
數(shù)據(jù)湖VS數(shù)據(jù)倉庫之爭?阿里提出大數(shù)據(jù)架構(gòu)新概念:湖倉一體

導(dǎo)讀:隨著近幾年數(shù)據(jù)湖概念的興起,業(yè)界對于數(shù)據(jù)倉庫和數(shù)據(jù)湖的對比甚至爭論就一直不斷。有人說數(shù)據(jù)湖是下一代大數(shù)據(jù)平臺,各大云廠商也在紛紛的提出自己的數(shù)據(jù)湖解決方案,一些云數(shù)倉產(chǎn)品也增加了和數(shù)據(jù)湖聯(lián)動的特性。
但是數(shù)據(jù)倉庫和數(shù)據(jù)湖的區(qū)別到底是什么,是技術(shù)路線之爭?是數(shù)據(jù)管理方式之爭?二者是水火不容還是其實可以和諧共存,甚至互為補充?
本文作者來自阿里巴巴計算平臺部門,深度參與阿里巴巴大數(shù)據(jù)/數(shù)據(jù)中臺領(lǐng)域建設(shè),將從歷史的角度對數(shù)據(jù)湖和數(shù)據(jù)倉庫的來龍去脈進行深入剖析,來闡述兩者融合演進的新方向——湖倉一體,并就基于阿里云MaxCompute/EMR DataLake的湖倉一體方案做一介紹。

數(shù)據(jù)保持高速增長- 從5V核心要素看,大數(shù)據(jù)領(lǐng)域保持高速增長。阿里巴巴經(jīng)濟體,作為一個重度使用并著力發(fā)展大數(shù)據(jù)領(lǐng)域的公司,過去5年數(shù)據(jù)規(guī)模保持高速增長(年化60%-80%),增速在可見的未來繼續(xù)保持。對于新興企業(yè),大數(shù)據(jù)領(lǐng)域增長超過年200%。 大數(shù)據(jù)作為新的生產(chǎn)要素,得到廣泛認可- 大數(shù)據(jù)領(lǐng)域價值定位的遷移,從“探索”到“普惠”,成為各個企業(yè)/政府的核心部門,并承擔關(guān)鍵任務(wù)。還是以阿里巴巴為例,30%的員工直接提交大數(shù)據(jù)作業(yè)。隨大數(shù)據(jù)普惠進入生產(chǎn)環(huán)境,可靠性、安全性、管控能力、易用性等企業(yè)級產(chǎn)品力增強。 數(shù)據(jù)管理能力成為新的關(guān)注點- 數(shù)倉(中臺)能力流行起來,如何用好數(shù)據(jù)成為企業(yè)的核心競爭力。 引擎技術(shù)進入收斂期?- 隨著Spark(通用計算)、Flink(流計算)、Hbase(KV)、Presto(交互分析)、ElasticSearch(搜索)、Kafka(數(shù)據(jù)總線)自從2010-2015年逐步占領(lǐng)開源生態(tài),最近5年新引擎開源越來越少,但各引擎技術(shù)開始向縱深發(fā)展(更好的性能、生產(chǎn)級別的穩(wěn)定性等)。 平臺技術(shù)演進出兩個趨勢,數(shù)據(jù)湖?VS 數(shù)據(jù)倉庫- 兩者均關(guān)注數(shù)據(jù)存儲和管理(平臺技術(shù)),但方向不同。

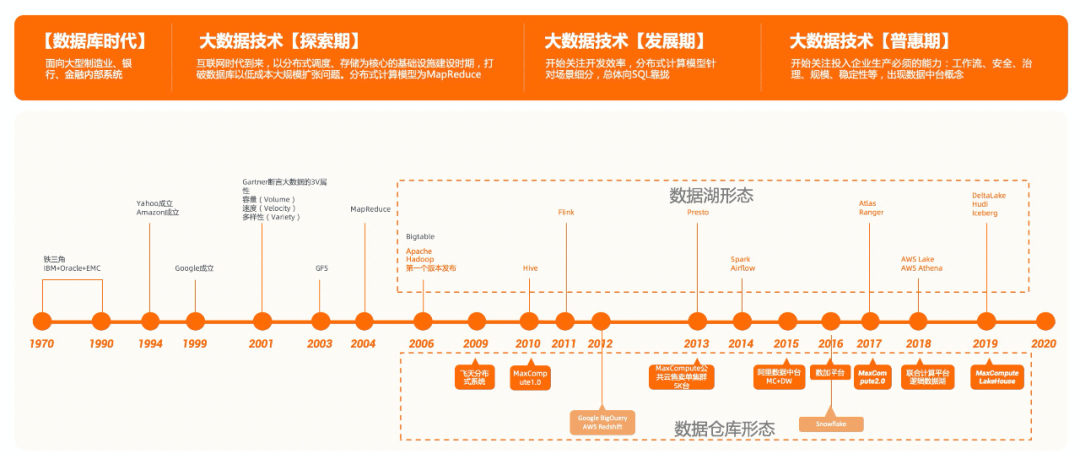
階段一:數(shù)據(jù)庫時代
階段二:大數(shù)據(jù)技術(shù)的「探索期」
階段三:大數(shù)據(jù)技術(shù)的「發(fā)展期」
階段四:大數(shù)據(jù)技術(shù)「普及期」
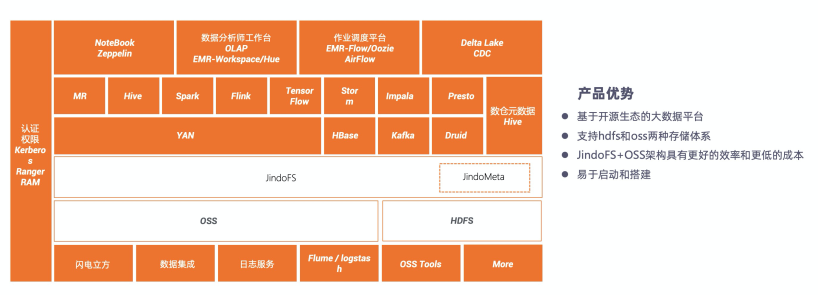
開源 Hadoop 線,引擎、元數(shù)據(jù)、存儲等基礎(chǔ)部件的迭代更替進入相對穩(wěn)態(tài),大眾對開源大數(shù)據(jù)技術(shù)的認知達到空前的水平。一方面,開放架構(gòu)的便利帶來了不錯的市場份額,另一方面開放架構(gòu)的松散則使開源方案在企業(yè)級能力構(gòu)建上遇到瓶頸,尤其是數(shù)據(jù)安全、身份權(quán)限強管控、數(shù)據(jù)治理等方面,協(xié)同效率較差(如 Ranger 作為權(quán)限管控組件、Atlas 作為數(shù)據(jù)治理組件,跟今天的主流引擎竟然還無法做到全覆蓋)。同時引擎自身的發(fā)展也對已有的開放架構(gòu)提出了更多挑戰(zhàn),Delta Lake、Hudi 這樣自閉環(huán)設(shè)計的出現(xiàn)使得一套存儲、一套元數(shù)據(jù)、多種引擎協(xié)作的基礎(chǔ)出現(xiàn)了某種程度的裂痕。 真正將數(shù)據(jù)湖概念推而廣之的是AWS。AWS 構(gòu)筑了一套以 S3 為中心化存儲、Glue 為元數(shù)據(jù)服務(wù),E-MapReduce、Athena 為引擎的開放協(xié)作式的產(chǎn)品解決方案。它的開放性和和開源體系類似,并在2019年推出Lake Formation 解決產(chǎn)品間的安全授信問題。雖然這套架構(gòu)在企業(yè)級能力上和相對成熟的云數(shù)據(jù)倉庫產(chǎn)品相去甚遠,但對于開源技術(shù)體系的用戶來說,架構(gòu)相近理解容易,還是很有吸引力。AWS 之后,各個云廠商也紛紛跟進數(shù)據(jù)湖的概念,并在自己的云服務(wù)上提供類似的產(chǎn)品解決方案。 云廠商主推的數(shù)據(jù)倉庫類產(chǎn)品則發(fā)展良好,數(shù)倉核心能力方面持續(xù)增強。性能、成本方面極大提升(MaxCompute 完成了核心引擎的全面升級和性能跳躍式發(fā)展,連續(xù)三年刷新 TPCx-BigBench 世界記錄),數(shù)據(jù)管理能力空前增強(數(shù)據(jù)中臺建模理論、智能數(shù)倉),企業(yè)級安全能力大為繁榮(同時支持基于 ACL 和基于規(guī)則等多種授權(quán)模型,列級別細粒度授權(quán),可信計算,存儲加密,數(shù)據(jù)脫敏等),在聯(lián)邦計算方面也普遍做了增強,一定程度上開始將非數(shù)倉自身存儲的數(shù)據(jù)納入管理,和數(shù)據(jù)湖的邊界日益模糊。
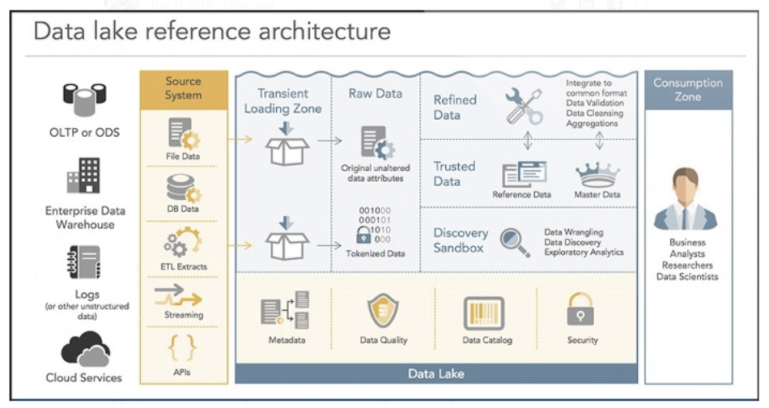
A data lake is a system or?repository of datastored in its natural/raw format,usually object?blobsor files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as?reporting,?visualization,?advanced analyticsand?machine learning. A data lake can include?structured datafrom?relational databases(rows and columns), semi-structured data (CSV, logs,?XML,?JSON),?unstructured data(emails, documents, PDFs) and?binary data(images,?audio,?video).?A data lake can be established "on premises" (within an organization's data centers) or "in the cloud" (using cloud services from vendors such as Amazon, Google and Microsoft).A data swamp is a deteriorated and unmanaged data lake that is either inaccessible to its intended users or is providing little value. 數(shù)據(jù)湖是指使用大型二進制對象或文件這樣的自然格式儲存數(shù)據(jù)的系統(tǒng)。它通常把所有的企業(yè)數(shù)據(jù)統(tǒng)一存儲,既包括源系統(tǒng)中的原始副本,也包括轉(zhuǎn)換后的數(shù)據(jù),比如那些用于報表, 可視化, 數(shù)據(jù)分析和機器學習的數(shù)據(jù)。數(shù)據(jù)湖可以包括關(guān)系數(shù)據(jù)庫的結(jié)構(gòu)化數(shù)據(jù)(行與列)、半結(jié)構(gòu)化的數(shù)據(jù)(CSV,日志,XML, JSON),非結(jié)構(gòu)化數(shù)據(jù) (電子郵件、文件、PDF)和 二進制數(shù)據(jù)(圖像、音頻、視頻)。儲存數(shù)據(jù)湖的方式包括 Apache Hadoop分布式文件系統(tǒng), Azure 數(shù)據(jù)湖或亞馬遜云 Lake Formation云存儲服務(wù),以及諸如 Alluxio 虛擬數(shù)據(jù)湖之類的解決方案。數(shù)據(jù)沼澤是一個劣化的數(shù)據(jù)湖,用戶無法訪問,或是沒什么價值。
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions. 數(shù)據(jù)湖是一個集中式存儲庫,允許您以任意規(guī)模存儲所有結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。您可以按原樣存儲數(shù)據(jù)(無需先對數(shù)據(jù)進行結(jié)構(gòu)化處理),并運行不同類型的分析 – 從控制面板和可視化到大數(shù)據(jù)處理、實時分析和機器學習,以指導(dǎo)做出更好的決策。
統(tǒng)一的存儲系統(tǒng) 存儲原始數(shù)據(jù) 豐富的計算模型/范式 數(shù)據(jù)湖與上云無關(guān)
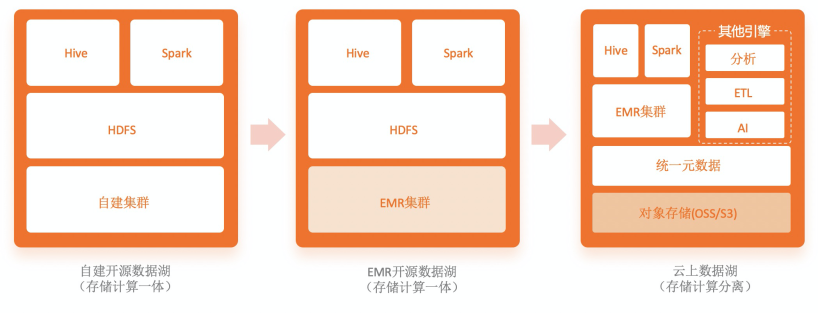
幫助用戶擺脫原生HDFS系統(tǒng)運維困難的問題。HDFS系統(tǒng)運維有兩個困難:1)存儲系統(tǒng)相比計算引擎更高的穩(wěn)定性要求和更高的運維風險 2)與計算混布在一起,帶來的擴展彈性問題。存儲計算分離架構(gòu)幫助用戶解耦存儲,并交由云廠商統(tǒng)一運維管理,解決了穩(wěn)定性和運維問題。 分離后的存儲系統(tǒng)可以獨立擴展,不再需要與計算耦合,可降低整體成本 當用戶采用數(shù)據(jù)湖架構(gòu)之后,客觀上也幫助客戶完成了存儲統(tǒng)一化(解決多個HDFS數(shù)據(jù)孤島的問題)
In?computing, a data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is a system used for?reportingand?data analysis, and is considered a core component of?business intelligence.DWs are central repositories of integrated data from one or more disparate sources.?Extract, transform, load(ETL) and?extract, load, transform(E-LT) are the two main approaches used to build a data warehouse system. 在計算機領(lǐng)域,數(shù)據(jù)倉庫(英語:data warehouse,也稱為企業(yè)數(shù)據(jù)倉庫)是用于報告和數(shù)據(jù)分析的系統(tǒng),被認為是商業(yè)智能的核心組件。數(shù)據(jù)倉庫是來自一個或多個不同源的集成數(shù)據(jù)的中央存儲庫。數(shù)據(jù)倉庫將當前和歷史數(shù)據(jù)存儲在一起,用于為整個企業(yè)的員工創(chuàng)建分析報告。比較學術(shù)的解釋是,數(shù)據(jù)倉庫由數(shù)據(jù)倉庫之父W.H.Inmon于1990年提出,主要功能乃是將組織透過信息系統(tǒng)之在線交易處理(OLTP)經(jīng)年累月所累積的大量數(shù)據(jù),透過數(shù)據(jù)倉庫理論所特有的數(shù)據(jù)存儲架構(gòu),作一有系統(tǒng)的分析整理,以利各種分析方法如在線分析處理(OLAP)、數(shù)據(jù)挖掘(Data Mining)之進行,并進而支持如決策支持系統(tǒng)(DSS)、主管信息系統(tǒng)(EIS)之創(chuàng)建,幫助決策者能快速有效的自大量數(shù)據(jù)中,分析出有價值的信息,以利決策擬定及快速回應(yīng)外在環(huán)境變動,幫助建構(gòu)商業(yè)智能(BI)。
內(nèi)置的存儲系統(tǒng),數(shù)據(jù)通過抽象的方式提供(例如采用Table或者View),不暴露文件系統(tǒng)。 數(shù)據(jù)需要清洗和轉(zhuǎn)化,通常采用ETL/ELT方式 強調(diào)建模和數(shù)據(jù)管理,供商業(yè)智能決策
引擎深度理解數(shù)據(jù),存儲和計算可做深度優(yōu)化 數(shù)據(jù)全生命周期管理,完善的血緣體系 細粒度的數(shù)據(jù)管理和治理 完善的元數(shù)據(jù)管理能力,易于構(gòu)建企業(yè)級數(shù)據(jù)中臺


當企業(yè)處于初創(chuàng)階段,數(shù)據(jù)從產(chǎn)生到消費還需要一個創(chuàng)新探索的階段才能逐漸沉淀下來,那么用于支撐這類業(yè)務(wù)的大數(shù)據(jù)系統(tǒng),靈活性就更加重要,數(shù)據(jù)湖的架構(gòu)更適用。 當企業(yè)逐漸成熟起來,已經(jīng)沉淀為一系列數(shù)據(jù)處理流程,問題開始轉(zhuǎn)化為數(shù)據(jù)規(guī)模不斷增長,處理數(shù)據(jù)的成本不斷增加,參與數(shù)據(jù)流程的人員、部門不斷增多,那么用于支撐這類業(yè)務(wù)的大數(shù)據(jù)系統(tǒng),成長性的好壞就決定了業(yè)務(wù)能夠發(fā)展多遠。數(shù)據(jù)倉庫的架構(gòu)更適用。

2017年Redshift推出Redshift Spectrum,支持Redsift數(shù)倉用戶訪問S3數(shù)據(jù)湖的數(shù)據(jù)。 2018年阿里云MaxCompute推出外表能力,支持訪問包括OSS/OTS/RDS數(shù)據(jù)庫在內(nèi)的多種外部存儲。
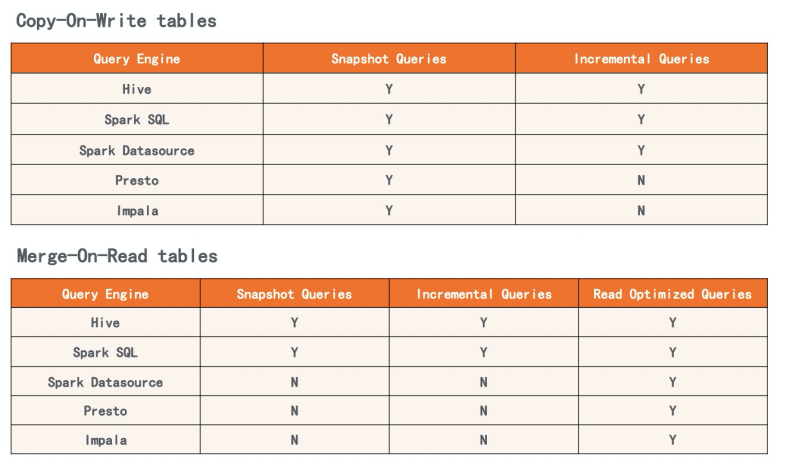
2011年,Hadoop開源體系公司Hortonworks開始了Apache Atlas和Ranger兩個開源項目的開發(fā),分別對應(yīng)數(shù)據(jù)血緣追蹤和數(shù)據(jù)權(quán)限安全兩個數(shù)倉核心能力。但兩個項目發(fā)展并不算順利,直到 2017 年才完成孵化,時至今日,在社區(qū)和工業(yè)界的部署都還遠遠不夠活躍。核心原因數(shù)據(jù)湖與生俱來的靈活性。例如Ranger作為數(shù)據(jù)權(quán)限安全統(tǒng)一管理的組件,天然要求所有引擎均適配它才能保證沒有安全漏洞,但對于數(shù)據(jù)湖中強調(diào)靈活的引擎,尤其是新引擎來說,會優(yōu)先實現(xiàn)功能、場景,而不是把對接Ranger作為第一優(yōu)先級的目標,使得Ranger在數(shù)據(jù)湖上的位置一直很尷尬。 2018年,Nexflix開源了內(nèi)部增強版本的元數(shù)據(jù)服務(wù)系統(tǒng)Iceberg,提供包括MVCC(多版本并發(fā)控制)在內(nèi)的增強數(shù)倉能力,但因為開源HMS已經(jīng)成為事實標準,開源版本的Iceberg作為插件方式兼容并配合HMS,數(shù)倉管理能力大打折扣。 2018-2019年,Uber和Databricks相繼推出了Apache Hudi和DeltaLake,推出增量文件格式用以支持Update/Insert、事務(wù)等數(shù)據(jù)倉庫功能。新功能帶來文件格式以及組織形式的改變,打破了數(shù)據(jù)湖原有多套引擎之間關(guān)于共用存儲的簡單約定。為此,Hudi為了維持兼容性,不得不發(fā)明了諸如 Copy-On-Write、Merge-On-Read 兩種表,Snapshot Query、Incremental Query、Read Optimized Query 三種查詢類型,并給出了一個支持矩陣(如圖10),極大提升了使用的復(fù)雜度。
湖和倉的數(shù)據(jù)/元數(shù)據(jù)無縫打通,且不需要用戶人工干預(yù) 湖和倉有統(tǒng)一的開發(fā)體驗,存儲在不同系統(tǒng)的數(shù)據(jù),可以通過一個統(tǒng)一的開發(fā)/管理平臺操作 數(shù)據(jù)湖與數(shù)據(jù)倉庫的數(shù)據(jù),系統(tǒng)負責自動caching/moving,系統(tǒng)可以根據(jù)自動的規(guī)則決定哪些數(shù)據(jù)放在數(shù)倉,哪些保留在數(shù)據(jù)湖,進而形成一體化

MaxCompute全新自創(chuàng)PrivateAccess網(wǎng)絡(luò)連通技術(shù),在遵循云虛擬網(wǎng)絡(luò)安全標準的前提下,實現(xiàn)多租戶模式下特定用戶作業(yè)定向與IDC/ECS/EMR Hadoop集群網(wǎng)絡(luò)整體打通能力,具有低延遲、高獨享帶寬的特點。 經(jīng)過快速簡單的開通、安全配置步驟即可將數(shù)據(jù)湖和購買的 MaxCompute數(shù)倉相連通。
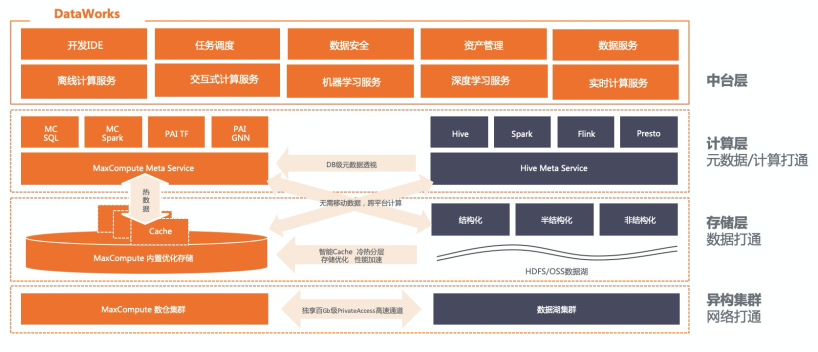
MaxCompute實現(xiàn)湖倉一體化的元數(shù)據(jù)管理,通過DB元數(shù)據(jù)一鍵映射技術(shù),實現(xiàn)數(shù)據(jù)湖和MaxCompute數(shù)倉的元數(shù)據(jù)無縫打通。MaxCompute通過向用戶開放創(chuàng)建external project的形式,將數(shù)據(jù)湖HiveMetaStore中的整個database直接映射為MaxCompute的project,對Hive Database的改動會實時反應(yīng)在這個project中,并可以在MaxCompute側(cè)隨時通過這個project進行訪問、計算其中的數(shù)據(jù)。與此同時,阿里云EMR數(shù)據(jù)湖解決方案也將推出Data Lake Formation,MaxCompute湖倉一體方案也會支持對該數(shù)據(jù)湖中的統(tǒng)一元數(shù)據(jù)服務(wù)的一鍵映射能力。MaxCompute側(cè)對external project的各種操作,也會實時反應(yīng)在Hive側(cè),真正實現(xiàn)數(shù)據(jù)倉庫和數(shù)據(jù)湖之間的無縫聯(lián)動,完全不需要類似聯(lián)邦查詢方案里的元數(shù)據(jù)人工干預(yù)步驟。 MaxCompute實現(xiàn)湖倉一體化的存儲訪問層,不僅支持內(nèi)置優(yōu)化的存儲系統(tǒng),也無縫的支持外部存儲系統(tǒng)。既支持HDFS數(shù)據(jù)湖,也支持OSS云存儲數(shù)據(jù)湖,可讀寫各種開源文件格式。
數(shù)據(jù)湖里的Hive DataBase映射為MaxCompute external project,和普通project別無二致,同樣享受MaxCompute數(shù)倉里的數(shù)據(jù)開發(fā)、追蹤和管理功能。基于DataWorks強大的數(shù)據(jù)開發(fā)/管理/治理能力,提供統(tǒng)一的湖倉開發(fā)體驗,降低兩套系統(tǒng)的管理成本。 MaxCompute高度兼容Hive/Spark,支持一套任務(wù)可以在湖倉兩套體系中靈活無縫的運行。 同時,MaxCompute也提供高效的數(shù)據(jù)通道接口,可以讓數(shù)據(jù)湖中的Hadoop生態(tài)引擎直接訪問,提升了數(shù)倉的開放性。
湖倉一體需要用戶根據(jù)自身資產(chǎn)使用情況將數(shù)據(jù)在湖和倉之間進行合理的分層和存儲,以最大化湖和倉的優(yōu)勢。MaxCompute開發(fā)了一套智能cache技術(shù),根據(jù)對歷史任務(wù)的分析來識別數(shù)據(jù)冷熱度,從而自動利用閑時帶寬將數(shù)據(jù)湖中的熱數(shù)據(jù)以高效文件格式cache在數(shù)據(jù)倉庫中,進一步加速數(shù)據(jù)倉庫的后續(xù)數(shù)據(jù)加工流程。不僅解決了湖倉之間的帶寬瓶頸問題,也達到了無須用戶參與即可實現(xiàn)數(shù)據(jù)分層管理/治理以及性能加速的目的。
案例背景
核心痛點
安排專人專項負責訓練數(shù)據(jù)同步,工作量巨大 訓練數(shù)據(jù)體量大,導(dǎo)致耗時多,無法滿足實時訓練的要求 新寫SQL數(shù)據(jù)處理query,無法復(fù)用Hive SQL原有query
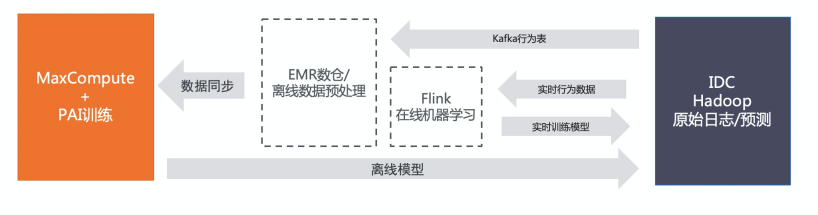
解決方案
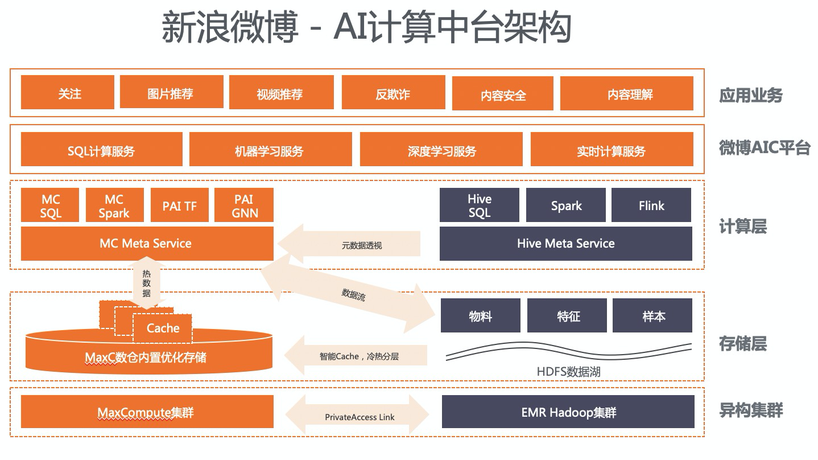
案例價值
不僅融合了數(shù)據(jù)湖和數(shù)據(jù)倉庫的優(yōu)勢,在靈活性和效率上找到最佳平衡,還快速構(gòu)建了一套統(tǒng)一的AI計算中臺,極大提升該機器學習平臺團隊的業(yè)務(wù)支撐能力。無須進行數(shù)據(jù)搬遷和作業(yè)遷移,即可將一套作業(yè)無縫靈活調(diào)度在MaxCompute集群和EMR集群中。 SQL數(shù)據(jù)處理任務(wù)被廣泛運行到MaxCompute集群,性能有明顯提升。基于阿里巴巴PAI豐富且強大的算法能力,封裝出多種貼近業(yè)務(wù)場景的算法服務(wù),滿足更多的業(yè)務(wù)需求。 MaxCompute云原生的彈性資源和EMR集群資源形成互補,兩套體系之間進行資源的削峰填谷,不僅減少作業(yè)排隊,且降低整體成本。

評論
圖片
表情