
Grafana Loki 查詢語言 LogQL 使用
受 PromQL 的啟發(fā),Loki 也有自己的查詢語言,稱為 LogQL,它就像一個分布式的 grep,可以聚合查看日志。和 PromQL 一樣,LogQL 也是使用標簽和運算符進行過濾的,主要有兩種類型的查詢功能:
查詢返回日志行內(nèi)容 通過過濾規(guī)則在日志流中計算相關(guān)的度量指標
日志查詢
一個基本的日志查詢由兩部分組成。
log stream selector(日志流選擇器)log pipeline(日志管道)
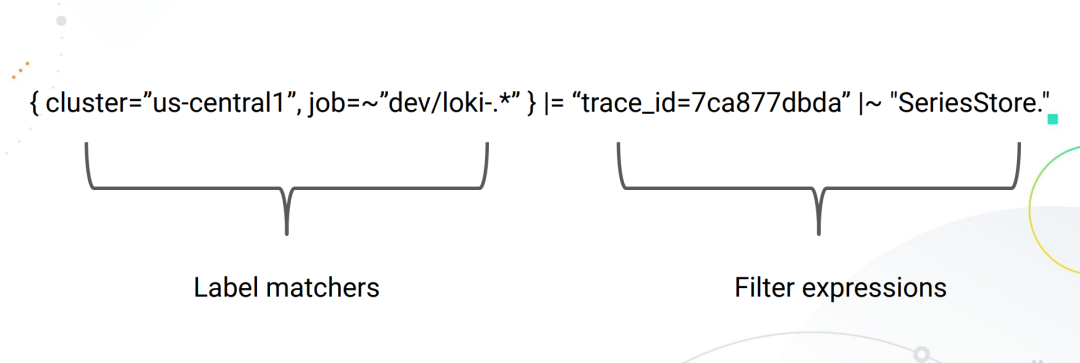
由于 Loki 的設(shè)計,所有 LogQL 查詢必須包含一個日志流選擇器。一個 Log Stream 代表了具有相同元數(shù)據(jù)(Label 集)的日志條目。
日志流選擇器決定了有多少日志將被搜索到,一個更細粒度的日志流選擇器將搜索到流的數(shù)量減少到一個可管理的數(shù)量,通過精細的匹配日志流,可以大幅減少查詢期間帶來資源消耗。
而日志流選擇器后面的日志管道是可選的,用于進一步處理和過濾日志流信息,它由一組表達式組成,每個表達式都以從左到右的順序為每個日志行執(zhí)行相關(guān)過濾,每個表達式都可以過濾、解析和改變?nèi)罩拘袃?nèi)容以及各自的標簽。
下面的例子顯示了一個完整的日志查詢的操作:
{container="query-frontend",namespace="loki-dev"} |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500該查詢語句由以下幾個部分組成:
一個日志流選擇器 {container="query-frontend",namespace="loki-dev"},用于過濾loki-dev命名空間下面的query-frontend容器的日志然后后面跟著一個日志管道 |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500,該管道表示將篩選出包含metrics.go這個詞的日志,然后解析每一行日志提取更多的表達式并進行過濾
為了避免轉(zhuǎn)義特色字符,你可以在引用字符串的時候使用單引號,而不是雙引號,比如 `\w+1` 與 "\w+" 是相同的。
Log Stream Selector
日志流選擇器決定了哪些日志流應(yīng)該被包含在你的查詢結(jié)果中,選擇器由一個或多個鍵值對組成,其中每個鍵是一個日志標簽,每個值是該標簽的值。
日志流選擇器是通過將鍵值對包裹在一對大括號中編寫的,比如:
{app="mysql", name="mysql-backup"}上面這個示例表示,所有標簽為 app 且其值為 mysql 和標簽為 name 且其值為 mysql-backup 的日志流將被包括在查詢結(jié)果中。
其中標簽名后面的 = 運算符是一個標簽匹配運算符,LogQL 中一共支持以下幾種標簽匹配運算符:
=: 完全匹配!=: 不相等=~: 正則表達式匹配!~: 正則表達式不匹配
例如:
{name=~"mysql.+"}{name!~"mysql.+"}{name!~"mysql-\\d+"}
適用于 Prometheus 標簽選擇器的規(guī)則同樣適用于 Loki 日志流選擇器。
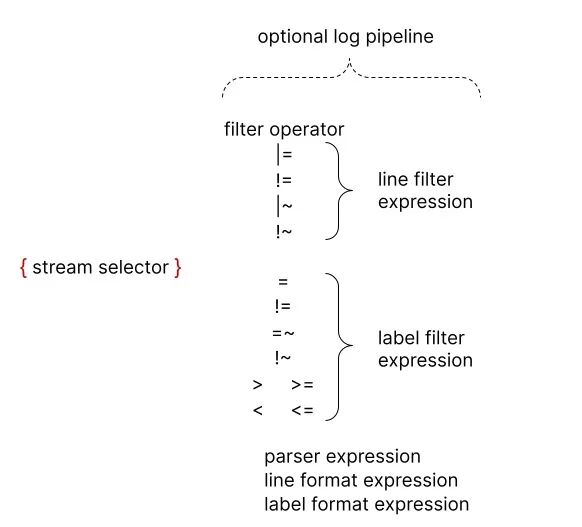
Log Pipeline
日志管道可以附加到日志流選擇器上,以進一步處理和過濾日志流。它通常由一個或多個表達式組成,每個表達式針對每個日志行依次執(zhí)行。如果一個表達式過濾掉了日志行,則管道將在此處停止并開始處理下一行。一些表達式可以改變?nèi)罩緝?nèi)容和各自的標簽,然后可用于進一步過濾和處理后續(xù)表達式或指標查詢。
一個日志管道可以由以下部分組成。
日志行過濾表達式 解析器表達式 標簽過濾表達式 日志行格式化表達式 標簽格式化表達式 Unwrap 表達式
其中 unwrap 表達式是一個特殊的表達式,只能在度量查詢中使用。
日志行過濾表達式
日志行過濾表達式用于對匹配日志流中的聚合日志進行分布式 grep。
編寫入日志流選擇器后,可以使用一個搜索表達式進一步過濾得到的日志數(shù)據(jù)集,搜索表達式可以是文本或正則表達式,比如:
{job="mysql"} |= "error"{name="kafka"} |~ "tsdb-ops.*io:2003"{name="cassandra"} |~ "error=\\w+"{instance=~"kafka-[23]",name="kafka"} != "kafka.server:type=ReplicaManager"
上面示例中的 |=、|~ 和 != 是過濾運算符,支持下面幾種:
|=:日志行包含的字符串!=:日志行不包含的字符串|~:日志行匹配正則表達式!~:日志行與正則表達式不匹配
過濾運算符可以是鏈式的,并將按順序過濾表達式,產(chǎn)生的日志行必須滿足每個過濾器。當使用 |~和 !~ 時,可以使用 Golang 的 RE2 語法的正則表達式,默認情況下,匹配是區(qū)分大小寫的,可以用 (?i) 作為正則表達式的前綴,切換為不區(qū)分大小寫。
雖然日志行過濾表達式可以放在管道的任何地方,但最好把它們放在開頭,這樣可以提高查詢的性能,當某一行匹配時才做進一步的后續(xù)處理。例如,雖然結(jié)果是一樣的,但下面的查詢 {job="mysql"} |= "error" |json | line_format "{{.err}}" 會比 {job="mysql"} | json | line_format "{{.message}}" |= "error" 更快,日志行過濾表達式是繼日志流選擇器之后過濾日志的最快方式。
解析器表達式
解析器表達式可以解析和提取日志內(nèi)容中的標簽,這些提取的標簽可以用于標簽過濾表達式進行過濾,或者用于指標聚合。
提取的標簽鍵將由解析器進行自動格式化,以遵循 Prometheus 指標名稱的約定(它們只能包含 ASCII 字母和數(shù)字,以及下劃線和冒號,不能以數(shù)字開頭)。
例如下面的日志經(jīng)過管道 | json 將產(chǎn)生以下 Map 數(shù)據(jù):
{ "a.b": { "c": "d" }, "e": "f" }
->
{a_b_c="d", e="f"}在出現(xiàn)錯誤的情況下,例如,如果該行不是預(yù)期的格式,該日志行不會被過濾,而是會被添加一個新的 __error__ 標簽。
需要注意的是如果一個提取的標簽鍵名已經(jīng)存在于原始日志流中,那么提取的標簽鍵將以 _extracted 作為后綴,以區(qū)分兩個標簽,你可以使用一個標簽格式化表達式來強行覆蓋原始標簽,但是如果一個提取的鍵出現(xiàn)了兩次,那么只有最新的標簽值會被保留。
目前支持 json、logfmt、pattern、regexp 和 unpack 這幾種解析器。
我們應(yīng)該盡可能使用 json 和 logfmt 等預(yù)定義的解析器,這會更加容易,而當日志行結(jié)構(gòu)異常時,可以使用 regexp,可以在同一日志管道中使用多個解析器,這在你解析復(fù)雜日志時很有用。
JSON
json 解析器有兩種模式運行。
如果日志行是一個有效的 json 文檔,在你的管道中添加
| json將提取所有 json 屬性作為標簽,嵌套的屬性會使用_分隔符被平鋪到標簽鍵中。注意:數(shù)組會被忽略。
例如,使用 json 解析器從以下文件內(nèi)容中提取標簽。
{
"protocol": "HTTP/2.0",
"servers": ["129.0.1.1", "10.2.1.3"],
"request": {
"time": "6.032",
"method": "GET",
"host": "foo.grafana.net",
"size": "55",
"headers": {
"Accept": "*/*",
"User-Agent": "curl/7.68.0"
}
},
"response": {
"status": 401,
"size": "228",
"latency_seconds": "6.031"
}
}可以得到如下所示的標簽列表:
"protocol" => "HTTP/2.0"
"request_time" => "6.032"
"request_method" => "GET"
"request_host" => "foo.grafana.net"
"request_size" => "55"
"response_status" => "401"
"response_size" => "228"
"response_latency_seconds" => "6.031"沒有參數(shù)。 在你的管道中使用
|json label="expression", another="expression"將只提取指定的 json 字段為標簽,你可以用這種方式指定一個或多個表達式,與label_format相同,所有表達式必須加引號。當前僅支持字段訪問(
my.field,my["field"])和數(shù)組訪問(list[0]),以及任何級別嵌套中的這些組合(my.list[0]["field"])。例如,
|json first_server="servers[0]", ua="request.headers[\"User-Agent\"]將從以下日志文件中提取標簽:{
"protocol": "HTTP/2.0",
"servers": ["129.0.1.1", "10.2.1.3"],
"request": {
"time": "6.032",
"method": "GET",
"host": "foo.grafana.net",
"size": "55",
"headers": {
"Accept": "*/*",
"User-Agent": "curl/7.68.0"
}
},
"response": {
"status": 401,
"size": "228",
"latency_seconds": "6.031"
}
}提取的標簽列表為:
"first_server" => "129.0.1.1"
"ua" => "curl/7.68.0"如果表達式返回一個數(shù)組或?qū)ο螅鼘⒁?json 格式分配給標簽。例如,
|json server_list="services", headers="request.headers將提取到如下標簽:"server_list" => `["129.0.1.1","10.2.1.3"]`
"headers" => `{"Accept": "*/*", "User-Agent": "curl/7.68.0"}`帶參數(shù)的
logfmt
logfmt 解析器可以通過使用 | logfmt 來添加,它將從 logfmt 格式的日志行中提前所有的鍵和值。
例如,下面的日志行數(shù)據(jù):
at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service=8ms status=200將提取得到如下所示的標簽:
"at" => "info"
"method" => "GET"
"path" => "/"
"host" => "grafana.net"
"fwd" => "124.133.124.161"
"service" => "8ms"
"status" => "200"regexp
與 logfmt 和 json(它們隱式提取所有值且不需要參數(shù))不同,regexp 解析器采用單個參數(shù) | regexp "<re>" 的格式,其參數(shù)是使用 Golang RE2 語法的正則表達式。
正則表達式必須包含至少一個命名的子匹配(例如(?P<name>re)),每個子匹配項都會提取一個不同的標簽。
例如,解析器 | regexp "(?P<method>\\w+) (?P<path>[\\w|/]+) \\((?P<status>\\d+?)\\) (?P<duration>.*)" 將從以下行中提取標簽:
POST /api/prom/api/v1/query_range (200) 1.5s提取的標簽為:
"method" => "POST"
"path" => "/api/prom/api/v1/query_range"
"status" => "200"
"duration" => "1.5s"pattern
模式解析器允許通過定義模式表達式(| pattern "<pattern-expression>")從日志行中顯式提取字段,該表達式與日志行的結(jié)構(gòu)相匹配。
比如我們來考慮下面的 NGINX 日志行數(shù)據(jù):
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""
該日志行可以用下面的表達式來解析:
<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>
解析后可以提取出下面的這些屬性:
"ip" => "0.191.12.2"
"method" => "GET"
"uri" => "/api/plugins/versioncheck"
"status" => "200"
"size" => "2"
"agent" => "Go-http-client/2.0"模式表達式的捕獲是由 < 和 > 字符分隔的字段名稱,比如 <example> 定義了字段名稱為 example,未命名的 capture 顯示為 <_>,未命名的 capture 會跳過匹配的內(nèi)容。默認情況下,模式表達式錨定在日志行的開頭,可以在表達式的開頭使用 <_> 將表達式錨定在開頭。
比如我們查看下面的日志行數(shù)據(jù):
level=debug ts=2021-06-10T09:24:13.472094048Z caller=logging.go:66 traceID=0568b66ad2d9294c msg="POST /loki/api/v1/push (204) 16.652862ms"
我們?nèi)绻幌Mテヅ?msg=" 的內(nèi)容,我們可以使用下面的表達式來進行匹配:
<_> msg="<method> <path> (<status>) <latency>"
前面大部分日志數(shù)據(jù)我們不需要,只需要使用 <_> 進行占位即可,明顯可以看出這種方式比正則表達式要簡單得多。
unpack
unpack 解析器將解析 json 日志行,并通過打包階段解開所有嵌入的標簽,一個特殊的屬性 _entry 也將被用來替換原來的日志行。
例如,使用 | unpack 解析器,可以得到如下所示的標簽:
{
"container": "myapp",
"pod": "pod-3223f",
"_entry": "original log message"
}
允許提取 container 和 pod 標簽以及原始日志信息作為新的日志行。
如果原始嵌入的日志行是特定的格式,你可以將 unpack 與 json 解析器(或其他解析器)相結(jié)合使用。
標簽過濾表達式
標簽過濾表達式允許使用其原始和提取的標簽來過濾日志行,它可以包含多個謂詞。
一個謂詞包含一個標簽標識符、操作符和用于比較標簽的值。
例如 cluster="namespace" 其中的 cluster 是標簽標識符,操作符是 =,值是"namespace"。
LogQL 支持從查詢輸入中自動推斷出的多種值類型:
String(字符串)用雙引號或反引號引起來,例如"200"或`us-central1`。Duration(時間)是一串十進制數(shù)字,每個數(shù)字都有可選的數(shù)和單位后綴,如"300ms"、"1.5h"或"2h45m",有效的時間單位是"ns"、"us"(或"μs")、"ms"、"s"、"m"、"h"。Number(數(shù)字)是浮點數(shù)(64 位),如 250、89.923。Bytes(字節(jié))是一串十進制數(shù)字,每個數(shù)字都有可選的數(shù)和單位后綴,如"42MB"、"1.5Kib"或"20b",有效的字節(jié)單位是"b"、"kib"、"kb"、"mib"、"mb"、"gib"、"gb"、"tib"、"tb"、"pib"、"bb"、"eb"。
字符串類型的工作方式與 Prometheus 標簽匹配器在日志流選擇器中使用的方式完全一樣,這意味著你可以使用同樣的操作符(=、!=、=~、!~)。
使用 Duration、Number 和 Bytes 將在比較前轉(zhuǎn)換標簽值,并支持以下比較器。
==或=相等比較!=不等于比較>和>=用于大于或大于等于比較<和<=用于小于或小于等于比較
例如 logfmt | duration > 1m and bytes_consumed > 20MB 過濾表達式。
如果標簽值的轉(zhuǎn)換失敗,日志行就不會被過濾,而會添加一個 __error__ 標簽。你可以使用 and和 or 來連接多個謂詞,它們分別表示且和或的二進制操作,and 可以用逗號、空格或其他管道來表示,標簽過濾器可以放在日志管道的任何地方。
以下所有的表達式都是等價的:
| duration >= 20ms or size == 20kb and method!~"2.."
| duration >= 20ms or size == 20kb | method!~"2.."
| duration >= 20ms or size == 20kb,method!~"2.."
| duration >= 20ms or size == 20kb method!~"2.."默認情況下,多個謂詞的優(yōu)先級是從右到左,你可以用圓括號包裝謂詞,強制使用從左到右的不同優(yōu)先級。
例如,以下內(nèi)容是等價的:
| duration >= 20ms or method="GET" and size <= 20KB
| ((duration >= 20ms or method="GET") and size <= 20KB)它將首先評估 duration>=20ms or method="GET",要首先評估 method="GET" and size<=20KB,請確保使用適當?shù)睦ㄌ枺缦滤尽?/p>
| duration >= 20ms or (method="GET" and size <= 20KB)日志行格式表達式
日志行格式化表達式可以通過使用 Golang 的 text/template 模板格式重寫日志行的內(nèi)容,它需要一個字符串參數(shù) | line_format "{{.label_name}}" 作為模板格式,所有的標簽都是注入模板的變量,可以用 {{.label_name}} 的符號來使用。
例如,下面的表達式:
{container="frontend"} | logfmt | line_format "{{.query}} {{.duration}}"將提取并重寫日志行,只包含 query 和請求的 duration。你可以為模板使用雙引號字符串或反引號 `{{.label_name}}` 來避免轉(zhuǎn)義特殊字符。
此外 line_format 也支持數(shù)學(xué)函數(shù),例如:
如果我們有以下標簽 ip=1.1.1.1, status=200 和 duration=3000(ms), 我們可以用 duration 除以 1000 得到以秒為單位的值:
{container="frontend"} | logfmt | line_format "{{.ip}} {{.status}} {{div .duration 1000}}"上面的查詢將得到的日志行內(nèi)容為1.1.1.1 200 3。
標簽格式表達式
| label_format 表達式可以重命名、修改或添加標簽,它以逗號分隔的操作列表作為參數(shù),可以同時進行多個操作。
當兩邊都是標簽標識符時,例如 dst=src,該操作將把 src 標簽重命名為 dst。
左邊也可以是一個模板字符串,例如 dst="{{.status}} {{.query}}",在這種情況下,dst 標簽值會被 Golang 模板執(zhí)行結(jié)果所取代,這與 | line_format 表達式是同一個模板引擎,這意味著標簽可以作為變量使用,也可以使用同樣的函數(shù)列表。
在上面兩種情況下,如果目標標簽不存在,那么就會創(chuàng)建一個新的標簽。
重命名形式 dst=src 會在將 src 標簽重新映射到 dst 標簽后將其刪除,然而,模板形式將保留引用的標簽,例如 dst="{{.src}}" 的結(jié)果是 dst 和 src 都有相同的值。
一個標簽名稱在每個表達式中只能出現(xiàn)一次,這意味著
| label_format foo=bar,foo="new"是不允許的,但你可以使用兩個表達式來達到預(yù)期效果,比如| label_format foo=bar | label_format foo="new"。
日志度量
LogQL 同樣支持通過函數(shù)方式將日志流進行度量,通常我們可以用它來計算消息的錯誤率或者排序一段時間內(nèi)的應(yīng)用日志輸出 Top N。
區(qū)間向量
LogQL 同樣也支持有限的區(qū)間向量度量語句,使用方式和 PromQL 類似,常用函數(shù)主要是如下 4 個:
rate: 計算每秒的日志條目count_over_time: 對指定范圍內(nèi)的每個日志流的條目進行計數(shù)bytes_rate: 計算日志流每秒的字節(jié)數(shù)bytes_over_time: 對指定范圍內(nèi)的每個日志流的使用的字節(jié)數(shù)
比如計算 nginx 的 qps:
rate({filename="/var/log/nginx/access.log"}[5m]))計算 kernel 過去 5 分鐘發(fā)生 oom 的次數(shù):
count_over_time({filename="/var/log/message"} |~ "oom_kill_process" [5m]))聚合函數(shù)
LogQL 也支持聚合運算,我們可用它來聚合單個向量內(nèi)的元素,從而產(chǎn)生一個具有較少元素的新向量,當前支持的聚合函數(shù)如下:
sum:求和min:最小值max:最大值avg:平均值stddev:標準差stdvar:標準方差count:計數(shù)bottomk:最小的 k 個元素topk:最大的 k 個元素
聚合函數(shù)我們可以用如下表達式描述:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]對于需要對標簽進行分組時,我們可以用 without 或者 by 來區(qū)分。比如計算 nginx 的 qps,并按照 pod 來分組:
sum(rate({filename="/var/log/nginx/access.log"}[5m])) by (pod)只有在使用 bottomk 和 topk 函數(shù)時,我們可以對函數(shù)輸入相關(guān)的參數(shù)。比如計算 nginx 的 qps 最大的前 5 個,并按照 pod 來分組:
topk(5,sum(rate({filename="/var/log/nginx/access.log"}[5m])) by (pod)))二元運算
數(shù)學(xué)計算
Loki 存的是日志,都是文本,怎么計算呢?顯然 LogQL 中的數(shù)學(xué)運算是面向區(qū)間向量操作的,LogQL 中的支持的二進制運算符如下:
+:加法-:減法*:乘法/:除法%:求模^:求冪
比如我們要找到某個業(yè)務(wù)日志里面的錯誤率,就可以按照如下方式計算:
sum(rate({app="foo", level="error"}[1m])) / sum(rate({app="foo"}[1m]))邏輯運算
集合運算僅在區(qū)間向量范圍內(nèi)有效,當前支持
and:并且or:或者unless:排除
比如:
rate({app=~"foo|bar"}[1m]) and rate({app="bar"}[1m])比較運算
LogQL 支持的比較運算符和 PromQL 一樣,包括:
==:等于!=:不等于>:大于>=: 大于或等于<:小于<=: 小于或等于
通常我們使用區(qū)間向量計算后會做一個閾值的比較,這對應(yīng)告警是非常有用的,比如統(tǒng)計 5 分鐘內(nèi) error 級別日志條目大于 10 的情況:
count_over_time({app="foo", level="error"}[5m]) > 10我們也可以通過布爾計算來表達,比如統(tǒng)計 5 分鐘內(nèi) error 級別日志條目大于 10 為真,反正則為假:
count_over_time({app="foo", level="error"}[5m]) > bool 10注釋
LogQL 查詢可以使用 # 字符進行注釋,例如:
{app="foo"} # anything that comes after will not be interpreted in your query對于多行 LogQL 查詢,可以使用 # 排除整個或部分行:
{app="foo"}
| json
# this line will be ignored
| bar="baz" # this checks if bar = "baz"查詢示例
這里我們部署一個示例應(yīng)用,該應(yīng)用程序是一個偽造的記錄器,它的日志具有 debug、info 和 warning 輸出到 stdout。error 級別的日志將被寫入 stderr,實際的日志消息以 JSON 格式生成,每 500 毫秒將創(chuàng)建一條新的日志消息。日志消息格式如下所示:
{
"app":"The fanciest app of mankind",
"executable":"fake-logger",
"is_even": true,
"level":"debug",
"msg":"This is a debug message. Hope you'll catch the bug",
"time":"2022-04-04T13:41:50+02:00",
"version":"1.0.0"
}
使用下面的命令來創(chuàng)建示例應(yīng)用:
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: fake-logger
environment: development
name: fake-logger
spec:
selector:
matchLabels:
app: fake-logger
environment: development
template:
metadata:
labels:
app: fake-logger
environment: development
spec:
containers:
- image: thorstenhans/fake-logger:0.0.2
name: fake-logger
resources:
requests:
cpu: 10m
memory: 32Mi
limits:
cpu: 10m
memory: 32Mi
EOF
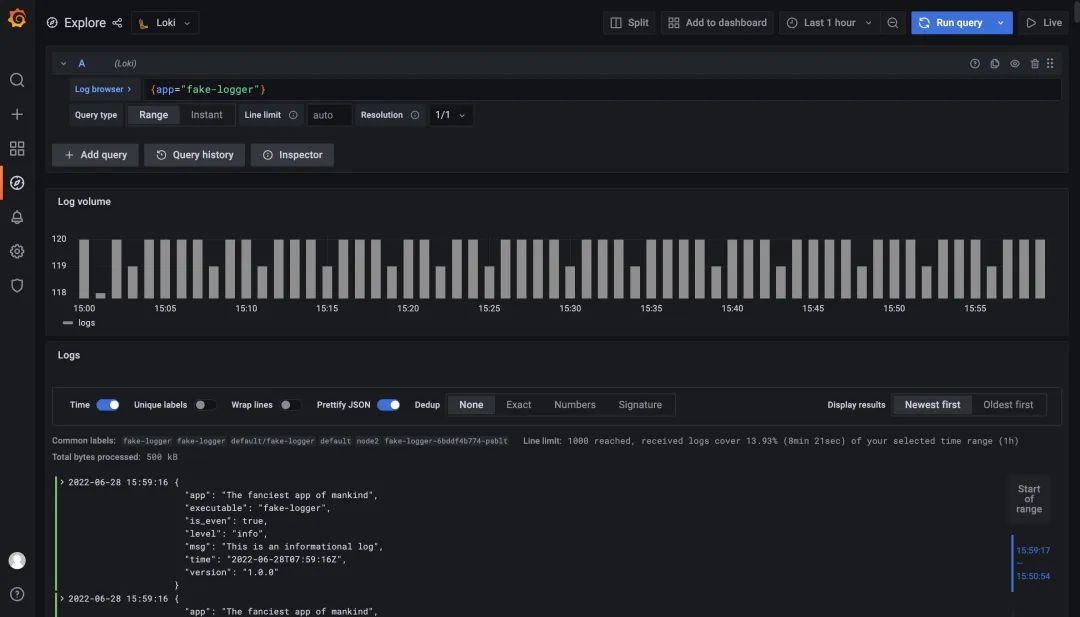
我們可以使用 {app="fake-logger"} 在 Grafana 中查詢到該應(yīng)用的日志流數(shù)據(jù)。
由于我們該示例應(yīng)用的日志是 JSON 形式的,我們可以采用 JSON 解析器來解析日志,表達式為 {app="fake-logger"} | json,如下所示。
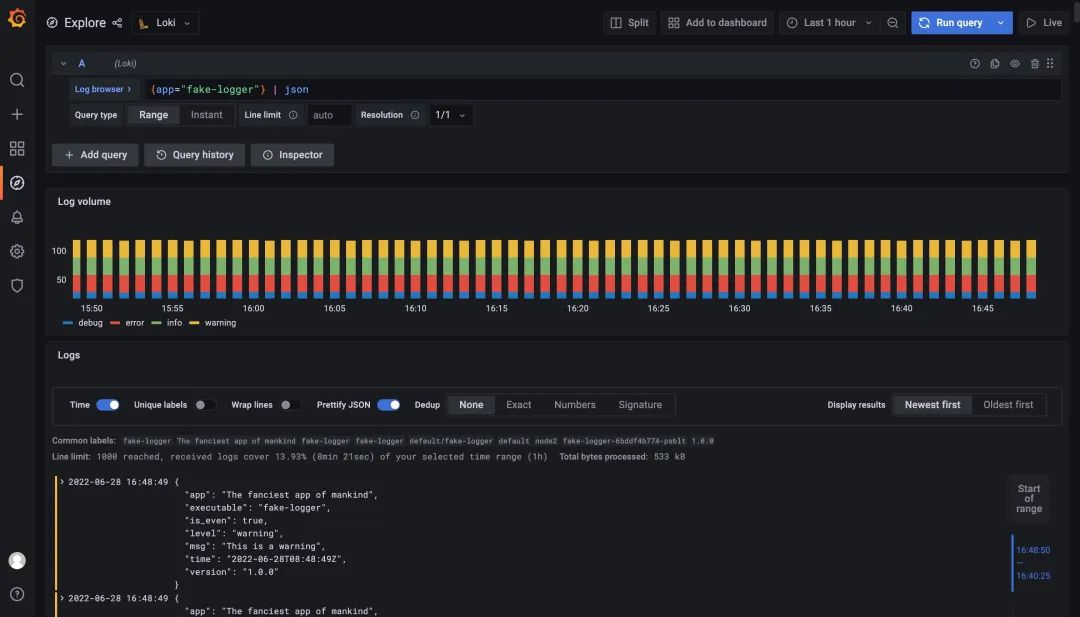
使用 JSON 解析器解析日志后可以看到 Grafana 提供的面板會根據(jù) level 的值使用不同的顏色進行區(qū)分,而且現(xiàn)在我們?nèi)罩镜膶傩砸脖惶砑拥搅?Log 的標簽中去了。
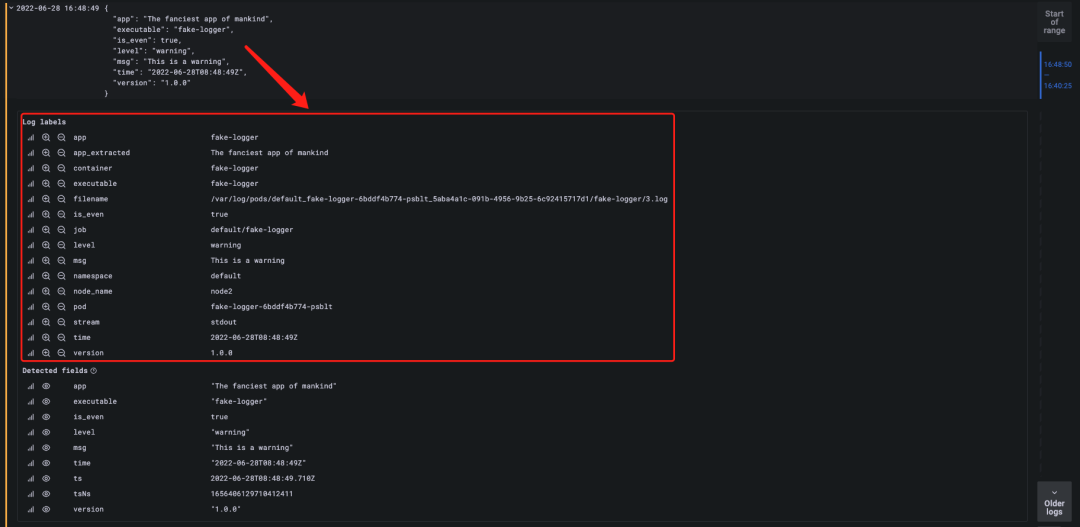
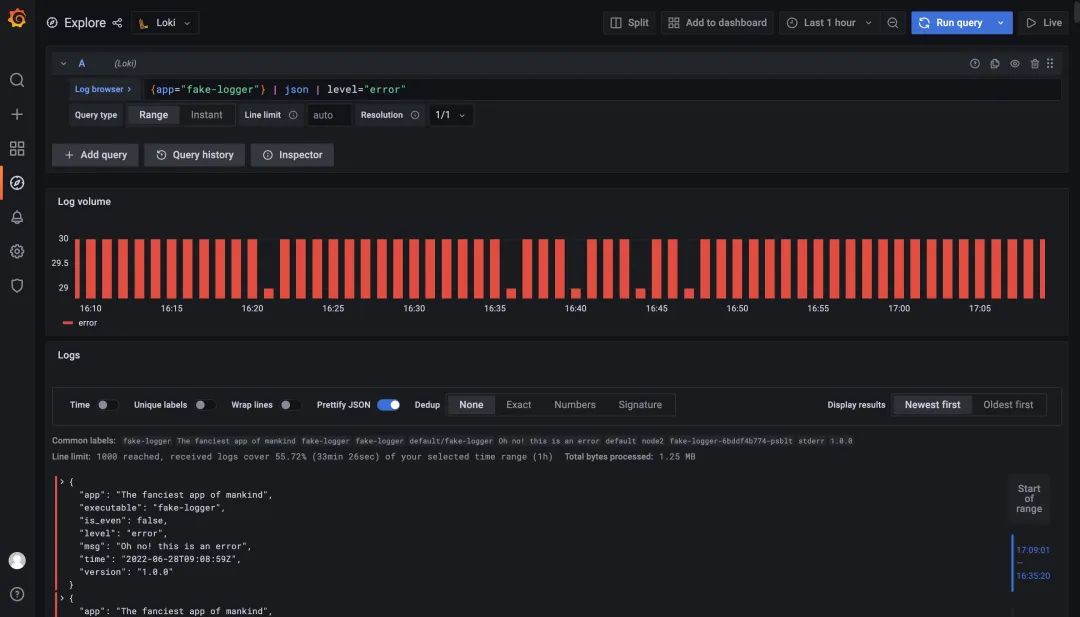
現(xiàn)在 JSON 中的數(shù)據(jù)變成了日志標簽我們自然就可以使用這些標簽來過濾日志數(shù)據(jù)了,比如我們要過濾 level=error 的日志,只使用表達式 {app="fake-logger"} | json | level="error" 即可實現(xiàn)。
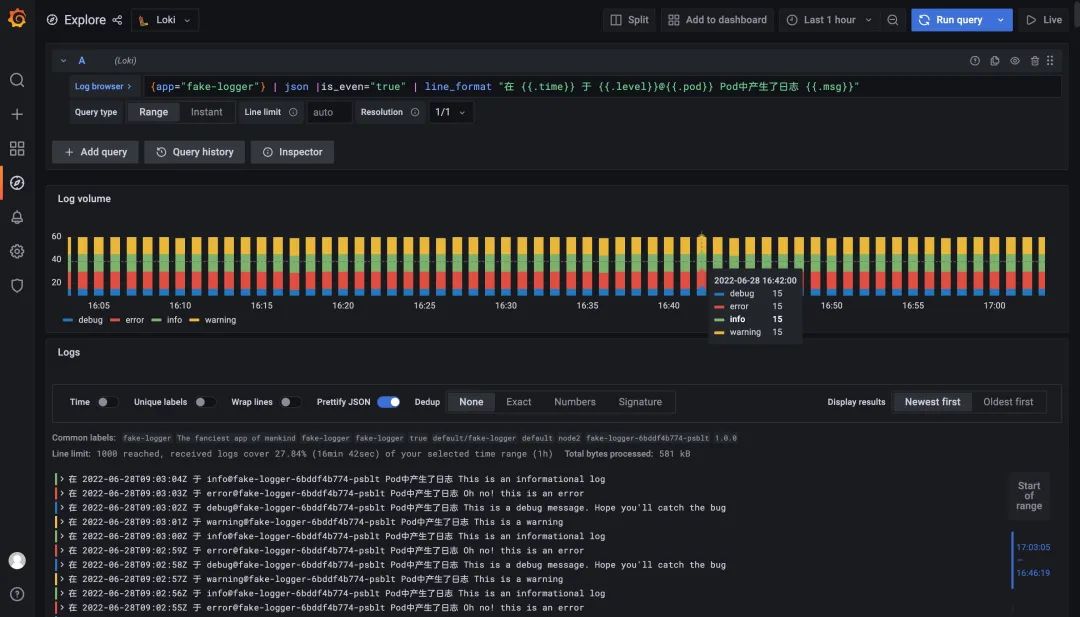
此外我們還可以根據(jù)我們的需求去格式化輸出日志,使用 line_format 即可實現(xiàn),比如我們這里使用查詢語句 {app="fake-logger"} | json |is_even="true" | line_format "在 {{.time}} 于 {{.level}}@{{.pod}} Pod中產(chǎn)生了日志 {{.msg}}" 來格式化日志輸出
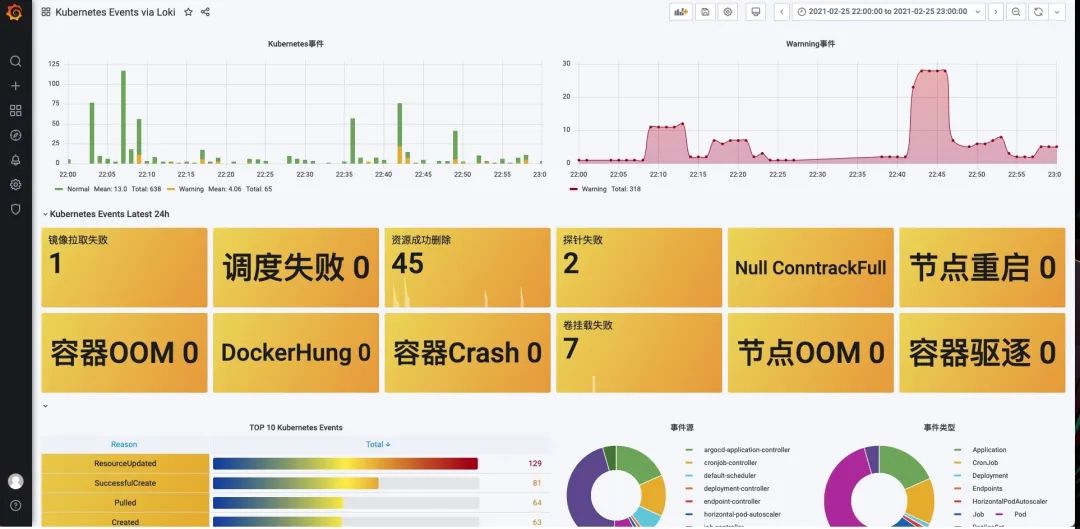
監(jiān)控大盤
這里我們以監(jiān)控 Kubernetes 的事件為例進行說明。首先需要安裝 [kubernetes-event-exporter],地址 https://github.com/opsgenie/kubernetes-event-exporter/tree/master/deploy,kubernetes-event-exporter 日志會打印到 stdout,然后我們的 promtail 會將日志上傳到 Loki。
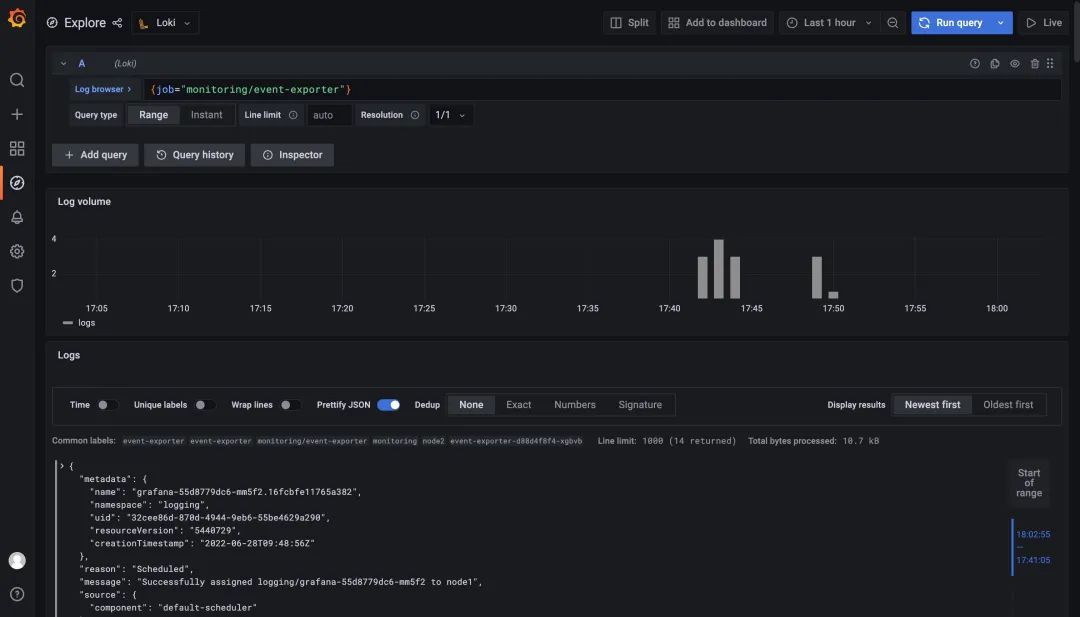
然后導(dǎo)入 https://grafana.com/grafana/dashboards/14003 這個 Dashboard 即可,不過需要注意修改每個圖表中的過濾標簽為 job="monitoring/event-exporter"。
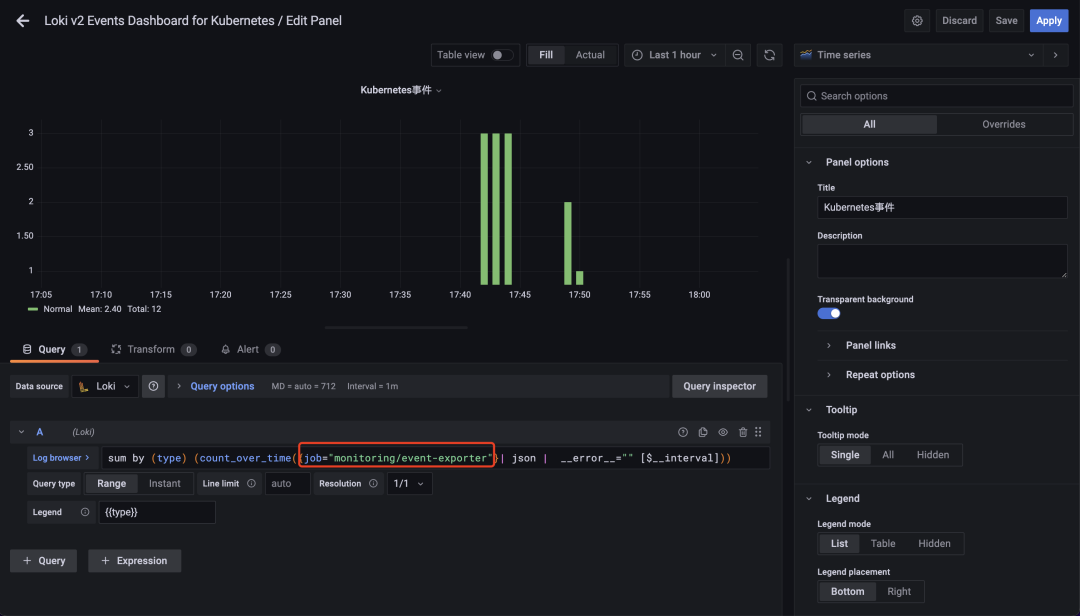
修改后正常就可以在 Dashboard 中看到集群中的相關(guān)事件信息了,不過建議用記錄規(guī)則去替換面板中的查詢語句。
建議
盡量使用靜態(tài)標簽,開銷更小,通常日志在發(fā)送到 Loki 之前注入 label,推薦的靜態(tài)標簽包含:
宿主機:kubernetes/hosts 應(yīng)用名:kubernetes/labels/app_kubernetes_io/name 組件名:kubernetes/labels/name 命名空間:kubernetes/namespace 其他靜態(tài)標簽,如環(huán)境、版本等
謹慎使用動態(tài)標簽。過多的標簽組合會造成大量的流,它會讓 Loki 存儲大量的索引和小塊的對象文件。這些都會顯著消耗 Loki 的查詢性能。為避免這些問題,在你知道需要之前不要添加標簽。Loki 的優(yōu)勢在于并行查詢,使用過濾器表達式(label="text", |~ "regex", ...)來查詢?nèi)罩緯行В⑶宜俣纫埠芸臁?img class="rich_pages wxw-img" data-ratio="0.4899095337508699" src="https://filescdn.proginn.com/8123cc340e0640e7569a7d80b02c128b/cb17a1b1e59b10b67effd07c2a9ed739.webp" data-type="png" data-w="2874" style="display: block;margin: 0 auto;max-width: 100%;border-radius: 4px;margin-bottom: 5px;"> 有界的標簽值范圍,作為 Loki 的用戶或操作員,我們的目標應(yīng)該是使用盡可能少的標簽來存儲你的日志。這意味著,更少的標簽帶來更小的索引,從而導(dǎo)致更好的性能,所以我們在添加標簽之前一定要三思而行。 配置緩存,Loki 可以為多個組件配置緩存, 可以選擇 redis 或者 memcached,這可以顯著提高性能。 合理使用 LogQL 語法,可大幅提高查詢效率。Label matchers(標簽匹配器)是你的第一道防線,是大幅減少你搜索的日志數(shù)量(例如,從100TB到1TB)的最好方法。當然,這意味著你需要在日志采集端上有良好的標簽定義規(guī)范。