
GAN的入門與實(shí)踐
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

引言
生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Nets,GAN)是由open ai研究員Good fellow在2014年提出的一種生成式模型,自從提出后在深度學(xué)習(xí)領(lǐng)域收到了廣泛的關(guān)注和研究。目前,深度學(xué)習(xí)領(lǐng)域的圖像生成,風(fēng)格遷移,圖像變換,圖像描述,無(wú)監(jiān)督學(xué)習(xí),甚至強(qiáng)化學(xué)習(xí)領(lǐng)域都能看到GAN 的身影。GAN主要針對(duì)的是一種生成類問(wèn)題。目前深度學(xué)習(xí)領(lǐng)域可以分為兩大類,其中一個(gè)是檢測(cè)識(shí)別,比如圖像分類,目標(biāo)識(shí)別等等,此類模型主要是VGG, GoogLenet,residual net等等,目前幾乎所有的網(wǎng)絡(luò)都是基于識(shí)別的;另一種是圖像生成,即解決如何從一些數(shù)據(jù)里生成出圖像的問(wèn)題,生成類模型主要有深度信念網(wǎng)(DBN),變分自編碼器(VAE)。而某種程度上,在生成能力上,GAN遠(yuǎn)遠(yuǎn)超過(guò)DBN、VAE。經(jīng)過(guò)改進(jìn)后的GAN足以生成以假亂真的圖像。本文將首先介紹一些GAN 的原理和公式推導(dǎo),另外會(huì)詳細(xì)給出GAN生成圖像的Tensorflow的實(shí)現(xiàn),基于python語(yǔ)言。
GAN主要解決的是生成類問(wèn)題,即如何從一段任意的隨機(jī)數(shù)中生成圖像。假設(shè)給定一段100維的向量X{x1, x2,…, x100 }作為網(wǎng)絡(luò)的輸入,其中x是產(chǎn)生的隨機(jī)數(shù),一般按照高斯分布或者均勻分布產(chǎn)生,GAN通過(guò)對(duì)抗訓(xùn)練的方式,可以生成清晰的圖像,這個(gè)過(guò)程是通過(guò)GAN不斷模擬訓(xùn)練集中圖像的像素分布來(lái)實(shí)現(xiàn)的。看完下文GAN的原理后或許你會(huì)對(duì)這個(gè)過(guò)程有一個(gè)清晰的認(rèn)識(shí)。
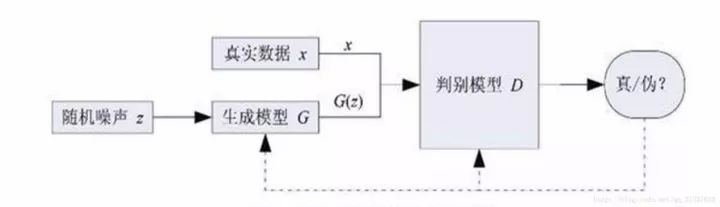
圖1?
首先,附上一張GAN的網(wǎng)絡(luò)流程圖,如圖1所示。不同于以往的判別網(wǎng)絡(luò)模型,GAN包括兩個(gè)網(wǎng)絡(luò)模型,一個(gè)生成模型G(generator)和一個(gè)判別模型D(discriminator),其中D就是識(shí)別檢測(cè)類模型中經(jīng)常使用的網(wǎng)絡(luò)。GAN的大概流程是,G以隨機(jī)噪聲作為輸入,生成出一張圖像G(z),暫且不管生成質(zhì)量多好,然后D以G(z)和真實(shí)圖像x作為輸入,對(duì)G(z)和x做一個(gè)二分類,檢測(cè)誰(shuí)是真實(shí)圖像誰(shuí)是生成的假圖像。D的輸出是一個(gè)概率值,比如G(z)作為輸入時(shí)D輸出0.15,那么代表D認(rèn)為G(z)有15%的概率是真圖像。然后G和D會(huì)根據(jù)D輸出的情況不斷改進(jìn)自己,G提高G(z)和x的相似度,盡可能的欺騙D,而D則會(huì)通過(guò)學(xué)習(xí)盡可能的不被G欺騙。二者相當(dāng)于是做一個(gè)極大極小的博弈過(guò)程,稱為零和博弈。可以用一個(gè)簡(jiǎn)單的例子描述他們之間的過(guò)程,我們把G想象成制造假幣的團(tuán)伙,視D為警察,G不斷產(chǎn)生假幣,而D任務(wù)就是從真錢幣中分辨出G的假幣,剛開始時(shí),G沒(méi)有經(jīng)驗(yàn),制造的假幣太假,D很容易就能分辨出來(lái),所以G不斷改進(jìn)自己的技術(shù),產(chǎn)生的假幣越來(lái)越真實(shí),D可能就沒(méi)有那么容易判別出真假了,所以D也根據(jù)自己的情況不斷改進(jìn)自己,經(jīng)過(guò)很多次這樣的循環(huán)之后,G產(chǎn)生的假幣足以以假亂真了,D很難分出真假。對(duì)應(yīng)到圖像生成上,此時(shí)G足以生成出一般的分類神經(jīng)網(wǎng)絡(luò)分辨不出真假的圖像了,G從而獲得了生成圖像的能力。
與傳統(tǒng)神經(jīng)網(wǎng)絡(luò)訓(xùn)練不一樣的且有趣的地方,就是訓(xùn)練生成器的方法不同,生成器參數(shù)的更新來(lái)自于D的反傳梯度。生成器一心想要“騙過(guò)”判別器。使用博弈理論分析技術(shù),可以證明這里面存在一種納什均衡。
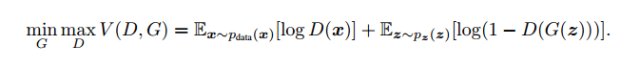
這里就是他們的損失函數(shù)定義,實(shí)際上是一個(gè)交叉熵,判別器的目的是盡可能的令D(x)接近1,令D(G(z))接近0,所以D主要是最大化上面的損失函數(shù),G恰恰相反,他主要是最小化上述損失函數(shù)。
訓(xùn)練過(guò)程:

(圖2)
圖2展示了GAN訓(xùn)練的偽代碼,首先在迭代次數(shù)范圍內(nèi),首先對(duì)z和x采樣一個(gè)批次,獲得他們的數(shù)據(jù)分布,然后通過(guò)隨機(jī)梯度下降的方法先對(duì)D做k次更新,之后對(duì)G做一次更新,這樣做的主要目的是保證D一直有足夠的能力去分辨真假。實(shí)際在代碼中我們可能會(huì)多更新幾次G只更新一次D,不然D學(xué)習(xí)的太好,會(huì)導(dǎo)致訓(xùn)練前期發(fā)生梯度消失的問(wèn)題。
在求平衡點(diǎn)之前,我們先做一個(gè)數(shù)學(xué)假設(shè),即G固定情況下D的最優(yōu)形式,然后根據(jù)D的最優(yōu)形式再去觀察G最小化損失函數(shù)的問(wèn)題。
假設(shè)在G固定的條件下,并將損失函數(shù)化為如下簡(jiǎn)單形式:
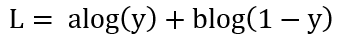
D的目標(biāo)就是最大化L,我們可以通過(guò)對(duì)L求導(dǎo),并令導(dǎo)數(shù)為0,計(jì)算出L取最大值時(shí)y的取值如下:
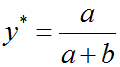
所以,換為原來(lái)的式子D的最優(yōu)解形式為:
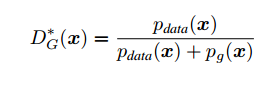
到這里我們得出了結(jié)論,當(dāng)G固定時(shí),D的最優(yōu)形式是上面形式。
接下來(lái)我們求一下D最優(yōu)時(shí),G最小化損失函數(shù)到什么形式才能達(dá)到二者相互博弈的平衡點(diǎn)。
帶入到損失函數(shù)里面后,損失函數(shù)可以寫為如下形式:
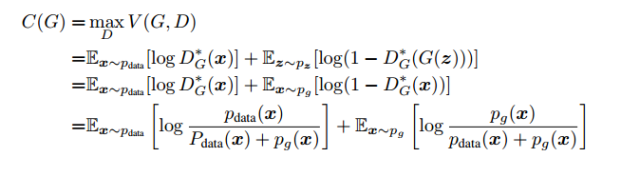
這時(shí)觀察到,上面式子仍然是一個(gè)交叉熵也稱KL散度的形式,KL散度通常用來(lái)衡量分布之間的距離,它是非對(duì)稱的。同樣還有另一個(gè)衡量數(shù)據(jù)分布距離的散度--JS散度,他們之間有如下關(guān)系。
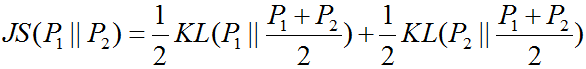
不過(guò)JS散度有一個(gè)很重要的性質(zhì)就是總是大于等于0的,當(dāng)且僅當(dāng) P1=P2上面的式子取得最小值0,
所以我們可以將C(G)寫成JS散度的形式:
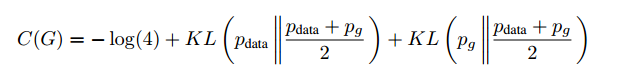
也即是當(dāng)且僅當(dāng)Pg=Pdata時(shí),C(G)取得最小值-log(4),也即是D最優(yōu)時(shí),G能將損失函數(shù)最小化到-log(4),最小點(diǎn)處Pg=Pdata。即真實(shí)數(shù)據(jù)的分布和生成數(shù)據(jù)的分布相等。
分析到這里,直觀上也很好理解了,Pg=Pdata意味著此時(shí)D恰好等于0.5,就是D有一半的概率認(rèn)為D(G(z))是真的數(shù)據(jù),有一半概率認(rèn)為是假的數(shù)據(jù),這不就和猜硬幣正反面一樣嘛。也說(shuō)明了此時(shí)G生成的數(shù)據(jù)足以以假亂真。
到這里,GAN的原理和數(shù)學(xué)推導(dǎo)就介紹完了,理論上說(shuō)明了GAN只要循規(guī)蹈矩的訓(xùn)練,G就可以完美的模擬數(shù)據(jù)分布并生成真實(shí)的圖像,但是我們做數(shù)學(xué)推導(dǎo)的時(shí)候?yàn)榱俗C明方便做了一些假設(shè),實(shí)際上并不是這樣,GAN存在訓(xùn)練困難、梯度消失、模式崩潰的問(wèn)題,這些問(wèn)題在這里不做重點(diǎn)介紹。
首先,建立一個(gè)train.py文件,在文件里建立一個(gè)名為Train的類,在類的初始化函數(shù)里進(jìn)行一些初始化:
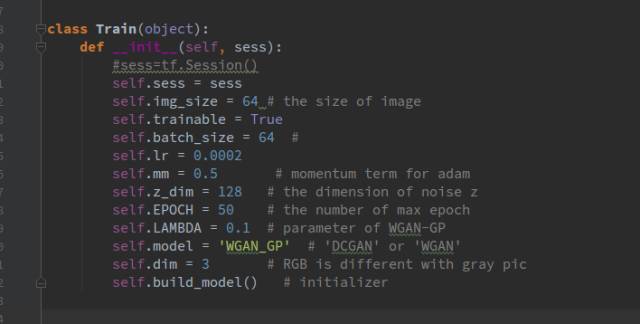
Self.build_model()函數(shù)用來(lái)存放構(gòu)建流圖部分的代碼,下面會(huì)介紹,其他初始化的都是一些簡(jiǎn)單的參數(shù)。
下面先介紹生成器和判別器的網(wǎng)絡(luò):
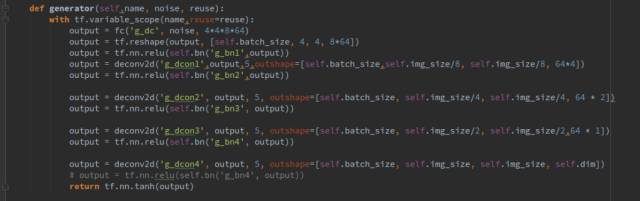
生成器傳進(jìn)去三個(gè)參數(shù),分別是名字,輸入數(shù)據(jù),和一個(gè)bool型狀態(tài)變量reuse,用來(lái)表示生成器是否復(fù)用,reuse=True代表網(wǎng)絡(luò)復(fù)用,F(xiàn)alse代表不復(fù)用。
生成器一共包括1個(gè)全連接層和4個(gè)轉(zhuǎn)置卷積層,每一層后面都跟一個(gè)batchnorm層,激活函數(shù)都選擇relu。其中fc(),deconv2d()函數(shù)和bn()函數(shù)都是我們封裝好的函數(shù),代表全鏈接層,轉(zhuǎn)制卷積層,和歸一化層,其形式如下:
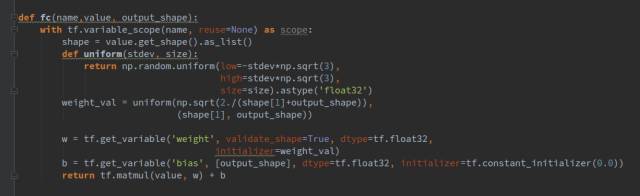
全連接層fc的輸入?yún)?shù)value指輸入向量,output_shape指經(jīng)過(guò)全連接層后輸出的向量維度,比如我們生成器這里噪聲向量維度是128,我們輸出的是4*4*8*64維。
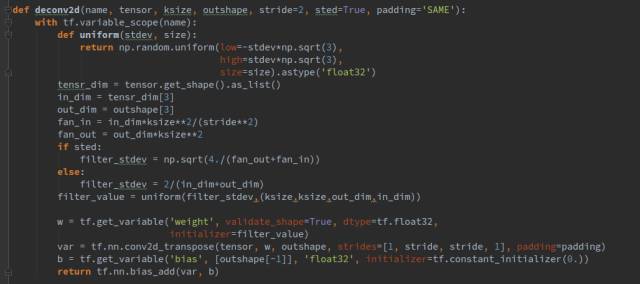
其中Ksize指卷積核的大小,outshape指輸出的張量的shape,sted是一個(gè)bool類型的參數(shù),表示用不同的方式初始化參數(shù)
bn()函數(shù)我是直接放在了train的類里面,其形式如下:
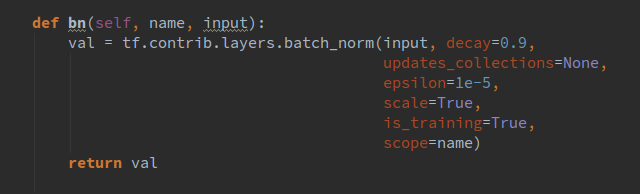
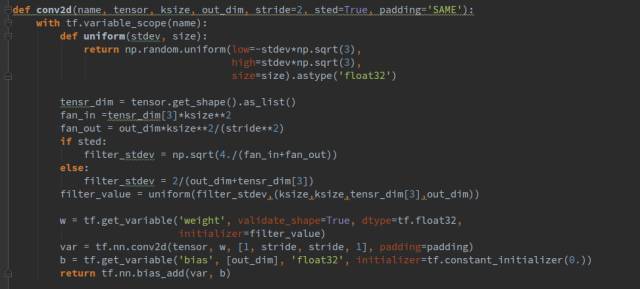
我們都希望權(quán)重都能初始化到一個(gè)比較好的數(shù),所以這里我沒(méi)有直接用固定方差的高斯分布去初始化權(quán)重,而是根據(jù)每一層的輸入輸出通道數(shù)量的不同計(jì)算出一個(gè)合適的方差去做初始化。同理,我們還封裝了卷積操作,其形式如下:
好了,目前已經(jīng)介紹了生成器的結(jié)構(gòu)和一些基本函數(shù),下面來(lái)介紹一下判別網(wǎng)絡(luò),其代碼如下所示:
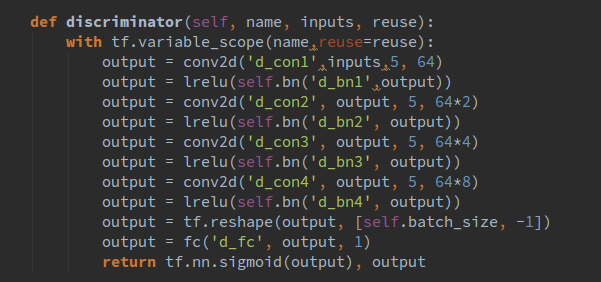
與生成器不同的是,我們使用leakrelu作為激活函數(shù),
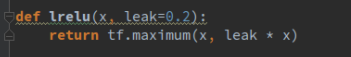
這些函數(shù)的定義都是放在了layer.py文件里,
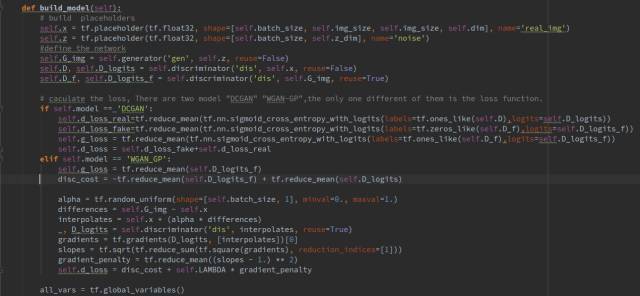
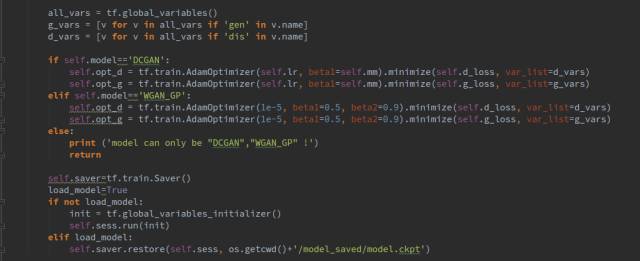
這里有兩個(gè)GAN可供選擇,DCGAN 和WGAN-GP,他們唯一不同的地方是損失函數(shù)的計(jì)算不同,網(wǎng)絡(luò)結(jié)構(gòu)都是一樣的,二者都是GAN的改進(jìn)版,WGAN-GP效果好更好一些,這里我們使用WGAN-GP。DCGAN訓(xùn)練的時(shí)候容易遇到訓(xùn)練不穩(wěn)定的問(wèn)題。
?
到這里我們已經(jīng)介紹完了所有的初始化過(guò)程,接下來(lái)就是訓(xùn)練數(shù)據(jù)的提取和網(wǎng)絡(luò)的訓(xùn)練部分了,訓(xùn)練數(shù)據(jù)我們使用cele名人數(shù)據(jù)集,一共20萬(wàn)張圖像左右,數(shù)據(jù)集里的圖像size并不是很一致,我們可以使用一小段代碼把圖像的人臉截取下來(lái),并resize到64*64大小。
代碼如下:
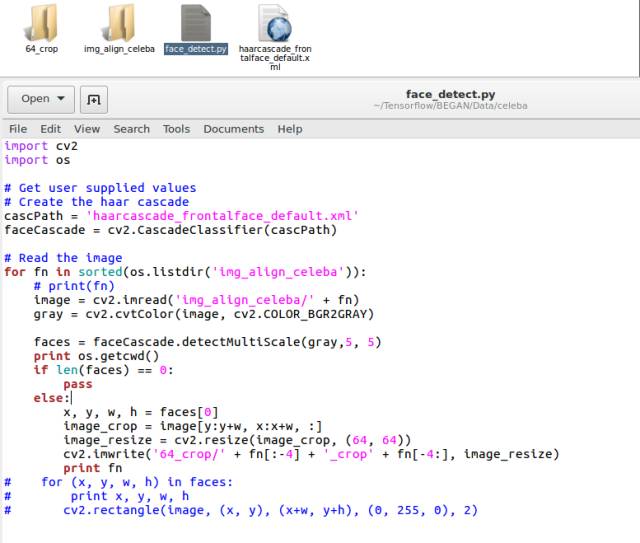
把數(shù)據(jù)集下載下來(lái)后解壓到img_align_celeba文件夾里面,然后運(yùn)行face_detec.py就可以了,截取下來(lái)的圖像會(huì)放到64_crop文件夾里,本來(lái)有20萬(wàn)張圖像的,截取過(guò)后就剩15萬(wàn)張了。
?
下面就是訓(xùn)練部分了,首先是讀取數(shù)據(jù),load_data()函數(shù)每次會(huì)讀取一個(gè)batch_size的數(shù)據(jù)作為網(wǎng)絡(luò)的輸入,在訓(xùn)練過(guò)程中,我們選擇訓(xùn)練一次D訓(xùn)練兩次G,而不是訓(xùn)練多次D之后訓(xùn)練一次G,不然容易發(fā)生訓(xùn)練不穩(wěn)定的問(wèn)題,因?yàn)镈總是學(xué)的太好,很容易就判別出真假,所以導(dǎo)致G不論怎么改進(jìn)都沒(méi)有用,有些太打擊G的造假積極性了。
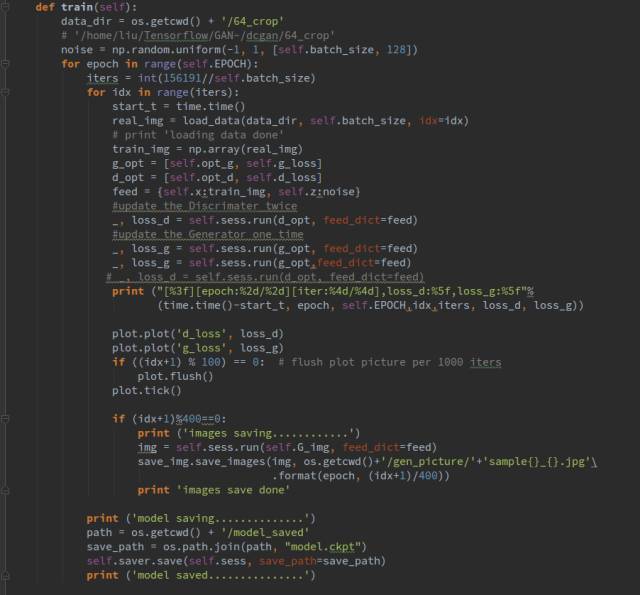
Plot()函數(shù)會(huì)每訓(xùn)練100步后繪出網(wǎng)絡(luò)loss的變化圖像,是另外封裝的函數(shù)
同時(shí)我們選擇每訓(xùn)練400步生成一張圖像,看一下生成器的效果。
load_data()函數(shù)我們并沒(méi)有使用隊(duì)列或者轉(zhuǎn)化為record文件讀取,這樣的方式肯定會(huì)快一些,讀取圖像我們使用scipy.misc 來(lái)讀取,
具體是import scipy.misc as scm
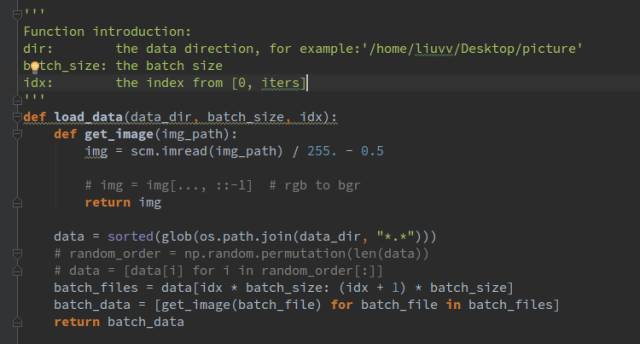
可以看到,我們首先對(duì)所有的圖像做一個(gè)排序,返回一個(gè)列表,列表里存放的是每個(gè)圖像的位置索引,這樣做就是每次將一個(gè)batch_size的數(shù)據(jù)讀到了內(nèi)存里,讀取的數(shù)據(jù)做了一個(gè)歸一化操作,我們選擇歸一化到[-0.5,+0.5]。
?
接下來(lái)就是展示結(jié)果的時(shí)候了,其中訓(xùn)練過(guò)程loss的變化如下所示:
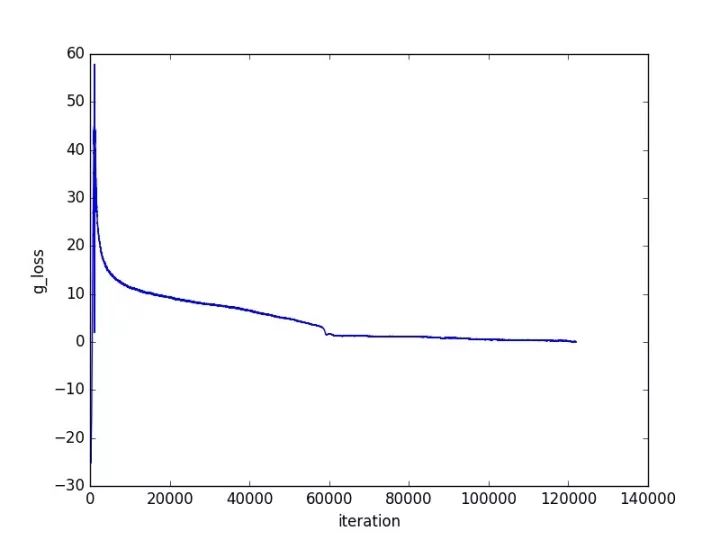
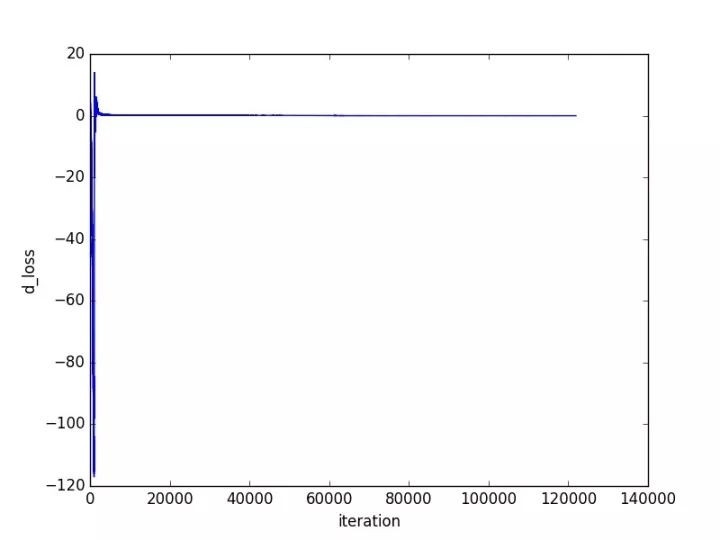
由圖可見,經(jīng)過(guò)一次比較大的震蕩之后,網(wǎng)絡(luò)就收斂的比較好了。
接下來(lái)是展示生成結(jié)果了:
我測(cè)試的時(shí)候設(shè)置了bach_size是16:
訓(xùn)練1epoch的時(shí)候是這樣子的:

訓(xùn)練一段時(shí)間后:

再往后訓(xùn)練效果看上去反而差了一些,而且明顯沒(méi)有學(xué)習(xí)到眼鏡的特征(最后一行第二個(gè))估計(jì)是數(shù)據(jù)集里眼鏡比較少,GAN學(xué)習(xí)不到足夠的特征,眼睛鼻子嘴巴學(xué)習(xí)的還是很好的。

訓(xùn)練失敗的結(jié)果:

下面談一談我訓(xùn)練GAN的感受,GAN是在是太難訓(xùn)練了,即使是使用WGAN,WGAN-GP,還是遇到了訓(xùn)練困難的問(wèn)題,以上這些結(jié)果都是我做了好幾次實(shí)驗(yàn)得出來(lái)的結(jié)果,有些實(shí)驗(yàn)中間得到的生成結(jié)果其實(shí)是慘不忍睹的,就像是下面這樣,我總結(jié)了一部分原因,一個(gè)原因是網(wǎng)絡(luò)結(jié)構(gòu)太簡(jiǎn)單,我本次使用的網(wǎng)絡(luò)是幾年前流行的DCGAN的網(wǎng)絡(luò)結(jié)構(gòu),有很大的改進(jìn)空間,現(xiàn)在基本上用的不多了,我也試了BEGAN,不得不說(shuō)BEGAN是真好訓(xùn)練,只要寫好代碼就讓他自己跑去吧,基本上不會(huì)出問(wèn)題,而且效果還很好;另一個(gè)原因是優(yōu)化器的選擇和學(xué)習(xí)率等超參數(shù)的設(shè)置。設(shè)置好的超參數(shù)對(duì)GAN的訓(xùn)練是很有幫助的,至于優(yōu)化器,盡量不要選擇SGD,因?yàn)镚AN的平衡點(diǎn)是一個(gè)鞍點(diǎn),鞍點(diǎn)附近梯度幾乎為0,使用梯度的優(yōu)化方法很難收斂到最優(yōu)點(diǎn),另外就是SGD訓(xùn)練震蕩,很容易引起訓(xùn)練不穩(wěn)定。理論上是這樣,實(shí)際的問(wèn)題比這復(fù)雜的多。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~