù) t_start_date='20170102' ,t_end_date='99991231',放入當天的 is_latest_row='1' 分區(qū)下。
==========使用方法=========
假如數(shù)據(jù)已經(jīng)更新到了 20170102 這一天。
is_latest_row = '0' 的分區(qū)絕對不允許刪除,保證歷史變化都能記錄下來。
is_latest_row = '1' 的分區(qū)只保留最近 7 天或最近 3 天的數(shù)據(jù),節(jié)省存儲空間的同時,就是某一天更新錯誤也能很快的修正數(shù)據(jù)。
可以查最新快照:
select * from dim_user_history where day='20170102' and is_latest_row='1' ?;
可以查歷史任意一天[20161002]的快照:
select t.*
from
(
select t.*
,row_number() over (partition by user_id order by t_end_date) rn
from dim_user_history
where (day>='20161002' and is_latest_row='0') ?or (day='20170102' and is_latest_row='1')
) t
where t.rn=1
;
可以查指定時間范圍內的[20161002-20161101]的所有狀態(tài):
select t.*
from dim_user_history
where (day<'20161101' and is_latest_row='0' ?and ?t_start_date>'20161002') ?
or (day='20170102' and is_latest_row='1' and t_start_date>'20161002')
;
拉鏈表雖然能解決很多問題,但是,只要一個日期卡錯,就會出問題。使用起來真的太太太難了。。。。
4.3 歷史數(shù)據(jù)初始化
上邊,我們了解到,拉鏈表的使用有多麻煩。這一節(jié)我們接著討論下寫入。
如果我們構建拉鏈表的時候,歷史數(shù)據(jù)已經(jīng)沉淀一段時間了,那么大概率我們是需要全量加工處理,并一次性寫入進來的。當然,我們可以從第一天開始、一天一天的往后計算。
但是,總覺得吧,這不是我們技術該干的事兒,因為這也太 lower 了吧。一天一天算,那得等多久啊,技術不能提高效率,要技術干嘛?
這個時候 SQL Boy 該上場了。有啥事情是一條 SQL 搞不定的呢?如果有,那就兩條吧。哈哈哈。。。
接下來先說一下思路吧:
增量更新相對簡單些,我們直接拿上一次統(tǒng)計周期的全量快照,關聯(lián)本次統(tǒng)計周期的變化量即可。
歷史數(shù)據(jù)初始化,由于存在某一個業(yè)務主鍵對應的屬性可能會變化多次的情況,處理起來就會復雜很多:
相鄰兩個統(tǒng)計周期的數(shù)據(jù)如果沒有變化,需要去重。
剩下的數(shù)據(jù),需要按時間正序排列,第一條的數(shù)據(jù)止期=第二條的數(shù)據(jù)起期、第二條的數(shù)據(jù)止期=第三條的數(shù)據(jù)起期,以此類推。
而 SQL 對于行間數(shù)據(jù)的處理常常無能為力,那我們能否把行間數(shù)據(jù)計算轉化成行內數(shù)據(jù)計算呢?
? ? ?
結合以上分析,實現(xiàn)步驟如下(以統(tǒng)計周期為天來舉例):
原始數(shù)據(jù)表。
user_id | user_name | other_column | update_date | update_time |
1 | aaa | 11 | 20210101 | 2021/1/1 12:00 |
1 | bbb | 22 | 20210101 | 2021/1/1 15:00 |
1 | aaa | 33 | 20210102 | 2021/1/2 12:00 |
1 | aaa | 44 | 20210103 | 2021/1/3 12:00 |
1 | aaa | 55 | 20210104 | 2021/1/4 12:00 |
1 | bbb | 66 | 20210105 | 2021/1/5 12:00 |
1 | bbb | 77 | 20210106 | 2021/1/6 12:00 |
1 | bbb | 88 | 20210107 | 2021/1/7 12:00 |
按更新時間,每天只保留最后一條數(shù)據(jù),數(shù)據(jù)起期為當天,止期為無限大。
create table dws.user_his_mid_01 as
select user_id,user_name,update_day b_date,'99990101' e_date
,row_number() over (partition by user_id order by update_day ) rn
from
(
select update_day,user_id,user_name
,row_number() over (partition by update_day,user_id order by update_time desc ) rn
from ods.user
) t
where rn=1
;
前兩條數(shù)據(jù)會只留下一條
user_id | user_name | b_date | e_date | rn |
1 | bbb | 20210101 | 99990101 | 1 |
1 | aaa | 20210102 | 99990101 | 2 |
1 | aaa | 20210103 | 99990101 | 3 |
1 | aaa | 20210104 | 99990101 | 4 |
1 | bbb | 20210105 | 99990101 | 5 |
1 | bbb | 20210106 | 99990101 | 6 |
1 | bbb | 20210107 | 99990101 | 7 |
修正數(shù)據(jù)起止期。
create table dws.user_his_mid_02 as
select t1.user_id,t1.user_name
,t1.b_date
,nvl(t2.b_date,t1.e_date) e_date
from dws.user_his_mid_01 t1
left join dws.user_his_mid t2 on t1.user_id=t2.user_id and t1.rn=t2.rn-1
;

user_id | user_name | b_date | e_date |
1 | bbb | 20210101 | 20210102 |
1 | aaa | 20210102 | 20210103 |
1 | aaa | 20210103 | 20210104 |
1 | aaa | 20210104 | 20210105 |
1 | bbb | 20210105 | 20210106 |
1 | bbb | 20210106 | 20210107 |
1 | bbb | 20210107 | 99990101 |
相鄰兩條數(shù)據(jù),屬性無變化的去重。
上表數(shù)據(jù),會合并為三條。
user_id | user_name | b_date | e_date |
1 | bbb | 20210101 | 20210102 |
1 | aaa | 20210102 | 20210105 |
1 | bbb | 20210105 | 99990101 |
好吧。歷史數(shù)據(jù)初始化,當時是有寫過 SQL 的,好多年過去實在想不起來,當時的 SQL 也找不到了。
本想重現(xiàn)當時的 SQL,不過寫到第三條實在寫不動了,因為太難了。
換做現(xiàn)在的我,其實更愿意寫 MR 或者 UDAF 去實現(xiàn)這一業(yè)務邏輯的。思路特簡單,就是將相同業(yè)務主鍵的數(shù)據(jù)放到一個 Reduce 里,按 update_time 排序后,循環(huán)遍歷,返回結果。
4.4 增量更新
木東居士這條 SQL 寫的非常簡介、實用,借過來給大家看看。
ods.user_update 表應該存的是前一天的變化量(新增 + Update)。
這是關系型數(shù)據(jù)庫的寫法,具體到大數(shù)據(jù)場景,大家還得參照上文,加上分區(qū)列,直接 overwrite 總感覺心里不踏實。
INSERT OVERWRITE TABLE dws.user_his
SELECT * FROM
(
? ?SELECT A.user_num,
? ? ? ? ? A.mobile,
? ? ? ? ? A.reg_date,
? ? ? ? ? A.t_start_time,
? ? ? ? ? CASE
? ? ? ? ? ? ? ?WHEN A.t_end_time = '9999-12-31' AND B.user_num IS NOT NULL THEN '2017-01-01'
? ? ? ? ? ? ? ?ELSE A.t_end_time
? ? ? ? ? END AS t_end_time
? ?FROM dws.user_his AS A
? ?LEFT JOIN ods.user_update AS B
? ?ON A.user_num = B.user_num
UNION
? ?SELECT C.user_num,
? ? ? ? ? C.mobile,
? ? ? ? ? C.reg_date,
? ? ? ? ? '2017-01-02' AS t_start_time,
? ? ? ? ? '9999-12-31' AS t_end_time
? ?FROM ods.user_update AS C
) AS T
;
下邊是我之前寫的,每月計算 IP 地址經(jīng)緯度歷史變化的拉鏈表。
牽涉到部分計算邏輯,會稍微有點復雜,大家看核心代碼段即可。
第一條 SQL 是,這個月的變化量,關聯(lián)上個月的全量快照,更新這個月變化量的起止日期,暫時放到這個月的全量快照分區(qū)里(類似上邊 SQL 的 ods.user_update ?作用)。
第二條 SQL 是,上個月的全量快照,關聯(lián)這個月的變化量,得到這個月的全量快照+這個月失效的數(shù)據(jù)(數(shù)據(jù)止期='$1')。
奧,看了好久,下邊 SQL 的數(shù)據(jù)止期有問題。因為當時的需求跟拉鏈表的不太一樣。數(shù)據(jù)止期用的不是一個無限大的日期,而是(數(shù)據(jù)止期='$1') 。意味著,如果某ip只在其中一個月份出現(xiàn)過,那么起止日期都是一樣的,如果連續(xù)出現(xiàn)過2個月,數(shù)據(jù)起期是第一月,數(shù)據(jù)止期是第二月。
insert OVERWRITE table bds_ip_info partition(month='$1',is_latest_row='1')
?select a.ip,
? ? ? ? if(size(split(lgt_list,';'))=1,split(lgt_list,';')[0],if(size(split(lgt_list,';'))=2,(split(lgt_list,';')[0]+split(lgt_list,';')[1])/2,b.lgt_center)) lgt_center,
? ? ? ? if(size(split(ltt_list,';'))=1,split(ltt_list,';')[0],if(size(split(ltt_list,';'))=2,(split(ltt_list,';')[0]+split(ltt_list,';')[1])/2,b.ltt_center)) ltt_center,
? ? ? ? if(size(split(lgt_list,';'))=1,0,if(size(split(lgt_list,';'))=2,lipb_GetDistance(concat(split(lgt_list,';')[0],',',split(ltt_list,';')[0]),concat(split(lgt_list,';')[1],',',split(ltt_list,';')[1]))/2,b.radius)) radius,
? ? ? ? a.b_month,
? ? ? ? a.e_month,
? ? ? ? size(split(a.geo_list,',')) geo_num,
? ? ? ? a.geo_list,
? ? ? ? month_from_list
?from
?(
? ?select t1.ip
? ?,if(t2.ip is null,substring(t1.month,1,6),t2.b_month) b_month
? ?,substring(t1.month,1,6) e_month
? ?,if(t2.ip is null,t1.month,concat(t1.month,';',t2.month_from_list)) month_from_list
? ?,if(t2.ip is null,GetGeoList(time_list,ltt_list,lgt_list)
? ? ? ? ? ,GetGeoLatest(GetGeoList(time_list,ltt_list,lgt_list),t2.geo_list,'500')) geo_list
? ?,split(SplitGeoList(if(t2.ip is null,GetGeoList(time_list,ltt_list,lgt_list)
? ? ? ? ? ,GetGeoLatest(GetGeoList(time_list,ltt_list,lgt_list),t2.geo_list,'500'))),',')[0] ltt_list
? ?,split(SplitGeoList(if(t2.ip is null,GetGeoList(time_list,ltt_list,lgt_list)
? ? ? ? ? ,GetGeoLatest(GetGeoList(time_list,ltt_list,lgt_list),t2.geo_list,'500'))),',')[1] lgt_list
? ?from ods_ip_info_m t1
? ? ?left join
? ? ?(
? ? ? ?select *
? ? ? ?from bds_ip_info t2
? ? ? ?where month=to_char(dateadd(dateadd(dateadd(to_date('$1','yyyymmdd'),1,'dd'),-1,'mm'),-1,'dd'),'yyyymmdd')
? ? ? ?and is_latest_row='1'
? ? ?) t2
? ? ? ?on t1.ip=t2.ip
? ? ?and abs(t1.radius-t2.radius)<=200
? ? ?and lipb_GetDistance(concat(t1.lgt_center,',',t1.ltt_center),concat(t2.lgt_center,',',t2.ltt_center))<=400
? ?where t1.month='$1'
?) a lateral view MapMedianRadius(ltt_list,lgt_list,';') b as ltt_center,lgt_center,radius
;
insert overwrite ?table bds_ip_info partition(month,is_latest_row)
?select a.ip,
? ? ? ? a.lgt_center,
? ? ? ? a.ltt_center,
? ? ? ? a.radius,
? ? ? ? a.b_month,
? ? ? ? a.e_month,
? ? ? ? a.geo_num,
? ? ? ? a.geo_list,
? ? ? ? a.month_from_list,
? ? ? ? '$1' month,
? ? ? ? if(b.ip is null,'1',if(a.e_month<>b.e_month,'0','1')) is_latest_row
?from
?(
? ?select * from bds_ip_info t1
? ?where month=to_char(dateadd(dateadd(dateadd(to_date('$1','yyyymmdd'),1,'dd'),-1,'mm'),-1,'dd'),'yyyymmdd')
? ?and is_latest_row='1'
?) a
? ?left join
? ?(
? ? ?select t1.ip,e_month from bds_ip_info t1 where t1.month='$1' and is_latest_row='1'
? ?) b on a.ip=b.ip
union all
select * from bds_ip_info t1 where t1.month='$1' and is_latest_row='1'
;
5 典型案例
拉鏈表概念來源于數(shù)倉,數(shù)倉的面試也經(jīng)常會被問到。拉鏈表也切實解決了數(shù)倉四大特性之一的反應歷史變化這一訴求。
但是,拉鏈表在數(shù)倉之外是否還有用武之地呢?事實上,數(shù)倉體系內的各種方法論、規(guī)范、核心技術等,在整個數(shù)據(jù)開發(fā)流程內始終有著巨大的指導借鑒意義。
數(shù)倉人不應局限于數(shù)倉,可以跳出數(shù)倉來看問題。我是數(shù)倉人,但我一定要建數(shù)倉嗎?我們更應該思考的是如何讓組織內的數(shù)據(jù)能夠相對低成本、高效率的使用起來,發(fā)揮更大的價值,我們構建的是組織內的一整套數(shù)據(jù)流轉體系。
案例一:記錄設備庫核心屬性的歷史變更
上邊提到過,我們有一個設備庫,需要記錄核心屬性的歷史變更。記錄歷史變更有什么用呢?比如識別假冒設備,一部手機,imei、mac地址經(jīng)常變化,很可能它不是一個真實的設備。
由于設備庫非常大,4.2 大數(shù)據(jù)數(shù)倉設計方案 是更好的選擇。
案例二:記錄商品成本價格的變化
我們有銷售訂單,訂單里只有銷售價格,我們想要計算毛利潤,就必須要有對應商品的成本價格,而商品的成本價,是隨著每一次進貨入庫實時變更的(當時用到一個移動加權平均算法),比如該筆訂單是昨天下午2點整完成的,那么我必須拿到該商品昨天下午2點整的時點值價格。
該場景,我們的數(shù)據(jù)起止日期(t_start_date、t_end_date)就不適用了,因為理論上,商品價格一天可能會變更多次,必須改成數(shù)據(jù)起止時間(t_start_time、t_end_time),由此帶來的數(shù)據(jù)處理邏輯的變化,上邊 4.4 增量更新的處理邏輯就不適用了,必須改用 4.3 歷史數(shù)據(jù)初始化方式了。
商品成本價格維表,數(shù)據(jù)量大概也就幾萬條數(shù)據(jù)吧,可以采用 4.1 傳統(tǒng)數(shù)倉設計方案存儲。當然也可以使用兩張表,熱表存放近一個月或近7天的成本價格數(shù)據(jù),其它的都歸檔到冷表。
案例三:拉鏈表確實能解決你的問題,但是有沒有別的方案呢?

? ? ?
上邊是一位網(wǎng)友的問題,很快彭總的群里也有人問到了拉鏈表的設計,風大佬還在發(fā)言了,這讓我回憶起曾經(jīng)跟拉鏈表的各種糾葛,聯(lián)想到網(wǎng)上這類文章太過零碎,就想嘗試著寫一下。但,寫文章真的太難啦,就這簡單的一個拉鏈表,從早八點寫到凌晨兩點。。。
? ? ?言歸正傳,簡單幾句閑聊,隱約感覺到,這個需求根本不需要采用拉鏈表的。但本著實時求實的態(tài)度,了解詳情后,給他了他更好的解決方案。經(jīng)得本人同意,脫敏后,特分享給大家。
? ? ?
? ? ?業(yè)務上有一張貸款詳情表,記錄了大概七八個屬性狀態(tài),每一次業(yè)務事件會導致狀態(tài)發(fā)生變化,其實吧數(shù)倉也可以自己算的,但太麻煩還容易造成數(shù)據(jù)不一致,所以還是每日從業(yè)務庫取時點值。業(yè)務庫是主從結構,其中一個從庫,當天的數(shù)據(jù)同步結束后會自動斷開跟主庫的連接,零點以后的狀態(tài)變更會等待 ETL 抽數(shù)完成后重新開啟。
? ? ?業(yè)務庫貸款詳情表屬性狀態(tài)沒有更新時間這個時間戳,業(yè)務系統(tǒng)也不愿意加字段,說是該表數(shù)據(jù)量太大,加這個字段可能會影響業(yè)務。這么大一頂帽子扣過來,咱也拿他沒辦法,只能每天全量抽。
? ? ?但是吧,數(shù)據(jù)抽取,每天都是全量抽,后續(xù) ETL 處理不能也也這么干呀。比如每天存一份全量快照,后續(xù)直接從快照出結果,有時候還要拿最近好多天的快照去跟別的表關聯(lián)。好長一段時間的快照都得存著,因為獨此一份啊,刪了數(shù)據(jù)就丟了。由此帶來了大量的存儲、計算資源的開銷,并且隨著該表的持續(xù)膨脹,里邊數(shù)據(jù)也沒有清退機制,快照會越滾越大,而且還清貸款的數(shù)據(jù),所有屬性狀態(tài)是不會再變動的。
? ? ?以上是網(wǎng)友的困惑,為了提高計算效率,降低存儲成本,他想要使用拉鏈表,記錄歷史變化。
? ? ?說實話,拉鏈表確實能解決他的問題,但引進董卓消滅了外戚,萬一袁紹降不住大魔頭咋辦?
? ? ?
下面是不用拉鏈表的問題解決思路。以截圖開始,就讓我們以截圖結束吧。
? ? ?
 我們點開一個文件夾后:
我們點開一個文件夾后:
Hi,我是王知無,一個大數(shù)據(jù)領域的原創(chuàng)作者。? 放心關注我,獲取更多行業(yè)的一手消息。