
MySQL千萬(wàn)大表優(yōu)化實(shí)踐
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




前段時(shí)間筆者遇到一個(gè)復(fù)雜的慢查詢,今天有空便進(jìn)行了整理,以便日后回顧。舉一個(gè)相似的業(yè)務(wù)場(chǎng)景的例子。以文章評(píng)論為例,查詢20191201~20191231日期間發(fā)表的經(jīng)濟(jì)科技類別的文章,同時(shí)需要顯示這些文章的熱評(píng)數(shù)目
涉及到的四張表結(jié)構(gòu)如下所示
文章表結(jié)構(gòu)和索引信息如下,文章表中存儲(chǔ)了200萬(wàn)數(shù)據(jù)


評(píng)論表結(jié)構(gòu)和索引信息如下,評(píng)論表存儲(chǔ)了1000萬(wàn)數(shù)據(jù)


文章分類表結(jié)構(gòu)如下,這張表數(shù)據(jù)比較少,僅僅存儲(chǔ)了300條數(shù)據(jù)

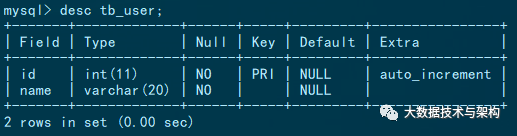
用戶表結(jié)構(gòu)如下,該表存儲(chǔ)了100萬(wàn)數(shù)據(jù)
其中涉及到的慢查詢語(yǔ)句如下所示,這個(gè)查詢語(yǔ)句性能非常慢,執(zhí)行時(shí)間接近60s
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
FROM
tb_article
LEFT JOIN tb_cmt ON tb_article.`id` = tb_cmt.`article_id`
INNER JOIN tb_user on tb_article.`userid` = tb_user.`id`
WHERE
tb_article.`type` IN (
SELECT code
FROM tb_category
WHERE code like '12%' or code like '13%'
)
AND tb_cmt.`upvote` > 100
AND tb_cmt.`len` BETWEEN 10 AND 30
AND tb_article.`create_time` BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
GROUP BY
tb_cmt.`article_id`使用explain分析慢查詢的執(zhí)行流程

Mysql執(zhí)行流程如下,首先mysql以tb_category作為驅(qū)動(dòng)表,看到這,有沒(méi)有感到很奇怪,tb_category在整個(gè)查詢中只是作為一個(gè)子查詢存在,tb_category怎么成為驅(qū)動(dòng)表了呢?如果讀者了解mysql的in子查詢?cè)淼脑捑秃芎美斫饬耍琺ysql會(huì)將in查詢改寫為semi-join關(guān)聯(lián)查詢,explain涉及到的start temporary和end temporary用于semi-join的去重。我們可以使用explain extended和show warnings查看mysql改寫的的查詢語(yǔ)句,mysql改寫后的查詢語(yǔ)句如下所示

Mysql為什么選擇tb_category作為驅(qū)動(dòng)表呢?原因是tb_category的表最小,只有300條數(shù)據(jù),mysql查詢優(yōu)化器通常情況下都會(huì)以小表作為驅(qū)動(dòng)表。
隨后,tb_category和tb_article進(jìn)行關(guān)聯(lián)計(jì)算,關(guān)聯(lián)計(jì)算的列是tb_article的type列,mysql使用了tb_article表上的type_time_idx的索引,這個(gè)過(guò)程mysql使用了Batched Key Access進(jìn)行了優(yōu)化以達(dá)到減少索引回表查找的IO次數(shù),隨后關(guān)聯(lián)tb_cmt表,這次關(guān)聯(lián)中,mysql使用了tb_cmt的article_id_idx字段。經(jīng)過(guò)上述關(guān)聯(lián),mysql生成了一個(gè)結(jié)果集,mysql再在結(jié)果集上對(duì)upvote,type和len字段進(jìn)行where條件篩選,最后進(jìn)行了一次group by操作。
優(yōu)化的核心思路仍然是減少掃描的行數(shù),從上述的explain結(jié)果上看,掃描的rows行數(shù)好像不是很多,但是tb_category,tb_article,tb_cmt,tb_user四張表關(guān)聯(lián)之后生成的結(jié)果集非常的龐大,筆者使用如下代碼進(jìn)行以一次計(jì)算
SELECT
count(*)
FROM
tb_article
LEFT JOIN tb_cmt ON tb_article.`id` = tb_cmt.`article_id`
INNER JOIN tb_user on tb_article.`userid` = tb_user.`id`
WHERE
tb_article.`type` IN (
SELECT code
FROM tb_category
WHERE code like '12%' or code like '13%'
)結(jié)果如下
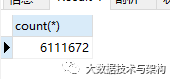
四張表的關(guān)聯(lián)結(jié)果集有611萬(wàn)數(shù)據(jù)
如果讀者了解Mysql關(guān)聯(lián)查詢?cè)淼脑挘x者便會(huì)知道m(xù)ysql的關(guān)聯(lián)查詢之后,如果再進(jìn)行條件篩選是無(wú)法使用非驅(qū)動(dòng)表索引的(換一句話講,mysql關(guān)聯(lián)查詢只會(huì)使用驅(qū)動(dòng)表的索引進(jìn)行條件篩選),也就是說(shuō)下面幾個(gè)條件都是無(wú)法使用索引的

在611萬(wàn)結(jié)果集上進(jìn)行upvote,len,create_time條件篩選和group by操作性能可想而知很慢了。筆者希望在執(zhí)行關(guān)聯(lián)查詢的時(shí)候可以盡量多的使用索引,比如upvote_len_idx,create_time_idx索引,所以驅(qū)動(dòng)表一定不能是tb_category。和1000萬(wàn)數(shù)據(jù)量的tb_cmt表相比,筆者更希望以只有200萬(wàn)數(shù)據(jù)量的tb_article表作為驅(qū)動(dòng)表。
步驟一:避免semi-join
如果筆者希望以tb_article作為驅(qū)動(dòng)表,那么一定要避免in的關(guān)聯(lián)子查詢,因?yàn)閙ysql在執(zhí)行in關(guān)聯(lián)子查詢的時(shí)候,會(huì)將其轉(zhuǎn)化為semi-join,因?yàn)閠b_category數(shù)據(jù)量少,mysql查詢優(yōu)化器會(huì)使用tb_category作為驅(qū)動(dòng)表。
避免semi-join的關(guān)鍵是避免in子查詢,筆者將上述查詢語(yǔ)句拆分為兩個(gè)查詢語(yǔ)句,在應(yīng)用服務(wù)層首先執(zhí)行如下語(yǔ)句選出經(jīng)濟(jì),科技類型文章的編碼
SELECT code
FROM tb_category
WHERE code like '12%' or code like '13%'然后再將上述結(jié)果代入到原來(lái)查詢中,查詢語(yǔ)句修改如下
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
FROM
tb_article
LEFT JOIN tb_cmt ON tb_article.`id` = tb_cmt.`article_id`
INNER JOIN tb_user on tb_article.`userid` = tb_user.`id`
WHERE
tb_article.`type` IN (
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
AND tb_cmt.`upvote` > 100
AND tb_cmt.`len` BETWEEN 10 AND 30
AND tb_article.`create_time` BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
GROUP BY
tb_cmt.`article_id`優(yōu)化之后查詢耗時(shí)18s,性能有了非常大的提升,我們?cè)倏匆幌聝?yōu)化后的explain結(jié)果

我們看到,mysql以tb_article作為驅(qū)動(dòng)表,并且查詢不再涉及semi-join,達(dá)到了當(dāng)前步驟的優(yōu)化目的
步驟二:盡力使用索引
當(dāng)前的查詢語(yǔ)句以tb_article作為驅(qū)動(dòng)表,同時(shí)使用了tb_article上的type_time_idx索引過(guò)濾tb_article表,然后關(guān)聯(lián)tb_cmt表,這個(gè)關(guān)聯(lián)過(guò)程只會(huì)使用tb_cmt一個(gè)索引article_id,而tb_cmt存儲(chǔ)有1000萬(wàn)數(shù)據(jù),即使使用了article_id這個(gè)索引,最終會(huì)生成一個(gè)134萬(wàn)的結(jié)果集,在134萬(wàn)的結(jié)果集上進(jìn)行如下條件過(guò)濾和group by mysql的性能仍然會(huì)非常差。
tb_cmt.`upvote` > 100
tb_cmt.`len` BETWEEN 10 AND 30
GROUP BY
tb_cmt.`article_id`筆者希望tb_article僅僅和熱門評(píng)論進(jìn)行關(guān)聯(lián),掃描的數(shù)據(jù)就大大減少。利用這個(gè)思路筆者重新編寫sql語(yǔ)句如下
select
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
from tb_article
LEFT JOIN (
SELECT article_id FROM tb_cmt
WHERE tb_cmt.upvote > 100
AND tb_cmt.len BETWEEN 10 AND 30
) t
on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_article.userid = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
GROUP BY article_id為了使用tb_cmt上的upvote_len_idx索引,筆者延遲了tb_cmt關(guān)聯(lián),先對(duì)tb_cmt進(jìn)行了篩選。雖然這個(gè)查詢會(huì)生成一個(gè)臨時(shí)表t,但是臨時(shí)表t比較小,數(shù)據(jù)量不足10萬(wàn),所以這個(gè)臨時(shí)表也不會(huì)造成太大的性能負(fù)擔(dān)。但是tb_cmt的子查詢卻無(wú)法使用upvote_len_idx索引,我們還得對(duì)范圍查詢進(jìn)行優(yōu)化
步驟三:范圍查詢優(yōu)化
筆者讓tb_article和篩選過(guò)的評(píng)論表即熱評(píng)表t進(jìn)行關(guān)聯(lián),但是發(fā)現(xiàn)評(píng)論的子查詢表仍然不使用upvote_len_idx索引,原因是tb_cmt.upvote > 100是一個(gè)范圍查詢,而tb_cmt.len BETWEEN 10 AND 30也是一個(gè)范圍查詢,mysql不支持松散索引掃描,無(wú)法在同一個(gè)索引上使用兩個(gè)范圍查詢。優(yōu)化思路是將兩個(gè)范圍查詢優(yōu)化為一個(gè)范圍查詢,將tb_cmt.len BETWEEN 10 AND 30優(yōu)化為散列值,同時(shí)刪除原來(lái)的upvote_len_idx,創(chuàng)建len_upvote_idx索引,目的是將需要范圍掃描的upvote字段置為組合索引的尾部。
優(yōu)化之后代碼如下所示
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
from tb_article
LEFT JOIN (
SELECT article_id FROM tb_cmt
WHERE tb_cmt.upvote > 100
AND tb_cmt.len in (10 ,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29, 30 )
) t
on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_user.id = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
GROUP BY article_id在這一步優(yōu)化之后,筆者再次執(zhí)行查詢,發(fā)現(xiàn)性能變得更差了,原本18秒可以運(yùn)行結(jié)束的查詢,現(xiàn)在需要40s。原因是什么呢?因?yàn)閠表的生成過(guò)程完全走在索引上,所以t表的生成過(guò)程不是性能瓶頸所在,所以筆者猜測(cè)是引入的t表和tb_article表左關(guān)聯(lián)時(shí)候性能太差的原因,于是筆者注釋掉生成t表的子查詢以驗(yàn)證筆者的猜想,注釋后的代碼如下所示
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
from tb_article
-- LEFT JOIN (
-- SELECT article_id FROM tb_cmt
-- WHERE tb_cmt.upvote > 100
-- AND tb_cmt.len in (10 ,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29, 30 )
-- ) t
-- on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_user.id = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
GROUP BY tb_article.id上述查詢耗時(shí)5.26秒,驗(yàn)證了筆者的上述猜想,但是筆者也沒(méi)有太好的辦法解決這個(gè)問(wèn)題,筆者在嘗試group by優(yōu)化時(shí)意外找到了優(yōu)化方案
步驟四 group by優(yōu)化
仔細(xì)觀察這個(gè)sql語(yǔ)句,我們可以發(fā)現(xiàn)GROUP BY這個(gè)操作既可以放在臨時(shí)表t中,又可以放在關(guān)聯(lián)后的結(jié)果集上進(jìn)行,我們?nèi)绾芜x擇呢?group by無(wú)法使用索引,只能使用臨時(shí)表,所以我們應(yīng)該讓需要被group by的數(shù)據(jù)盡量的少,而tb_article和tb_cmt是左關(guān)聯(lián),所以應(yīng)該將group by操作放在tb_cmt子查詢內(nèi)部進(jìn)行。除此之外,group by 優(yōu)化還有一個(gè)小技巧,mysql在執(zhí)行g(shù)roup by的時(shí)候,默認(rèn)會(huì)進(jìn)行排序,在當(dāng)前業(yè)務(wù)中,筆者并不需要進(jìn)行排序,于是筆者在group by 末尾追加order by null ,最終優(yōu)化的sql結(jié)果為
SELECT
tb_article.`title`,
tb_user.`name`,
`total`
from tb_article
LEFT JOIN (
SELECT article_id ,count( 1 ) AS `total` FROM tb_cmt
WHERE tb_cmt.upvote > 100
AND tb_cmt.len in (10 ,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29, 30 )
GROUP BY article_id
ORDER BY null
) t
on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_user.id = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)整個(gè)查詢耗時(shí)1.3秒,和原查詢耗時(shí)60秒相比,已經(jīng)有了近60倍性能提升。我們?cè)倏匆幌翬xplain分析

可以看到在將group by放在子查詢內(nèi)部的時(shí)候,生成的臨時(shí)表t好像出現(xiàn)了一個(gè)索引


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??