數(shù)據(jù)湖 | 如何打造一款極速數(shù)據(jù)湖分析引擎
作者
阿里云 EMR 開源大數(shù)據(jù) OLAP 團(tuán)隊(duì)
StarRocks 社區(qū)數(shù)據(jù)湖分析團(tuán)隊(duì)
隨著數(shù)字產(chǎn)業(yè)化和產(chǎn)業(yè)數(shù)字化成為經(jīng)濟(jì)驅(qū)動(dòng)的重要?jiǎng)恿Γ髽I(yè)的數(shù)據(jù)分析場景越來越豐富,對數(shù)據(jù)分析架構(gòu)的要求也越來越高。新的數(shù)據(jù)分析場景催生了新的需求,主要包括三個(gè)方面:
用戶希望用更加低廉的成本,更加實(shí)時(shí)的方式導(dǎo)入并存儲(chǔ)任何數(shù)量的關(guān)系數(shù)據(jù)數(shù)據(jù)(例如,來自業(yè)務(wù)線應(yīng)用程序的運(yùn)營數(shù)據(jù)庫和數(shù)據(jù))和非關(guān)系數(shù)據(jù)(例如,來自移動(dòng)應(yīng)用程序、IoT 設(shè)備和社交媒體的運(yùn)營數(shù)據(jù)庫和數(shù)據(jù))
用戶希望自己的數(shù)據(jù)資產(chǎn)受到嚴(yán)密的保護(hù)
用戶希望數(shù)據(jù)分析的速度變得更快、更靈活、更實(shí)時(shí)
數(shù)據(jù)湖的出現(xiàn)很好的滿足了用戶的前兩個(gè)需求,它允許用戶導(dǎo)入任何數(shù)量的實(shí)時(shí)獲得的數(shù)據(jù)。用戶可以從多個(gè)來源收集數(shù)據(jù),并以其原始形式存儲(chǔ)到數(shù)據(jù)湖中。數(shù)據(jù)湖擁有極高的水平擴(kuò)展能力,使得用戶能夠存儲(chǔ)任何規(guī)模的數(shù)據(jù)。同時(shí)其底層通常使用廉價(jià)的存儲(chǔ)方案,使得用戶存儲(chǔ)數(shù)據(jù)的成本大大降低。數(shù)據(jù)湖通過敏感數(shù)據(jù)識別、分級分類、隱私保護(hù)、資源權(quán)限控制、數(shù)據(jù)加密傳輸、加密存儲(chǔ)、數(shù)據(jù)風(fēng)險(xiǎn)識別以及合規(guī)審計(jì)等措施,幫助用戶建立安全預(yù)警機(jī)制,增強(qiáng)整體安全防護(hù)能力,讓數(shù)據(jù)可用不可得和安全合規(guī)。
為了進(jìn)一步滿足用戶對于數(shù)據(jù)湖分析的要求,我們需要一套適用于數(shù)據(jù)湖的分析引擎,能夠在更短的時(shí)間內(nèi)從更多來源利用更多數(shù)據(jù),并使用戶能夠以不同方式協(xié)同處理和分析數(shù)據(jù),從而做出更好、更快的決策。本篇文章將向讀者詳細(xì)揭秘這樣一套數(shù)據(jù)湖分析引擎的關(guān)鍵技術(shù),并通過StarRocks 來幫助用戶進(jìn)一步理解系統(tǒng)的架構(gòu)。
之后我們會(huì)繼續(xù)發(fā)表兩篇文章,來更詳細(xì)地介紹極速數(shù)據(jù)湖分析引擎的內(nèi)核和使用案例:
代碼走讀篇:通過走讀 StarRocks 這個(gè)開源分析型數(shù)據(jù)庫內(nèi)核的關(guān)鍵數(shù)據(jù)結(jié)構(gòu)和算法,幫助讀者進(jìn)一步理解極速數(shù)據(jù)湖分析引擎的原理和具體實(shí)現(xiàn)。
Case Study 篇:介紹大型企業(yè)如何使用 StarRocks 在數(shù)據(jù)湖上實(shí)時(shí)且靈活的洞察數(shù)據(jù)的價(jià)值,從而幫助業(yè)務(wù)進(jìn)行更好的決策,幫助讀者進(jìn)一步理解理論是如何在實(shí)際場景落地的。
什么是數(shù)據(jù)湖,根據(jù) Wikipedia 的定義,“A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files”。通俗來說可以將數(shù)據(jù)湖理解為在廉價(jià)的對象存儲(chǔ)或分布式文件系統(tǒng)之上包了一層,使這些存儲(chǔ)系統(tǒng)中離散的 object 或者 file 結(jié)合在一起對外展現(xiàn)出一個(gè)統(tǒng)一的語義,例如關(guān)系型數(shù)據(jù)庫常見的“表”語義等。
了解完數(shù)據(jù)湖的定義之后,我們自然而然地想知道數(shù)據(jù)湖能為我們提供什么獨(dú)特的能力,我們?yōu)槭裁匆褂脭?shù)據(jù)湖?
在數(shù)據(jù)湖這個(gè)概念出來之前,已經(jīng)有很多企業(yè)或組織大量使用 HDFS 或者 S3 來存放業(yè)務(wù)日常運(yùn)作中產(chǎn)生的各式各樣的數(shù)據(jù)(例如一個(gè)制作 APP 的公司可能會(huì)希望將用戶所產(chǎn)生的點(diǎn)擊事件事無巨細(xì)的記錄)。因?yàn)檫@些數(shù)據(jù)的價(jià)值不一定能夠在短時(shí)間內(nèi)被發(fā)現(xiàn),所以找一個(gè)廉價(jià)的存儲(chǔ)系統(tǒng)將它們暫存,期待在將來的一天這些數(shù)據(jù)能派上用場的時(shí)候再從中將有價(jià)值的信息提取出來。然而 HDFS 和 S3 對外提供的語義畢竟比較單一(HDFS 對外提供文件的語義,S3對外提供對象的語義),隨著時(shí)間的推移工程師們可能都無法回答他們到底在這里面存儲(chǔ)了些什么數(shù)據(jù)。為了防止后續(xù)使用數(shù)據(jù)的時(shí)候必須將數(shù)據(jù)一一解析才能理解數(shù)據(jù)的含義,聰明的工程師想到將定義一致的數(shù)據(jù)組織在一起,然后再用額外的數(shù)據(jù)來描述這些數(shù)據(jù),這些額外的數(shù)據(jù)被稱之為“元”數(shù)據(jù),因?yàn)樗麄兪敲枋鰯?shù)據(jù)的數(shù)據(jù)。這樣后續(xù)通過解析元數(shù)據(jù)就能夠回答這些數(shù)據(jù)的具體含義。這就是數(shù)據(jù)湖最原始的作用。
隨著用戶對于數(shù)據(jù)質(zhì)量的要求越來越高,數(shù)據(jù)湖開始豐富其他能力。例如為用戶提供類似數(shù)據(jù)庫的 ACID 語義,幫助用戶在持續(xù)寫入數(shù)據(jù)的過程中能夠拿到 point-in-time 的視圖,防止讀取數(shù)據(jù)過程中出現(xiàn)各種錯(cuò)誤。或者是提供用戶更高性能的數(shù)據(jù)導(dǎo)入能力等,發(fā)展到現(xiàn)在,數(shù)據(jù)湖已經(jīng)從單純的元數(shù)據(jù)管理變成現(xiàn)在擁有更加豐富,更加類似數(shù)據(jù)庫的語義了。
用一句不太準(zhǔn)確的話描述數(shù)據(jù)湖,就是一個(gè)存儲(chǔ)成本更廉價(jià)的“AP 數(shù)據(jù)庫”。但是數(shù)據(jù)湖僅僅提供數(shù)據(jù)存儲(chǔ)和組織的能力,一個(gè)完整的數(shù)據(jù)庫不僅要有數(shù)據(jù)存儲(chǔ)的能力,還需要有數(shù)據(jù)分析能力。因此怎么為數(shù)據(jù)湖打造一款高效的分析引擎,為用戶提供洞察數(shù)據(jù)的能力,將是本文所要重點(diǎn)闡述的部分。下面通過如下幾個(gè)章節(jié)一起逐步拆解一款現(xiàn)代的 OLAP 分析引擎的內(nèi)部構(gòu)造和實(shí)現(xiàn):
怎么在數(shù)據(jù)湖上進(jìn)行極速分析
現(xiàn)代數(shù)據(jù)湖分析引擎的架構(gòu)
從這一節(jié)開始,讓我們開始回到數(shù)據(jù)庫課程,一個(gè)用于數(shù)據(jù)湖的分析引擎和一個(gè)用于數(shù)據(jù)庫的分析引擎在架構(gòu)上別無二致,通常我們認(rèn)為都會(huì)分為下面幾個(gè)部分:
Parser:將用戶輸入的查詢語句解析成一棵抽象語法樹
Analyzer:分析查詢語句的語法和語義是否正確,符合定義
Optimizer:為查詢生成性能更高、代價(jià)更低的物理查詢計(jì)劃
Execution Engine:執(zhí)行物理查詢計(jì)劃,收集并返回查詢結(jié)果
對于一個(gè)數(shù)據(jù)湖分析引擎而言,Optimizer 和 Execution Engine 是影響其性能兩個(gè)核心模塊,下面我們將從三個(gè)維度入手,逐一拆解這兩個(gè)模塊的核心技術(shù)原理,并通過不同技術(shù)方案的對比,幫助讀者理解一個(gè)現(xiàn)代的數(shù)據(jù)湖分析引擎的始末。
RBO vs CBO
基本上來講,優(yōu)化器的工作就是對給定的一個(gè)查詢,生成查詢代價(jià)最低(或者相對較低)的執(zhí)行計(jì)劃。不同的執(zhí)行計(jì)劃性能會(huì)有成千上萬倍的差距,查詢越復(fù)雜,數(shù)據(jù)量越大,查詢優(yōu)化越重要。
Rule Based Optimization (RBO) 是傳統(tǒng)分析引擎常用的優(yōu)化策略。RBO 的本質(zhì)是核心是基于關(guān)系代數(shù)的等價(jià)變換,通過一套預(yù)先制定好的規(guī)則來變換查詢,從而獲得代價(jià)更低的執(zhí)行計(jì)劃。常見的 RBO 規(guī)則謂詞下推、Limit 下推、常量折疊等。在 RBO 中,有著一套嚴(yán)格的使用規(guī)則,只要你按照規(guī)則去寫查詢語句,無論數(shù)據(jù)表中的內(nèi)容怎樣,生成的執(zhí)行計(jì)劃都是固定的。但是在實(shí)際的業(yè)務(wù)環(huán)境中,數(shù)據(jù)的量級會(huì)嚴(yán)重影響查詢的性能,而 RBO 是沒法通過這些信息來獲取更優(yōu)的執(zhí)行計(jì)劃。
為了解決 RBO 的局限性,Cost Based Optimization (CBO) 的優(yōu)化策略應(yīng)運(yùn)而生。CBO 通過收集數(shù)據(jù)的統(tǒng)計(jì)信息來估算執(zhí)行計(jì)劃的代價(jià),這些統(tǒng)計(jì)信息包括數(shù)據(jù)集的大小,列的數(shù)量和列的基數(shù)等信息。舉個(gè)例子,假設(shè)我們現(xiàn)在有三張表 A,B 和 C,在進(jìn)行 A join B join C 的查詢時(shí)如果沒有對應(yīng)的統(tǒng)計(jì)信息我們是無法判斷不同 join 的執(zhí)行順序代價(jià)上的差異。如果我們收集到這三張表的統(tǒng)計(jì)信息,發(fā)現(xiàn) A 表和 B 表的數(shù)據(jù)量都是 1M 行,但是 C 表的 數(shù)據(jù)量僅為 10 行,那么通過先執(zhí)行 B join C 可以大大減少中間結(jié)果的數(shù)據(jù)量,這在沒有統(tǒng)計(jì)信息的情況下基本不可能判斷。
隨著查詢復(fù)雜度的增加,執(zhí)行計(jì)劃的狀態(tài)空間會(huì)變的非常巨大。刷過算法題的小伙伴都知道,一旦狀態(tài)空間非常大,通過暴力搜索的方式是不可能 AC 的,這時(shí)候一個(gè)好的搜索算法格外重要。通常 CBO 使用動(dòng)態(tài)規(guī)劃算法來得到最優(yōu)解,并且減少重復(fù)計(jì)算子空間的代價(jià)。當(dāng)狀態(tài)空間達(dá)到一定程度之后,我們只能選擇貪心算法或者其他一些啟發(fā)式算法來得到局部最優(yōu)。本質(zhì)上搜索算法是一種在搜索時(shí)間和結(jié)果質(zhì)量做 trade-off 的方法。
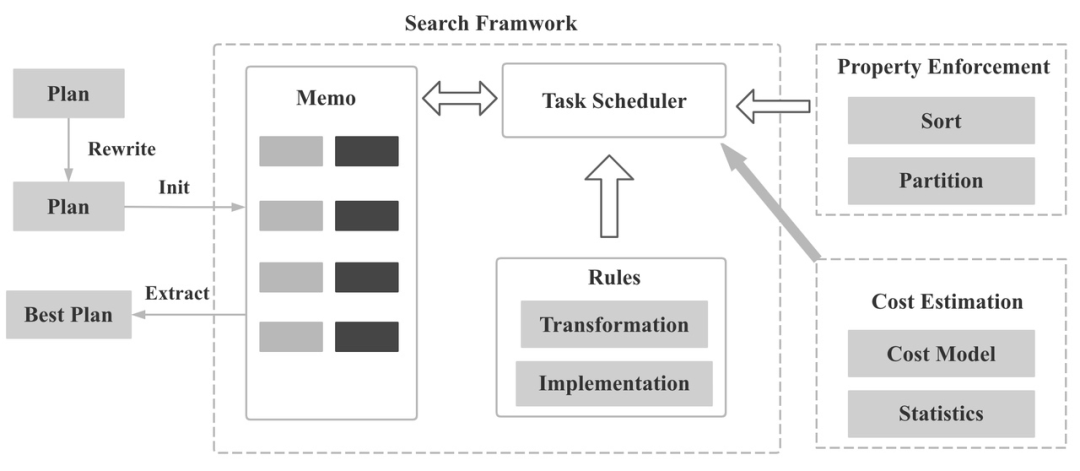
(常見 CBO 實(shí)現(xiàn)架構(gòu))
Record Oriented vs Block Oriented
執(zhí)行計(jì)劃可以認(rèn)為是一串 operator(關(guān)系代數(shù)的運(yùn)算符)首尾相連串起來的執(zhí)行流,前一個(gè) operator 的 output 是下一個(gè) operator 的 input。傳統(tǒng)的分析引擎是 Row Oriented 的,也就是說 operator 的 output 和 input 是一行一行的數(shù)據(jù)。
舉一個(gè)簡單的例子,假設(shè)我們有下面一個(gè)表和查詢:
CREATE TABLE t (n int, m int, o int, p int);SELECT o FROM t WHERE m < n + 1;
例子來源:GitHub - jordanlewis/exectoy
上述查詢語句展開為執(zhí)行計(jì)劃的時(shí)候大致如下圖所示:
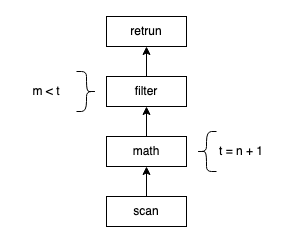
通常情況下,在 Row Oriented 的模型中,執(zhí)行計(jì)劃的執(zhí)行過程可以用如下偽碼表示:
next:for:row = source.next()if filterExpr.Eval(row):// return a new row containing just column oreturnedRow rowfor col in selectedCols:returnedRow.append(row[col])return returnedRow
根據(jù) DBMSs On A Modern Processor: Where Does Time Go? 的評估,這種執(zhí)行方式存在大量的 L2 data stalls 和 L1 I-cache stalls、分支預(yù)測的效率低等問題。
隨著磁盤等硬件技術(shù)的蓬勃發(fā)展,各種通過 CPU 換 IO 的壓縮算法、Encoding 算法和存儲(chǔ)技術(shù)的廣泛使用,CPU 的性能逐漸成為成為分析引擎的瓶頸。為了解決 Row Oriented 執(zhí)行所存在的問題,學(xué)術(shù)界開始思考解決方案,Block oriented processing of Relational Database operations in modern Computer Architectures 這篇論文提出使用按 block 的方式在 operator 之間傳遞數(shù)據(jù),能夠平攤條件檢查和分支預(yù)測的工作的耗時(shí),MonetDB/X100: Hyper-Pipelining Query Execution 在此基礎(chǔ)上更進(jìn)一步,提出將通過將數(shù)據(jù)從原來的 Row Oriented,改變成 Column Oriented,進(jìn)一步提升 CPU Cache 的效率,也更有利于編譯器進(jìn)行優(yōu)化。在 Column Oriented 的模型中,執(zhí)行計(jì)劃的執(zhí)行過程可以用如下偽碼表示:
// first create an n + 1 result, for all values in the n columnprojPlusIntIntConst.Next():batch = source.Next()for i < batch.n:outCol[i] = intCol[i] + constArgreturn batch// then, compare the new column to the m column, putting the result into// a selection vector: a list of the selected indexes in the column batchselectLTIntInt.Next():batch = source.Next()for i < batch.n:if int1Col < int2Col:selectionVector.append(i)return batch with selectionVector// finally, we materialize the batch, returning actual rows to the user,// containing just the columns requested:materialize.Next():batch = source.Next()for s < batch.n:i = selectionVector[i]returnedRow rowfor col in selectedCols:returnedRow.append(cols[col][i])yield returnedRow
可以看到,Column Oriented 擁有更好的數(shù)據(jù)局部性和指令局部性,有利于提高 CPU Cache 的命中率,并且編譯器更容易執(zhí)行 SIMD 優(yōu)化等。
Pull Based vs Push Based
數(shù)據(jù)庫系統(tǒng)中,通常是將輸入的 SQL 語句轉(zhuǎn)化為一系列的算子,然后生成物理執(zhí)行計(jì)劃用于實(shí)際的計(jì)算并返回結(jié)果。在生成的物理執(zhí)行計(jì)劃中,通常會(huì)對算子進(jìn)行 pipeline。常見的 pipeline 方式通常有兩種:
基于數(shù)據(jù)驅(qū)動(dòng)的 Push Based 模式,上游算子推送數(shù)據(jù)到下游算子
基于需求的 Pull Based 模式,下游算子主動(dòng)從上游算子拉取數(shù)據(jù)。經(jīng)典的火山模型就是 Pull Based 模式。
Push Based 的執(zhí)行模式提高了緩存效率,能夠更好地提升查詢性能。
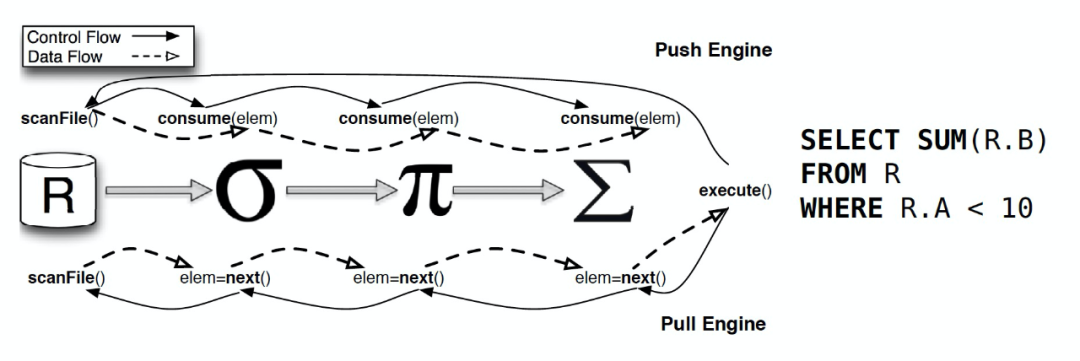
參考:Push vs. Pull-Based Loop Fusion in Query Engines
通過上一節(jié)的介紹,相信讀者已經(jīng)對數(shù)據(jù)湖分析引擎的前沿理論有了相應(yīng)了解。在本節(jié)中,我們以 StarRocks 為例,進(jìn)一步介紹數(shù)據(jù)湖分析引擎是怎么有機(jī)的結(jié)合上述先進(jìn)理論,并且通過優(yōu)雅的系統(tǒng)架構(gòu)將其呈現(xiàn)給用戶。
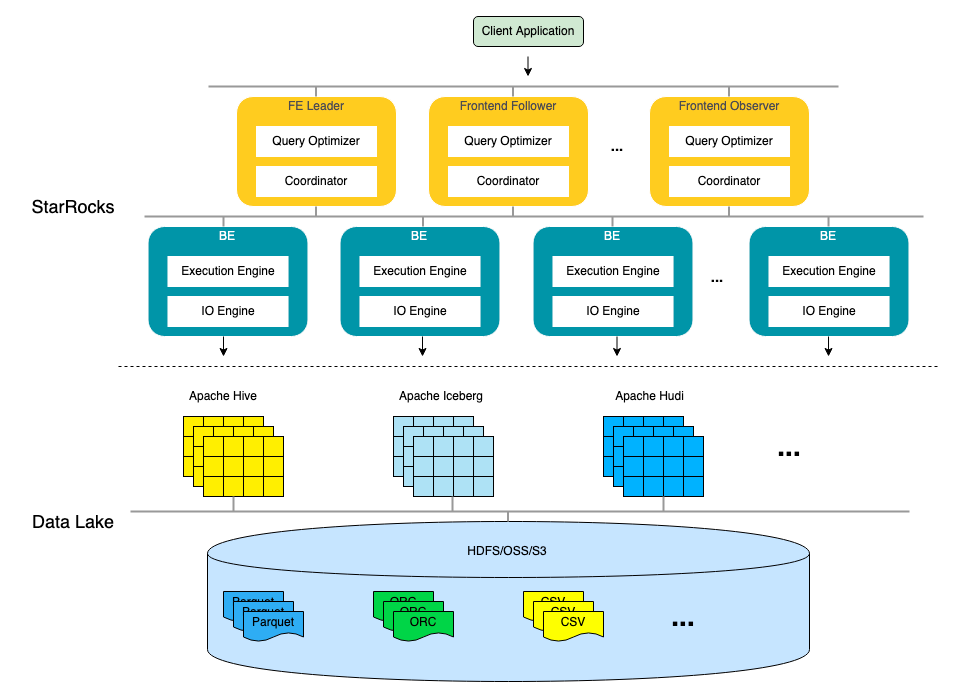
如上圖所示,StarRocks 的架構(gòu)非常簡潔,整個(gè)系統(tǒng)的核心只有 Frontend (FE)、Backend (BE) 兩類進(jìn)程,不依賴任何外部組件,方便部署與維護(hù)。其中 FE 主要負(fù)責(zé)解析查詢語句(SQL),優(yōu)化查詢以及查詢的調(diào)度,而 BE 則主要負(fù)責(zé)從數(shù)據(jù)湖中讀取數(shù)據(jù),并完成一系列的 Filter 和 Aggregate 等操作。
Frontend
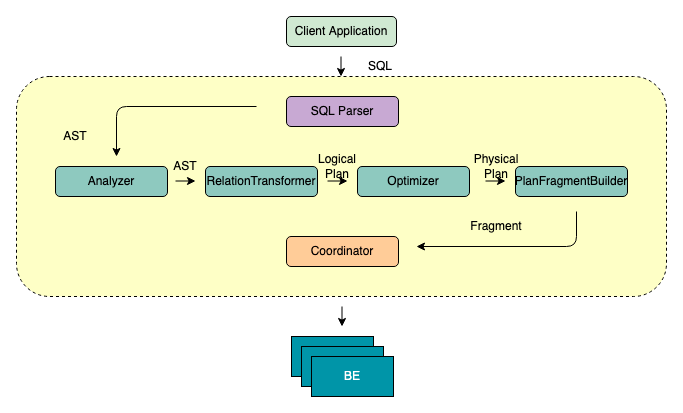
FE 的主要作用將 SQL 語句通過一系列轉(zhuǎn)化和優(yōu)化,最終轉(zhuǎn)換成 BE 能夠認(rèn)識的一個(gè)個(gè) Fragment。一個(gè)不那么準(zhǔn)確但易于理解的比喻,如果把 BE 集群當(dāng)成一個(gè)分布式的線程池的話,那么 Fragment 就是線程池中的 Task。從 SQL 文本到 Fragment,F(xiàn)E 的主要工作包含以下幾個(gè)步驟:
SQL Parse:將 SQL 文本轉(zhuǎn)換成一個(gè) AST(抽象語法樹)
Analyze:基于 AST 進(jìn)行語法和語義分析
Logical Plan:將 AST 轉(zhuǎn)換成邏輯計(jì)劃
Optimize:基于關(guān)系代數(shù),統(tǒng)計(jì)信息,Cost 模型對邏輯計(jì)劃進(jìn)行重寫,轉(zhuǎn)換,選擇出 Cost “最低” 的物理執(zhí)行計(jì)劃
生成 Fragment:將 Optimizer 選擇的物理執(zhí)行計(jì)劃轉(zhuǎn)換為 BE 可以直接執(zhí)行的 Fragment
Coordinate:將 Fragment 調(diào)度到合適的 BE 上執(zhí)行
Backend
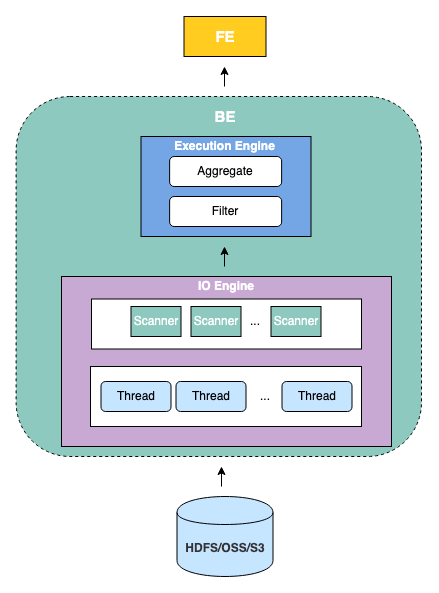
BE 是 StarRocks 的后端節(jié)點(diǎn),負(fù)責(zé)接收 FE 傳下來的 Fragment 執(zhí)行并返回結(jié)果給 FE。StarRocks 的 BE 節(jié)點(diǎn)都是完全對等的,F(xiàn)E 按照一定策略將數(shù)據(jù)分配到對應(yīng)的 BE 節(jié)點(diǎn)。常見的 Fragment 工作流程是讀取數(shù)據(jù)湖中的部分文件,并調(diào)用對應(yīng)的 Reader (例如,適配 Parquet 文件的 Parquet Reader 和適配 ORC 文件的 ORC Reader等)解析這些文件中的數(shù)據(jù),使用向量化執(zhí)行引擎進(jìn)一步過濾和聚合解析后的數(shù)據(jù)后,返回給其他 BE 或 FE。
本篇文章主要介紹了極速數(shù)據(jù)湖分析引擎的核心技術(shù)原理,從多個(gè)維度對比了不同技術(shù)實(shí)現(xiàn)方案。為方便接下來的深入探討,進(jìn)一步介紹了開源數(shù)據(jù)湖分析引擎 StarRocks 的系統(tǒng)架構(gòu)設(shè)計(jì)。希望和各位同仁共同探討、交流。
附錄
基準(zhǔn)測試
本次測試采用的 TPCH 100G 的標(biāo)準(zhǔn)測試集,分別對比測試了 StarRocks 本地表,StarRocks On Hive 和 Trino(PrestoSQL) On Hive 三者之間的性能差距。
在 TPCH 100G規(guī)模的數(shù)據(jù)集上進(jìn)行對比測試,共22個(gè)查詢,結(jié)果如下:
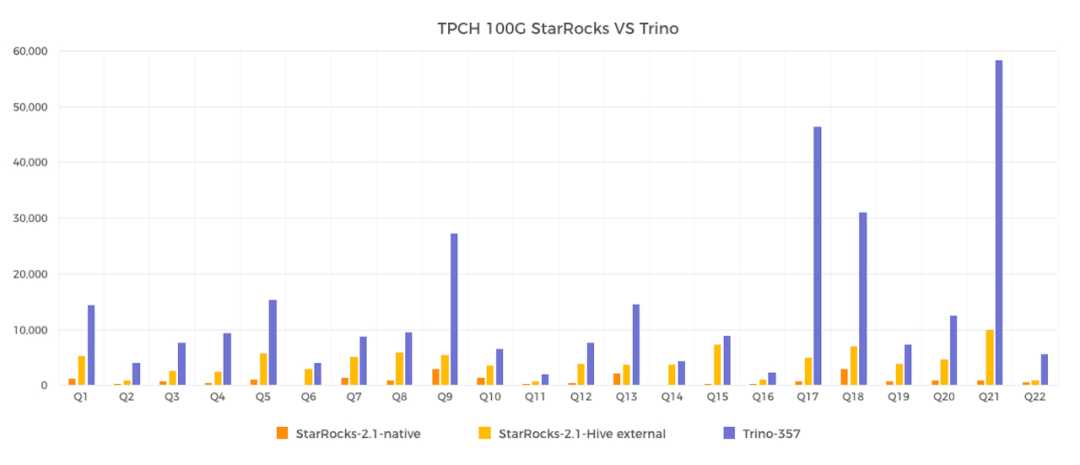
StarRocks 使用本地存儲(chǔ)查詢和 Hive 外表查詢兩種方式進(jìn)行測試。其中,StarRocks On Hive 和 Trino On Hive 查詢的是同一份數(shù)據(jù),數(shù)據(jù)采用 ORC 格式存儲(chǔ),采用 zlib 格式壓縮。測試環(huán)境使用 阿里云 EMR 進(jìn)行構(gòu)建。
最終,StarRocks 本地存儲(chǔ)查詢總耗時(shí)為21s,StarRocks Hive 外表查詢總耗時(shí)92s。Trino 查詢總耗時(shí)307s。可以看到 StarRocks On Hive 在查詢性能方面遠(yuǎn)遠(yuǎn)超過 Trino,但是對比本地存儲(chǔ)查詢還有不小的距離,主要的原因是訪問遠(yuǎn)端存儲(chǔ)增加了網(wǎng)絡(luò)開銷,以及遠(yuǎn)端存儲(chǔ)的延時(shí)和 IOPS 通常都不如本地存儲(chǔ),后面的計(jì)劃是通過 Cache 等機(jī)制彌補(bǔ)問題,進(jìn)一步縮短 StarRocks 本地表和 StarRocks On Hive 的差距。
參考資料
[1] GitHub - jordanlewis/exectoy
[2] DBMSs On A Modern Processor: Where Does Time Go?
[3] Block oriented processing of Relational Database operations in modern Computer Architectures
[4] MonetDB/X100: Hyper-Pipelining Query Execution
[5] 阿里云 EMR StarRocks 官方文檔
https://help.aliyun.com/document_detail/404790.html
招聘
阿里云智能計(jì)算平臺事業(yè)部-開源大數(shù)據(jù)-OLAP 團(tuán)隊(duì)招聘實(shí)習(xí)生,重點(diǎn)參與 StarRocks、ClickHouse 等開源項(xiàng)目,和社區(qū)深度合作。有機(jī)會(huì)參與核心特性開發(fā),觸達(dá)海量客戶場景。歡迎感興趣的同學(xué)們通過如下二維碼投遞:
我們會(huì)在釘群推送精彩文章,邀請技術(shù)大牛直播分享。
歡迎釘釘掃碼加入交流群一起參與討論~