
拒絕代碼臃腫,這套計算引擎設計方法值得一看!

導語 | 在龐大的數(shù)據(jù)系統(tǒng)中,往往會有大量的計算需求。傳統(tǒng)的方式便是直接在代碼寫各種計算邏輯判斷,這導致了代碼非常臃腫,計算維護的成本變大。所以想著編寫一套DSL,定義專用的語法去實現(xiàn)對數(shù)據(jù)的計算,并將其獨立成為底層基礎服務。
一、DSL 設計
(一)何為 DSL
領域特定語言(英語:domain-specific language、DSL)指的是專注于某個應用程序領域的計算機語言。不同于普通的跨領域通用計算機語言(GPL),領域特定語言只用在某些特定的領域。
簡單來說,就是利用DSL,通過抽象構建模型,抽取公共的代碼,以達到提高開發(fā)效率,減少重復的勞動的目的,比如經(jīng)常使用的SQL。
同樣的思路,我們要將復雜的邏輯判斷與計算規(guī)則抽象化,構建計算DSL。
(二)如何通用化設計計算 DSL
值得慶幸的是,辦公中經(jīng)常使用的Excel就包含了許多計算規(guī)則。
讓我直接舉一個例子來說明,比如:要計算實際支出超出預算的金額,由于超出金額不可能為負數(shù),所以邏輯條件為:如果實際支出大于預算,則結果為實際支出減預算,反之則取0。對應的Excel計算公式為:
IF (C2 > B2, IMSUB (C2, B2), 0)(C2 代表實際支出,B2 代表預算,IMSUB 代表減法)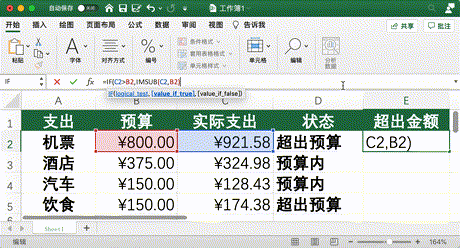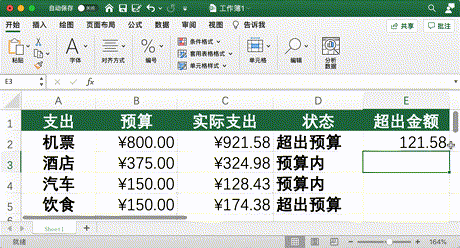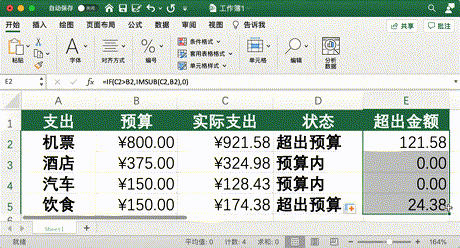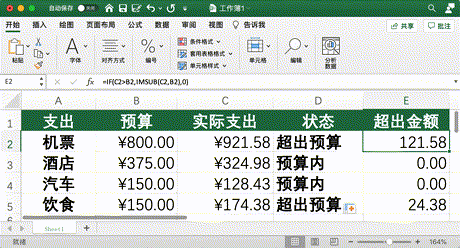
有了一個這么專業(yè)的例子,那么對應我們的計算DSL就是:
IF ({budget} > {actual_expenses}, IMSUB ({budget}, {actual_expenses}), 0)({}用于標示具體字段,budget、actual_expenses 代表數(shù)據(jù)庫中對應的預算、實際支出字段)
(三)DSL 設計的優(yōu)勢
與Excel計算規(guī)則相似,減少用戶學習成本。
按照專業(yè)的規(guī)則來定義,使計算DSL更規(guī)范。
由于規(guī)范的設計,更有利于后期擴展。
二、計算引擎的實現(xiàn)
(一)DSL 解析
對于這種有關鍵字并且無限嵌套的DSL,應該沒有比堆棧更合適的方法來解析了。下面是具體例子的部分解析代碼:
$dsl = 'IF({budget}>={actual_expenses},IMSUB({budget},{actual_expenses}),0,1)';$stack = []; // 堆棧$result = []; // 結果$comparisonOperators = ['<', '>', '&', '|', '=']; // 比較運算符$placeholders = [',', '(', ')']; // 占位符for ($index = 0; $index < strlen($dsl); $index++) {$key = $dsl[$index];switch ($key) {// 解析變量case '}' :$variable = '';while (true) {$item = array_pop($stack); // 出棧if ($item === '{') {break;}$variable = $item . $variable;}$result[] = $this->getVariable($variable); // 獲取真實變量值break;// 解析方法case '(' :$method = '';while (true) {$item = array_pop($stack); // 出棧if (is_null($item)) {break;}$method = $item . $method;}$result[] = $method;$result[] = $key;break;// 存儲占位符,清空棧內(nèi)變量(常量)case in_array($key, $placeholders) :$variable = '';while (true) {$item = array_pop($stack); // 出棧if (is_null($item)) {break;}$variable = $item . $variable;}$variable != '' && $result[] = $variable;$result[] = $key;break;// 解析比較運算符case in_array($key, $comparisonOperators) :if ($dsl[$index + 1] == '=') { // 兼容 >=、<=$result[] = $key . '=';$index++;} else {$result[] = $key;}break;// 入棧default :$stack[] = $key;break;}}
(二)數(shù)據(jù)結構化
通過DSL解析可以得到“未賦值”的結構,再根據(jù)預先存儲的數(shù)據(jù)模型對變量進行賦值,我們便可以得到如下結構:
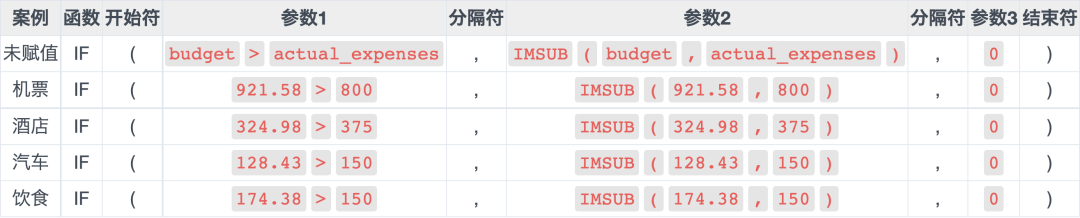
這樣一來,DSL就變成了機器所能識別的數(shù)據(jù),將參數(shù)帶入到指定的函數(shù)中便能得到計算結果。
(三)遞歸計算
從上圖的結構中,我們可以分析出:每一個計算都包含了計算函數(shù)、占位符(開始符、分割符、結束符)以及函數(shù)對應的多個參數(shù)。其中參數(shù)可以是比較運算(IF函數(shù)第一個參數(shù)必為比較運算),也可以是另一個函數(shù)。這時候我們只需要使用遞歸的方式去不斷往下運算便能得出結果。
/*** IF 函數(shù)核心計算邏輯*/public function calculate(){// 計算比較結果if ($this->getComparativeResult()) {return $this->getResult($this->params[1]); // 返回真} else {return $this->getResult($this->params[2]); // 返回假}}/*** 獲取計算結果*/public function getResult($params){// 如果是函數(shù),則繼續(xù)計算if (is_array($params)) {return (new Calculate($params))->calculate(); // 遞歸計算}// 非函數(shù),直接返回結果return $params;}
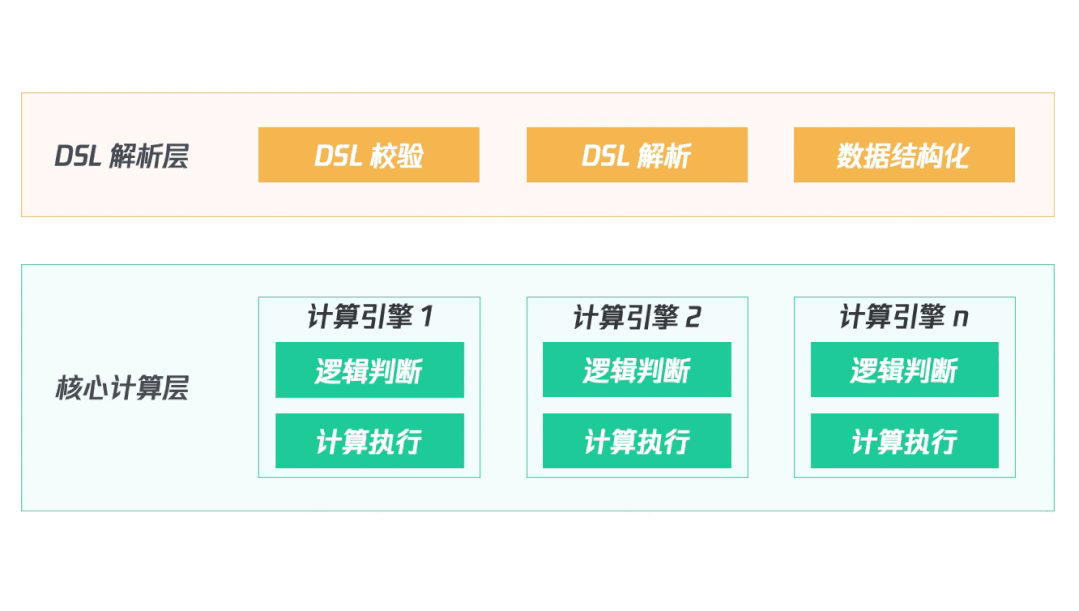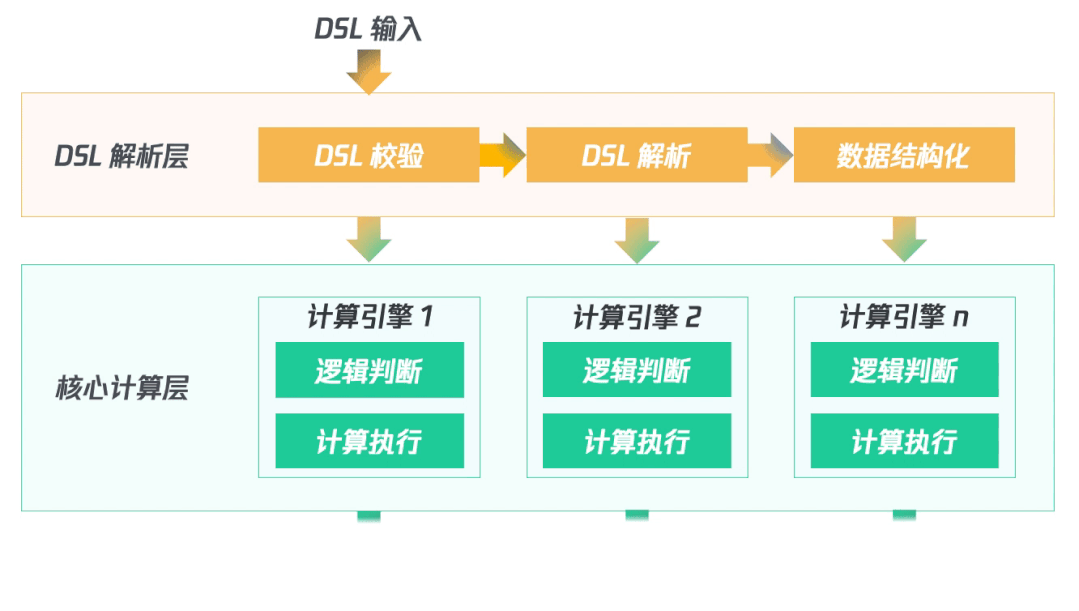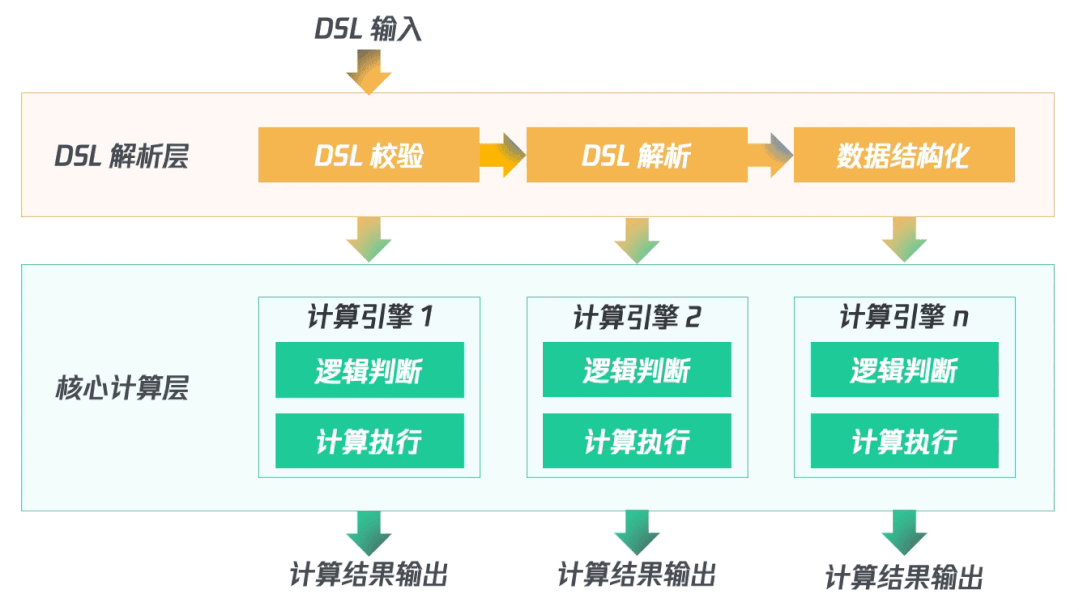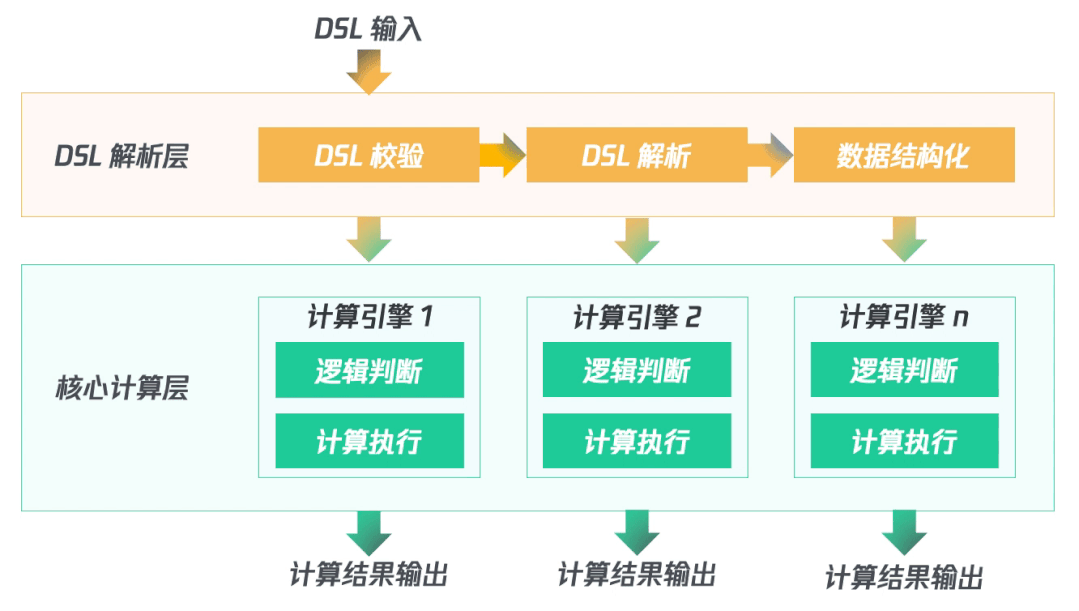
(四)架構梳理
首先對輸入的DSL進行校驗、解析并結構化數(shù)據(jù);然后啟動多個計算引擎同時并行處理;最終輸出計算結果。
三、項目接入
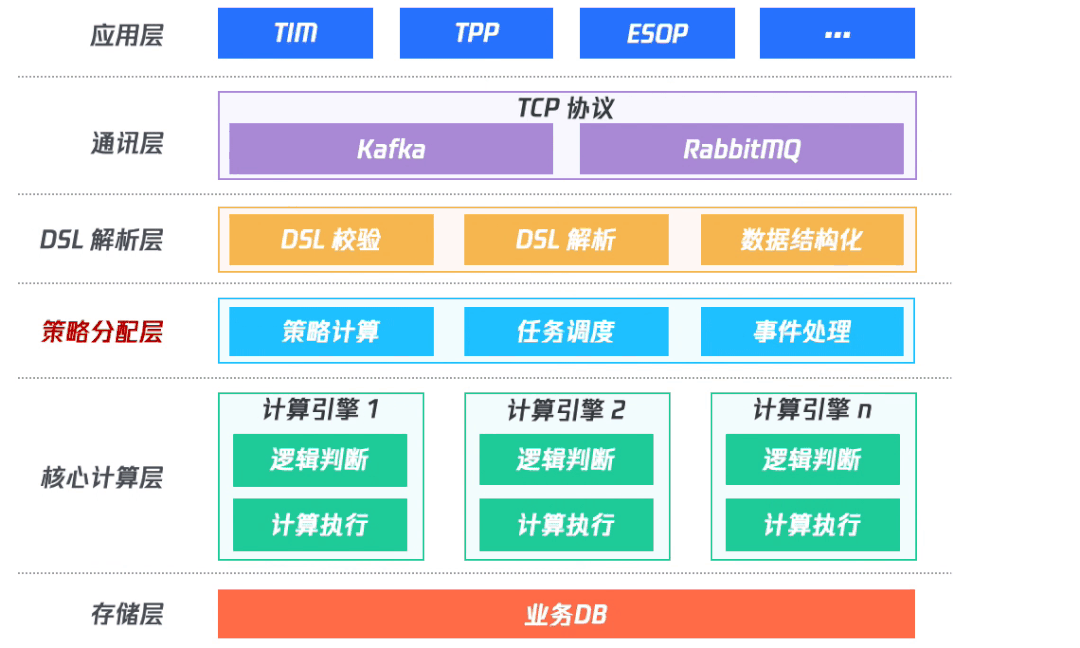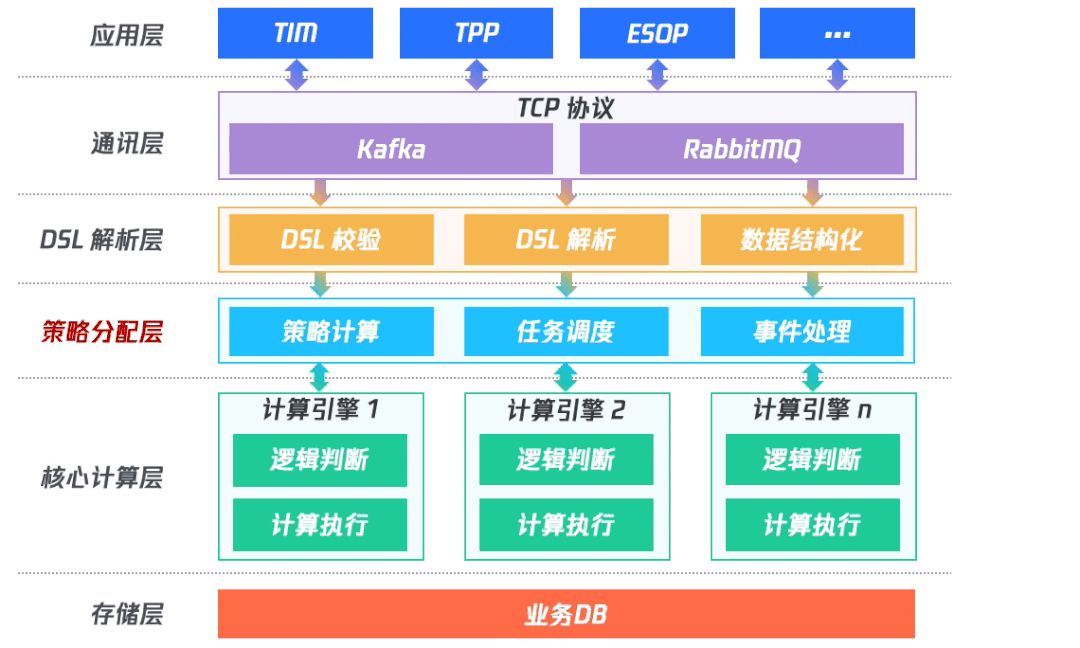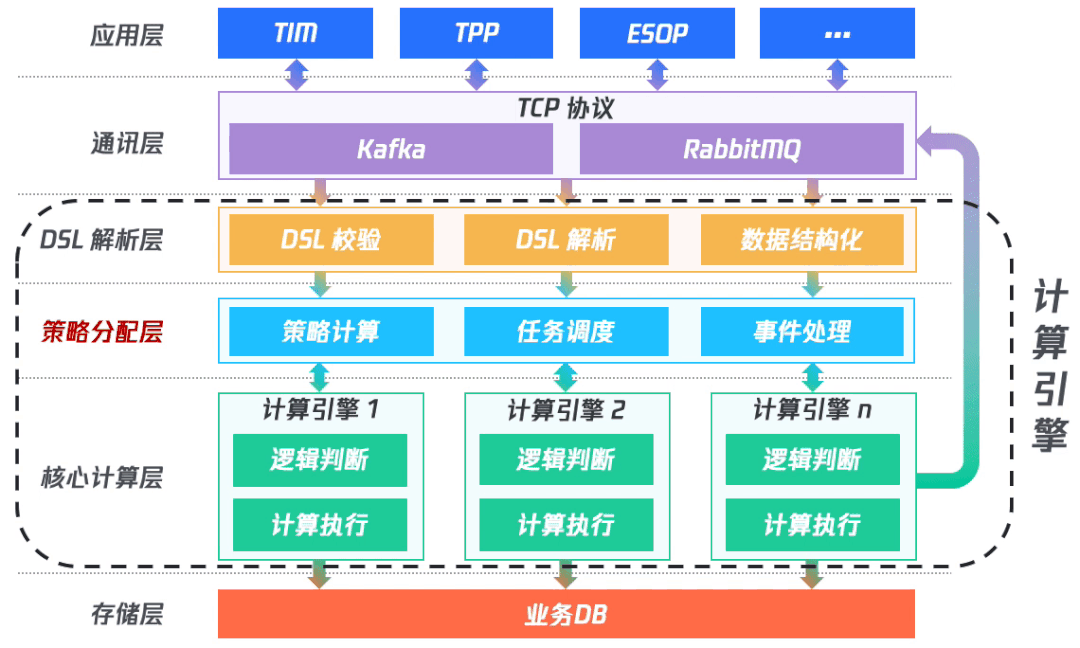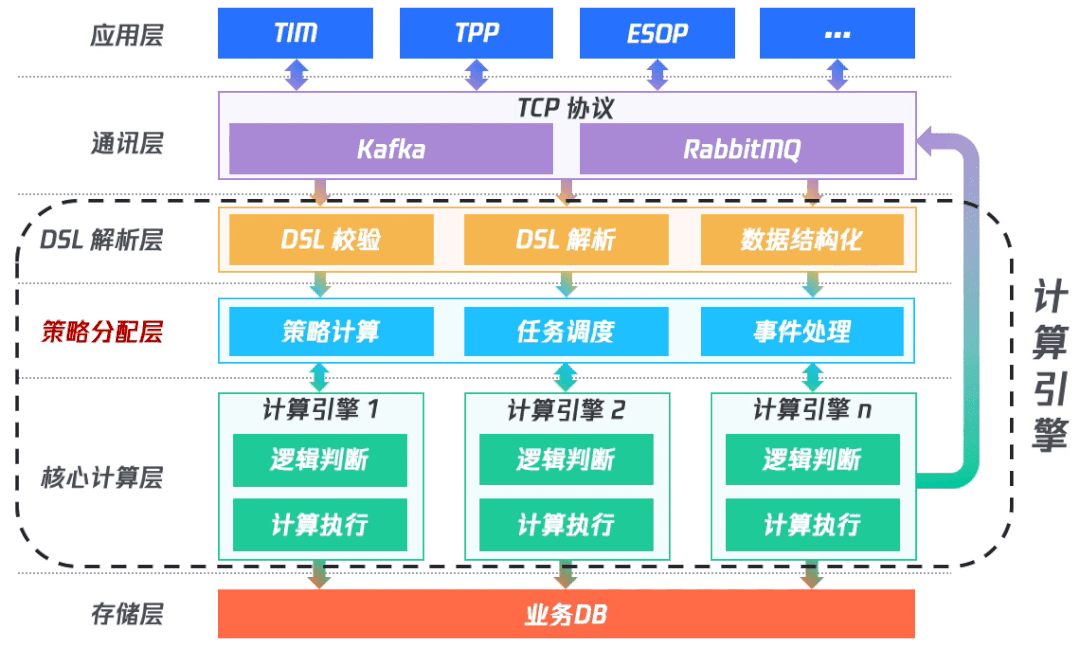
(一)架構設計
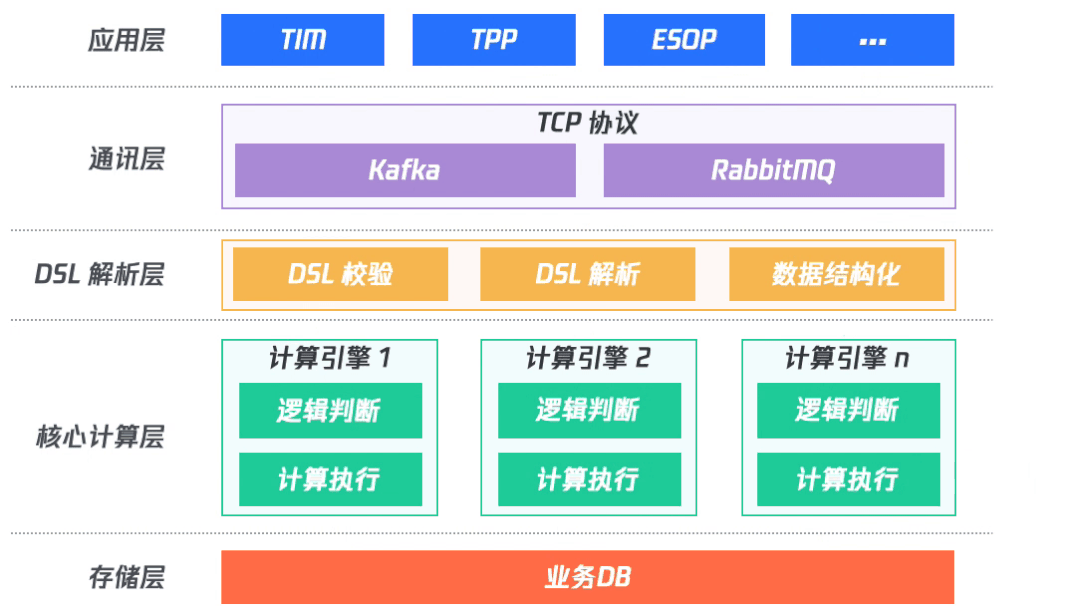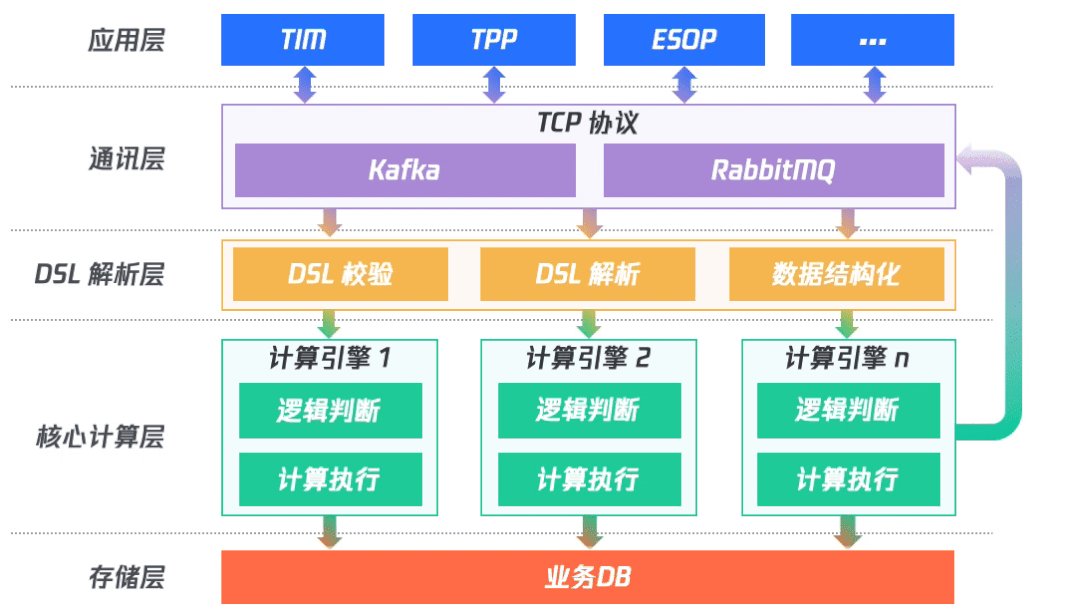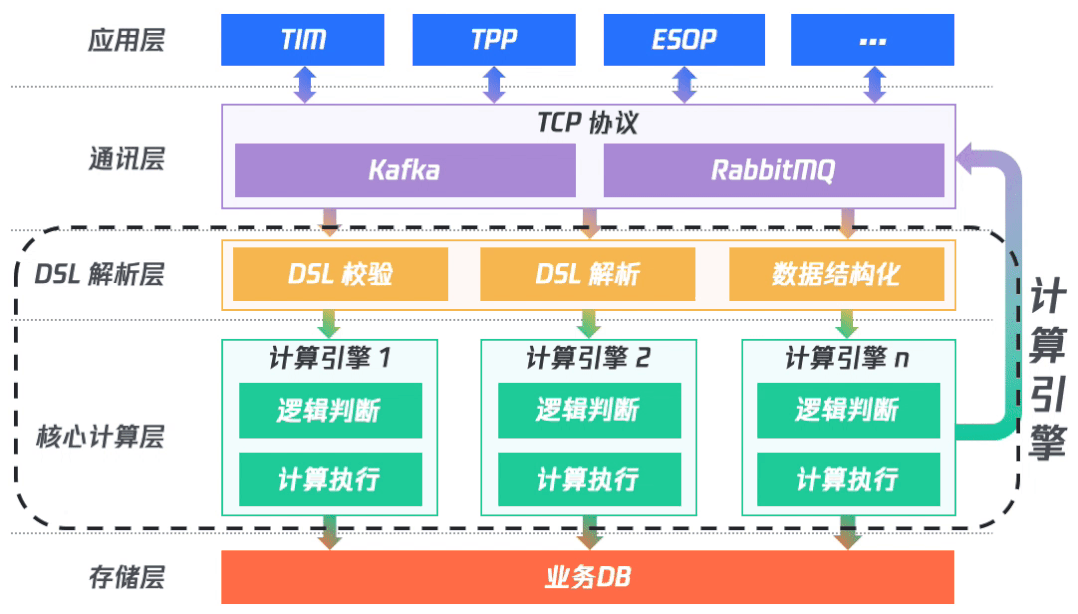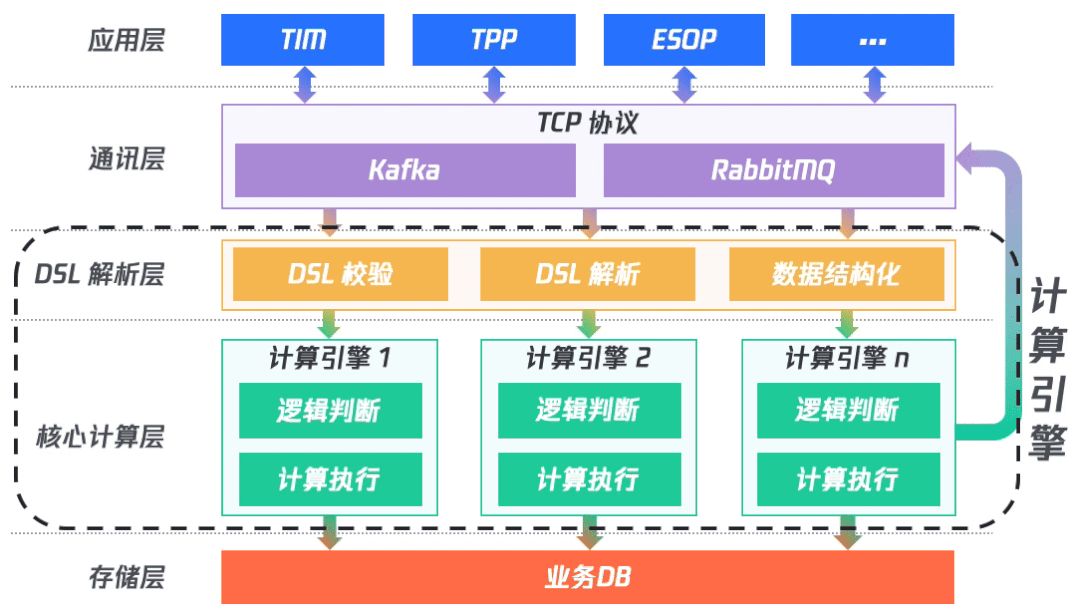
整體架構分為五層,上層應用層提供給具體應用接入;通訊層負責對接收應用層的數(shù)據(jù),及對支持應用層輪詢獲取計算結果;DSL解析層負責DSL校驗、DSL解析以及數(shù)據(jù)結構化;處理完之后再到核心計算層,進行具體的計算執(zhí)行;最后再將結果入庫并將結果發(fā)送到消息隊列中。
其中,DSL 解析層和核心計算層共同組成計算引擎。
四、問題與思考
(一)計算提升效率緩慢
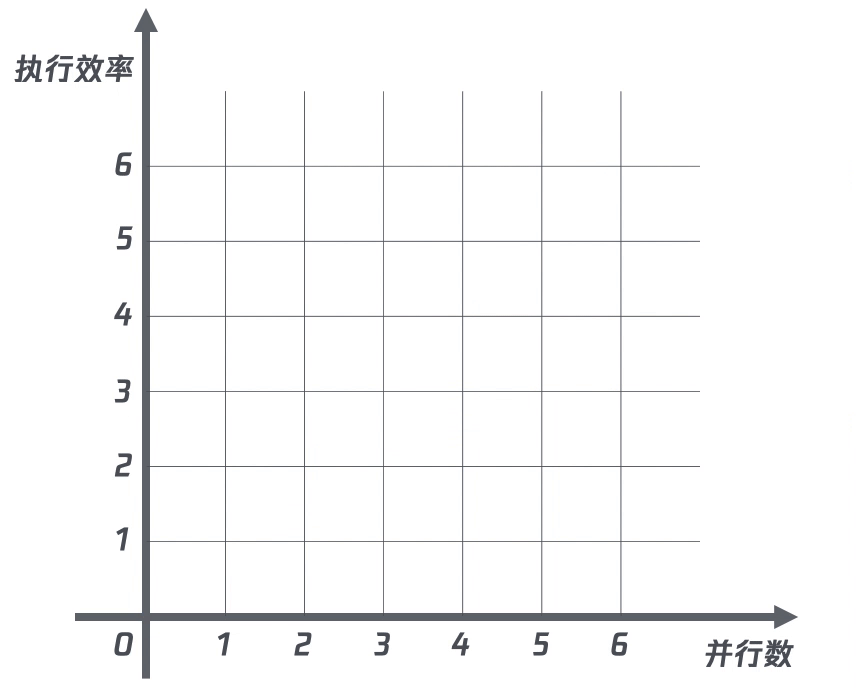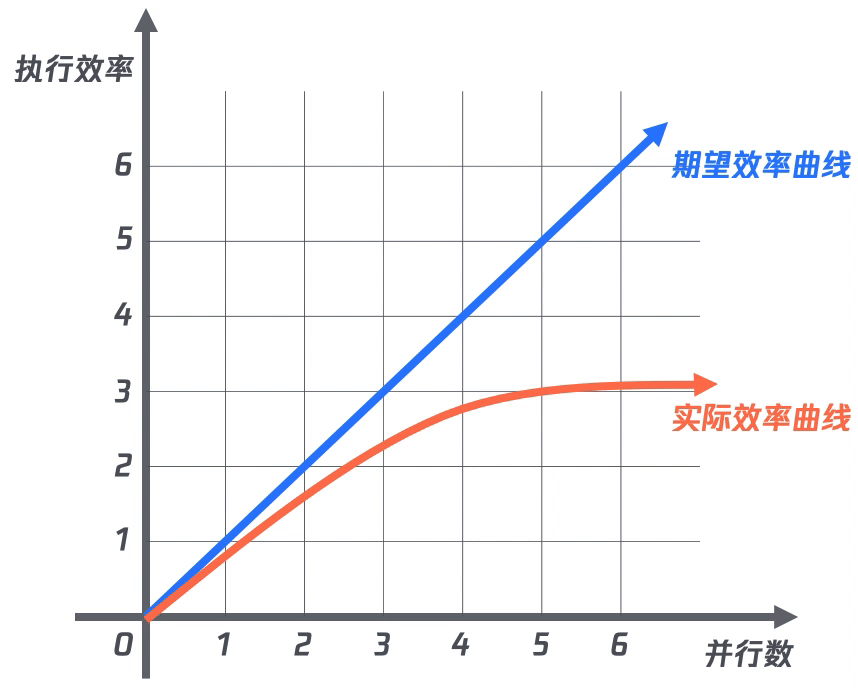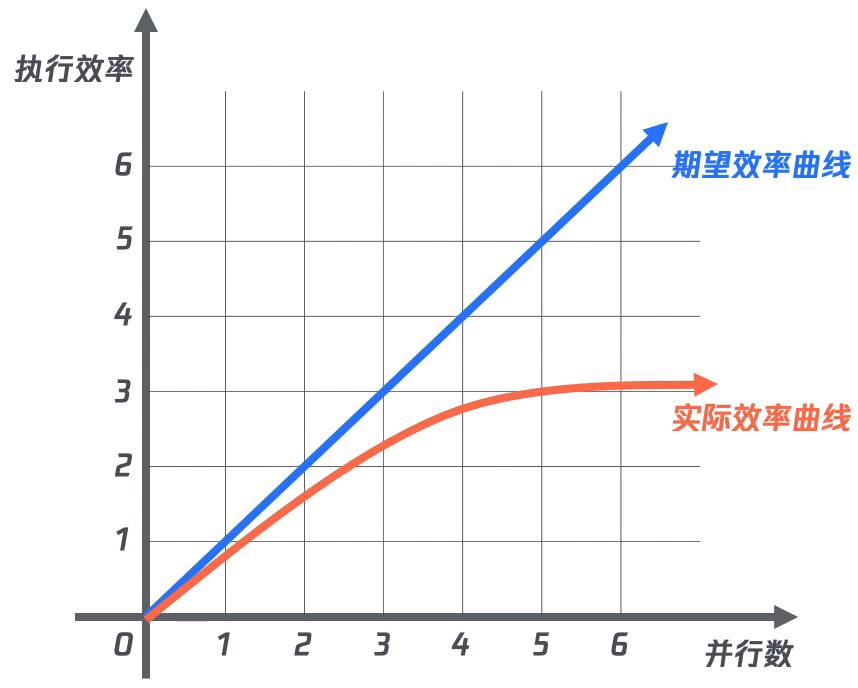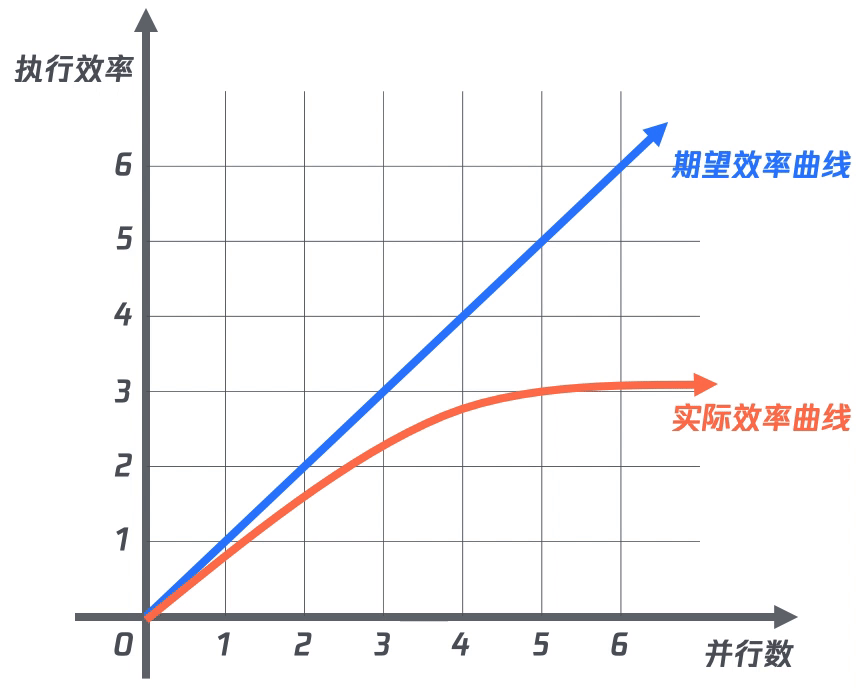
在完成項目接入后,為了提升計算效率,采用并行執(zhí)行的方式來執(zhí)行計算。期望的效果便是:隨著并行的數(shù)量增加,效率也隨之增加。
但事實總是事與愿違,即使擴大計算的并行數(shù)量也無法成倍提升計算效率,并且當并行數(shù)達到一定量時,效率提升越不明顯。
(二)計算依賴
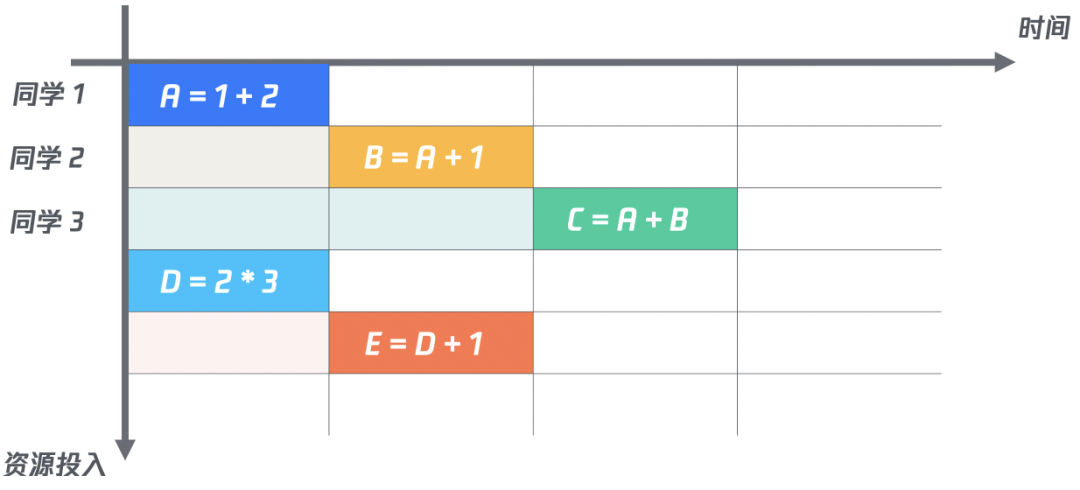
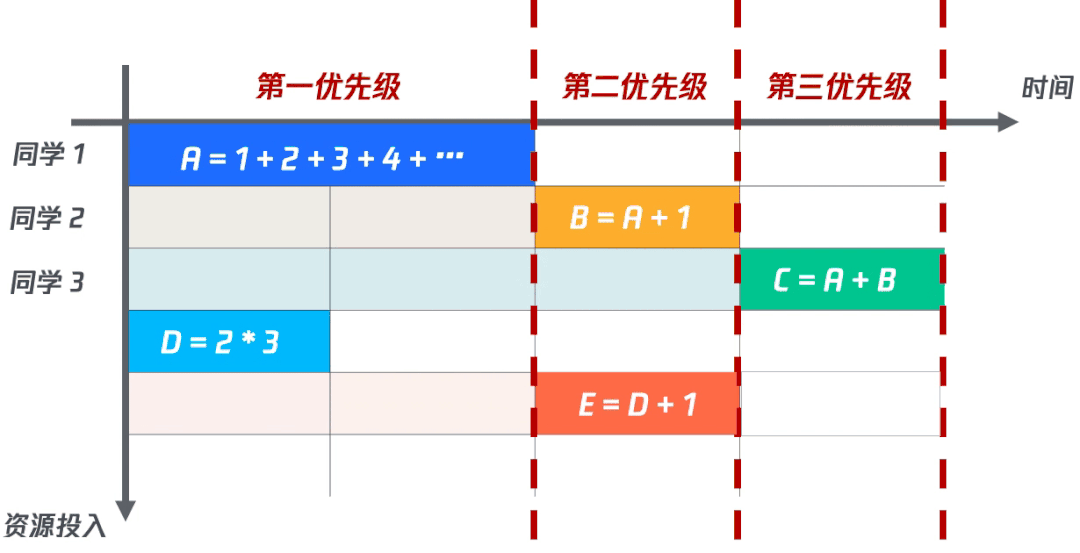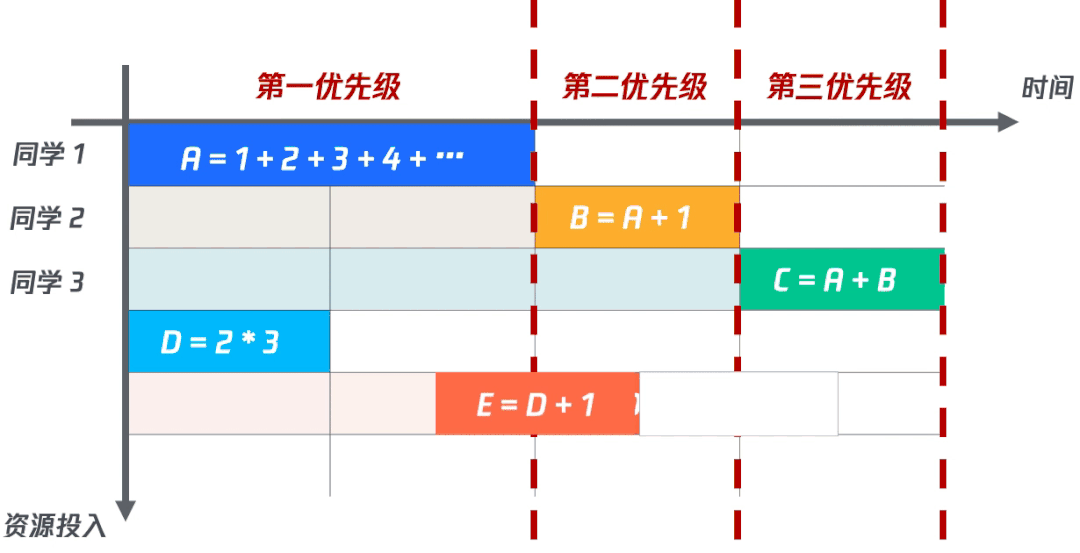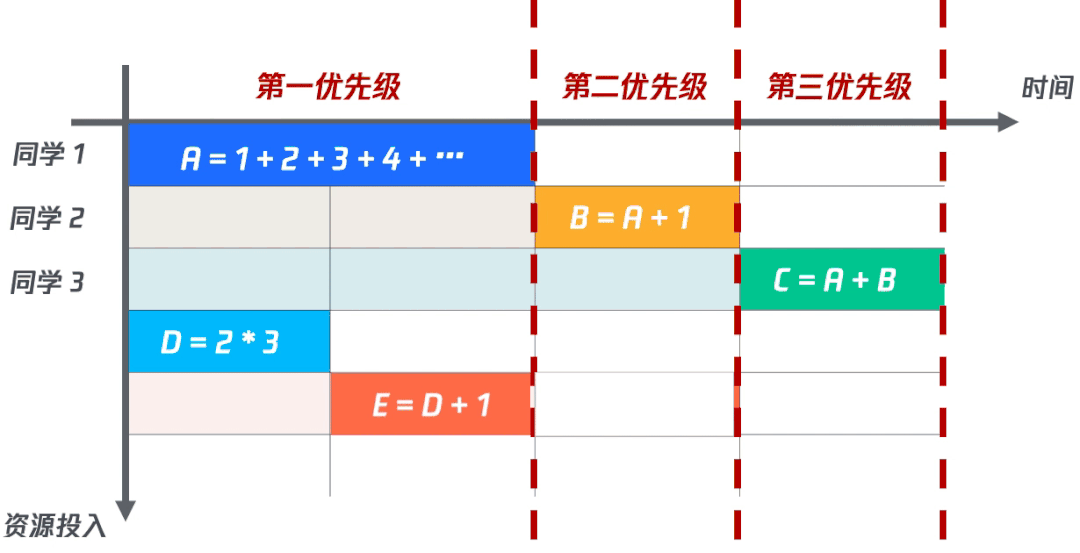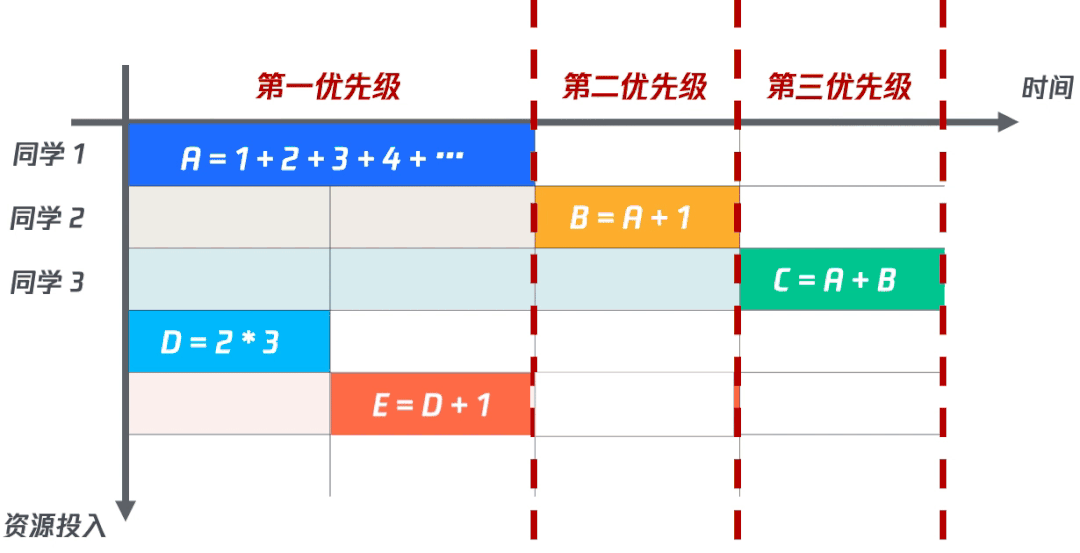
在經(jīng)過仔細的問題排查之后,發(fā)現(xiàn)數(shù)據(jù)計算之間是有依賴關系的。讓我們直接看下圖的例子:當同時計算A、B、C三個字段時,不管如何并行執(zhí)行,B的計算永遠依賴A計算的結果;同理,C的計算也永遠依賴A和B的計算結果。總而言之,就是說計算效率是有瓶頸的。
那么,如何能夠用最少的資源達到整體計算的最佳效率呢?
五、解決方案:尋找最優(yōu)解
(一)策略優(yōu)先算法
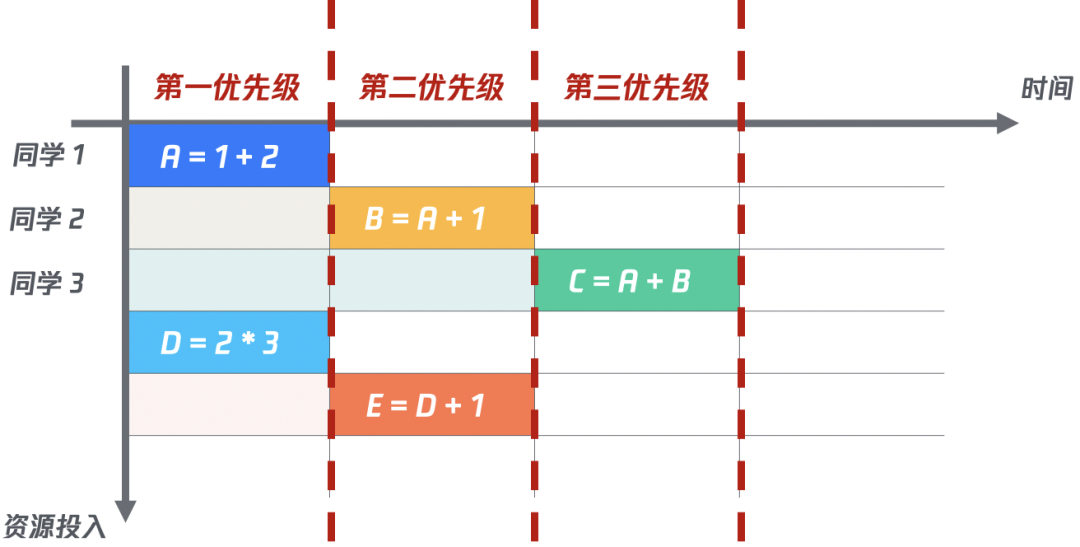
對于每個計算字段來說,我們是知道具體依賴的程度的:
對于A、D,只依賴常數(shù),所以他們依賴程度為0。
對于B、E,分別依賴A、B,那么他們的依賴應該分別在A、B的基礎上+1,所以他們的依賴程度為1。
對于C,同時依賴A、B,那么他的依賴程度應該為A+B+1=2。
所以,我們將每個字段排了優(yōu)先級,對于同一優(yōu)先級的字段并行計算,依次進行,便能以最少的資源達到整體計算的最佳效率。
(二)計算速度不一致
在實際的計算中,每個字段計算的速度是不一樣的。比如:在第一優(yōu)先級中的A需要不斷的累加才能得出結果,需要比同一優(yōu)先級的D花費更長的時間。假如此時D已經(jīng)計算完成,那么E其實已經(jīng)不需要再依賴其他計算了,應該立即被執(zhí)行。但由于第一優(yōu)先級還未算完,所以只能繼續(xù)等待。這樣一來,對于計算結果的反饋非常的不友好。
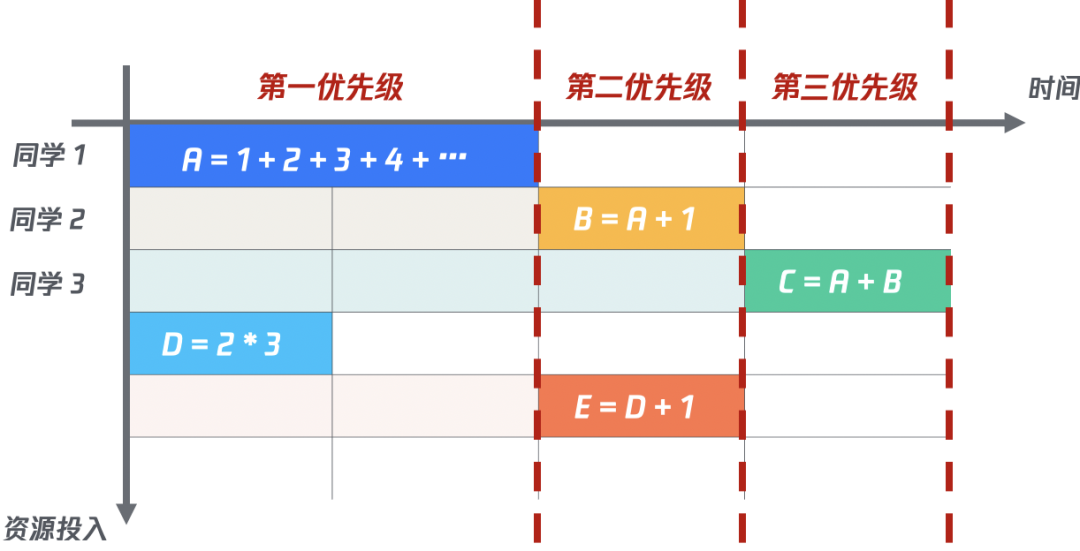
(三)更進一步:動態(tài)策略優(yōu)先算法
為了能快速的響應計算結果,我們需要在計算的同時,對計算完成的字段觸發(fā)完成事件,對依賴該字段的其他優(yōu)先級字段,重新分配優(yōu)先級,當獲得第一優(yōu)先級時,立即執(zhí)行。
比如:在D計算完成后,去修改E的優(yōu)先級,因為E只依賴D,而D已經(jīng)計算完成,所以應該獲得第一優(yōu)先級,立即執(zhí)行。
六、總結
(一)架構完善
在動態(tài)策略優(yōu)先算法的思路下,我們在原先的結構中引入策略分配層。在DSL解析之后將數(shù)據(jù)傳入到策略分配層中進行策略計算;然后,依次對各個優(yōu)先級的字段進行計算任務調(diào)度;在計算完成后對事件進行處理,再依次進行任務調(diào)度;最終在完成整個計算后將數(shù)據(jù)入庫。
其中,DSL解析層、策略分配層和核心計算層共同組成計算引擎。
(二)下一步:引入監(jiān)控
在完成了一系列的開發(fā)與項目接入工作之后。對于整個底層計算服務來說,并不是已經(jīng)無懈可擊了。
在DSL的解析中需要實時監(jiān)控解析結果,及時對錯誤進行攔截與記錄,避免影響下層計算。
在策略分配層中,也需要對每一次的策略計算、任務調(diào)度、事件處理進行監(jiān)控,因為每一次錯誤都將影響整個模型的計算結果。
在最終入庫之前,還需要監(jiān)控每個字段的計算結果是否符合預期。及時對錯誤結果進行修正。
作者簡介

林楨淵
騰訊 CDC 團隊應用開發(fā)工程師
騰訊 CDC 團隊應用開發(fā)工程師,畢業(yè)于廣東工業(yè)大學,負責騰訊投資決策信息平臺開發(fā)。致力于低代碼開發(fā)平臺(包括流程引擎、表單配置、計算引擎等等)的架構設計與持續(xù)優(yōu)化。在投資領域開發(fā)有著豐富的落地經(jīng)驗。
推薦閱讀
程序員如何把你關注的內(nèi)容推送到你眼前?揭秘信息流推薦背后的系統(tǒng)設計
在Exception的影響下,如何才能寫出更高質(zhì)量的C++代碼?
自動的內(nèi)存管理系統(tǒng)實操手冊——Java和Golang對比篇
