
實(shí)現(xiàn)基于 Grafana Loki 的日志報(bào)警
對(duì)于生產(chǎn)環(huán)境以及一個(gè)有追求的運(yùn)維人員來(lái)說(shuō),哪怕是毫秒級(jí)別的宕機(jī)也是不能容忍的。對(duì)基礎(chǔ)設(shè)施及應(yīng)用進(jìn)行適當(dāng)?shù)娜罩居涗浐捅O(jiān)控非常有助于解決問(wèn)題,還可以幫助優(yōu)化成本和資源,以及幫助檢測(cè)以后可能會(huì)發(fā)生的一些問(wèn)題。前面我們學(xué)習(xí)使用了 Prometheus 來(lái)進(jìn)行監(jiān)控報(bào)警,但是如果我們使用 Loki 收集日志是否可以根據(jù)采集的日志來(lái)進(jìn)行報(bào)警呢?答案是肯定的,而且有兩種方式可以來(lái)實(shí)現(xiàn):Promtail 中的 metrics 階段和 Loki 的 ruler 組件。
測(cè)試應(yīng)用
比如現(xiàn)在我們有一個(gè)如下所示的 nginx 應(yīng)用用于 Loki 日志報(bào)警:
# nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- name: nginx
port: 80
protocol: TCP
selector:
app: nginx
type: NodePort
為方便測(cè)試,我們這里使用 NodePort 類(lèi)型的服務(wù)來(lái)暴露應(yīng)用,直接安裝即可:
$ kubectl apply -f nginx-deploy.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-5d59d67564-ll9xf 1/1 Running 0 16s
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 91d
nginx NodePort 10.99.153.32 <none> 80:31313/TCP 22s
我們可以通過(guò)如下命令來(lái)來(lái)模擬每隔10s訪(fǎng)問(wèn) Nginx 應(yīng)用:
$ while true; do curl --silent --output /dev/null --write-out '%{http_code}' http://192.168.0.106:31313; sleep 10; echo; done
200
200
metrics 階段
前面我們提到在 Promtail 中通過(guò)一系列 Pipeline 來(lái)處理日志,其中就包括一個(gè) metrics 的階段,可以根據(jù)我們的需求來(lái)增加一個(gè)監(jiān)控指標(biāo),這就是我們需要實(shí)現(xiàn)的基于日志的監(jiān)控報(bào)警的核心點(diǎn),通過(guò)結(jié)構(gòu)化日志,增加監(jiān)控指標(biāo),然后使用 Prometheus 結(jié)合 Alertmanager 完成之前我們非常熟悉的監(jiān)控報(bào)警。
首先我們需要安裝 Prometheus 與 Alertmanager,可以手動(dòng)安裝,也可以使用 Prometheus Operator 的方式,可以參考監(jiān)控報(bào)警章節(jié)相關(guān)內(nèi)容,比如這里我們選擇使用 Prometheus Operator 的方式。
前面我們介紹了幾種 Loki 的部署方式,這里我們就保留上節(jié)微服務(wù)模式的 Loki 集群,接下來(lái)我們需要重新配置 Promtail,為其添加一個(gè) metrics 處理階段,使用如下所示的 values 文件重新安裝。
# ci/metrics-values.yaml
rbac:
pspEnabled: false
config:
clients:
- url: http://loki-loki-distributed-gateway/loki/api/v1/push
snippets:
pipelineStages:
- cri: {}
- match:
selector: '{app="nginx"}'
stages:
- regex:
expression: '.*(?P<hits>GET /.*)'
- metrics:
nginx_hits:
type: Counter
description: "Total nginx requests"
source: hits
config:
action: inc
serviceMonitor:
enabled: true
additionalLabels:
app: prometheus-operator
release: prometheus
上面最重要的部分就是為 Promtail 添加了 pipelineStages 配置,用于對(duì)日志行進(jìn)行轉(zhuǎn)換,在這里我們添加了一個(gè) match 的階段,會(huì)去匹配具有 app=nginx 這樣的日志流數(shù)據(jù),然后下一個(gè)階段是利用正則表達(dá)式過(guò)濾出包含 GET 關(guān)鍵字的日志行。
在 metrics 指標(biāo)階段,我們定義了一個(gè) nginx_hits 的指標(biāo),Promtail 通過(guò)其 /metrics 端點(diǎn)暴露這個(gè)自定義的指標(biāo)數(shù)據(jù)。這里我們定義的是一個(gè) Counter 類(lèi)型的指標(biāo),當(dāng)從 regex 階段匹配上后,這個(gè)計(jì)數(shù)器就會(huì)遞增。
為了在 Prometheus 中能夠這個(gè)指標(biāo),我們通過(guò) promtail.serviceMonitor.enable=true 開(kāi)啟了一個(gè) ServiceMonitor。接下來(lái)重新更新 Loki 應(yīng)用,使用如下所示的命令即可:
$ helm upgrade --install loki -n logging -f ci/metrics-values.yaml .
更新完成后會(huì)創(chuàng)建一個(gè) ServiceMonitor 對(duì)象用于發(fā)現(xiàn) Promtail 的指標(biāo)數(shù)據(jù):
$ kubectl get servicemonitor -n logging
NAME AGE
loki-promtail 10s
如果你使用的 Prometheus-Operator 默認(rèn)不能發(fā)現(xiàn) logging 命名空間下面的數(shù)據(jù),則需要?jiǎng)?chuàng)建如下所示的一個(gè) Role 權(quán)限:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.26.0
name: prometheus-k8s
namespace: logging
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: prometheus-k8s
namespace: logging
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: prometheus-k8s
subjects:
- kind: ServiceAccount
name: prometheus-k8s
namespace: monitoring
正常在 Prometheus 里面就可以看到 Promtail 的抓取目標(biāo)了:
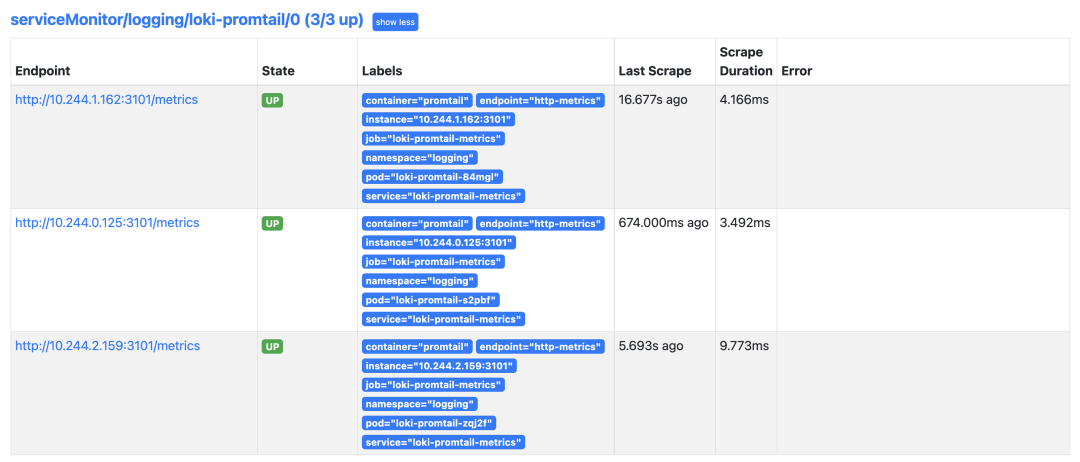
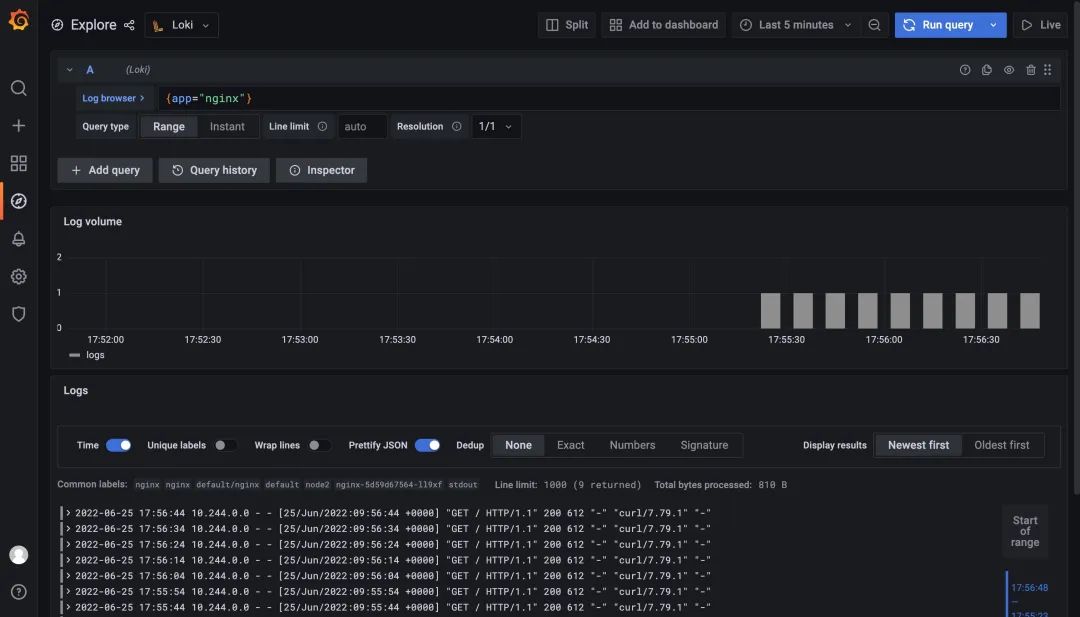
如果你使用的是 Prometheus Operator 自帶的 Grafana,則需要手動(dòng)添加上 Loki 的數(shù)據(jù)源,前面微服務(wù)模式中我們已經(jīng)在 Grafana 中配置了 Loki 的數(shù)據(jù)源,現(xiàn)在當(dāng)我們?cè)L問(wèn)測(cè)試應(yīng)用的時(shí)候,在 Loki 中是可以查看到日志數(shù)據(jù)的:
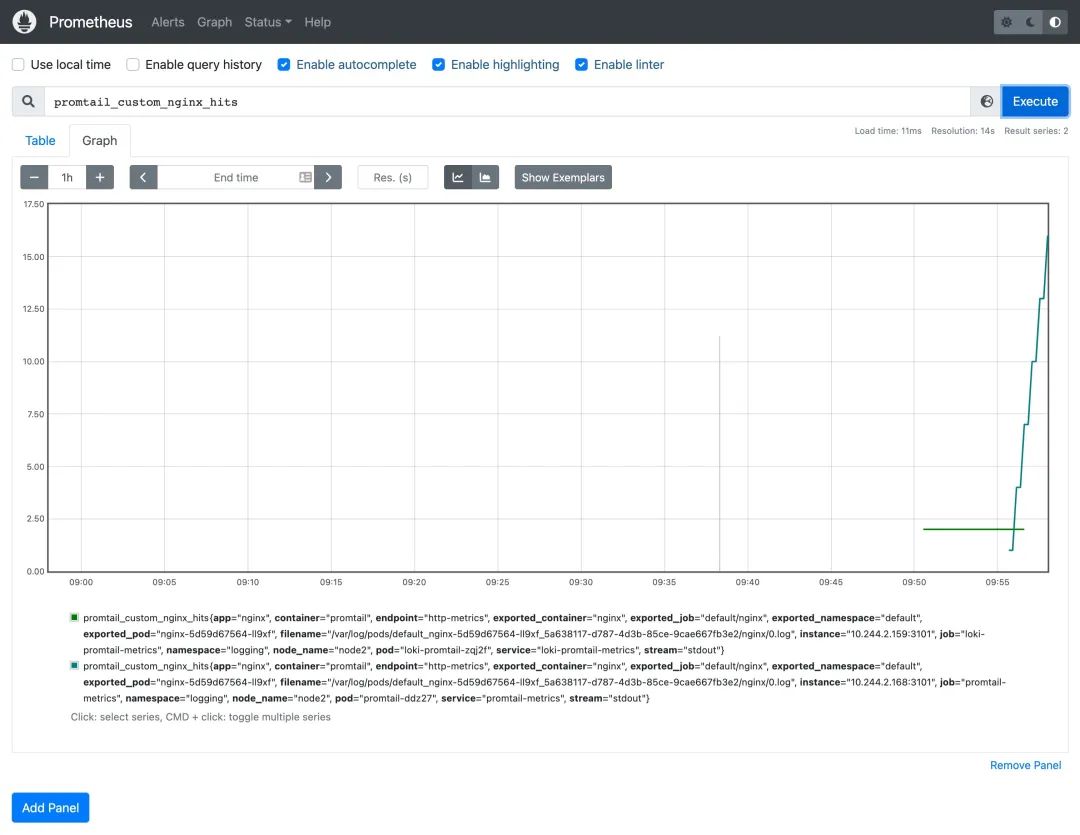
而且現(xiàn)在在 Prometheus 中還可以查詢(xún)到我們?cè)? Promtail 中添加的 metrics 指標(biāo)數(shù)據(jù):
因?yàn)楝F(xiàn)在已經(jīng)有監(jiān)控指標(biāo)了,所以我們就可以根據(jù)需求來(lái)創(chuàng)建報(bào)警規(guī)則了,我們這里使用的 Prometheus Operator,所以可以直接創(chuàng)建一個(gè) PrometheusRule 資源對(duì)象即可:
# nginx-prometheus-rule.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: promtail-nginx-hits
namespace: logging
spec:
groups:
- name: nginx-hits
rules:
- alert: LokiNginxHits
annotations:
summary: nginx hits counter
description: 'nginx_hits total insufficient count ({{ $value }}).'
expr: |
sum(increase(promtail_custom_nginx_hits[1m])) > 2
for: 2m
labels:
severity: critical
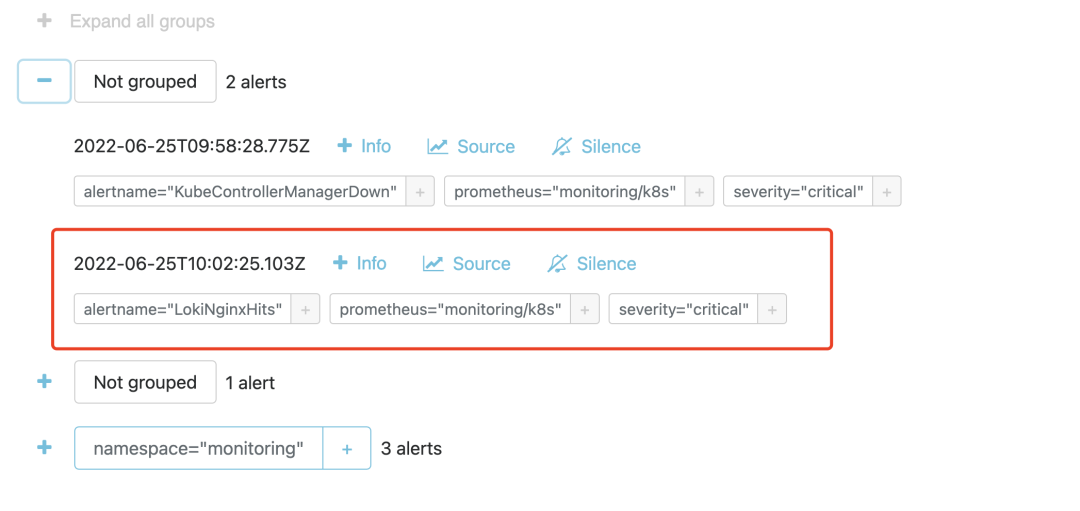
這里我們配置了名為 nginx_hits 的報(bào)警規(guī)則,這些規(guī)則在同一個(gè)分組中,每隔一定的時(shí)間間隔依次執(zhí)行。觸發(fā)報(bào)警的閾值通過(guò) expr 表達(dá)式進(jìn)行配置。我們這里表示的是1分鐘之內(nèi)新增的總和是否大于2,當(dāng) expor 表達(dá)式的條件持續(xù)了2分鐘時(shí)間后,報(bào)警就會(huì)真正被觸發(fā),報(bào)警真正被觸發(fā)之前會(huì)保持為 Pending 狀態(tài)。

然后具體想要把報(bào)警發(fā)送到什么地方去,可以根據(jù)標(biāo)簽去配置 receiver,比如可以通過(guò) WebHook 來(lái)接收。我們?cè)?AlertManager 中也是可以看到接收到的報(bào)警事件的。
Ruler 組件
上面的方式雖然可以實(shí)現(xiàn)我們的日志報(bào)警功能,但是還是不夠直接,需要通過(guò) Promtail 去進(jìn)行處理,那么我們能否直接通過(guò) Loki 來(lái)實(shí)現(xiàn)報(bào)警功能呢?其實(shí)在 Loki2.0 版本就提供了報(bào)警功能,其中有一個(gè) Ruler 組件可以持續(xù)查詢(xún)一個(gè) rules 規(guī)則,并將超過(guò)閾值的事件推送給 AlertManager 或者其他 Webhook 服務(wù),這也就是 Loki 自帶的報(bào)警功能了,而且是兼容 AlertManager 的。
首先我們需要開(kāi)啟 Loki Ruler 組件,更新 loki-distributed 安裝的 Values 文件,在前面微服務(wù)模式的基礎(chǔ)上增加 ruler 組件配置:
# ci/alert-values.yaml
loki:
structuredConfig:
ingester:
max_transfer_retries: 0
chunk_idle_period: 1h
chunk_target_size: 1536000
max_chunk_age: 1h
storage_config: # 存儲(chǔ)的配置,定義其他組件可能用到的存儲(chǔ)
aws: # s3 / s3 兼容的對(duì)象存儲(chǔ)
endpoint: minio.logging.svc.cluster.local:9000
insecure: true
bucketnames: loki-data
access_key_id: myaccessKey
secret_access_key: mysecretKey
s3forcepathstyle: true
boltdb_shipper:
shared_store: s3
schema_config:
configs:
- from: 2022-06-21
store: boltdb-shipper # index
object_store: s3 # chunks
schema: v12
index:
prefix: loki_index_
period: 24h
ruler:
storage:
type: local
local:
directory: /etc/loki/rules
ring:
kvstore:
store: memberlist
rule_path: /tmp/loki/scratch
alertmanager_url: http://alertmanager-main.monitoring.svc.cluster.local:9093
external_url: http:/192.168.0.106:31918
distributor:
replicas: 2
ingester: # WAL(replay)
replicas: 2
persistence:
enabled: true
size: 1Gi
storageClass: local-path
querier:
replicas: 2
persistence:
enabled: true
size: 1Gi
storageClass: local-path
queryFrontend:
replicas: 2
gateway: # nginx容器 -> 路由日志寫(xiě)/讀的請(qǐng)求
nginxConfig:
httpSnippet: |-
client_max_body_size 100M;
serverSnippet: |-
client_max_body_size 100M;
# Configuration for the ruler
ruler:
enabled: true
kind: Deployment
replicas: 1
persistence:
enabled: true
size: 1Gi
storageClass: local-path
# -- Directories containing rules files
directories:
tenant_no:
rules1.txt: |
groups:
- name: nginx-rate
rules:
- alert: LokiNginxRate
expr: sum(rate({app="nginx"} |= "error" [1m])) by (job)
/
sum(rate({app="nginx"}[1m])) by (job)
> 0.01
for: 1m
labels:
severity: critical
annotations:
summary: loki nginx rate
description: high request latency
我們首先通過(guò) loki.structuredConfig.ruler 對(duì) Ruler 組件進(jìn)行配置,比如指定 Alertmanager 的地址,規(guī)則存儲(chǔ)方式等,然后通過(guò) ruler 屬性配置了組件的相關(guān)信息以及報(bào)警規(guī)則,重新使用上面的 values 文件安裝 Loki:
$ helm upgrade --install loki -n logging -f ci/alert-values.yaml .
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
grafana-55d8779dc6-gkgpf 1/1 Running 2 (66m ago) 3d21h
loki-loki-distributed-distributor-56959cc548-xpv6d 1/1 Running 0 3m36s
loki-loki-distributed-distributor-56959cc548-zjfsb 1/1 Running 0 2m52s
loki-loki-distributed-gateway-6f4cfd898c-p9xxf 1/1 Running 0 21m
loki-loki-distributed-ingester-0 1/1 Running 0 2m32s
loki-loki-distributed-ingester-1 1/1 Running 0 3m34s
loki-loki-distributed-querier-0 1/1 Running 0 2m48s
loki-loki-distributed-querier-1 1/1 Running 0 3m29s
loki-loki-distributed-query-frontend-5bcc7949d-brzg6 1/1 Running 0 3m30s
loki-loki-distributed-query-frontend-5bcc7949d-g2wwd 1/1 Running 0 3m35s
loki-loki-distributed-ruler-5d4b8cd889-m2vbd 1/1 Running 0 3m35s
minio-548656f786-mjd4c 1/1 Running 2 (66m ago) 3d21h
promtail-ddz27 1/1 Running 0 19m
promtail-lzr6v 1/1 Running 0 20m
promtail-nldqx 1/1 Running 0 20m
Loki 的 rulers 規(guī)則和結(jié)構(gòu)與 Prometheus 是完全兼容,唯一的區(qū)別在于查詢(xún)語(yǔ)句(LogQL)不同,在 Loki 中我們用 LogQL 來(lái)查詢(xún)?nèi)罩荆粋€(gè)典型的 rules 配置文件如下所示:
groups:
# 組名稱(chēng)
- name: xxxx
rules:
# Alert名稱(chēng)
- alert: xxxx
# logQL查詢(xún)語(yǔ)句
expr: xxxx
# 產(chǎn)生告警的持續(xù)時(shí)間 pending.
[ for: | default = 0s ]
# 自定義告警事件的label
labels:
[ : ]
# 告警時(shí)間的注釋
annotations:
[ : ]
比如我們這里配置的規(guī)則 sum(rate({app="nginx"} |= "error" [1m])) by (job) / sum(rate({app="nginx"}[1m])) by (job) > 0.01 表示通過(guò)日志查到 nginx 日志的錯(cuò)誤率大于1%就觸發(fā)告警,同樣重新使用上面的 values 文件更新 Loki:
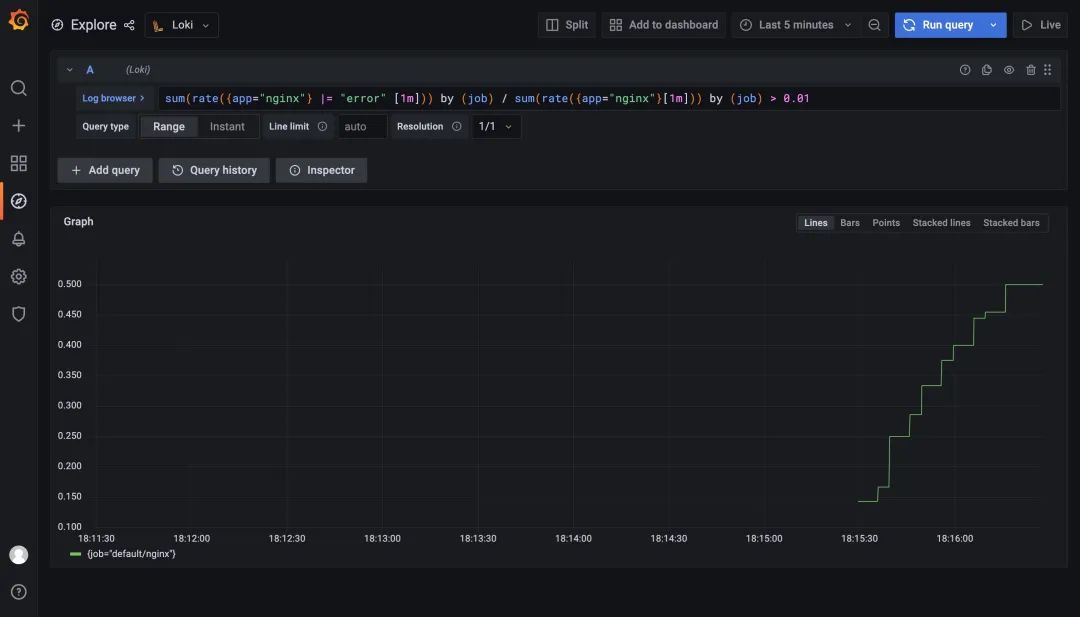
更新完成后我們查看 Ruler 組件的日志可以看到一些關(guān)于上面我們配置的報(bào)警規(guī)則的信息:
$ kubectl logs -f loki-loki-distributed-ruler-5d4b8cd889-m2vbd -n logging
......
level=info ts=2022-06-25T10:10:07.445554993Z caller=metrics.go:122 component=ruler org_id=tenant_no latency=fast query="((sum by(job)(rate({app=\"nginx\"} |= \"error\"[1m])) / sum by(job)(rate({app=\"nginx\"}[1m]))) > 0.01)" query_type=metric range_type=instant length=0s step=0s duration=25.306079ms status=200 limit=0 returned_lines=0 throughput=0B total_bytes=0B queue_time=0s subqueries=1
level=info ts=2022-06-25T10:11:03.196836972Z caller=pool.go:171 msg="removing stale client" addr=10.244.2.165:9095
level=info ts=2022-06-25T10:11:07.423644116Z caller=metrics.go:122 component=ruler org_id=tenant_no latency=fast query="((sum by(job)(rate({app=\"nginx\"} |= \"error\"[1m])) / sum by(job)(rate({app=\"nginx\"}[1m]))) > 0.01)" query_type=metric range_type=instant length=0s step=0s duration=3.234499ms status=200 limit=0 returned_lines=0 throughput=0B total_bytes=0B queue_time=0s subqueries=1
同樣在 1m 之內(nèi)如果持續(xù)超過(guò)閾值,則會(huì)真正觸發(fā)報(bào)警規(guī)則,觸發(fā)后我們?cè)?Alertmanager 也可以看到對(duì)應(yīng)的報(bào)警信息了:
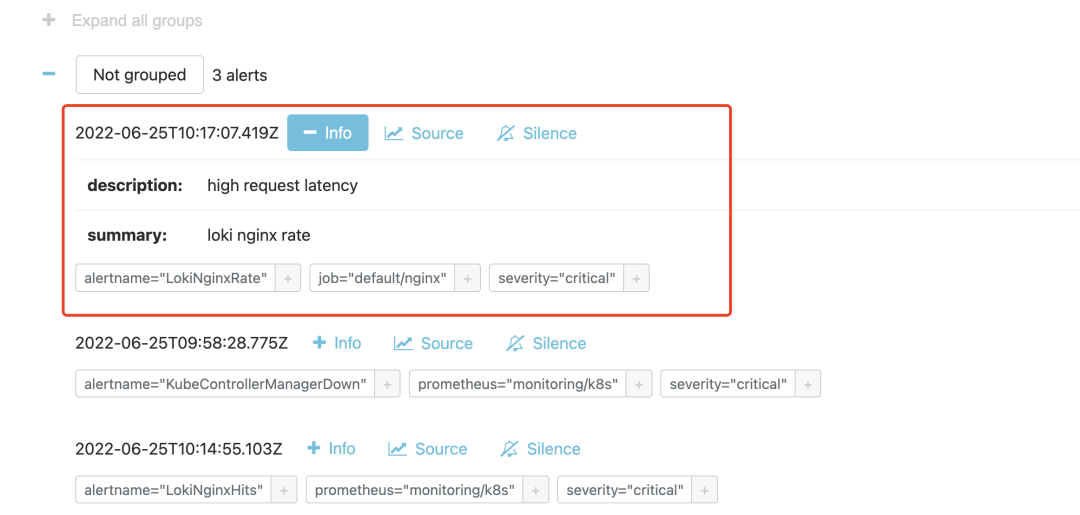
到這里我們就完成了使用 Loki 基于日志的監(jiān)控報(bào)警。