
解決小目標檢測!多尺度方法匯總

極市導讀
?本文匯總了SNIP/SNIPER、SSD、空洞卷積、FPN等多尺度圖像處理方法,詳細介紹了它們的網(wǎng)絡結構和實現(xiàn)細節(jié),對大家理解小目標檢測很有幫助。
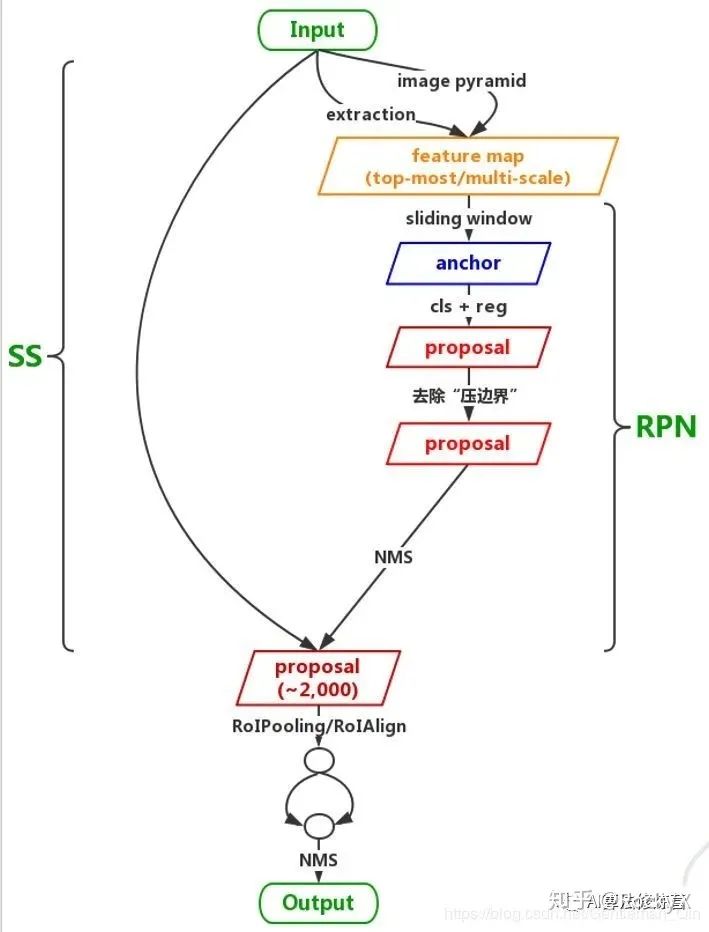
傳統(tǒng)的圖像金字塔
最開始在深度學習方法流行之前,對于不同尺度的目標,大家普遍使用將原圖構建出不同分辨率的圖像金字塔,再對每層金字塔用固定輸入分辨率的分類器在該層滑動來檢測目標,以求在金字塔底部檢測出小目標;或者只用一個原圖,在原圖上,用不同分辨率的分類器來檢測目標,以求在比較小的窗口分類器中檢測到小目標。經(jīng)典的基于簡單矩形特征(Haar)+級聯(lián)Adaboost與Hog特征+SVM的DPM目標識別框架,均使用圖像金字塔的方式處理多尺度目標,早期的CNN目標識別框架同樣采用該方式,但對圖像金字塔中的每一層分別進行CNN提取特征,耗時與內(nèi)存消耗均無法滿足需求。但該方式毫無疑問仍然是最優(yōu)的。值得一提的是,其實目前大多數(shù)深度學習算法提交結果進行排名的時候,大多使用多尺度測試。同時類似于SNIP使用多尺度訓練,均是圖像金字塔的多尺度處理。
SNIP/SNIPER中的多尺度處理
論文地址:https://arxiv.org/abs/1711.08189
代碼地址:https://github.com/mahyarnajibi/SNIPER
當前的物體檢測算法通常使用微調(diào)的方法,即先在ImageNet數(shù)據(jù)集上訓練分類任務,然后再遷移到物體檢測的數(shù)據(jù)集上,如COCO來訓練檢測任務。我們可以將ImageNet的分類任務看做224×224的尺度,而COCO中的物體尺度大部分在幾十像素的范圍內(nèi),并且包含大量小物體,物體尺度差距更大,因此兩者的樣本差距太大,會導致映射遷移(Domain Shift)的誤差。
SNIP是多尺度訓練(Multi-Scale Training)的改進版本。MST的思想是使用隨機采樣的多分辨率圖像使檢測器具有尺度不變特性。然而作者通過實驗發(fā)現(xiàn),在MST中,對于極大目標和過小目標的檢測效果并不好,但是MST也有一些優(yōu)點,比如對一張圖片會有幾種不同分辨率,每個目標在訓練時都會有幾個不同的尺寸,那么總有一個尺寸在指定的尺寸范圍內(nèi)。
SNIP的做法是只對size在指定范圍內(nèi)的目標回傳損失,即訓練過程實際上只是針對某些特定目標進行,這樣就能減少domain-shift帶來的影響。
SNIP的網(wǎng)絡結構如下圖所示:
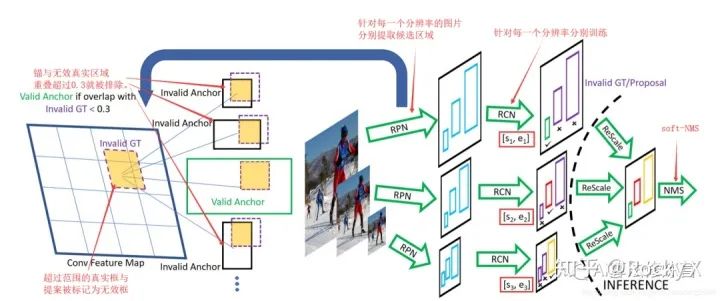
具體的實現(xiàn)細節(jié):
(1)3個尺度分別擁有各自的RPN模塊,并且各自預測指定范圍內(nèi)的物體。
(2)對于大尺度的特征圖,其RPN只負責預測被放大的小物體,對于小尺度的特征圖,其RPN只負責預測被縮小的大物體,這樣真實的物體尺度分布在較小的區(qū)間內(nèi),避免了極大或者極小的物體。
(3)在RPN階段,如果真實物體不在該RPN預測范圍內(nèi),會被判定為無效,并且與該無效物體的IoU大于0.3的Anchor也被判定為無效的Anchor。
(4)在訓練時,只對有效的Proposal進行反向傳播。在測試階段,對有效的預測Boxes先縮放到原圖尺度,利用Soft NMS將不同分辨率的預測結果合并。
(5)實現(xiàn)時SNIP采用了可變形卷積的卷積方式,并且為了降低對于GPU的占用,將原圖隨機裁剪為1000×1000大小的圖像。使用Deformable-RFCN檢測器提取單一分辨率的候選。Deformable-RFCN的主干網(wǎng)絡選用ResNet-101,訓練分辨率為800x1200。在RPN中選用5個錨尺寸。分類時,選用沒有Deformable Position Sensitive RoIPooling的主干網(wǎng)路為ResNet-50的Deformable-RFCN。使用帶有雙線性插值的Position Sensitive RoIPooling, 因為它將最后一層中的卷積核數(shù)量減少了3倍。NMS的閾值為0.3,不是端到端的訓練。使用ResNet-50以及消除deformable PSRoI filters可以減少3倍的時間并且節(jié)省GPU內(nèi)存。
總體來說,SNIP讓模型更專注于物體本身的檢測,剝離了多尺度的學習難題。在網(wǎng)絡搭建時,SNIP也使用了類似于MST的多尺度訓練方法,構建了3個尺度的圖像金字塔,但在訓練時,只對指定范圍內(nèi)的Proposal進行反向傳播,而忽略掉過大或者過小的Proposal。
SNIP方法雖然實現(xiàn)簡單,但其背后卻蘊藏深意,更深入地分析了當前檢測算法在多尺度檢測上的問題所在,在訓練時只選擇在一定尺度范圍內(nèi)的物體進行學習,在COCO數(shù)據(jù)集上有3%的檢測精度提升,可謂是大道至簡。
論文地址:https://arxiv.org/abs/1805.09300?
代碼地址:https://github.com/MahyarNajibi/SNIPER
SNIPER的關鍵是減少了SNIP的計算量。SNIP借鑒了multi-scale training的思想進行訓練,multi-scale training是用圖像金字塔作為模型的輸入,這種做法雖然能夠提高模型效果,但是計算量的增加也非常明顯,因為模型需要處理每個scale圖像的每個像素,而SNIPER(Scale Normalization for Image Pyramids with Efficient Resampling)算法以適當?shù)谋壤幚韌round truth(稱為chips)周圍的上下文區(qū)域,在訓練期間每個圖像生成的chips的數(shù)量會根據(jù)場景復雜度而自適應地變化,由于SNIPER在采樣后的低分辨率的chips上運行,故其可以在訓練期間收益于Batch Normalization,而不需要在GPU之間再用同步批量標準化進行統(tǒng)計信息。實驗證明,BN有助于最后性能的提升。
這些chips主要分為兩大類:
一種是postivice chips,這些chips包含ground truth;
另一種是從RPN網(wǎng)絡輸出的ROI抽樣得到的negative chips,這些chips相當于是難分類的背景,而那些容易分類的背景就沒必要進行多尺度訓練了。
因此模型最終只處理這些chips,而不是處理整張圖像,這樣就達到提升效果的同時提升速度。相比于SNIP,基于Faster RCNN(ResNet101作為Backbone)的實驗結果顯示SNIPER的mAP值比SNIP算法提升了4.6百分點,所以效果也還是非常不錯的。在單卡V100上,每秒可以處理5張圖像,這個速度在two-stage的算法中來看并不快,但是效果是非常好。
SNIPER的思路:
把圖片丟到網(wǎng)絡中時,就會產(chǎn)生不同尺度的feature map。作者的想法就是在特征圖上的ground truth box周圍去crop一些圖片,這些圖片稱為chips。
1、如何選擇positive chips : 就是在圖像金字塔的每一層中,都設定一個范圍,在該大小范圍內(nèi)的目標就可以標出來作為ground truth box,然后對圖片中ground truth box所在的地方進行crop,crop出來的圖片就是chips。選擇positive chips的一個要求就是,每一個pos chip都至少應該覆蓋一個groud-truth box,當然一個groud-truth box可以被多個pos chips包含。
2、如何選擇negative chips : 如果只基于前面的positive chip,那么因為大量的背景區(qū)域沒有參與訓練,所以容易誤檢(比較高的false positive rate),傳統(tǒng)的multi scale訓練方式因為有大量的背景區(qū)域參與計算,所以誤檢率沒那么高,但因為大部分背景區(qū)域都是非常容易分類的,所以這部分計算量是可以避免的,于是就有了negative chip seleciton。選擇negative chips的目的在于要讓網(wǎng)絡更容易去判斷出哪些是背景,而不必花費太多的時間在上面。在Faster-RCNN中的RPN的其中一步就是,將anchor和ground truth box交并比小于0.3視為背景,全部去掉(去掉易分樣本)。然后剩下的再去掉完全覆蓋groun truth box的proposal(去掉易分樣本),大部分proposal都是具有假陽性的,也就是和ground truth 都有一部分的交集,但是比較小,我們的negative chips都從這里來。(negative chips就是難分樣本)。這樣可以用來減少假陽率。
3、標注label:每一張chip上大概產(chǎn)生300個proposal,但是對這300個proposals不做限制(比如faster-rcnn會濾除掉背景部分,我們不這樣),而是對里面的一些proposal抽出來做positive proposal。
4、模型訓練:應該是先生成chips,然后再用chips去訓練一個端到端的網(wǎng)絡,所以其實是分開進行的。
如下圖是作者的選擇positive chips的一個示意圖:

左側中,綠色框起來的就是ground truth的所在,其他顏色是生成的chips,這張圖就生成了4個chips,右側中綠色線條就是valid box,紅色的線就是invalid box。可以看出,合適尺度內(nèi)的ground truth box就是valid box(藍色和紅色框內(nèi)綠線),否則就是invalid box(黃色和紫色圖中的紅線就是invalid)(clip的尺寸要比原圖小很多,不然就起不到減少計算量的目的,對于高分辨率的圖,clip可以比它小十倍不止)
下圖是作者選擇negative chips的一個示意圖:

negative chips的選取
上面一行就是ground truth boxes,下面一行就是作者選擇的negative chips,比如最后兩個,negative chips都和ground truth box有一定的交集。這就是我們所需要的negative chips。第二行圖像中的紅色小圓點表示沒有被positive chips(Cipos)包含的negative proposals,因為proposals較多,用框畫出來的話比較繁雜,所以用紅色小圓點表示。橘色框表示基于這些negative proposals生成的negative chips,也就是Cineg。每個negative chip是這么得到的:對于尺度i而言,首先移除包含在Cipos的region proposal,然后在Ri范圍內(nèi),每個chip都至少選擇M個proposal。在訓練模型時,每一張圖像的每個epoch都處理固定數(shù)量的negative chip,這些固定數(shù)量的negative chip就是從所有scale的negative chip中抽樣得到的。
優(yōu)點:
1、確實可以減少計算量;(一張圖片可以Crop出5個512x512的chips,而且進行3個尺度的訓練,但是它的計算量只比一張800x1333的圖片進行單尺度訓練多出30%,要是800x1333也進行多尺度訓練時,訓練量可比這種方法大多了)
2、用固定大小的chips去進行訓練時,數(shù)據(jù)很容易被打包,更利于GPU的使用。(把數(shù)據(jù)丟到GPU中去訓練,這30%的差距算個毛線,GPU計算速度那么大呢)
3、更為重要的是,可以進行多尺度訓練,設置更大的batch_size和batch normalization,而且再也不用擔心這些操作會拉低我們的速度了!
實驗細節(jié):用圖像金字塔生成chips的時候,在不同scale的層上使用的ground truth box范圍在[0,802]、[322,1502]、[1202, inf]。訓練RPN是為了獲取negative chips。每一張圖上產(chǎn)生的chips是不同的,如果這張圖包含的目標多,產(chǎn)生的chips就會增多,相反則減少。
在SNIP的基礎上加了一個「positive/negative chip selection」,從實驗結果來看是非常SOTA的,可以說碾壓了Mosaic反應出來的結果。另外基于ResNet101的Faster RCNN架構結合SNIPER,精度超過了YOLOV4接近4個點,效果是非常好的。感興趣的朋友可以嘗試。
SSD中的多尺度處理
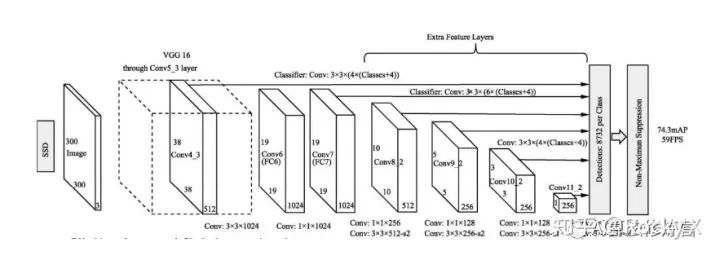
SSD以不同stride的feature map作為檢測層分別檢測不同尺度的目標,用戶可以根據(jù)自己的任務的目標尺度制定方案。該方式尺度處理簡單有效,但存在一些缺陷:
空洞卷積處理多尺度
空洞卷積本身可以控制不同大小的感受野,也即可以處理多尺度;一般空洞率設計得越大,感受野越大(但一般空洞率不能無限擴大,網(wǎng)格效應問題會加劇)。
TridentNet:三叉戟網(wǎng)絡
論文地址:https://arxiv.org/abs/1901.01892
代碼地址:https://github.com/TuSimple/simpledet/tree/master/models/tridentnet
傳統(tǒng)的解決多尺度檢測的算法,大都依賴于圖像金字塔與特征金字塔。與上述算法不同,圖森組對感受野這一因素進行了深入的分析,并利用了空洞卷積這一利器,構建了簡單的三分支網(wǎng)絡TridentNet,對于多尺度物體的檢測有了明顯的精度提升。
TridentNet網(wǎng)絡的作者將3種不同的感受野網(wǎng)絡并行化,提出了如下圖所示的檢測框架。采用ResNet作為基礎Backbone,前三個stage沿用原始的結構,在第四個stage,使用了三個感受野不同的并行網(wǎng)絡。
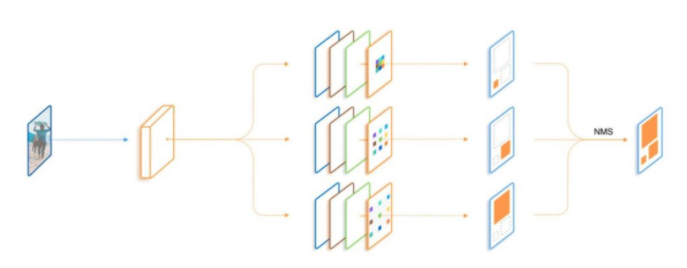
具體實現(xiàn)細節(jié):
(1)3個不同的分支使用了空洞數(shù)不同的空洞卷積,感受野由小到大,可以更好地覆蓋多尺度的物體分布。
(2)由于3個分支要檢測的內(nèi)容是相同的、要學習的特征也是相同的,只不過是形成了不同的感受野來檢測不同尺度的物體,因此,3個分支共享權重,這樣既充分利用了樣本信息,學習到更本質(zhì)的目標檢測信息,也減少了參數(shù)量與過擬合的風險。
(3)借鑒了SNIP的思想,在每一個分支內(nèi)只訓練一定范圍內(nèi)的樣本,避免了過大與過小的樣本對于網(wǎng)絡參數(shù)的影響。
在訓練時,TridentNet網(wǎng)絡的三個分支會接入三個不同的head網(wǎng)絡進行后續(xù)損失計算。在測試時,由于沒有先驗的標簽來選擇不同的分支,因此只保留了一個分支進行前向計算,這種前向方法只有少量的精度損失。
FPN中的多尺度處理及其改進
自從2016年FPN網(wǎng)絡出來后,目前各大視覺任務的baseline基本都是以backbone-FPN。FPN以更為輕量的最近鄰插值結合側向連接實現(xiàn)了將高層的語義信息逐漸傳播到低層的功能,使得尺度更為平滑,同時它可以看做是輕量級的decoder結構。FPN看起來很完美,但仍然有一些缺陷:
PANet
論文地址:https://arxiv.org/abs/1803.01534
代碼地址:https://github.com/ShuLiu1993/PANet
PANet是由香港中文大學和騰訊優(yōu)圖聯(lián)合提出的實例分割框架。模型不是直接實現(xiàn)目標檢測,但是論文的核心內(nèi)容是增強FPN的多尺度融合信息。PANet 在 COCO 2017 挑戰(zhàn)賽的實例分割任務中取得了第一名,在目標檢測任務中取得了第二名。
FPN的低層次的特征(C5)對應大型目標,而高層級特征與低層級別特征之間路徑較長(如圖 2a所示紅色虛線),增加訪問準確定位信息的難度。為了縮短信息路徑和用低層級的準確定位信息增強特征金字塔,PANet在FPN基礎上創(chuàng)建了自下而上的路徑增強(圖 2b)。用于縮短信息路徑,利用low-level 特征中存儲的精確定位信號,提升特征金字塔架構。
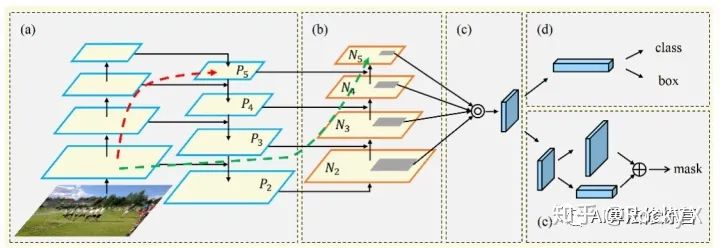
PANet創(chuàng)建自適應特征池化(Adaptive feature pooling)( 圖 2c)。用于恢復每個候選區(qū)域和所有特征層次之間被破壞的信息路徑,聚合每個特征層次上的每個候選區(qū)域。
PANet的目標檢測和實例分割共享網(wǎng)絡架構的圖 2 abc三部分,使得兩者性能均有提升。
ThunderNet
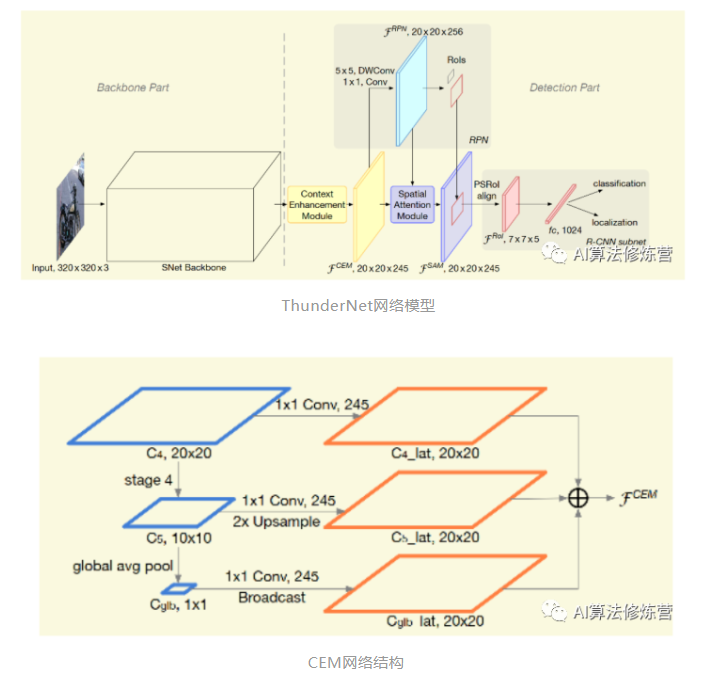
ThunderNet是曠視提出的輕量型目標檢測框架,實現(xiàn)了ARM平臺上的實時檢測器,整體結構如圖 3所示。主要簡化了FPN結構,只使用C4/C5,同時引入gpooling操作(Face++論文好多這么用,確實有效),最終輸出C4分辨率大小的累加特征。ThunderNet使用320×320像素作為網(wǎng)絡的輸入分辨率。
整體的網(wǎng)絡結構分為兩部分:Backbone部分和Detection部分。網(wǎng)絡的骨干部分為SNet(ShuffleNetV2修改版)。 網(wǎng)絡的檢測部分,利用了壓縮的RPN網(wǎng)絡,既Context Enhancement Module(CEM)整合局部和全局特征增強網(wǎng)絡特征表達能力。并提出Spatial Attention Module空間注意模塊,引入來自RPN的前后景信息用以優(yōu)化特征分布。
FPN的結合不同層語義信息,但是相對而言每層均有檢測分支,對移動終端而言增加計算成本和運行時間。論文提出簡單粗暴的CEM(如圖 4所示),合并三個尺度特征圖C4,C5和Cglb:
1、C4 1×1卷積,通道數(shù)量壓縮為α×p×p = 245
2、C5進行上采樣 + 1×1卷積,通道數(shù)量壓縮為α×p×p = 245
3、C5全局平均池化得到Cglb,Cglb進行Broadcast + 1×1卷積,通道數(shù)量壓縮為α×p×p = 245 。
通過利用局部和全局信息,CEM有效地擴大了感受野,并細化了特征圖的表示能力。與先前的FPN結構相比,CEM predict預測及減少fc計算,提高模型運算效率。
代碼地址:https://github.com/OceanPang/Libra_R-CNN
Libra R-CNN是有浙江大學,香港中文大學等聯(lián)合提出目標檢測模型。無論是one-stage two-stage,都涉及選擇候選區(qū)域,特征提取與融合、loss收斂。針對目標檢測的三個階段,論文提出三個問題:采樣的候選區(qū)域示范具有代表性,不同level特征如何融合,以及損失函數(shù)如何更好收斂。論文針對三個問題提出三個改進方向:
1、IoU-balanced Sampling
M個候選框選擇N個hard negative,選中的概率就是:
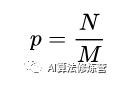
N個樣本通過IoU的值劃分為K個區(qū)間,每個區(qū)間中的候選采樣數(shù)為Mk,則IoU-balanced sampling的采樣公式即為:
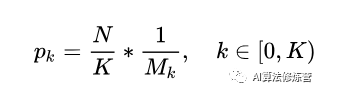
作者通過在IoU上均勻采樣, 把hard negative在IoU上均勻分布。
2、Balanced Feature Pyramid
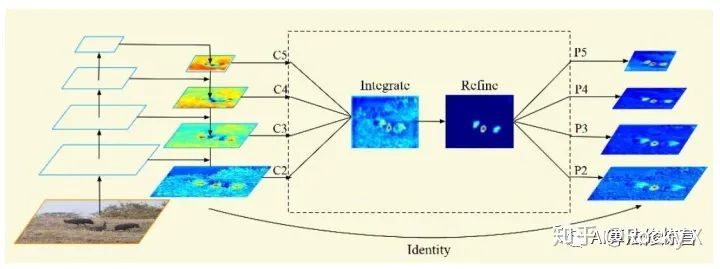
為了更高效利用FPN特征,論文使用4步改進rescaling, integrating, refining,Strengthening(如上圖所示):
a、rescaling。把{C2,C3 ,C5}的多層特征均rescaling到C4尺寸,做加權求平均值。得到的特征C rescaling返回到{C2,C3 ,C5}特征分辨率。
b、Refining&strengthening。論文使用Gaussian non-local attention 增加特征。
c、 Indentity,既殘差設計。
3、Balanced L1 Loss。
推薦閱讀
