
如何開發(fā)一個(gè)自己的TensorFlow?
鏈接:https://www.zhihu.com/question/326890535 編輯:深度學(xué)習(xí)與計(jì)算機(jī)視覺


https://www.zhihu.com/question/326890535/answer/719907717
當(dāng)時(shí)測了幾個(gè)典型的模型的GPU訓(xùn)練速度,論文中的表格:
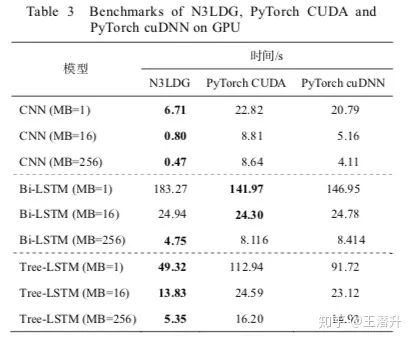
我fork了一個(gè)完全由自己主導(dǎo)的版本:https://github.com/chncwang/N3LDG-plus
等有時(shí)間加上transformer和BERT的支持了,再整文檔吧(其實(shí)到底該叫啥名也沒想清楚,姑且稱之為N3LDG++),目前主要就自己在用來做文本生成。
GPU計(jì)算的實(shí)現(xiàn)是相對(duì)麻煩的一部分。出于性能極致的追求(N卡很貴,計(jì)算速度怎么強(qiáng)調(diào)都不過分)和對(duì)自己代碼負(fù)責(zé)的態(tài)度,當(dāng)時(shí)算把CUDA徹底整明白了(除了圖形學(xué)用的紋理內(nèi)存),針對(duì)每種操作專門寫了對(duì)應(yīng)的CUDA,比如concat操作就能在一次kernel調(diào)用下完成一個(gè)batch里的多個(gè)不同維度輸入向量的拼接:

顯存也需要操心。由于GPU離CPU遠(yuǎn),不能像用malloc一樣頻繁地調(diào)cudaMalloc。當(dāng)時(shí)不滿cnmem的性能,就自己擼了個(gè)buddy system。顯然這個(gè)做法不夠精細(xì),dynet的解決方案應(yīng)該更合理,詳見他們的論文。
提到顯存,忍不住想多說幾句。NLP任務(wù)和CV不一樣,同個(gè)mini-batch中句子長短不一,pytorch會(huì)要求補(bǔ)零的操作以求維度對(duì)齊,往往還會(huì)有一個(gè)全局的max_sentence_length(哪怕是N3LDG也是如此),這其實(shí)很浪費(fèi)顯存。在N3LDG++中,如果一個(gè)mini-batch里的句子總長度是100,那么分配100長度的空間也就夠用,減少了浪費(fèi)。所以我計(jì)劃有時(shí)間了支持下BERT,至少讓base模型在1080ti里也能伸展開來,不怕OOM。只是不清楚大家都用啥顯卡,這塊的需求有多強(qiáng)。
然后說一下編程語言。主流的框架使用C++、CUDA實(shí)現(xiàn)底層的計(jì)算,然后用python實(shí)現(xiàn)上層的封裝,似乎是兼顧了計(jì)算效率和使用方便。然而使用PyTorch時(shí)還是會(huì)發(fā)現(xiàn)CPU模式下的龜速。我自己沒用過PyTorch,也不清楚CPU龜速的原因(也許是Python調(diào)用C++的額外開銷?),只是每當(dāng)看到實(shí)驗(yàn)室同學(xué)跑個(gè)幾千的數(shù)據(jù)集就要用GPU,就覺得Python在深度學(xué)習(xí)界的流行抬高了英偉達(dá)的市值。
N3LDG++中的C++代碼繼承自N3LDG,不過做了很大的改動(dòng),難以細(xì)述,最大的一點(diǎn)是改進(jìn)了Node類型的資源管理方式,所有的Node對(duì)象由Graph持有(比如在N3LDG中每多創(chuàng)建一個(gè)節(jié)點(diǎn),都需要有相應(yīng)的對(duì)象來持有,不能當(dāng)作臨時(shí)變量用,這很不方便)。不過歷史遺留的代碼還是有點(diǎn)亂,不少該抽象的地方?jīng)]有抽象,以后慢慢改吧(唉純算法背景寫出的代碼真是。。。)
最后,我覺得從0寫一個(gè)可用的深度學(xué)習(xí)框架不難,但是工作量很大, 對(duì)人的要求也不高(但是多,不能光懂算法),主要以下幾點(diǎn):
-
編碼能力過關(guān),精通C++、CUDA、OO思想,以及能搞定一切的debug能力 -
編碼習(xí)慣良好,比如重視變量命名 -
算法方面,會(huì)手算梯度就行
https://www.zhihu.com/question/326890535/answer/700281308首先需要熟練使用C++編程,其次學(xué)會(huì)cuda的GPU顯卡計(jì)算框架,了解一下并行計(jì)算,寫出比TensorFlow快的框架非常簡單。畢竟TensorFlow為了可移植性等等犧牲了很多。
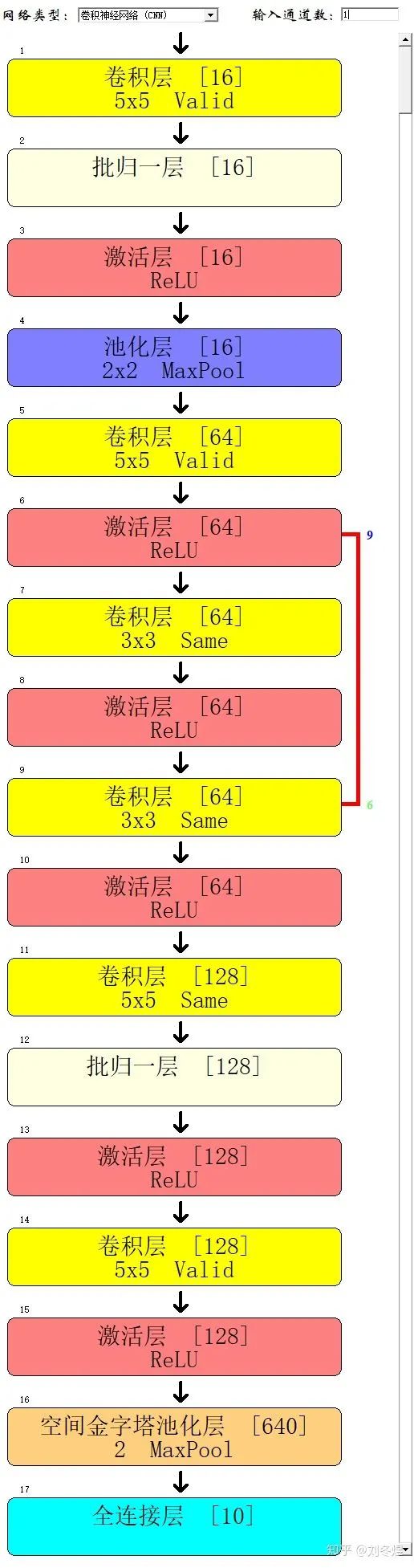

我已經(jīng)用自己的框架做了三四個(gè)項(xiàng)目了,由于干最底層的算法崗,自己這不成熟的框架已經(jīng)能勝任幾乎所有需求了。目前我正在對(duì)框架進(jìn)行可視化的相應(yīng)改進(jìn),力求能進(jìn)一步突破TensorBoard。
https://www.zhihu.com/question/326890535/answer/827912517
1、現(xiàn)在網(wǎng)上tensorflow能源碼級(jí)的,較清晰解讀尚且沒看到,不知道說不難的人自己有沒有過過源碼;
2、不要把手寫一兩種CNN網(wǎng)絡(luò)的難度和一個(gè)大規(guī)模商用深度學(xué)習(xí)平臺(tái)來比,不考慮各類具體算法實(shí)現(xiàn),單單是工程層面的抽象、設(shè)計(jì)也不簡單;
3、還有說tf里算法容易的,就想先請(qǐng)教一個(gè)小問題,Tensorflow里那種通用求導(dǎo)是如何實(shí)現(xiàn)的?別上網(wǎng)搜,想想能搞定不?
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請(qǐng)聯(lián)系微信號(hào):yiyang-sy 刪除或修改!
—THE END—