
Prometheus | 自從上線了 Prometheus 監(jiān)控告警,真香!
閱讀本文大概需要 7 分鐘。
來源 |?https://www.cyningsun.com/02-22-2020/hidden-secret-to-understanding-prometheus.html
對很多人來說,未知、不確定、不在掌控的東西,會(huì)有潛意識的逃避。當(dāng)我第一次接觸 Prometheus 的時(shí)候也有類似的感覺。對初學(xué)者來說, Prometheus 包含的概念太多了,門檻也太高了。
概念:Instance、Job、Metric、Metric Name、Metric Label、Metric Value、Metric Type(Counter、Gauge、Histogram、Summary)、DataType(Instant Vector、Range Vector、Scalar、String)、Operator、Function
馬云說:“雖然阿里巴巴是全球最大的零售平臺,但阿里不是零售公司,是一家數(shù)據(jù)公司”。Prometheus 也是一樣,本質(zhì)來說是一個(gè)基于數(shù)據(jù)的監(jiān)控系統(tǒng)。
日常監(jiān)控
假設(shè)需要監(jiān)控 WebServerA 每個(gè) API 的請求量為例,需要監(jiān)控的維度包括:服務(wù)名(job)、實(shí)例IP(instance)、API名(handler)、方法(method)、返回碼(code)、請求量(value)。
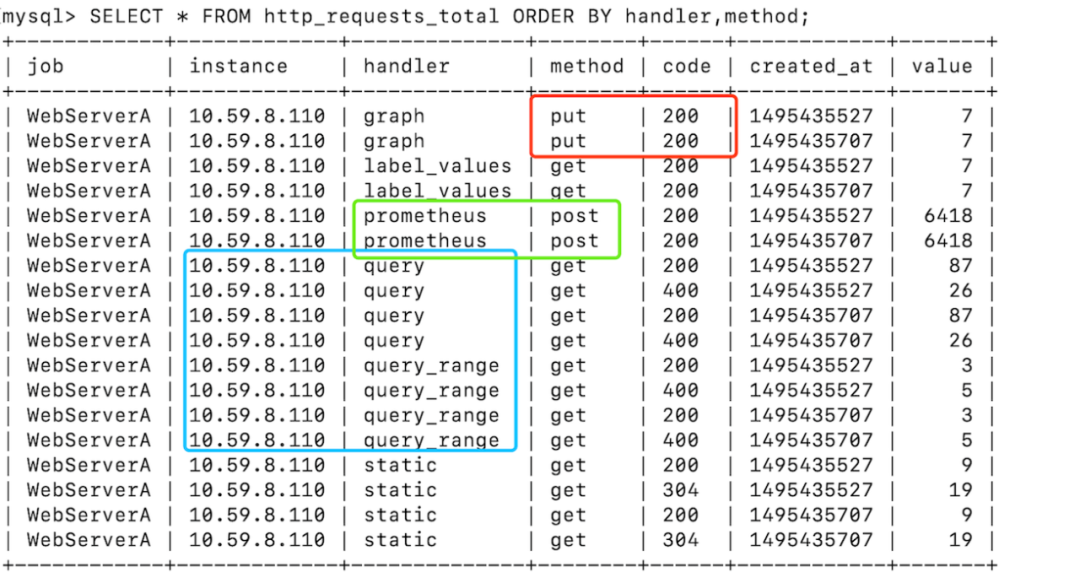
如果以 SQL 為例,演示常見的查詢操作:
查詢 method=put 且 code=200 的請求量(紅框)
SELECT?*?from?http_requests_total?WHERE?code=”200”?AND?method=”put”?AND?created_at?BETWEEN?1495435700?AND?1495435710;
查詢 handler=prometheus 且 method=post 的請求量(綠框)
SELECT?*?from?http_requests_total?WHERE?handler=”prometheus”?AND?method=”post”?AND?created_at?BETWEEN?1495435700?AND?1495435710;
查詢 instance=10.59.8.110 且 handler 以 query 開頭 的請求量(綠框)
SELECT?*?from?http_requests_total?WHERE?handler=”query”?AND?instance=”10.59.8.110”?AND?created_at?BETWEEN?1495435700?AND?1495435710;
通過以上示例可以看出,在常用查詢和統(tǒng)計(jì)方面,日常監(jiān)控多用于根據(jù)監(jiān)控的維度進(jìn)行查詢與時(shí)間進(jìn)行組合查詢。如果監(jiān)控 100 個(gè)服務(wù),平均每個(gè)服務(wù)部署 10 個(gè)實(shí)例,每個(gè)服務(wù)有 20 個(gè) API,4 個(gè)方法,30 秒收集一次數(shù)據(jù),保留 60 天。那么總數(shù)據(jù)條數(shù)為:100(服務(wù)) 10(實(shí)例) 20(API) 4(方法) 86400(1天秒數(shù))* 60(天) / 30(秒)= 138.24 億條數(shù)據(jù),寫入、存儲、查詢?nèi)绱肆考壍臄?shù)據(jù)是不可能在Mysql類的關(guān)系數(shù)據(jù)庫上完成的。因此 Prometheus 使用 TSDB 作為 存儲引擎
存儲引擎
TSDB 作為 Prometheus 的存儲引擎完美契合了監(jiān)控?cái)?shù)據(jù)的應(yīng)用場景
存儲的數(shù)據(jù)量級十分龐大 大部分時(shí)間都是寫入操作 寫入操作幾乎是順序添加,大多數(shù)時(shí)候數(shù)據(jù)到達(dá)后都以時(shí)間排序 寫操作很少寫入很久之前的數(shù)據(jù),也很少更新數(shù)據(jù)。大多數(shù)情況在數(shù)據(jù)被采集到數(shù)秒或者數(shù)分鐘后就會(huì)被寫入數(shù)據(jù)庫 刪除操作一般為區(qū)塊刪除,選定開始的歷史時(shí)間并指定后續(xù)的區(qū)塊。很少單獨(dú)刪除某個(gè)時(shí)間或者分開的隨機(jī)時(shí)間的數(shù)據(jù) 基本數(shù)據(jù)大,一般超過內(nèi)存大小。一般選取的只是其一小部分且沒有規(guī)律,緩存幾乎不起任何作用 讀操作是十分典型的升序或者降序的順序讀 高并發(fā)的讀操作十分常見
那么 TSDB 是怎么實(shí)現(xiàn)以上功能的呢?
"labels":?[{
????"latency":????????"500"
}]
"samples":[{
????"timestamp":?1473305798,
????"value":?0.9
}]
原始數(shù)據(jù)分為兩部分 label, samples。前者記錄監(jiān)控的維度(標(biāo)簽:標(biāo)簽值),指標(biāo)名稱和標(biāo)簽的可選鍵值對唯一確定一條時(shí)間序列(使用 series_id 代表);后者包含包含了時(shí)間戳(timestamp)和指標(biāo)值(value)。
series
^
│.?.?.?.?.?.?.?.?.?.?.?.???server{latency="500"}
│.?.?.?.?.?.?.?.?.?.?.?.???server{latency="300"}
│.?.?.?.?.?.?.?.?.?.???.???server{}
│.?.?.?.?.?.?.?.?.?.?.?.?
v
<--------?time?---------->
TSDB 使用 timeseries:doc:: 為 key 存儲 value。為了加速常見查詢查詢操作:label 和 時(shí)間范圍結(jié)合。TSDB 額外構(gòu)建了三種索引:Series, Label Index 和 Time Index。
以標(biāo)簽 latency 為例:
Series
存儲兩部分?jǐn)?shù)據(jù)。一部分是按照字典序的排列的所有標(biāo)簽鍵值對序列(series);另外一部分是時(shí)間線到數(shù)據(jù)文件的索引,按照時(shí)間窗口切割存儲數(shù)據(jù)塊記錄的具體位置信息,因此在查詢時(shí)可以快速跳過大量非查詢窗口的記錄數(shù)據(jù)
Label Index
每對 label 為會(huì)以 index:label: 為 key,存儲該標(biāo)簽所有值的列表,并通過引用指向 Series 該值的起始位置。
Time Index
數(shù)據(jù)會(huì)以 index:timeseries:: 為 key,指向?qū)?yīng)時(shí)間段的數(shù)據(jù)文件
數(shù)據(jù)計(jì)算
強(qiáng)大的存儲引擎為數(shù)據(jù)計(jì)算提供了完美的助力,使得 Prometheus 與其他監(jiān)控服務(wù)完全不同。Prometheus 可以查詢出不同的數(shù)據(jù)序列,然后再加上基礎(chǔ)的運(yùn)算符,以及強(qiáng)大的函數(shù),就可以執(zhí)行 metric series 的矩陣運(yùn)算(見下圖)。
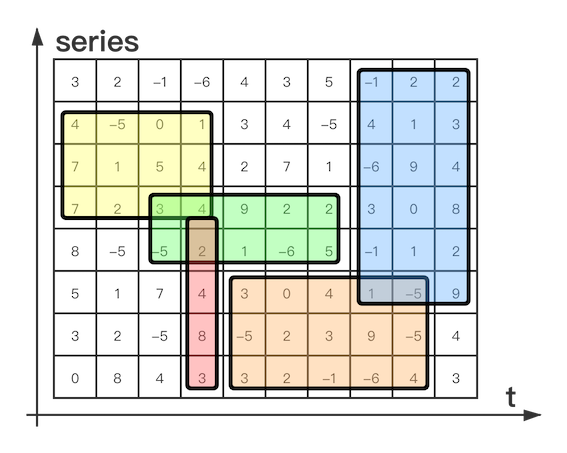
如此,Promtheus體系的能力不弱于監(jiān)控界的“數(shù)據(jù)倉庫”+“計(jì)算平臺”。因此,在大數(shù)據(jù)的開始在業(yè)界得到應(yīng)用,就能明白,這就是監(jiān)控未來的方向。
一次計(jì)算,處處查詢
當(dāng)然,如此強(qiáng)大的計(jì)算能力,消耗的資源也是挺恐怖的。因此,查詢預(yù)計(jì)算結(jié)果通常比每次需要原始表達(dá)式都要快得多,尤其是在儀表盤和告警規(guī)則的適用場景中,儀表盤每次刷新都需要重復(fù)查詢相同的表達(dá)式,告警規(guī)則每次運(yùn)算也是如此。
因此,Prometheus提供了 Recoding rules,可以預(yù)先計(jì)算經(jīng)常需要或者計(jì)算量大的表達(dá)式,并將其結(jié)果保存為一組新的時(shí)間序列, 達(dá)到一次計(jì)算,多次查詢的目的。

Love&Share?
推薦閱讀
1
2
3
4
崔慶才
靜覓博客博主,《Python3網(wǎng)絡(luò)爬蟲開發(fā)實(shí)戰(zhàn)》作者
隱形字
個(gè)人公眾號:進(jìn)擊的Coder
長按識別二維碼關(guān)注
好文和朋友一起看~


