
基于SSD的Kafka應(yīng)用層緩存架構(gòu)設(shè)計(jì)與實(shí)現(xiàn)

總第432篇
2021年 第002篇

Kafka在美團(tuán)數(shù)據(jù)平臺(tái)的現(xiàn)狀
Kafka出色的I/O優(yōu)化以及多處異步化設(shè)計(jì),相比其他消息隊(duì)列系統(tǒng)具有更高的吞吐,同時(shí)能夠保證不錯(cuò)的延遲,十分適合應(yīng)用在整個(gè)大數(shù)據(jù)生態(tài)中。
目前在美團(tuán)數(shù)據(jù)平臺(tái)中,Kafka承擔(dān)著數(shù)據(jù)緩沖和分發(fā)的角色。如下圖所示,業(yè)務(wù)日志、接入層Nginx日志或線上DB數(shù)據(jù)通過(guò)數(shù)據(jù)采集層發(fā)送到Kafka,后續(xù)數(shù)據(jù)被用戶的實(shí)時(shí)作業(yè)消費(fèi)、計(jì)算,或經(jīng)過(guò)數(shù)倉(cāng)的ODS層用作數(shù)倉(cāng)生產(chǎn),還有一部分則會(huì)進(jìn)入公司統(tǒng)一日志中心,幫助工程師排查線上問(wèn)題。

目前美團(tuán)線上Kafka規(guī)模:
集群規(guī)模:節(jié)點(diǎn)數(shù)達(dá)6000+,集群數(shù)100+。
集群承載:Topic數(shù)6萬(wàn)+,Partition數(shù)41萬(wàn)+。
處理的消息規(guī)模:目前每天處理消息總量達(dá)8萬(wàn)億,峰值流量為1.8億條/秒
提供的服務(wù)規(guī)模:目前下游實(shí)時(shí)計(jì)算平臺(tái)運(yùn)行了3萬(wàn)+作業(yè),而這其中絕大多數(shù)的數(shù)據(jù)源均來(lái)自Kafka。
Kafka線上痛點(diǎn)分析&核心目標(biāo)
當(dāng)前Kafka支撐的實(shí)時(shí)作業(yè)數(shù)量眾多,單機(jī)承載的Topic和Partition數(shù)量很大。這種場(chǎng)景下很容易出現(xiàn)的問(wèn)題是:同一臺(tái)機(jī)器上不同Partition間競(jìng)爭(zhēng)PageCache資源,相互影響,導(dǎo)致整個(gè)Broker的處理延遲上升、吞吐下降。
接下來(lái),我們將結(jié)合Kafka讀寫請(qǐng)求的處理流程以及線上統(tǒng)計(jì)的數(shù)據(jù)來(lái)分析一下Kafka在線上的痛點(diǎn)。
原理分析

對(duì)于Produce請(qǐng)求:Server端的I/O線程統(tǒng)一將請(qǐng)求中的數(shù)據(jù)寫入到操作系統(tǒng)的PageCache后立即返回,當(dāng)消息條數(shù)到達(dá)一定閾值后,Kafka應(yīng)用本身或操作系統(tǒng)內(nèi)核會(huì)觸發(fā)強(qiáng)制刷盤操作(如左側(cè)流程圖所示)。
對(duì)于Consume請(qǐng)求:主要利用了操作系統(tǒng)的ZeroCopy機(jī)制,當(dāng)Kafka Broker接收到讀數(shù)據(jù)請(qǐng)求時(shí),會(huì)向操作系統(tǒng)發(fā)送sendfile系統(tǒng)調(diào)用,操作系統(tǒng)接收后,首先試圖從PageCache中獲取數(shù)據(jù)(如中間流程圖所示);如果數(shù)據(jù)不存在,會(huì)觸發(fā)缺頁(yè)異常中斷將數(shù)據(jù)從磁盤讀入到臨時(shí)緩沖區(qū)中(如右側(cè)流程圖所示),隨后通過(guò)DMA操作直接將數(shù)據(jù)拷貝到網(wǎng)卡緩沖區(qū)中等待后續(xù)的TCP傳輸。
綜上所述,Kafka對(duì)于單一讀寫請(qǐng)求均擁有很好的吞吐和延遲。處理寫請(qǐng)求時(shí),數(shù)據(jù)寫入PageCache后立即返回,數(shù)據(jù)通過(guò)異步方式批量刷入磁盤,既保證了多數(shù)寫請(qǐng)求都能有較低的延遲,同時(shí)批量順序刷盤對(duì)磁盤更加友好。處理讀請(qǐng)求時(shí),實(shí)時(shí)消費(fèi)的作業(yè)可以直接從PageCache讀取到數(shù)據(jù),請(qǐng)求延遲較小,同時(shí)ZeroCopy機(jī)制能夠減少數(shù)據(jù)傳輸過(guò)程中用戶態(tài)與內(nèi)核態(tài)的切換,大幅提升了數(shù)據(jù)傳輸?shù)男省?/span>
但當(dāng)同一個(gè)Broker上同時(shí)存在多個(gè)Consumer時(shí),就可能會(huì)由于多個(gè)Consumer競(jìng)爭(zhēng)PageCache資源導(dǎo)致它們同時(shí)產(chǎn)生延遲。下面我們以兩個(gè)Consumer為例詳細(xì)說(shuō)明:

如上圖所示,Producer將數(shù)據(jù)發(fā)送到Broker,PageCache會(huì)緩存這部分?jǐn)?shù)據(jù)。當(dāng)所有Consumer的消費(fèi)能力充足時(shí),所有的數(shù)據(jù)都會(huì)從PageCache讀取,全部Consumer實(shí)例的延遲都較低。此時(shí)如果其中一個(gè)Consumer出現(xiàn)消費(fèi)延遲(圖中的Consumer Process2),根據(jù)讀請(qǐng)求處理流程可知,此時(shí)會(huì)觸發(fā)磁盤讀取,在從磁盤讀取數(shù)據(jù)的同時(shí)會(huì)預(yù)讀部分?jǐn)?shù)據(jù)到PageCache中。當(dāng)PageCache空間不足時(shí),會(huì)按照LRU策略開(kāi)始淘汰數(shù)據(jù),此時(shí)延遲消費(fèi)的Consumer讀取到的數(shù)據(jù)會(huì)替換PageCache中實(shí)時(shí)的緩存數(shù)據(jù)。后續(xù)當(dāng)實(shí)時(shí)消費(fèi)請(qǐng)求到達(dá)時(shí),由于PageCache中的數(shù)據(jù)已被替換掉,會(huì)產(chǎn)生預(yù)期外的磁盤讀取。這樣會(huì)導(dǎo)致兩個(gè)后果:
消費(fèi)能力充足的Consumer消費(fèi)時(shí)會(huì)失去PageCache的性能紅利。
多個(gè)Consumer相互影響,預(yù)期外的磁盤讀增多,HDD負(fù)載升高。
我們針對(duì)HDD的性能和讀寫并發(fā)的影響做了梯度測(cè)試,如下圖所示:

可以看到,隨著讀并發(fā)的增加,HDD的IOPS和帶寬均會(huì)明顯下降,這會(huì)進(jìn)一步影響整個(gè)Broker的吞吐以及處理延遲。
線上數(shù)據(jù)統(tǒng)計(jì)
目前Kafka集群TP99流量在170MB/s,TP95流量在100MB/s,TP50流量為50-60MB/s;單機(jī)的PageCache平均分配為80GB,取TP99的流量作為參考,在此流量以及PageCache分配情況下,PageCache最大可緩存數(shù)據(jù)時(shí)間跨度為80*1024/170/60 = 8min,可見(jiàn)當(dāng)前Kafka服務(wù)整體對(duì)延遲消費(fèi)作業(yè)的容忍性極低。該情況下,一旦部分作業(yè)消費(fèi)延遲,實(shí)時(shí)消費(fèi)作業(yè)就可能會(huì)受到影響。
同時(shí),我們統(tǒng)計(jì)了線上實(shí)時(shí)作業(yè)的消費(fèi)延遲分布情況,延遲范圍在0-8min(實(shí)時(shí)消費(fèi))的作業(yè)只占80%,說(shuō)明目前存在線上存在20%的作業(yè)處于延遲消費(fèi)的狀態(tài)。
痛點(diǎn)分析總結(jié)
總結(jié)上述的原理分析以及線上數(shù)據(jù)統(tǒng)計(jì),目前線上Kafka存在如下問(wèn)題:
實(shí)時(shí)消費(fèi)與延遲消費(fèi)的作業(yè)在PageCache層次產(chǎn)生競(jìng)爭(zhēng),導(dǎo)致實(shí)時(shí)消費(fèi)產(chǎn)生非預(yù)期磁盤讀。
傳統(tǒng)HDD隨著讀并發(fā)升高性能急劇下降。
線上存在20%的延遲消費(fèi)作業(yè)。
按目前的PageCache空間分配以及線上集群流量分析,Kafka無(wú)法對(duì)實(shí)時(shí)消費(fèi)作業(yè)提供穩(wěn)定的服務(wù)質(zhì)量保障,該痛點(diǎn)亟待解決。
預(yù)期目標(biāo)
根據(jù)上述痛點(diǎn)分析,我們的預(yù)期目標(biāo)為保證實(shí)時(shí)消費(fèi)作業(yè)不會(huì)由于PageCache競(jìng)爭(zhēng)而被延遲消費(fèi)作業(yè)影響,保證Kafka對(duì)實(shí)時(shí)消費(fèi)作業(yè)提供穩(wěn)定的服務(wù)質(zhì)量保障。
解決方案
為什么選擇SSD
根據(jù)上述原因分析可知,解決目前痛點(diǎn)可從以下兩個(gè)方向來(lái)考慮:
消除實(shí)時(shí)消費(fèi)與延遲消費(fèi)間的PageCache競(jìng)爭(zhēng),如:讓延遲消費(fèi)作業(yè)讀取的數(shù)據(jù)不回寫PageCache,或增大PageCache的分配量等。
在HDD與內(nèi)存之間加入新的設(shè)備,該設(shè)備擁有比HDD更好的讀寫帶寬與IOPS。
對(duì)于第一個(gè)方向,由于PageCache由操作系統(tǒng)管理,若修改其淘汰策略,那么實(shí)現(xiàn)難度較為復(fù)雜,同時(shí)會(huì)破壞內(nèi)核本身對(duì)外的語(yǔ)義。另外,內(nèi)存資源成本較高,無(wú)法進(jìn)行無(wú)限制的擴(kuò)展,因此需要考慮第二個(gè)方向。
SSD目前發(fā)展日益成熟,相較于HDD,SSD的IOPS與帶寬擁有數(shù)量級(jí)級(jí)別的提升,很適合在上述場(chǎng)景中當(dāng)PageCache出現(xiàn)競(jìng)爭(zhēng)后承接部分讀流量。我們對(duì)SSD的性能也進(jìn)行了測(cè)試,結(jié)果如下圖所示:

從圖中可以發(fā)現(xiàn),隨著讀取并發(fā)的增加,SSD的IOPS與帶寬并不會(huì)顯著降低。通過(guò)該結(jié)論可知,我們可以使用SSD作為PageCache與HDD間的緩存層。
架構(gòu)決策
在引入SSD作為緩存層后,下一步要解決的關(guān)鍵問(wèn)題包括PageCache、SSD、HDD三者間的數(shù)據(jù)同步以及讀寫請(qǐng)求的數(shù)據(jù)路由等問(wèn)題,同時(shí)我們的新緩存架構(gòu)需要充分匹配Kafka引擎讀寫請(qǐng)求的特征。本小節(jié)將介紹新架構(gòu)如何在選型與設(shè)計(jì)上解決上述提到的問(wèn)題。
Kafka引擎在讀寫行為上具有如下特性:
數(shù)據(jù)的消費(fèi)頻率隨時(shí)間變化,越久遠(yuǎn)的數(shù)據(jù)消費(fèi)頻率越低。
每個(gè)分區(qū)(Partition)只有Leader提供讀寫服務(wù)。
對(duì)于一個(gè)客戶端而言,消費(fèi)行為是線性的,數(shù)據(jù)并不會(huì)重復(fù)消費(fèi)。
下文給出了兩種備選方案,下面將對(duì)兩種方案給出我們的選取依據(jù)與架構(gòu)決策。
備選方案一:基于操作系統(tǒng)內(nèi)核層實(shí)現(xiàn)
目前開(kāi)源的緩存技術(shù)有FlashCache、BCache、DM-Cache、OpenCAS等,其中BCache和DM-Cache已經(jīng)集成到Linux中,但對(duì)內(nèi)核版本有要求,受限于內(nèi)核版本,我們僅能選用FlashCache/OpenCAS。
如下圖所示,F(xiàn)lashCache以及OpenCAS二者的核心設(shè)計(jì)思路類似,兩種架構(gòu)的核心理論依據(jù)為“數(shù)據(jù)局部性”原理,將SSD與HDD按照相同的粒度拆成固定的管理單元,之后將SSD上的空間映射到多塊HDD層的設(shè)備上(邏輯映射or物理映射)。在訪問(wèn)流程上,與CPU訪問(wèn)高速緩存和主存的流程類似,首先嘗試訪問(wèn)Cache層,如果出現(xiàn)CacheMiss,則會(huì)訪問(wèn)HDD層,同時(shí)根據(jù)數(shù)據(jù)局部性原理,這部分?jǐn)?shù)據(jù)將回寫到Cache層。如果Cache空間已滿,會(huì)通過(guò)LRU策略替換部分?jǐn)?shù)據(jù)。

FlashCache/OpenCAS提供了四種緩存策略:WriteThrough、WriteBack、WriteAround、WriteOnly。由于第四種不做讀緩存,這里我們只看前三種。
寫入:
WriteThrough:數(shù)據(jù)寫操作在寫入SSD的同時(shí)會(huì)寫入到后端存儲(chǔ)。
WriteBack:數(shù)據(jù)寫操作僅寫入SSD即返回,由緩存策略flush到后臺(tái)存儲(chǔ)。
WriteAround:數(shù)據(jù)寫入操作直接寫入后端存儲(chǔ),同時(shí)SSD對(duì)應(yīng)的緩存會(huì)失效。
讀取:
WriteThrough/WriteBack/WriteAround:首先讀取SSD,命中不了的將再次讀取后端存儲(chǔ),并數(shù)據(jù)會(huì)被刷入到SSD緩存中。

更多詳細(xì)實(shí)現(xiàn)細(xì)節(jié),極大可參見(jiàn)這二者的官方文檔:
FlashCache
OpenCAS
備選方案二:Kafka應(yīng)用內(nèi)部實(shí)現(xiàn)
上文提到的第一類備選方案中,核心的理論依據(jù)“數(shù)據(jù)局部性”原理與Kafka的讀寫特性并不能完全吻合,“數(shù)據(jù)回刷”這一特性依然會(huì)引入緩存空間污染問(wèn)題。同時(shí),上述架構(gòu)基于LRU的淘汰策略也與Kafka讀寫特性存在矛盾,在多Consumer并發(fā)消費(fèi)時(shí),LRU淘汰策略可能會(huì)誤淘汰掉一些近實(shí)時(shí)數(shù)據(jù),導(dǎo)致實(shí)時(shí)消費(fèi)作業(yè)出現(xiàn)性能抖動(dòng)。
可見(jiàn),備選方案一并不能完全解決當(dāng)前Kafka的痛點(diǎn),需要從應(yīng)用內(nèi)部進(jìn)行改造。整體設(shè)計(jì)思路如下,將數(shù)據(jù)按照時(shí)間維度分布在不同的設(shè)備中,近實(shí)時(shí)部分的數(shù)據(jù)緩存在SSD中,這樣當(dāng)出現(xiàn)PageCache競(jìng)爭(zhēng)時(shí),實(shí)時(shí)消費(fèi)作業(yè)從SSD中讀取數(shù)據(jù),保證實(shí)時(shí)作業(yè)不會(huì)受到延遲消費(fèi)作業(yè)影響。下圖展示了基于應(yīng)用層實(shí)現(xiàn)的架構(gòu)處理讀請(qǐng)求的流程:

當(dāng)消費(fèi)請(qǐng)求到達(dá)Kafka Broker時(shí),Kafka Broker直接根據(jù)其維護(hù)的消息偏移量(Offset)和設(shè)備的關(guān)系從對(duì)應(yīng)的設(shè)備中獲取數(shù)據(jù)并返回,并且在讀請(qǐng)求中并不會(huì)將HDD中讀取的數(shù)據(jù)回刷到SSD,防止出現(xiàn)緩存污染。同時(shí)訪問(wèn)路徑明確,不會(huì)由于Cache Miss而產(chǎn)生的額外訪問(wèn)開(kāi)銷。
下表對(duì)不同候選方案進(jìn)行了更加詳細(xì)的對(duì)比:
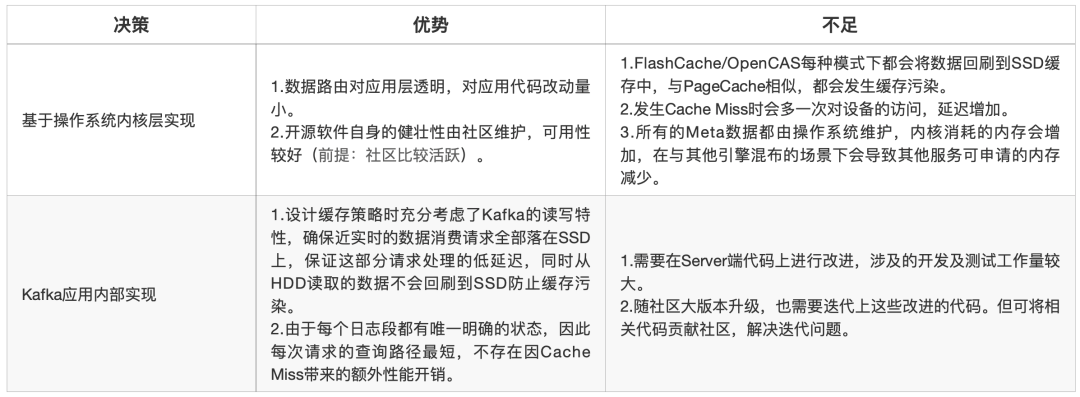
最終,結(jié)合與Kafka讀寫特性的匹配度,整體工作量等因素綜合考慮,我們采用Kafka應(yīng)用層實(shí)現(xiàn)這一方案,因?yàn)樵摲桨父N近Kafka本身讀寫特性,能更加徹底地解決Kafka的痛點(diǎn)。
新架構(gòu)設(shè)計(jì)
概述
根據(jù)上文對(duì)Kafka讀寫特性的分析,我們給出應(yīng)用層基于SSD的緩存架構(gòu)的設(shè)計(jì)目標(biāo):
數(shù)據(jù)按時(shí)間維度分布在不同的設(shè)備上,近實(shí)時(shí)數(shù)據(jù)分布在SSD上,隨時(shí)間的推移淘汰到HDD上。
Leader分區(qū)中所有數(shù)據(jù)均寫入SSD中。
從HDD中讀取的數(shù)據(jù)不回刷到SSD中。
依據(jù)上述目標(biāo),我們給出應(yīng)用層基于SSD的Kafka緩存架構(gòu)實(shí)現(xiàn):
Kafka中一個(gè)Partition由若干LogSegment構(gòu)成,每個(gè)LogSegment包含兩個(gè)索引文件以及日志消息文件。一個(gè)Partition的若干LogSegment按Offset(相對(duì)時(shí)間)維度有序排列。

根據(jù)上一小節(jié)的設(shè)計(jì)思路,我們首先將不同的LogSegment標(biāo)記為不同的狀態(tài),如圖所示(圖中上半部分)按照時(shí)間維度分為OnlyCache、Cached以及WithoutCache三種常駐狀態(tài)。而三種狀態(tài)的轉(zhuǎn)換以及新架構(gòu)對(duì)讀寫操作的處理如圖中下半部分所示,其中標(biāo)記為OnlyCached狀態(tài)的LogSegment只存儲(chǔ)在SSD上,后臺(tái)線程會(huì)定期將Inactive(沒(méi)有寫流量)的LogSegment同步到SSD上,完成同步的LogSegment被標(biāo)記為Cached狀態(tài)。
最后,后臺(tái)線程將會(huì)定期檢測(cè)SSD上的使用空間,當(dāng)空間達(dá)到閾值時(shí),后臺(tái)線程將會(huì)按照時(shí)間維度將距離現(xiàn)在最久的LogSegment從SSD中移除,這部分LogSegment會(huì)被標(biāo)記為WithoutCache狀態(tài)。
對(duì)于寫請(qǐng)求而言,寫入請(qǐng)求依然首先將數(shù)據(jù)寫入到PageCache中,滿足閾值條件后將會(huì)刷入SSD。對(duì)于讀請(qǐng)求(當(dāng)PageCache未獲取到數(shù)據(jù)時(shí)),如果讀取的offset對(duì)應(yīng)的LogSegment的狀態(tài)為Cached或OnlyCache,則數(shù)據(jù)從SSD返回(圖中LC2-LC1以及RC1),如果狀態(tài)為WithoutCache,則從HDD返回(圖中LC1)。
對(duì)于Follower副本的數(shù)據(jù)同步,可根據(jù)Topic對(duì)延遲以及穩(wěn)定性的要求,通過(guò)配置決定寫入到SSD還是HDD。
關(guān)鍵優(yōu)化點(diǎn)
上文介紹了基于SSD的Kafka應(yīng)用層緩存架構(gòu)的設(shè)計(jì)概要以及核心設(shè)計(jì)思路,包括讀寫流程、內(nèi)部狀態(tài)管理以及新增后臺(tái)線程功能等。本小節(jié)將介紹該方案的關(guān)鍵優(yōu)化點(diǎn),這些優(yōu)化點(diǎn)均與服務(wù)的性能息息相關(guān)。主要包括LogSegment同步以及Append刷盤策略優(yōu)化,下面將分別進(jìn)行介紹。
LogSegment同步
LogSegment同步是指將SSD上的數(shù)據(jù)同步到HDD上的過(guò)程,該機(jī)制在設(shè)計(jì)時(shí)主要有以下兩個(gè)關(guān)鍵點(diǎn):
同步的方式:同步方式?jīng)Q定了HDD上對(duì)SSD數(shù)據(jù)的可見(jiàn)時(shí)效性,從而會(huì)影響故障恢復(fù)以及LogSegment清理的及時(shí)性。
同步限速:LogSegment同步過(guò)程中通過(guò)限速機(jī)制來(lái)防止同步過(guò)程中對(duì)正常讀寫請(qǐng)求造成影響
同步方式
關(guān)于LogSegment的同步方式,我們給出了三種備選方案,下表列舉了三種方案的介紹以及各自的優(yōu)缺點(diǎn):
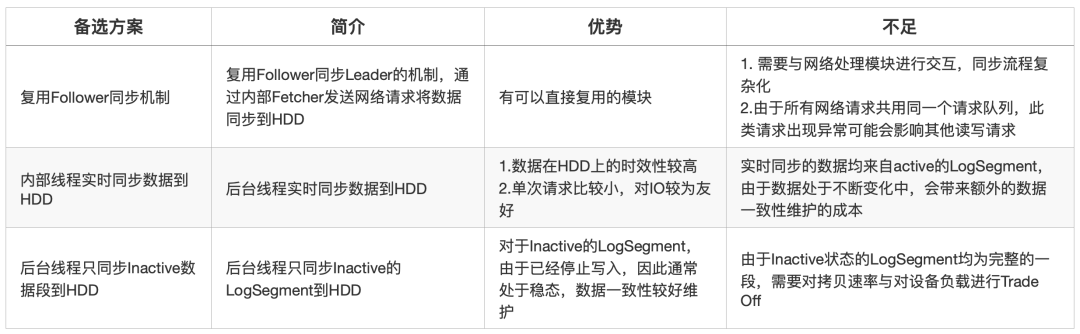
最終,我們對(duì)一致性維護(hù)代價(jià)、實(shí)現(xiàn)復(fù)雜度等因素綜合考慮,選擇了后臺(tái)同步Inactive的LogSegment的方式。
同步限速
LogSegment同步行為本質(zhì)上是設(shè)備間的數(shù)據(jù)傳輸,會(huì)同時(shí)在兩個(gè)設(shè)備上產(chǎn)生額外的讀寫流量,占用對(duì)應(yīng)設(shè)備的讀寫帶寬。同時(shí),由于我們選擇了同步Inactive部分的數(shù)據(jù),需要進(jìn)行整段的同步。如果在同步過(guò)程中不加以限制會(huì)對(duì)服務(wù)整體延遲造成較大的影響,主要表現(xiàn)在下面兩個(gè)方面:
從單盤性能角度,由于SSD的性能遠(yuǎn)高于HDD,因此在數(shù)據(jù)傳輸時(shí),HDD寫入帶寬會(huì)被寫滿,此時(shí)其他的讀寫請(qǐng)求會(huì)出現(xiàn)毛刺,如果此時(shí)有延遲消費(fèi)從HDD上讀取數(shù)據(jù)或者Follower正在同步數(shù)據(jù)到HDD上,會(huì)造成服務(wù)抖動(dòng)。
從單機(jī)部署的角度,單機(jī)會(huì)部署2塊SSD與10塊HDD,因此在同步過(guò)程中,1塊SSD需要承受5塊HDD的寫入量,因此SSD同樣會(huì)在同步過(guò)程中出現(xiàn)性能毛刺,影響正常的請(qǐng)求響應(yīng)延遲。
基于上述兩點(diǎn),我們需要在LogSegment同步過(guò)程中增加限速機(jī)制,總體的限速原則為在不影響正常讀寫請(qǐng)求延遲的情況下盡可能快速地進(jìn)行同步。因?yàn)橥剿俣冗^(guò)慢會(huì)導(dǎo)致SSD數(shù)據(jù)無(wú)法被及時(shí)清理而最終被寫滿。同時(shí)為了可以靈活調(diào)整,該配置也被設(shè)置為單Broker粒度的配置參數(shù)。
日志追加刷盤策略優(yōu)化
除了同步問(wèn)題,數(shù)據(jù)寫入過(guò)程中的刷盤機(jī)制同樣影響服務(wù)的讀寫延遲。該機(jī)制的設(shè)計(jì)不僅會(huì)影響新架構(gòu)的性能,對(duì)原生Kafka同樣會(huì)產(chǎn)生影響。
下圖展示了單次寫入請(qǐng)求的處理流程:

在Produce請(qǐng)求處理流程中,首先根據(jù)當(dāng)前LogSegment的位置與請(qǐng)求中的數(shù)據(jù)信息確定是否需要滾動(dòng)日志段,隨后將請(qǐng)求中的數(shù)據(jù)寫入到PageCache中,更新LEO以及統(tǒng)計(jì)信息,最后根據(jù)統(tǒng)計(jì)信息確定是否需要觸發(fā)刷盤操作,如果需要?jiǎng)t通過(guò)fileChannel.force強(qiáng)制刷盤,否則請(qǐng)求直接返回。
在整個(gè)流程中,除日志滾動(dòng)與刷盤操作外,其他操作均為內(nèi)存操作,不會(huì)帶來(lái)性能問(wèn)題。日志滾動(dòng)涉及文件系統(tǒng)的操作,目前,Kafka中提供了日志滾動(dòng)的擾動(dòng)參數(shù),防止多個(gè)Segment同時(shí)觸發(fā)滾動(dòng)操作給文件系統(tǒng)帶來(lái)壓力。針對(duì)日志刷盤操作,目前Kafka給出的機(jī)制是以固定消息條數(shù)觸發(fā)強(qiáng)制刷盤(目前線上為50000),該機(jī)制只能保證在入流量一定時(shí),消息會(huì)以相同的頻率刷盤,但無(wú)法限制每次刷入磁盤的數(shù)據(jù)量,對(duì)磁盤的負(fù)載無(wú)法提供有效的限制。
如下圖所示,為某磁盤在午高峰時(shí)間段write_bytes的瞬時(shí)值,在午高峰時(shí)間段,由于寫入流量的上升,在刷盤過(guò)程中會(huì)產(chǎn)生大量的毛刺,而毛刺的值幾乎接近磁盤最大的寫入帶寬,這會(huì)使讀寫請(qǐng)求延遲發(fā)生抖動(dòng)。

針對(duì)該問(wèn)題,我們修改了刷盤的機(jī)制,將原本的按條數(shù)限制修改為按實(shí)際刷盤的速率限制,對(duì)于單個(gè)Segment,刷盤速率限制為2MB/s。該值考慮了線上實(shí)際的平均消息大小,如果設(shè)置過(guò)小,對(duì)于單條消息較大的Topic會(huì)過(guò)于頻繁的進(jìn)行刷新,在流量較高時(shí)反而會(huì)加重平均延遲。目前該機(jī)制已在線上小范圍灰度,右圖展示了灰度后同時(shí)間段對(duì)應(yīng)的write_bytes指標(biāo),可以看到相比左圖,數(shù)據(jù)刷盤速率較灰度前明顯平滑,最高速率僅為40MB/s左右。
對(duì)于SSD新緩存架構(gòu),同樣存在上述問(wèn)題,因此在新架構(gòu)中,在刷盤操作中同樣對(duì)刷盤速率進(jìn)行了限制。
方案測(cè)試
測(cè)試目標(biāo)
驗(yàn)證基于應(yīng)用層的SSD緩存架構(gòu)能夠避免實(shí)時(shí)作業(yè)受到延遲作業(yè)的影響。
驗(yàn)證相比基于操作系統(tǒng)內(nèi)核層實(shí)現(xiàn)的緩存層架構(gòu),基于應(yīng)用層的SSD架構(gòu)在不同流量下讀寫延遲更低。
測(cè)試場(chǎng)景描述
構(gòu)建4個(gè)集群:新架構(gòu)集群、普通HDD集群、FlashCache集群、OpenCAS集群。
每個(gè)集群3個(gè)節(jié)點(diǎn)。
固定寫入流量,比較讀、寫耗時(shí)。
延遲消費(fèi)設(shè)置:只消費(fèi)相對(duì)當(dāng)前時(shí)間10~150分鐘的數(shù)據(jù)(超過(guò)PageCache的承載區(qū)域,不超過(guò)SSD的承載區(qū)域)。
測(cè)試內(nèi)容及重點(diǎn)關(guān)注指標(biāo)
Case1: 僅有延遲消費(fèi)時(shí),觀察集群的生產(chǎn)和消費(fèi)性能。
重點(diǎn)關(guān)注的指標(biāo):寫耗時(shí)、讀耗時(shí),通過(guò)這2個(gè)指標(biāo)體現(xiàn)出讀寫延遲。
命中率指標(biāo):HDD讀取量、HDD讀取占比(HDD讀取量/讀取總量)、SSD讀取命中率,通過(guò)這3個(gè)指標(biāo)體現(xiàn)出SSD緩存的命中率。
Case2: 存在延遲消費(fèi)時(shí),觀察實(shí)時(shí)消費(fèi)的性能。
重點(diǎn)指標(biāo):實(shí)時(shí)作業(yè)的SLA(服務(wù)質(zhì)量)的5個(gè)不同時(shí)間區(qū)域的占比情況。
測(cè)試結(jié)果
從單Broker請(qǐng)求延遲角度看:
在刷盤機(jī)制優(yōu)化前,SSD新緩存架構(gòu)在所有場(chǎng)景下,較其他方案都具有明顯優(yōu)勢(shì)。

刷盤機(jī)制優(yōu)化后,其余方案在延遲上服務(wù)質(zhì)量有提升,在較小流量下由于Flush機(jī)制的優(yōu)化,新架構(gòu)與其他方案的優(yōu)勢(shì)變小。當(dāng)單節(jié)點(diǎn)寫入流量較大時(shí)(大于170MB)優(yōu)勢(shì)明顯。

從延遲作業(yè)對(duì)實(shí)時(shí)作業(yè)的影響方面看:
新緩存架構(gòu)在測(cè)試所涉及的所有場(chǎng)景中,延遲作業(yè)都不會(huì)對(duì)實(shí)時(shí)作業(yè)產(chǎn)生影響,符合預(yù)期。

總結(jié)與未來(lái)展望
Kafka在美團(tuán)數(shù)據(jù)平臺(tái)承擔(dān)統(tǒng)一的數(shù)據(jù)緩存和分發(fā)的角色,針對(duì)目前由于PageCache互相污染、進(jìn)而引發(fā)PageCache競(jìng)爭(zhēng)導(dǎo)致實(shí)時(shí)作業(yè)被延遲作業(yè)影響的痛點(diǎn),我們基于SSD自研了Kafka的應(yīng)用層緩存架構(gòu)。本文主要介紹Kafka新架構(gòu)的設(shè)計(jì)思路以及與其他開(kāi)源方案的對(duì)比。與普通集群相比,新緩存架構(gòu)具備非常明顯的優(yōu)勢(shì):
降低讀寫耗時(shí):比起普通集群,新架構(gòu)集群讀寫耗時(shí)降低80%。
實(shí)時(shí)消費(fèi)不受延遲消費(fèi)的影響:比起普通集群,新架構(gòu)集群實(shí)時(shí)讀寫性能穩(wěn)定,不受延時(shí)消費(fèi)的影響。
目前,這套緩存架構(gòu)優(yōu)已經(jīng)驗(yàn)證完成,正在灰度階段,未來(lái)也優(yōu)先部署到高優(yōu)集群。其中涉及的代碼也將提交給Kafka社區(qū),作為對(duì)社區(qū)的回饋,也歡迎大家跟我們一起交流。
作者簡(jiǎn)介
世吉,仕祿,均為美團(tuán)數(shù)據(jù)平臺(tái)工程師。