
NVM原生數(shù)據(jù)庫技術(shù)解讀
為讓更多數(shù)據(jù)庫從業(yè)者了解數(shù)據(jù)庫領(lǐng)域最新研究成果,熟悉行業(yè)前沿發(fā)展趨勢,騰訊云數(shù)據(jù)庫計劃舉辦系列“DB · 洞見”活動,打造數(shù)據(jù)庫技術(shù)交流平臺,邀請學(xué)界及騰訊技術(shù)大咖,解讀數(shù)據(jù)庫基礎(chǔ)技術(shù)創(chuàng)新趨勢,分享數(shù)據(jù)庫技術(shù)創(chuàng)新成果。
今天為大家?guī)怼癉B ·?洞見”系列活動第一期的部分內(nèi)容,由中國人民大學(xué)信息學(xué)院計算機科學(xué)與技術(shù)系主任柴云鵬教授解讀NVM原生數(shù)據(jù)庫技術(shù),以下是分享實錄:
NVM原生數(shù)據(jù)庫概述
今天我分享的主題為“NVM原生數(shù)據(jù)庫技術(shù)”,內(nèi)容分三個部分,主要涉及到下面這五篇VLDB 2021的論文。首先我先來介紹下NVM原生數(shù)據(jù)庫整體的情況。??? ? ?
 1.1 NVM原生數(shù)據(jù)庫發(fā)展?fàn)顩r
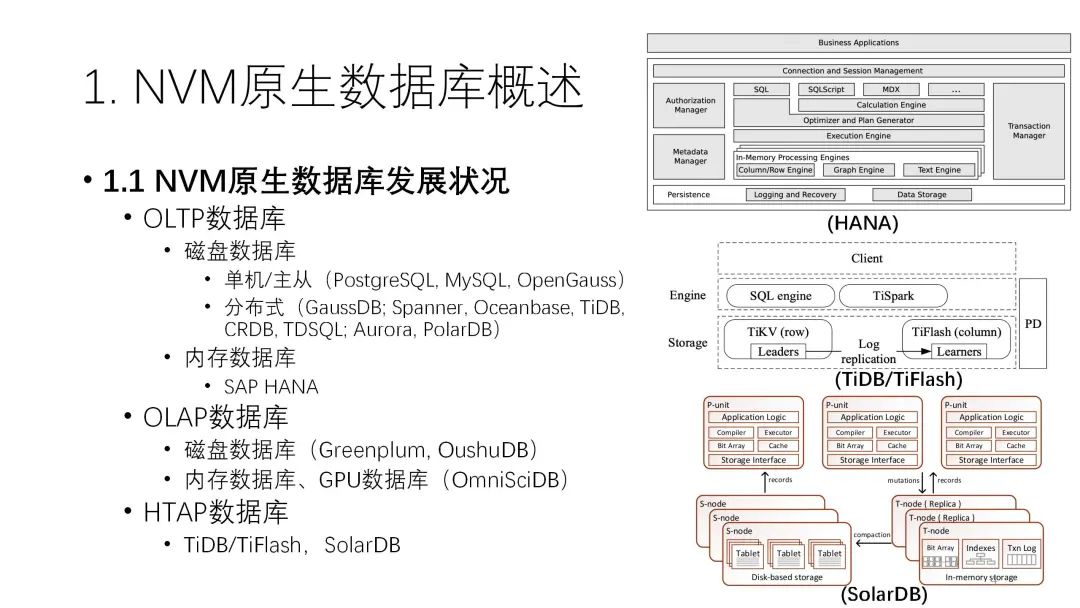
1.1 NVM原生數(shù)據(jù)庫發(fā)展?fàn)顩r現(xiàn)有的數(shù)據(jù)庫系統(tǒng)可以分成OLTP數(shù)據(jù)庫、OLAP數(shù)據(jù)庫和HTAP數(shù)據(jù)庫。
OLAP數(shù)據(jù)庫傳統(tǒng)上一直是以磁盤數(shù)據(jù)庫為主,即使到現(xiàn)在很多地方都以SSD為主,但還是采用磁盤數(shù)據(jù)庫技術(shù)。從早期的單機架構(gòu)發(fā)展到分布式,從主從到現(xiàn)在的存算分離,磁盤數(shù)據(jù)庫發(fā)展出了很多優(yōu)秀數(shù)據(jù)庫產(chǎn)品,是發(fā)展的最快的領(lǐng)域。另外一個分支則是比較高端的內(nèi)存數(shù)據(jù)庫或一體機,比較典型的就是HANA系統(tǒng)。磁盤數(shù)據(jù)庫和內(nèi)存數(shù)據(jù)庫的產(chǎn)品區(qū)分很明確,定位的場景、價格、容量各方面差距都很大。
OLAP數(shù)據(jù)庫方面也是類似的情況,因為大數(shù)據(jù)分析的量比較大,還是以磁盤數(shù)據(jù)庫為主。少部分的內(nèi)存或者GPU數(shù)據(jù)庫速度比較快,但數(shù)據(jù)規(guī)模特別小,所以實際上使用范圍也不是特別大。HTAP數(shù)據(jù)庫也一樣,傳統(tǒng)上也是分磁盤和內(nèi)存兩種介質(zhì)。? ? ??
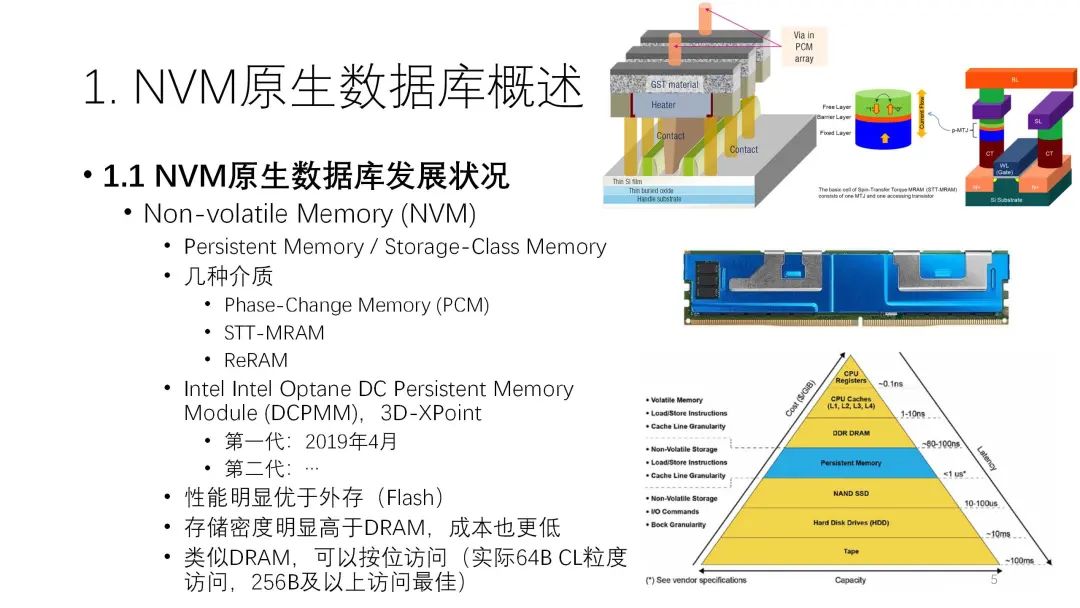
NVM即非易失內(nèi)存是近年來新出現(xiàn)的介質(zhì)。嚴(yán)格來說,NVM指的不是一種介質(zhì),而是一系列的介質(zhì),包括PCM相變存儲器、STT-MRAM、ReRAM憶阻器等,這些介質(zhì)之間也有很大的差別。NVM產(chǎn)品真正推出是在2019年,由英特爾公司研發(fā),目前已經(jīng)有了第二代產(chǎn)品。
NVM從性質(zhì)上看介于磁盤和內(nèi)存兩者之間,性能明顯優(yōu)于外存,存儲密度高于DRAM,成本也更低。此外,它還類似于DRAM,可以按位訪問,最小的粒度一般還是256B。?
??? ? ? ? ? ?
? ? ? ? ?NVM這種介質(zhì)如果后續(xù)逐漸成熟,對整個數(shù)據(jù)庫產(chǎn)品會有很大的意義。基于現(xiàn)在的內(nèi)存數(shù)據(jù)庫或者重新定制NVM原生的數(shù)據(jù)庫,它可以達到內(nèi)存數(shù)據(jù)庫的性能,而且可以擴展內(nèi)存空間,達到一個數(shù)量級左右,同時也可以幫助OLTP、OLAP、或者HTAP數(shù)據(jù)庫降低成本,數(shù)據(jù)規(guī)模也可以上得去,做得更實用。
但它也帶來了很多挑戰(zhàn)。首先,因為NVM是一個全新的東西,它既像內(nèi)存又像外存,可以當(dāng)成內(nèi)存去用,但現(xiàn)在不能直接的保持持久化,必須要加額外的匯編指令,如果把它當(dāng)成外存又好像浪費了它的某些屬性,這種情況下怎么去用它就是一個問題。其次,數(shù)據(jù)庫傳統(tǒng)當(dāng)中各個核心模塊的技術(shù)研究了幾十年,如果應(yīng)用到NVM上就有很多模塊需要重新設(shè)計。最后,這些年新出的存儲性硬件的特性都很強,但NVM介質(zhì)還存在很多問題,要如何去適應(yīng)硬件的特性也是個問題。
? ? ? ? 目前對于NVM的研究還處于模塊化階段,還不夠完善,還沒有真正比較大規(guī)模、比較實用的產(chǎn)品出現(xiàn),當(dāng)前的研究主要集中在以下幾個方面:
目前對于NVM的研究還處于模塊化階段,還不夠完善,還沒有真正比較大規(guī)模、比較實用的產(chǎn)品出現(xiàn),當(dāng)前的研究主要集中在以下幾個方面:首先是最流行的NVM索引研究,在NVM設(shè)備出來之前就已經(jīng)有人在研究了。索引里又可分為幾種:第一種是比較快速的Hash索引,但是它不支持范圍查詢,所以數(shù)據(jù)庫里一般還是有序索引比較多;第二種是基于B-Tree的索引;第三種是基于前綴樹的索引;第四種是基于LSM Tree即日志結(jié)構(gòu)合并樹的索引,很多人認(rèn)為從原理上講它不是很適合NVM,但因為LSM Tree確實有自己的優(yōu)勢,比如說寫操作比較好、訪問連續(xù)、利于壓縮,同時NVM的特性又沒有想象中那么接近于內(nèi)存,它的連續(xù)和隨機寫之間差別比較大,所以慢慢很多人也開始研究LSM Tree的NVM化,就是把SSD/NVM都加到這里面,做成一個更大容量但性能比SLM Tree引擎好很多的索引;最后一種是混合索引,即用DRAM加上NVM,它們之間的配合可能是多個索引,也可能是拼接索引,雖然這方面的研究不是特別主流,但因為DRAM性能遠遠好于NVM,因此混合還是有意義的。
其次是空間的分配,因為NVM和DRAM有很大差別,它多了一個空間分配。再者是日志和恢復(fù),因為NVM本身是關(guān)于持久化的,所以NVM的按位訪問,它的一種介質(zhì)既可以持久化,又可以非持久化,這就會帶來很大差別。最后是緩沖區(qū)。? ? ? ?
 1.2 NVM硬件特性:現(xiàn)在與未來
1.2 NVM硬件特性:現(xiàn)在與未來這部分主要是借助VLDB的這篇論文來介紹現(xiàn)在的NVM產(chǎn)品,以及暢想未來的NVM產(chǎn)品的特性。首先我們先來了解下目前NVM的硬件特性,這些都是業(yè)界認(rèn)可的。? ???
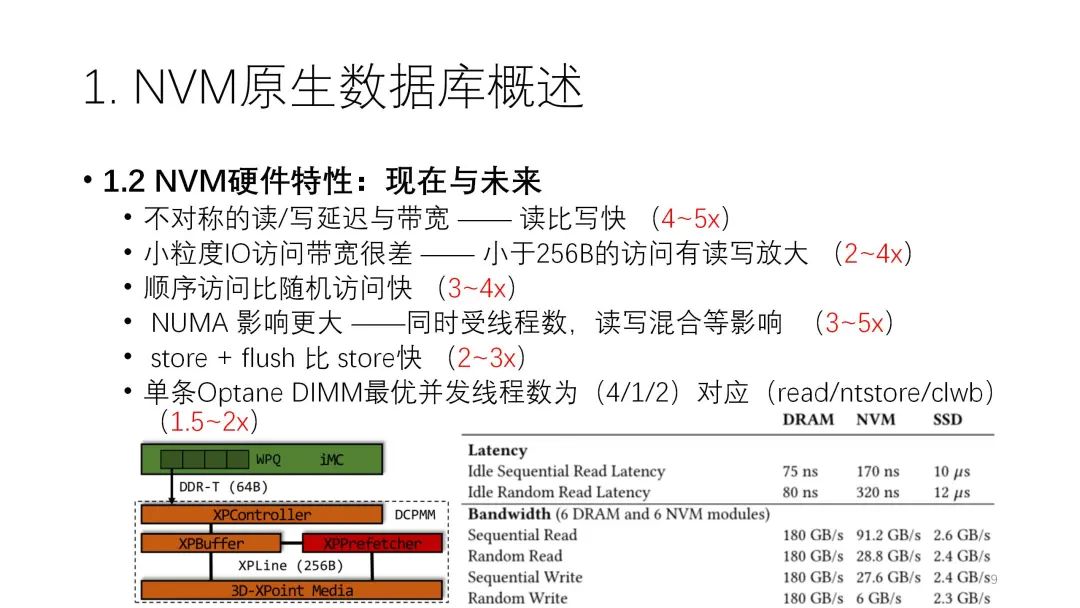 ? ? ? ? ?下面我們就這篇論文來詳細分析。該論文總結(jié)了NVM硬件的七個特征,并簡單介紹了它的特征以及主要原因,還有適用哪幾類NVM的類型。
? ? ? ? ?下面我們就這篇論文來詳細分析。該論文總結(jié)了NVM硬件的七個特征,并簡單介紹了它的特征以及主要原因,還有適用哪幾類NVM的類型。注:下圖中的C1指的是比較早的NVM硬件,上面的介質(zhì)還是DRAM,只是加了電池或電容。C2、C3是假想的,即假設(shè)某些產(chǎn)品用了一些cache和預(yù)取器,在這種情況下看各個特征是不是對每一類都適用。C4指的是英特爾已經(jīng)推出的產(chǎn)品。??? ? ?
 ? ? ? ? ?
? ? ? ? ?前兩類都是讀寫不平衡,store指的是持久化的store,它的延遲和帶寬都不匹配。首要的原因是介質(zhì)的影響,我們現(xiàn)在用的3D XPoint或者PCM實際上就是讀快寫慢。此外,在延遲方面也和CPU的緩存有很大的關(guān)系。
在帶寬方面,除了介質(zhì)的原因外,控制器相關(guān)的征用對一些資源也有影響。在數(shù)據(jù)DRAM中,讀的帶寬能到76G/s,寫的帶寬能到42G/s,兩者有一定差別,但不是很大。但到了NVM,讀是30G/s,寫大概是8G/s,差別就比較大。在讀寫差異這一點上,NVM比內(nèi)存放大很多,是2.5倍和5.2倍的差別。
? ? ? ? ? ? ? ? ?
? ? ? ? ?
 ? ? ? ? ?從訪問粒度來看,從小到大,性能帶寬應(yīng)該是逐漸提高的,到256B之后基本逐漸比較穩(wěn)定,但是到4K一般會有下滑,再后面就基本比較穩(wěn)定。到4K比較差的原因是內(nèi)部有interleave。一般情況下,一個CPU可以放6條NVM,它會做interleave即并行化,這個力度是4K。如果都是4K,很多訪問可能就會在各個通道上負載不均衡,從而導(dǎo)致性能有一定下滑。? ? ? ?
? ? ? ? ?從訪問粒度來看,從小到大,性能帶寬應(yīng)該是逐漸提高的,到256B之后基本逐漸比較穩(wěn)定,但是到4K一般會有下滑,再后面就基本比較穩(wěn)定。到4K比較差的原因是內(nèi)部有interleave。一般情況下,一個CPU可以放6條NVM,它會做interleave即并行化,這個力度是4K。如果都是4K,很多訪問可能就會在各個通道上負載不均衡,從而導(dǎo)致性能有一定下滑。? ? ? ?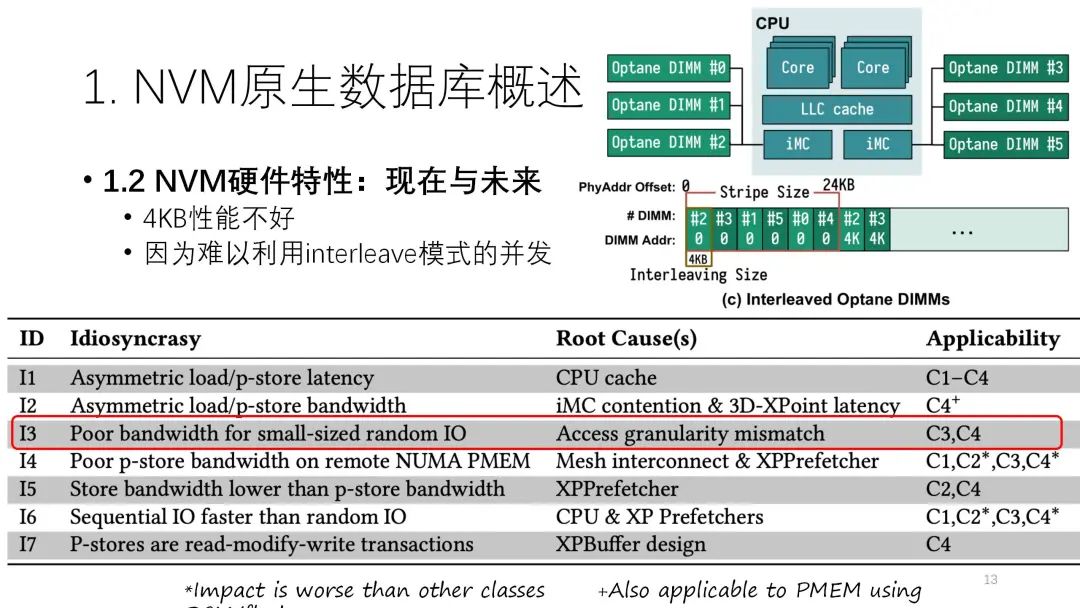 ? ? ? ? ?第四類就是NUMA影響更大。下圖的測試中,上面是內(nèi)存的NUMA訪問和普通訪問之間的性能差異,下面則是NVM的NUMA訪問和普通訪問之間的性能差異。綠色表示差異不大,顏色越深越藍說明差異越大。從圖上看,NVM的NUMA訪問明顯更差。原因則和NVM之間的連接以及預(yù)取器有關(guān)。
? ? ? ?
? ? ? ? ?第四類就是NUMA影響更大。下圖的測試中,上面是內(nèi)存的NUMA訪問和普通訪問之間的性能差異,下面則是NVM的NUMA訪問和普通訪問之間的性能差異。綠色表示差異不大,顏色越深越藍說明差異越大。從圖上看,NVM的NUMA訪問明顯更差。原因則和NVM之間的連接以及預(yù)取器有關(guān)。
? ? ? ? ? ? ? ? ?第五類是有時store的帶寬比持久化的p-spore還要小。
? ? ? ?
? ? ? ? ?第五類是有時store的帶寬比持久化的p-spore還要小。
? ? ? ? ? ? ? ? ?
? ? ? ? ?第六類是連續(xù)訪問和隨機訪問比較快。
最后一類是NVM的并發(fā)度有較大的限制。內(nèi)存能夠支持的并發(fā)數(shù)量比較大,它的性能比較好。但是NVM就不同,讀和寫的并發(fā)度并不一致。? ?? ?
 ? ? ? ? ?這篇文章也給了部分建議:避免持久化的寫,適度的、按照硬件特征的并發(fā),避免特別小的I/O,要限制NUMA訪問,盡量避免隨機I/O和避免transactions等。但是要在實際系統(tǒng)中去用好這些NVM的特性也并非容易。? ? ??
? ? ? ? ?這篇文章也給了部分建議:避免持久化的寫,適度的、按照硬件特征的并發(fā),避免特別小的I/O,要限制NUMA訪問,盡量避免隨機I/O和避免transactions等。但是要在實際系統(tǒng)中去用好這些NVM的特性也并非容易。? ? ??
NVM原生數(shù)據(jù)庫核心技術(shù)
2.1 NVM索引技術(shù)
索引方面的研究是最多的,最主流的是基于B+樹、B樹或前綴樹這種樹型結(jié)構(gòu)的有序索引,這個對數(shù)據(jù)庫來說可能更重要些。
NVM索引技術(shù)的研究前幾年做得比較多,大體的研究思路是:樹形結(jié)構(gòu)里,最下面一層放到NVM里,前面的中間節(jié)點放在DRAM,這樣可以減少一些NVM的寫入,恢復(fù)的時候可以通過最下面一層再把上面一層恢復(fù)出來,利用這些減少寫來提升性能。
這篇論文實際上是對NVM內(nèi)存上的哈希索引做了一個比較全面的測評,他選了六種比較常見的、比較新的結(jié)構(gòu),分別是Level Hash、Clevel Hash、CCEH、Dash、PCLHT、SOFT六個索引。接下來我們先介紹下這六種技術(shù)。? ? ? ?

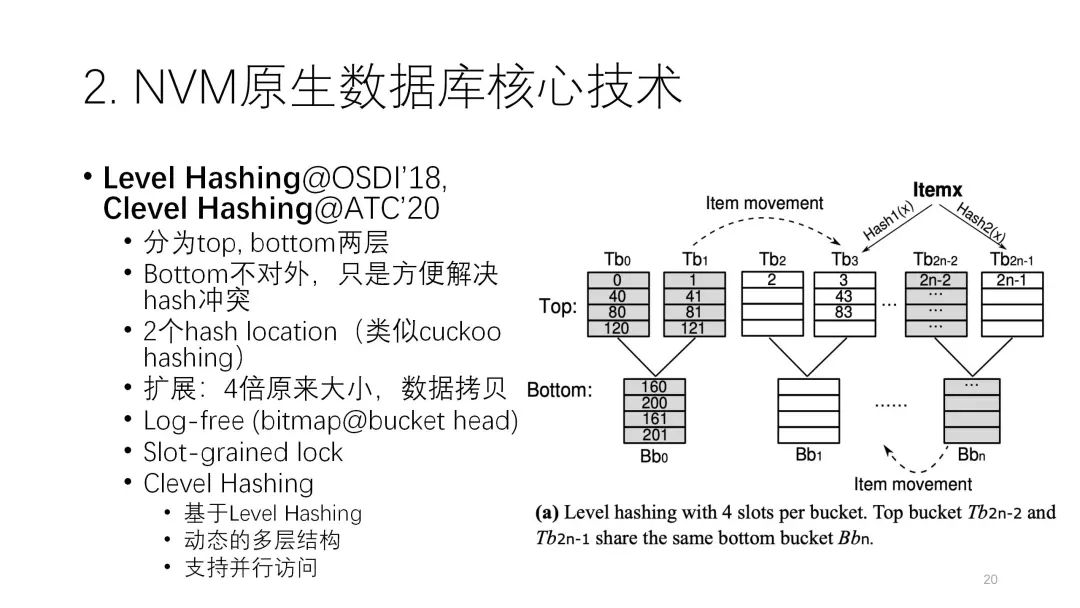
首先,Level Hash和Clevel Hash實際上是一個系列工作,最大的特征是減少和解決哈希沖突。最上面這一層是正常的桶,每兩個后面可以加一個bottom層的桶,這個的好處在于,一開始下面的桶是空的,一旦沖突了就可以利用下面的桶往里放。因為沖突的情況不是特別頻繁,所以它的容量比上面正常TOP層的要少一半,關(guān)鍵是左右兩個分支都可以共用這樣的結(jié)構(gòu)。這就從空間利用上和減小哈希沖突的開銷上起到了trade off的作用。
Clevel Hash也是類似的,可能是更深層次和動態(tài)決定的多層結(jié)構(gòu)。上面也用了哈希,有兩個哈希盡可能的減少沖突,涉及了log-free這種slot級別的鎖來優(yōu)化它。? ??
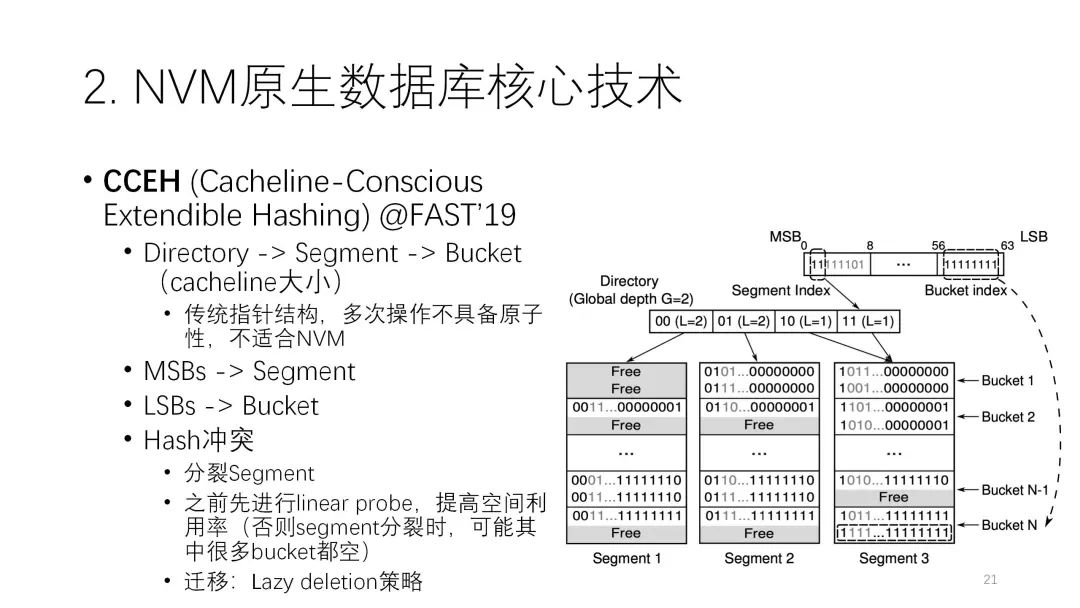
 ? ? ? ? ?第三個CCEH是FAST19的研究,是Cache Line相關(guān)的可擴展的索引。傳統(tǒng)上這種Extendible Hash 已經(jīng)有比較多的研究,它的架構(gòu)都是有目錄,再連到下面的數(shù)據(jù)。但這種傳統(tǒng)結(jié)構(gòu)的指針比較多,而指針在NVM上并不是很友好。指針的更新是比較小粒度的隨機寫,可能數(shù)據(jù)量不大,但對NVM的開銷比較大,所以傳統(tǒng)結(jié)構(gòu)不太適合NVM。因此它做了一個比較大的改進,改成了一個更簡單的結(jié)構(gòu),就是三層的結(jié)構(gòu),directory、segment、bucket。下圖中大的是segment,里面一行行的是一個個的bucket,每個Key里通過最前面的這部分來確定是哪個segment,通過后面來確定bucket。
? ? ? ? ?第三個CCEH是FAST19的研究,是Cache Line相關(guān)的可擴展的索引。傳統(tǒng)上這種Extendible Hash 已經(jīng)有比較多的研究,它的架構(gòu)都是有目錄,再連到下面的數(shù)據(jù)。但這種傳統(tǒng)結(jié)構(gòu)的指針比較多,而指針在NVM上并不是很友好。指針的更新是比較小粒度的隨機寫,可能數(shù)據(jù)量不大,但對NVM的開銷比較大,所以傳統(tǒng)結(jié)構(gòu)不太適合NVM。因此它做了一個比較大的改進,改成了一個更簡單的結(jié)構(gòu),就是三層的結(jié)構(gòu),directory、segment、bucket。下圖中大的是segment,里面一行行的是一個個的bucket,每個Key里通過最前面的這部分來確定是哪個segment,通過后面來確定bucket。它解決哈希沖突的最原始版本就是,當(dāng)沖突時把segment翻倍,再擴大一個segment,這樣第二個沖突就可以寫到后面新的segment里,這種叫Extendible,它可以很靈活地擴展哈希表的空間。但如果直接用也會產(chǎn)生問題,為了一個bucket沖突去擴展segment,那這個segment上下會有很多空置,平均算下來空間利用率很低。所以這里也做了一些改進,先去做探索,盡可能提高segment里的空間利用率,實在不行再去做擴展,也有一些lazy的策略減少開銷。? ? ? ?
 ? ? ? ? ?第四個Dash是VLDB2020的研究,基本結(jié)構(gòu)和CCEH相似,但它針對CCEH空間利用率較低的問題做了改進,主要是三個技術(shù):第一個是Balanced insert,指每次插入的位置實際上有多個選擇,這樣就降低了沖突的概率;第二個是Displacement,指如果b和b+1這兩個都滿了,就可以調(diào)整,這樣就減少一些沖突;第三個是Stash,指最后有兩個隱藏的空間,如果這個segment實在是調(diào)不開,那就可以利用隱藏的空間存,這在一定程度上也可以減少segment再擴展的頻率,每個segment可以相對壓得更實一點,提高空間利用率,后面的實驗結(jié)果也可以看出,它這方面比CCEH強。?? ?
? ? ? ? ?第四個Dash是VLDB2020的研究,基本結(jié)構(gòu)和CCEH相似,但它針對CCEH空間利用率較低的問題做了改進,主要是三個技術(shù):第一個是Balanced insert,指每次插入的位置實際上有多個選擇,這樣就降低了沖突的概率;第二個是Displacement,指如果b和b+1這兩個都滿了,就可以調(diào)整,這樣就減少一些沖突;第三個是Stash,指最后有兩個隱藏的空間,如果這個segment實在是調(diào)不開,那就可以利用隱藏的空間存,這在一定程度上也可以減少segment再擴展的頻率,每個segment可以相對壓得更實一點,提高空間利用率,后面的實驗結(jié)果也可以看出,它這方面比CCEH強。?? ?
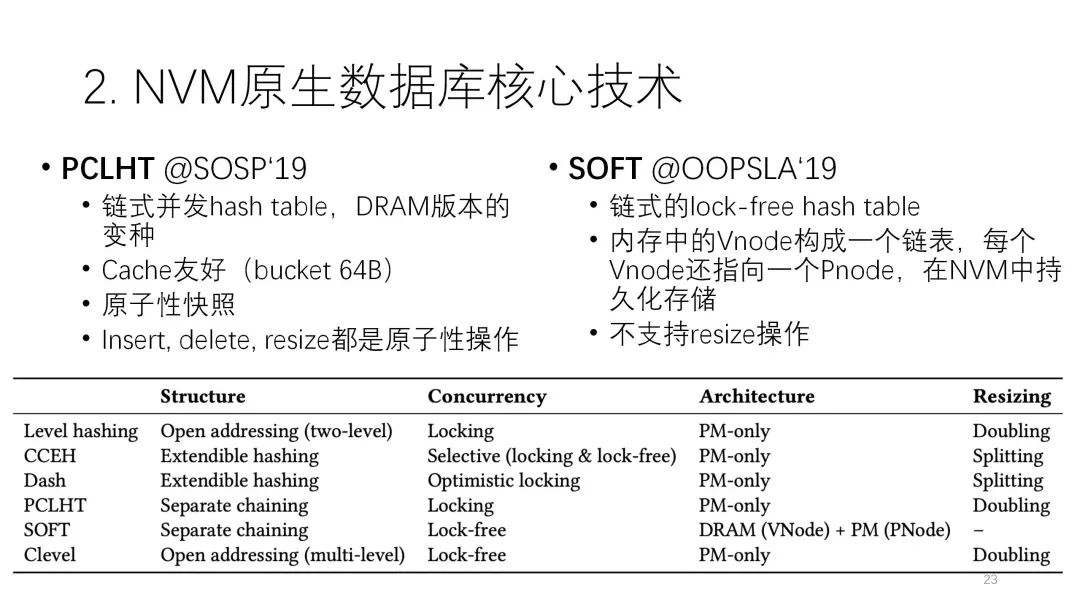
最后兩個都是鏈?zhǔn)降墓1?/span>。PCLHT是鏈?zhǔn)降牟l(fā)哈希,它原來有DRAM的版本,后面做了NVM的改進,包括對cache的友好,原則性的訪問等等。SOFT的特點是,有VM的部分,也有NVM的部分,它的數(shù)據(jù)在這兩邊都會存。?
? ?? ??下圖是這篇論文測評結(jié)果。從圖中可以看出,左邊是Uniform分布,左邊是傾斜分布,中間這兩個是讀和寫的情況。讀的操作里,這幾個索引都不錯,但還是鏈?zhǔn)降腜CLHT,它的性能是相對比較好,在這里面比較突出。寫的方面是SOFT,CCEH比較好。寫的性能影響到PM的寫放大,每個索引和原始的寫操作比起來,寫放大都很多,寫放大的多少直接影響到它的性能,包括resize,整體來看還是這個各種情況下相對比較好,像CCEH、Dash這些確實是優(yōu)秀的。? ? ? ?
??下圖是這篇論文測評結(jié)果。從圖中可以看出,左邊是Uniform分布,左邊是傾斜分布,中間這兩個是讀和寫的情況。讀的操作里,這幾個索引都不錯,但還是鏈?zhǔn)降腜CLHT,它的性能是相對比較好,在這里面比較突出。寫的方面是SOFT,CCEH比較好。寫的性能影響到PM的寫放大,每個索引和原始的寫操作比起來,寫放大都很多,寫放大的多少直接影響到它的性能,包括resize,整體來看還是這個各種情況下相對比較好,像CCEH、Dash這些確實是優(yōu)秀的。? ? ? ?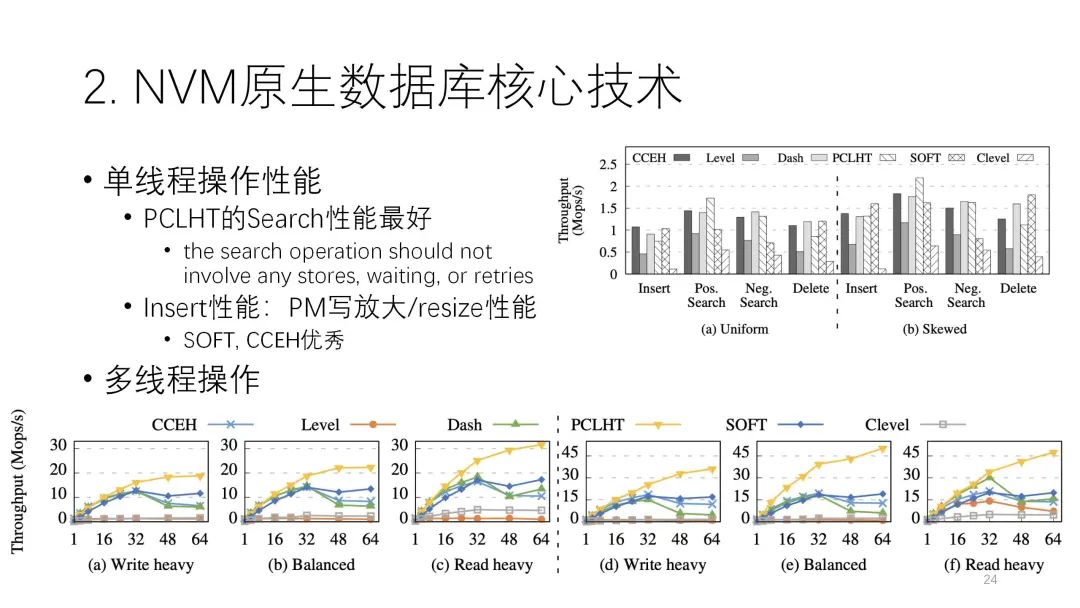
下圖中這個值代表內(nèi)存利用率。Dash也是基于CCEH做了空間的改進,確實是最優(yōu)。中間這個圖是它的PM寫放大,最下面這個灰色的是它原始的寫入,其他的都是放大出來的,所以可以很清楚地看到誰放大得比較多,像SOFT、CCEH這兩個寫放大比較少,所以它的性能確實是比較好。
在恢復(fù)時間上這幾個都差不多,只有SOFT有點差,這方面是它典型的劣勢,且SOFT沒辦法擴展,現(xiàn)在還不是特別實用,但其他幾個索引還是不錯的。? ? ? ?
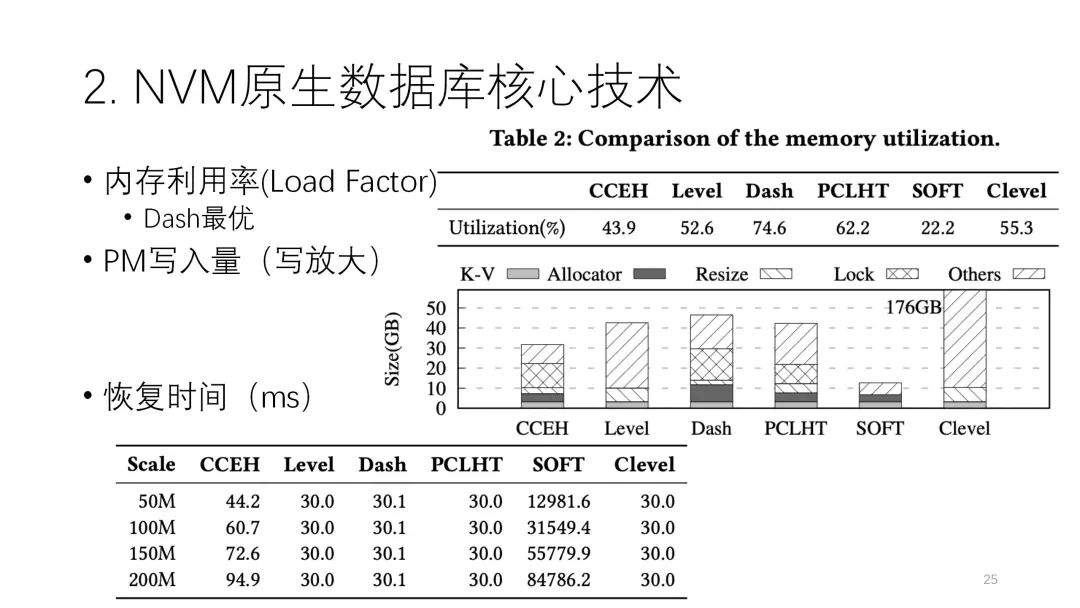 ? ? ? ? ?這篇文章也總結(jié)了以下經(jīng)驗,這些不一定局限在哈希,在更大的范圍內(nèi)都是有效的。? ? ?
? ? ? ? ?這篇文章也總結(jié)了以下經(jīng)驗,這些不一定局限在哈希,在更大的范圍內(nèi)都是有效的。? ? ? 2.2 NVM日志技術(shù)
2.2 NVM日志技術(shù)第二部分介紹日志技術(shù)。日志傳統(tǒng)上采用的是WAL,它的好處有很多,首要的是可以更好地利用buffer。我們寫入設(shè)備主要是連續(xù)寫,性能還是不錯的,但缺點是數(shù)據(jù)和日志要寫兩遍,這個會有一定的開銷。
這方面之前比較經(jīng)典的研究是VLDB 2016 的WBL,它和WAL是相反的兩種很典型的技術(shù)。它最大的訴求是只寫一遍。為了達到這個目標(biāo),它把日志縮得很小,只有一些元信息和時間信息,而數(shù)據(jù)不用放到日志里。數(shù)據(jù)再讀完后直接寫到下面持久化的設(shè)備里,上面是volatile,下面是durable,它實際上是寫完buffer之后先寫數(shù)據(jù),但是是以MVCC的方式去寫。當(dāng)一個數(shù)要提交的時候,必須保證是寫到數(shù)據(jù)表里,這時數(shù)據(jù)才能提交。這樣的話,寫放大明顯減少了,帶來更大的好處是,因為數(shù)據(jù)不在日志里,是在表里,不用掃數(shù)據(jù),也不用去重構(gòu),所以它的回來時間可以忽略不計,速度達到上百倍的提升。
今天介紹的這兩篇論文,實際上在事務(wù)、日志和恢復(fù)這方面都是沿著WBL的思路,但也會有一些新的東西。 ? ? ? ?
 ? ? ? ? ?陳世敏老師團隊的這篇論文,主要針對的是:假設(shè)用NVM構(gòu)建OLTP數(shù)據(jù)庫,實際上會面臨三個比較大的性能挑戰(zhàn)。
? ? ? ? ?陳世敏老師團隊的這篇論文,主要針對的是:假設(shè)用NVM構(gòu)建OLTP數(shù)據(jù)庫,實際上會面臨三個比較大的性能挑戰(zhàn)。第一個是元數(shù)據(jù)要進行頻繁的修改,尤其是在事務(wù)執(zhí)行過程中為了進行閉環(huán)控制,需要有很多元數(shù)據(jù)的修改。傳統(tǒng)上我們會把元數(shù)據(jù)持久化保存到持久化設(shè)備中,比如說NVM里,帶來的小粒度隨機寫是很多的,這個是很大的性能開銷。第二個是WAL的數(shù)據(jù)、日志寫兩遍的問題。第三個則是WAL的空間分配有其特殊的問題。
DRAM的空間分配之所以簡單,是因為當(dāng)DRAM真正宕機去恢復(fù)的時候,實際上系統(tǒng)是從空的開始,只需要從日志里構(gòu)建內(nèi)存的東西就行。但是在NVM里,它的數(shù)據(jù)是非易失的,所以當(dāng)它重啟后,里面的數(shù)據(jù)是直接去用的,而不是播放一遍日志去重建,所以這時每個分配出來的空間到底用沒用,一定要把元數(shù)據(jù)弄清楚,不然就會出現(xiàn)空間的泄露或者是不一致。 ? ? ? ?
 ? ? ? ? ?接下來這篇論文總結(jié)了NVM數(shù)據(jù)庫的四種架構(gòu):
? ? ? ? ?接下來這篇論文總結(jié)了NVM數(shù)據(jù)庫的四種架構(gòu):第一種是基于傳統(tǒng)的內(nèi)存數(shù)據(jù)庫擴展,比如用部分NVM空間去擴展這些內(nèi)存的空間,因為NVM可以當(dāng)成易失的模式,還有一部分NVM當(dāng)成非易失的模式,用來存日志,這是一個簡單又典型的思路,也能基于現(xiàn)有的內(nèi)存數(shù)據(jù)庫的代碼進行繼承和修改。
但是它有兩個缺點:第一個缺點是有三份重復(fù)寫,除了傳統(tǒng)WAL和checkpoint這兩部分外,volatile的NVM也充當(dāng)DRAM的角色,但是它的寫實際上要比DRAM要慢,所以一個數(shù)據(jù)可能先要寫到這邊,然后再寫到日志里,它的寫放大會更嚴(yán)重。第二個缺點是數(shù)據(jù)規(guī)模在增大的時候,DRAM起的作用會越來越小,主要還是NVM來起作用,所以它的性能會隨著使用下降,由NVM來去制約。 ? ? ? ?
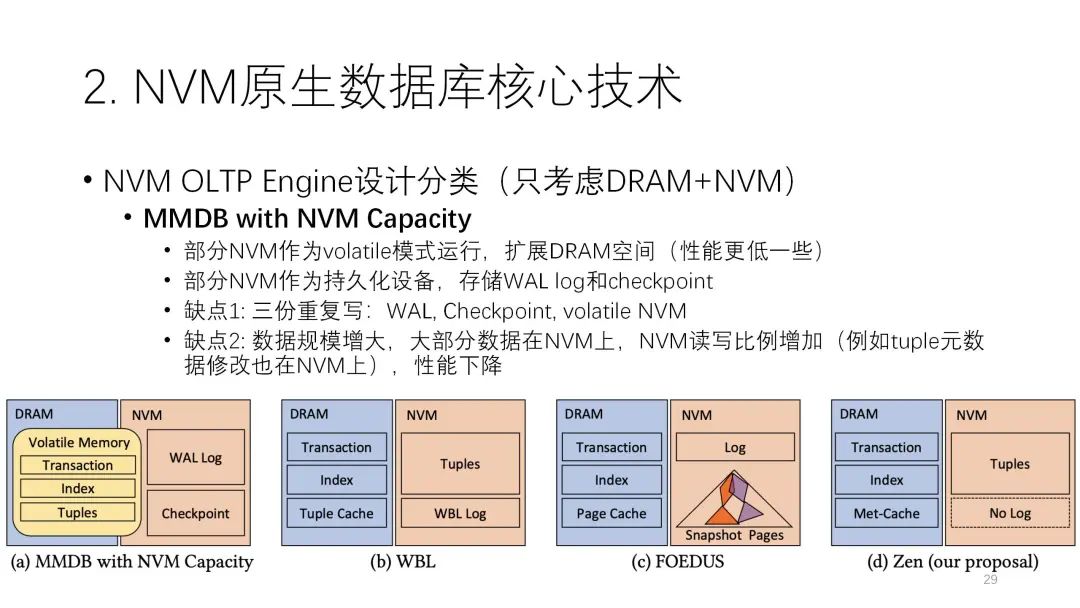 第二種是WBL,它基本上沒什么日志,主要都是在數(shù)據(jù)里。
第二種是WBL,它基本上沒什么日志,主要都是在數(shù)據(jù)里。第三種是WAL,每一個數(shù)據(jù)有兩個指針,一個指向內(nèi)存里的page cache,一個指向NVM當(dāng)中的快照,cache有的就從這讀,沒有的從快照里讀,從日志的角度看還是WAL,但它的性能相對是比較差的。? ? ? ?
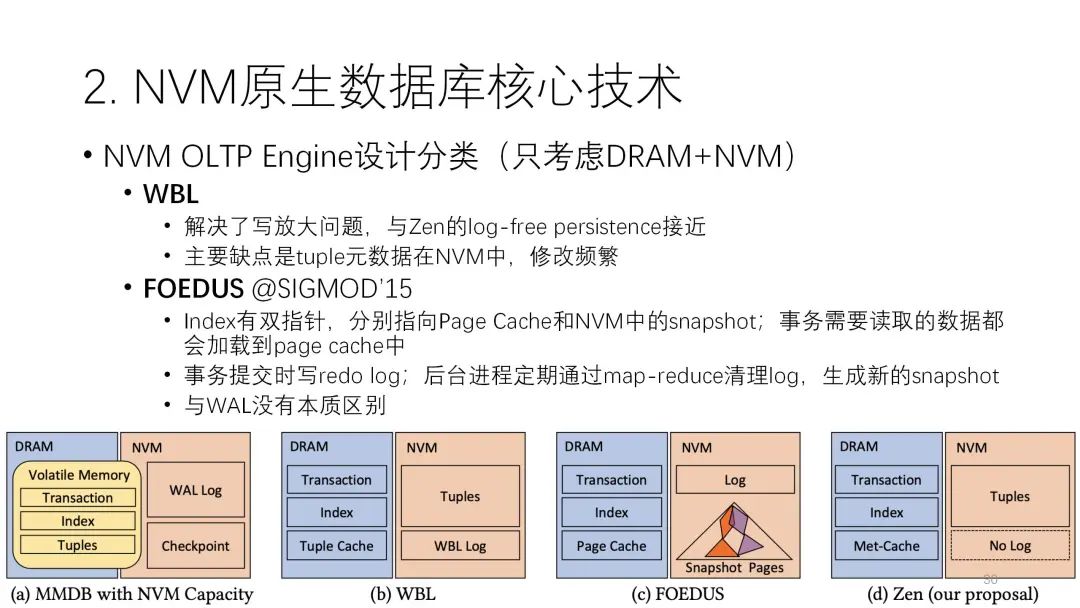 ? ? ? ? ?第四種是論文提出來的架構(gòu),和WBL架構(gòu)有些接近。接下來我將介紹它的幾個技術(shù)。
? ? ? ? ?第四種是論文提出來的架構(gòu),和WBL架構(gòu)有些接近。接下來我將介紹它的幾個技術(shù)。第一個重要的技術(shù)是matcache in DRAM,就是要盡可能的把DRAM的性能用好。它存儲的形式是:DRAM的索引不持久化,全在DRAM里,很多元數(shù)據(jù)也都在這里面,包括分配器的元數(shù)據(jù),盡量把內(nèi)存的空間用完,全都用做緩存,NVM里只存少量的元數(shù)據(jù)還有正常的表。前面說的tuple的元數(shù)據(jù)在控制過程中用到的元數(shù)據(jù)的修改,實際上都可以在內(nèi)存里進行,這樣性能就會好很多,可以減少很多NVM的寫入。 ? ? ? ?
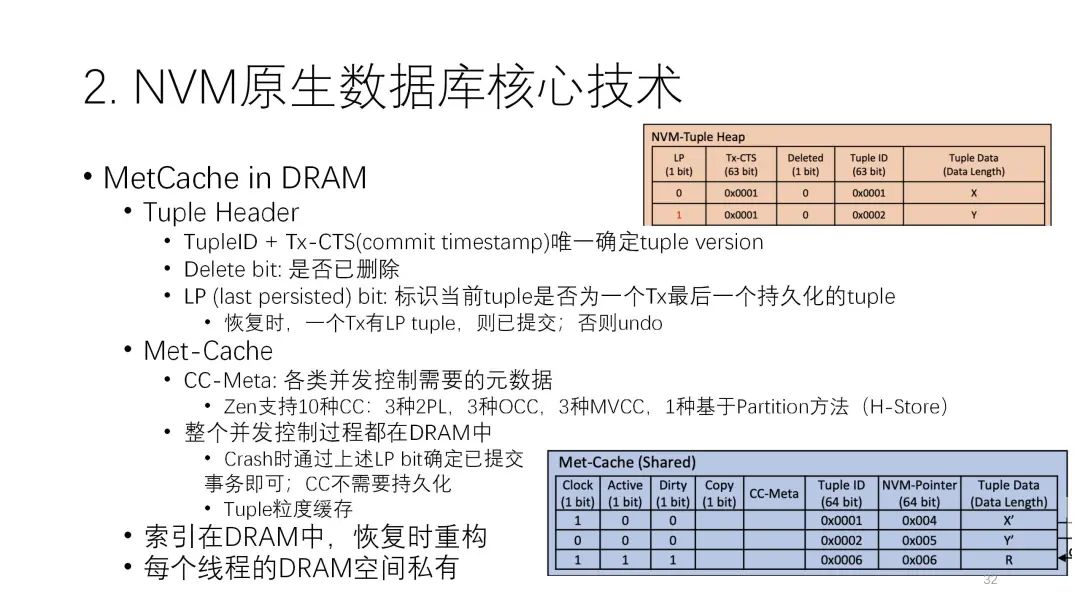 ? ? ? ? ?第二個重要的技術(shù)是在每一條NVM的進入里都有一個LP bit,它可能是0或者1,其作用很重要。當(dāng)一個事務(wù)在提交時有多條記錄,但前面的每一條都是0,只有到最后一條時它的LP bit才是1。這樣的好處是,當(dāng)中間突然宕機的時候,如果發(fā)現(xiàn)這個事務(wù)號只有0沒有1,說明這個事務(wù)沒有完成,那這條數(shù)據(jù)就可以忽略不計了。但如果發(fā)現(xiàn)這條事務(wù)有1,那說明前面的都寫完了,自然這個事務(wù)就是一個已經(jīng)完成的事務(wù),恢復(fù)時就可以把這個當(dāng)成是一個提交的事務(wù)去做。通過這樣的機制就做成了log-free的結(jié)構(gòu)。
? ? ? ?
? ? ? ? ?第二個重要的技術(shù)是在每一條NVM的進入里都有一個LP bit,它可能是0或者1,其作用很重要。當(dāng)一個事務(wù)在提交時有多條記錄,但前面的每一條都是0,只有到最后一條時它的LP bit才是1。這樣的好處是,當(dāng)中間突然宕機的時候,如果發(fā)現(xiàn)這個事務(wù)號只有0沒有1,說明這個事務(wù)沒有完成,那這條數(shù)據(jù)就可以忽略不計了。但如果發(fā)現(xiàn)這條事務(wù)有1,那說明前面的都寫完了,自然這個事務(wù)就是一個已經(jīng)完成的事務(wù),恢復(fù)時就可以把這個當(dāng)成是一個提交的事務(wù)去做。通過這樣的機制就做成了log-free的結(jié)構(gòu)。
? ? ? ?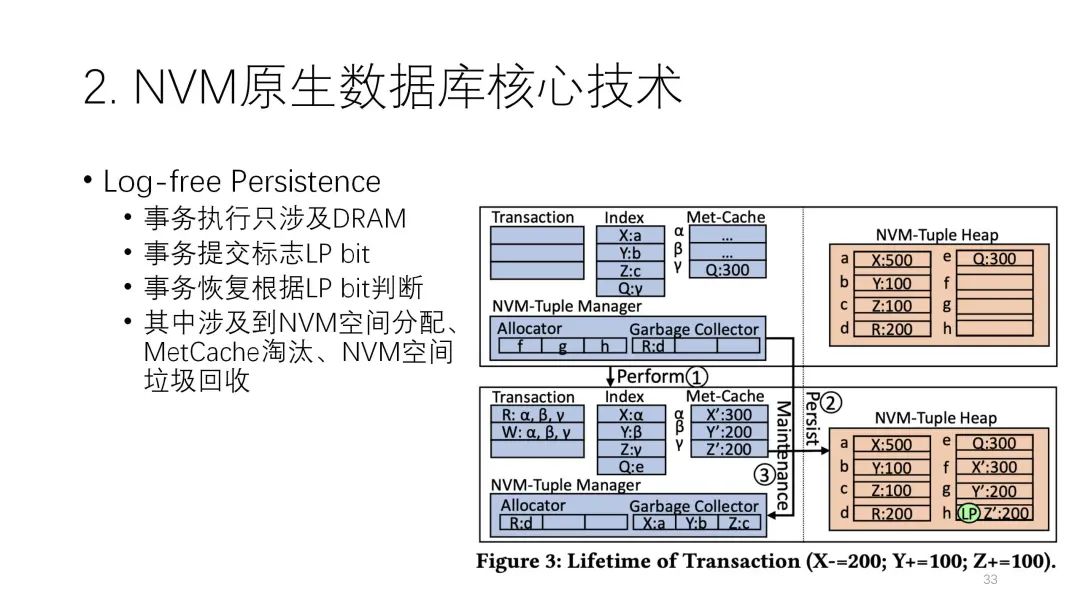 ? ? ? ? ?第三個重要的技術(shù)是空間管理。它分了兩層,一個是配置級別的,按照固定大小來分。另一個則是按照Tuple來分,且Tuple實際上不需要在NVM里保存元數(shù)據(jù),用DRAM就行,起來時都依靠恢復(fù)去做。? ? ?
? ? ? ? ?第三個重要的技術(shù)是空間管理。它分了兩層,一個是配置級別的,按照固定大小來分。另一個則是按照Tuple來分,且Tuple實際上不需要在NVM里保存元數(shù)據(jù),用DRAM就行,起來時都依靠恢復(fù)去做。? ? ?  實際上論文提出的Zen架構(gòu)在本質(zhì)上有點像交換。它在恢復(fù)時做的事情比較多,要掃描整個數(shù)據(jù),并且掃一遍還不行,必須掃一遍多。但是WBL技術(shù)可以做到基本不用掃數(shù)據(jù),它實際上也是一種交換。下圖種綠色的是Zen,它的性能基本上都是最好的。? ? ? ?
實際上論文提出的Zen架構(gòu)在本質(zhì)上有點像交換。它在恢復(fù)時做的事情比較多,要掃描整個數(shù)據(jù),并且掃一遍還不行,必須掃一遍多。但是WBL技術(shù)可以做到基本不用掃數(shù)據(jù),它實際上也是一種交換。下圖種綠色的是Zen,它的性能基本上都是最好的。? ? ? ?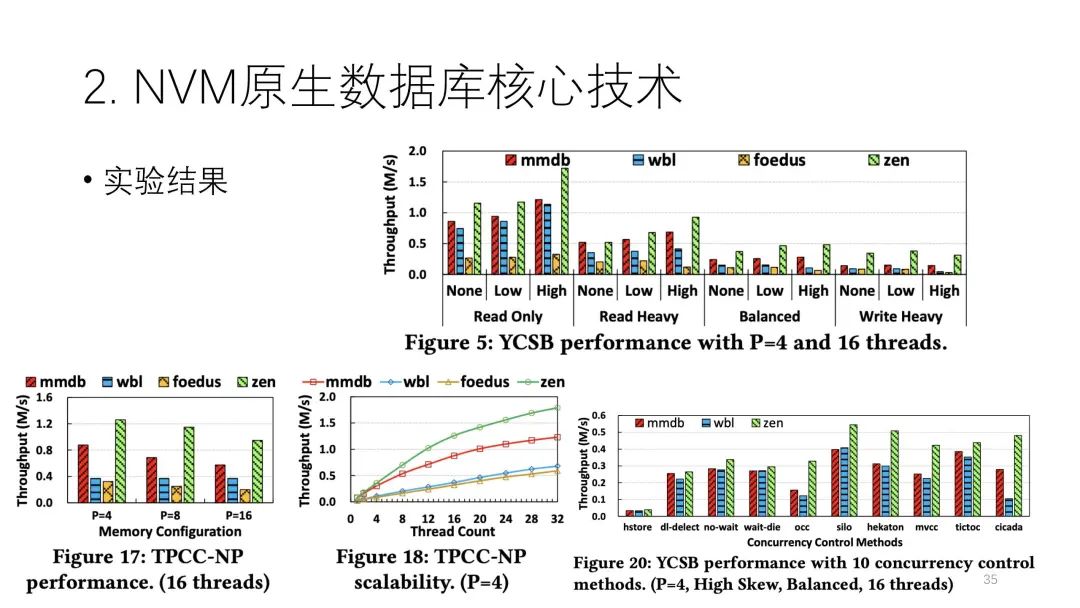 ? ? ? ? ?
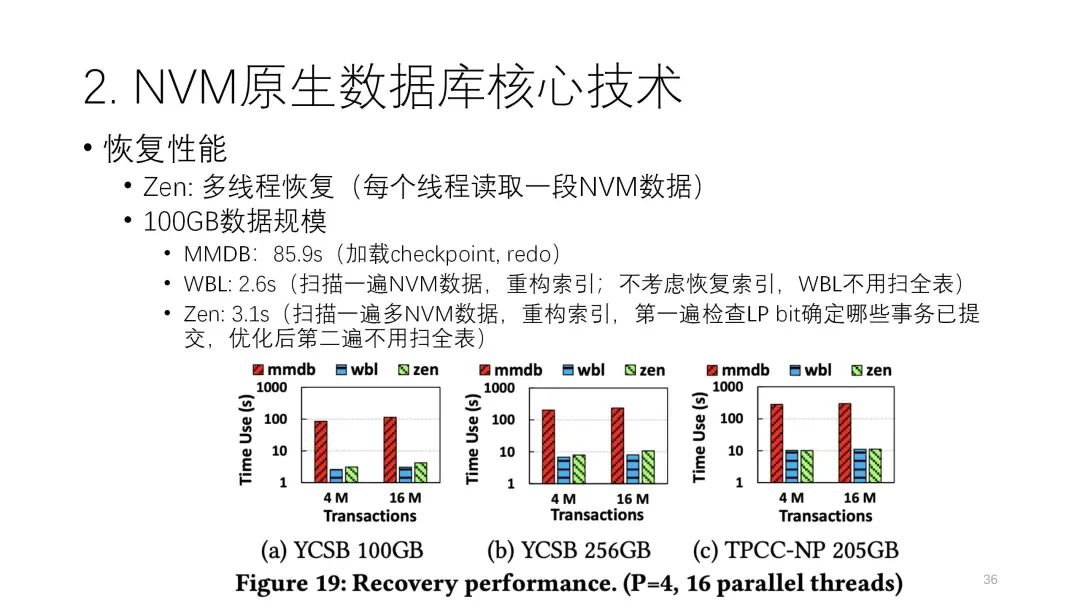
? ? ? ? ?下圖是恢復(fù)性能的比較。可以看到第一個方案確實恢復(fù)比較差,因為它要去做日志讀取,再去做redo,整個過程要80多秒,而后兩個方案都是個位數(shù)級別。WBL按照它的原則是不需要掃描的,基本上是零點幾秒,非常快就能恢復(fù),但因為索引也是要恢復(fù)的,也要掃一遍數(shù)據(jù),所以也需要幾秒的時間。Zen因為它的恢復(fù)更復(fù)雜些,除了掃一遍數(shù)據(jù)確定哪些數(shù)據(jù)提交之后,有一些還要再掃一部分?jǐn)?shù)據(jù),所以它的性能稍慢一點。但這里有個小疑問,論文中的數(shù)據(jù)規(guī)模比較小,如果數(shù)據(jù)規(guī)模更大,把所有的開銷都推到恢復(fù),那恢復(fù)是否還能做到這樣快,這個值得后續(xù)探討。? ? ?
? ? ? ? ? ?第二篇論文也是關(guān)于日志方面的,但是并不是數(shù)據(jù)庫層面,而是在LSM-tree層面做日志。實際上LSM-tree在寫的時候也有一個日志,也有內(nèi)存里的buffer。它為了提高性能盡可能地把數(shù)據(jù)先寫到內(nèi)存里,然后綜合competition再去做持久化,再寫到下面,但為了保證安全性必須先寫日志,寫日志的開銷實際上就代表了整個性能的高低。這里把NVM加進去之后,它對整個LSM-tree做了較大的改動,最重要的是改成了lock-free結(jié)構(gòu),性能就很好。
? ? ? ?
? ? ? ? ?第二篇論文也是關(guān)于日志方面的,但是并不是數(shù)據(jù)庫層面,而是在LSM-tree層面做日志。實際上LSM-tree在寫的時候也有一個日志,也有內(nèi)存里的buffer。它為了提高性能盡可能地把數(shù)據(jù)先寫到內(nèi)存里,然后綜合competition再去做持久化,再寫到下面,但為了保證安全性必須先寫日志,寫日志的開銷實際上就代表了整個性能的高低。這里把NVM加進去之后,它對整個LSM-tree做了較大的改動,最重要的是改成了lock-free結(jié)構(gòu),性能就很好。
? ? ? ?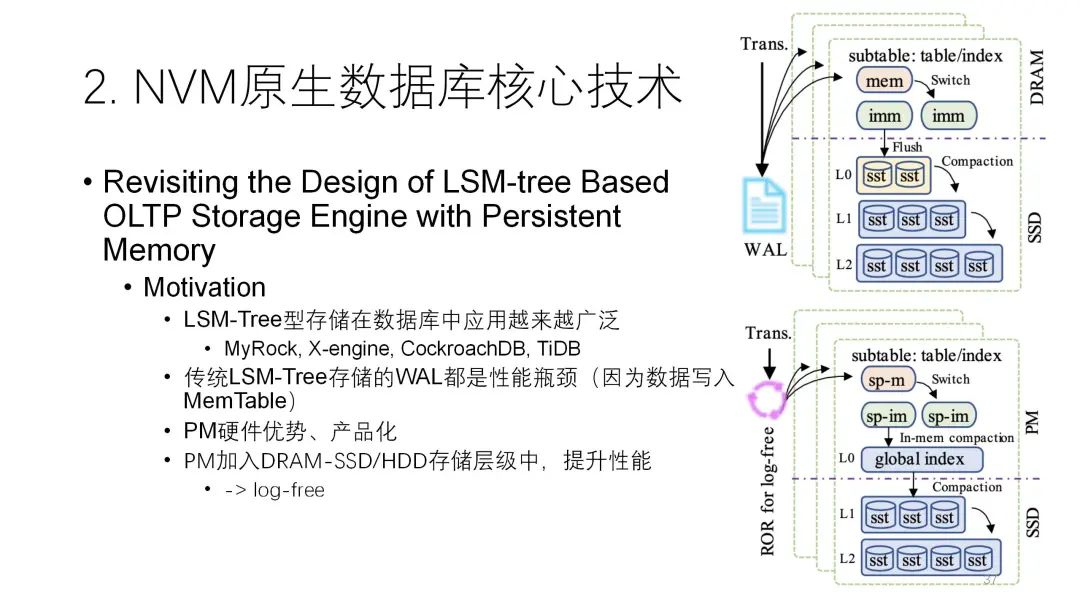 ? ? ? ??大體的思路是,先把數(shù)據(jù)寫到Chainlog里,在經(jīng)過 LSM-tree多層次轉(zhuǎn)移的時候,只從邏輯上去做,物理上數(shù)據(jù)只寫一遍就可以了,后面不需要再去寫。
? ? ? ?
? ? ? ??大體的思路是,先把數(shù)據(jù)寫到Chainlog里,在經(jīng)過 LSM-tree多層次轉(zhuǎn)移的時候,只從邏輯上去做,物理上數(shù)據(jù)只寫一遍就可以了,后面不需要再去寫。
? ? ? ?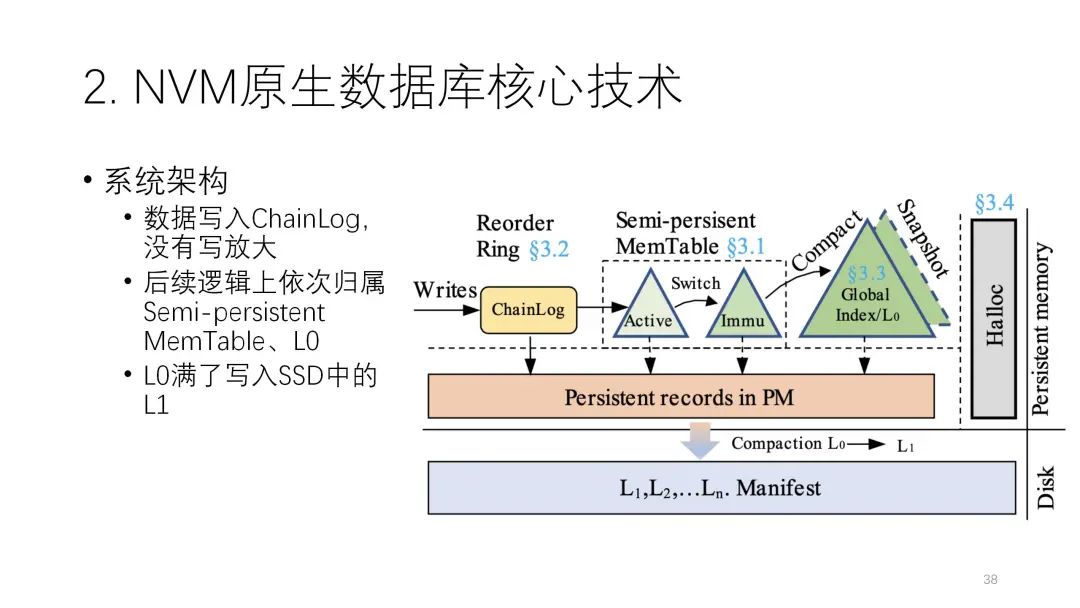
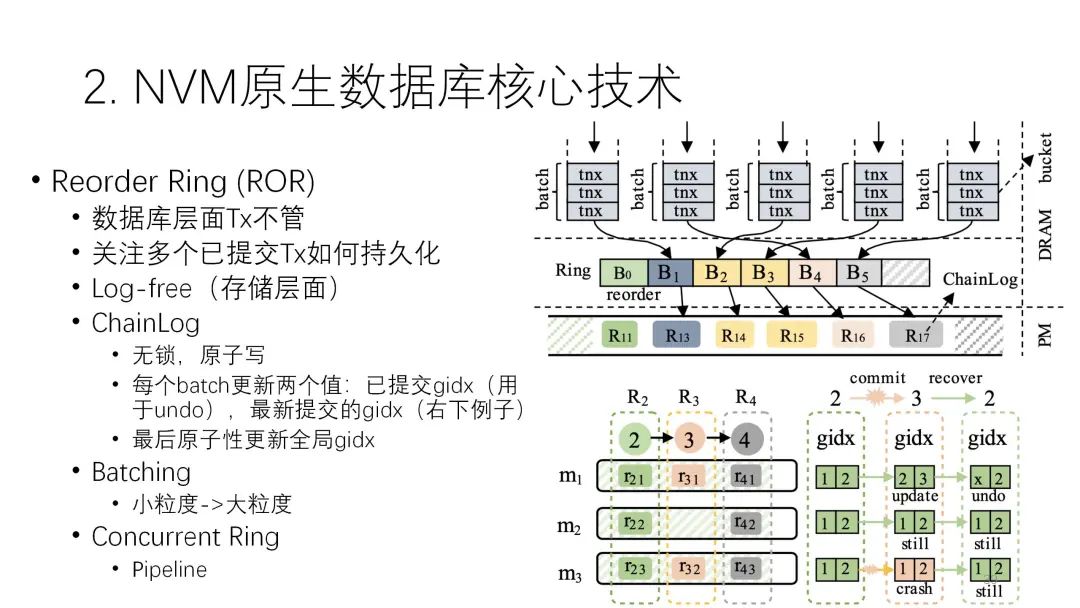
這里和日志最相關(guān)的是下面的技術(shù)。LSM-tree上可能有很多transaction并行在提交,它關(guān)心的是提交的時候怎么持久化。以下圖為例,這里有并行大量的持久化,為了讓力度更大就會把它變成批次來寫,但每一批怎么能做到lock-free呢?它計兩個值,兩個gidx,1就是1號版本,2是2號版本,3是3號版本。前面的值指的是之前已經(jīng)提交的正確版本,后面就表示當(dāng)前正在提交的版本。
在這個例子中,當(dāng)前是1、2的狀態(tài),前兩個批次已經(jīng)都提交了,現(xiàn)在正在提交第3個批次,第3個批次第一個已經(jīng)提交完了,第二、第三個還沒提交完,但是后面這個節(jié)點就掛掉了,掛掉之后在恢復(fù)的時候,因為這個地方是持久化的,它知道正在做2的過程中出問題了,我們只要回到上一個2就行了,如果前面這失敗了,再回滾到前面這個2就可以了,前面這個就不用管了,有一部分更新到3,最后也可以回滾到2,所以不會出問題,而且整個過程是必須要寫日志的。?
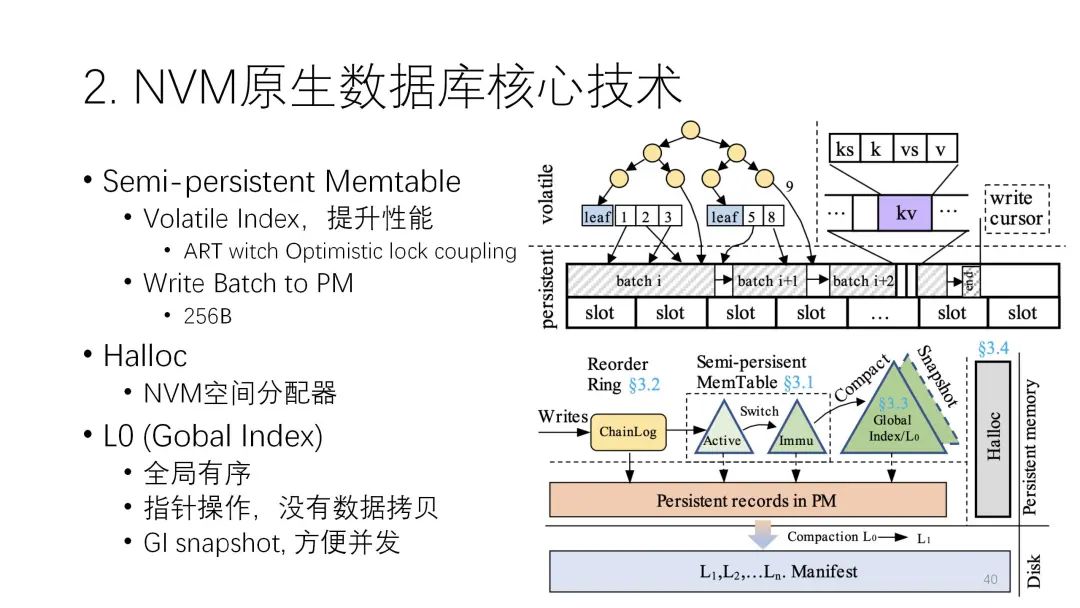
? ?? ? ? ? ? ?它的結(jié)構(gòu)上也采用了半持久化,中間的索引部分是易失的,下面的部分是非易失的,這樣來減少NVM的操作。
? ? ? ?
? ? ? ? ?它的結(jié)構(gòu)上也采用了半持久化,中間的索引部分是易失的,下面的部分是非易失的,這樣來減少NVM的操作。
? ? ? ? ? ? ? ? ?2.3 混合內(nèi)存技術(shù)
? ? ? ? ?2.3 混合內(nèi)存技術(shù)最后要分享的這篇論文,將介紹NVM的混合內(nèi)存技術(shù)。
此前很多研究都假設(shè)NVM與內(nèi)存比較接近,因此盡量要用NVM直接去寫,不做寫放大,避免重復(fù)的寫,但實際上兩者性能差別很大,因此還是要用好NVM。如何讓DRAM和cache進行分工協(xié)作,就成為了一個很重要的問題,這篇論文就是按照這樣的思路來開展研究的。 ? ? ? ?
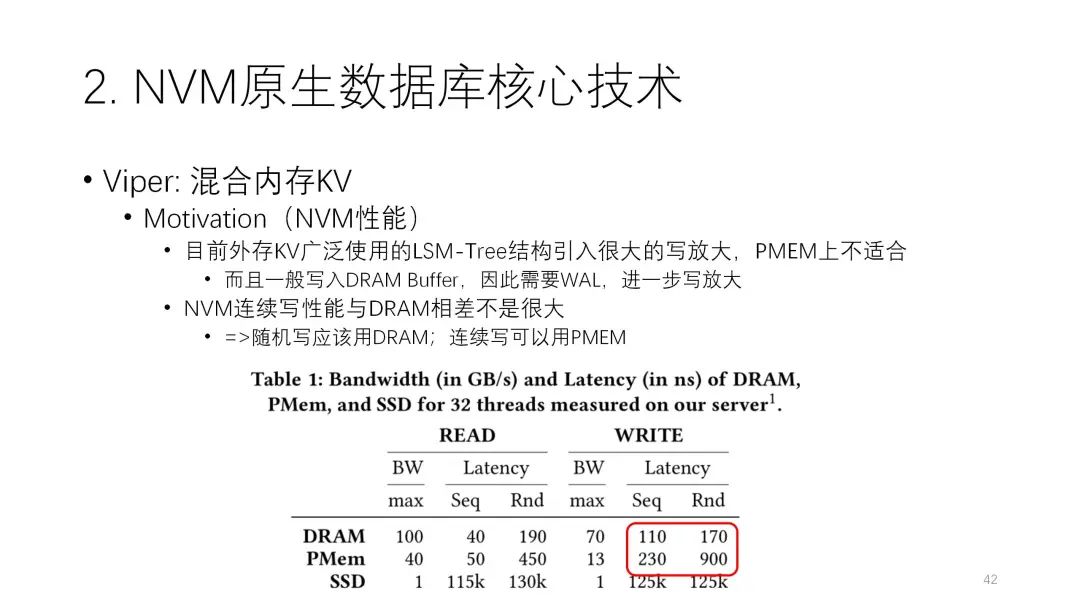
 ? ? ? ? ?這篇論文發(fā)現(xiàn)NVM的連續(xù)寫性能和DRAM相差不大,而隨機寫差別就比較大,因此建議NVM盡量不要隨機寫,要用連續(xù)寫。
? ? ? ?
? ? ? ? ?這篇論文發(fā)現(xiàn)NVM的連續(xù)寫性能和DRAM相差不大,而隨機寫差別就比較大,因此建議NVM盡量不要隨機寫,要用連續(xù)寫。
? ? ? ? ? ? ? ? ?因此整個思路是:在DRAM里采用易失性索引,因為索引有很多小粒度的隨機更新,放在NVM里效果肯定不太理想,所以索引干脆放棄,直接放在DRAM里;PMEM里主要是對數(shù)據(jù)進行持久化的寫入,而且盡可能把它組織好之后再連續(xù)的寫;然后把數(shù)據(jù)組織成4K對齊,橫著最大的是Vblock,小的4K的是Vpage,這樣除了數(shù)據(jù)規(guī)整以外還有利于并行度的控制;采用的結(jié)構(gòu)是并行模型,盡可能均勻地分到各個DIMM上,Vblock直接對應(yīng)下面不同的DIMM通道,因此每個用戶寫進去后,每個通道上拿到的并行都差不多,盡可能做到均衡,從并行的角度有一定的優(yōu)化,里面也支持變長和定長的結(jié)構(gòu)。? ? ??? ? ? ? ?
? ? ? ? ?因此整個思路是:在DRAM里采用易失性索引,因為索引有很多小粒度的隨機更新,放在NVM里效果肯定不太理想,所以索引干脆放棄,直接放在DRAM里;PMEM里主要是對數(shù)據(jù)進行持久化的寫入,而且盡可能把它組織好之后再連續(xù)的寫;然后把數(shù)據(jù)組織成4K對齊,橫著最大的是Vblock,小的4K的是Vpage,這樣除了數(shù)據(jù)規(guī)整以外還有利于并行度的控制;采用的結(jié)構(gòu)是并行模型,盡可能均勻地分到各個DIMM上,Vblock直接對應(yīng)下面不同的DIMM通道,因此每個用戶寫進去后,每個通道上拿到的并行都差不多,盡可能做到均衡,從并行的角度有一定的優(yōu)化,里面也支持變長和定長的結(jié)構(gòu)。? ? ??? ? ? ? ?這里有一個值得學(xué)習(xí)的比較通用的小技巧,即如何讓NVM的元數(shù)據(jù)持久化的開銷盡可能小。要先寫數(shù)據(jù),再寫元數(shù)據(jù),且要保證元數(shù)據(jù)是8字節(jié)內(nèi)的原子寫,這樣就不需要WAL。在下面這個例子中,先把數(shù)據(jù)寫進去,寫完之后,把beat從0改成1,這個小beat肯定是原子寫的。如果前面這個過程掛掉了,這個數(shù)據(jù)因為beat沒有set,我們就知道這個數(shù)據(jù)沒寫成功,甚至空間都沒有分配出去,那就可以直接下次再用。如果已經(jīng)寫完了1,說明上面肯定是完成的。通過這個技巧可以減少很多開銷。??? ? ?
 ? ? ? ? ?
? ? ? ? ?總結(jié)與思考
在很長時間內(nèi),NVM介質(zhì)還是明顯弱于DRAM。目前只有英特爾公司在做NVM產(chǎn)品,其發(fā)展不會很快,迭代的周期也會很長,所以前面介紹的硬件特性可能會長期存在,這也給未來數(shù)據(jù)庫的發(fā)展帶來了更多的機會。
如果要和內(nèi)存數(shù)據(jù)庫、磁盤數(shù)據(jù)庫做對比,實際上NVM數(shù)據(jù)庫應(yīng)該更接近于內(nèi)存數(shù)據(jù)庫。因此基于內(nèi)存數(shù)據(jù)庫去改造NVM數(shù)據(jù)庫要更方便,當(dāng)然也可以是原生的重新設(shè)計,這樣效果可能會更好。
但NVM數(shù)據(jù)庫和內(nèi)存數(shù)據(jù)庫雖然接近,實際上兩者還是有較大的差別。
一方面,內(nèi)存數(shù)據(jù)庫的空間是受限的,場景和成本都是它的問題,而NVM數(shù)據(jù)庫在存儲力度、成本上有較大的優(yōu)勢,將來可能會應(yīng)用在很多場景里。另一方面,內(nèi)存數(shù)據(jù)庫的日志持久化部分也帶來較大的性能開銷,而NVM數(shù)據(jù)庫在這方面還會有較多的提升空間,即使是從內(nèi)存數(shù)據(jù)庫優(yōu)化的角度,也能讓內(nèi)存數(shù)據(jù)庫的性能更好。 ? ? ? ?
 此外從系統(tǒng)設(shè)計的角度來看,NVM原生數(shù)據(jù)庫的設(shè)計也和內(nèi)存數(shù)據(jù)庫有很大的區(qū)。? ? ? ?
此外從系統(tǒng)設(shè)計的角度來看,NVM原生數(shù)據(jù)庫的設(shè)計也和內(nèi)存數(shù)據(jù)庫有很大的區(qū)。? ? ? ? ?
?﹀
﹀
﹀

解鎖數(shù)據(jù)庫前沿技術(shù)要點 | 騰訊云數(shù)據(jù)庫DTCC 2021亮點回顧

首例“微服務(wù)+國產(chǎn)分布式數(shù)據(jù)庫”架構(gòu),TDSQL助力昆山農(nóng)商行換“心”

數(shù)實融合·綻放新機,Techo Day技術(shù)回響日邀您“云相聚”
點擊閱讀原文,了解更多優(yōu)惠福利!