
又被字節(jié)問懵了!
前言
有位伙伴面試了字節(jié)(四年半工作經(jīng)驗),分享下面試真題,大家一起加油哈。
說說Redis為什么快 Redis有幾種數(shù)據(jù)結構,底層分別是怎么存儲的 Redis有幾種持久化方式 多線程情況下,如何保證線程安全? 用過volatile嗎?底層原理是? MySQL的索引結構,聚簇索引和非聚簇索引的區(qū)別 MySQL有幾種高可用方案,你們用的是哪一種 說說你做過最有挑戰(zhàn)性的項目 秒殺采用什么方案 聊聊分庫分表,需要停服嘛 redis掛了怎么辦? 你怎么防止優(yōu)惠券有人重復刷? 抖音評論系統(tǒng)怎么設計 怎么設計一個短鏈地址 有一個數(shù)組,里面元素非重復,先升序再降序,找出里面最大的值
1.說說Redis為什么快
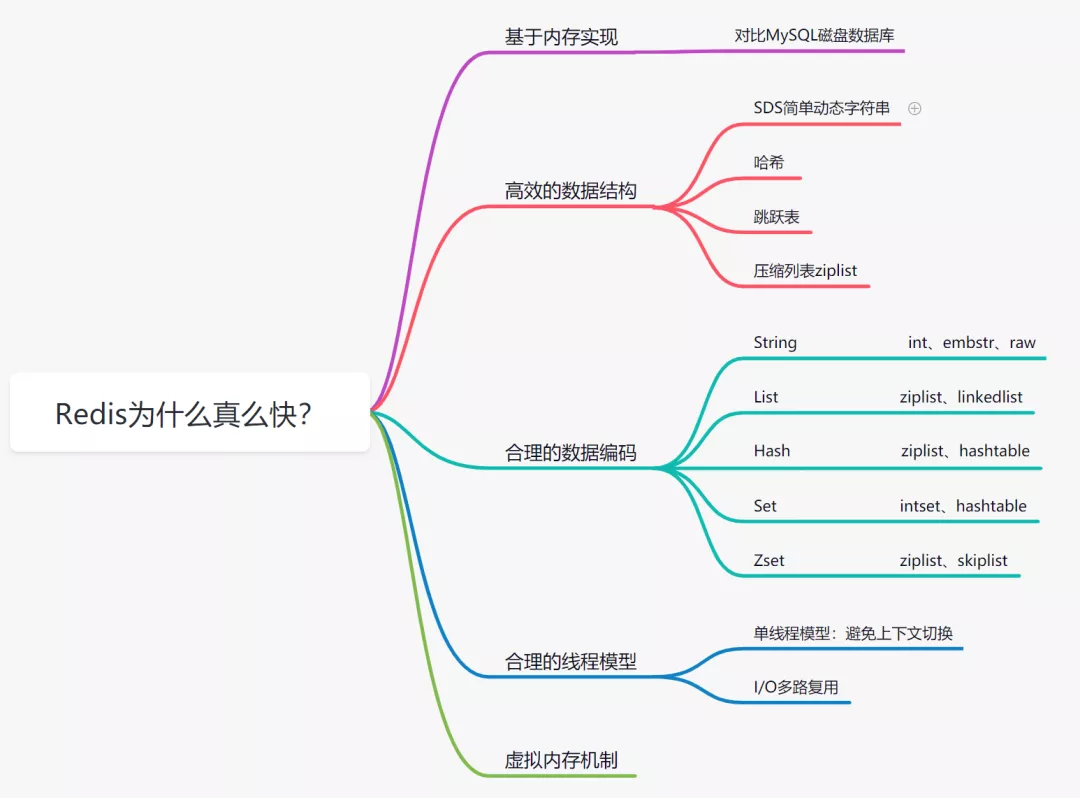
1.1 基于內(nèi)存存儲實現(xiàn)
內(nèi)存讀寫是比在磁盤快很多的,Redis基于內(nèi)存存儲實現(xiàn)的數(shù)據(jù)庫,相對于數(shù)據(jù)存在磁盤的MySQL數(shù)據(jù)庫,省去磁盤I/O的消耗。
1.2 高效的數(shù)據(jù)結構
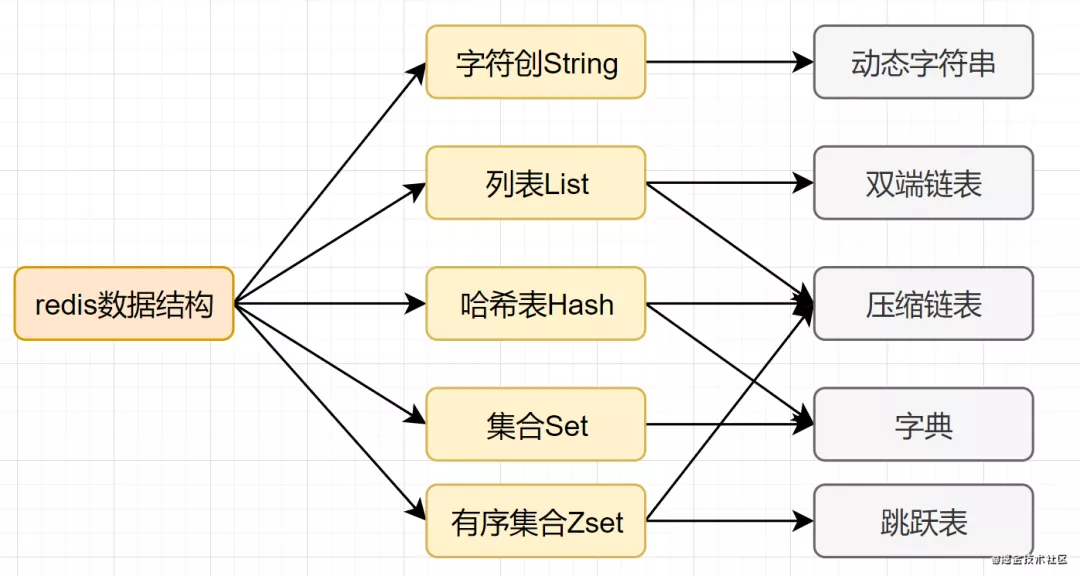
Mysql索引為了提高效率,選擇了B+樹的數(shù)據(jù)結構。其實合理的數(shù)據(jù)結構,就是可以讓你的應用/程序更快。先看下Redis的數(shù)據(jù)結構&內(nèi)部編碼圖:
1.2.1 SDS簡單動態(tài)字符串
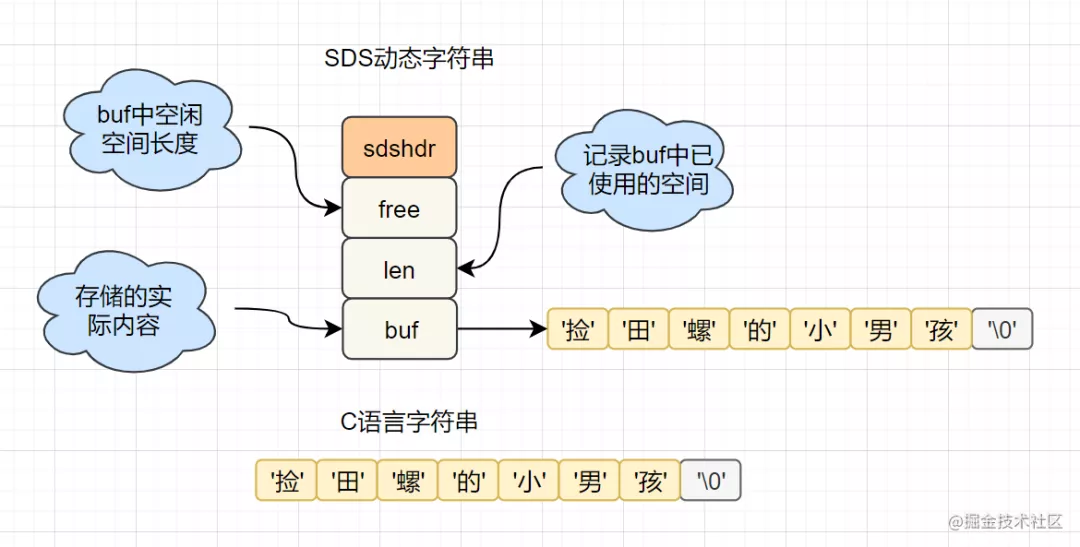
字符串長度處理:Redis獲取字符串長度,時間復雜度為O(1),而C語言中,需要從頭開始遍歷,復雜度為O(n); 空間預分配:字符串修改越頻繁的話,內(nèi)存分配越頻繁,就會消耗性能,而SDS修改和空間擴充,會額外分配未使用的空間,減少性能損耗。 惰性空間釋放:SDS 縮短時,不是回收多余的內(nèi)存空間,而是free記錄下多余的空間,后續(xù)有變更,直接使用free中記錄的空間,減少分配。
1.2.2 字典
Redis 作為 K-V 型內(nèi)存數(shù)據(jù)庫,所有的鍵值就是用字典來存儲。字典就是哈希表,比如HashMap,通過key就可以直接獲取到對應的value。而哈希表的特性,在O(1)時間復雜度就可以獲得對應的值。
1.2.3 跳躍表

跳躍表是Redis特有的數(shù)據(jù)結構,就是在鏈表的基礎上,增加多級索引提升查找效率。 跳躍表支持平均 O(logN),最壞 O(N)復雜度的節(jié)點查找,還可以通過順序性操作批量處理節(jié)點。
1.3 合理的數(shù)據(jù)編碼
Redis 支持多種數(shù)據(jù)類型,每種基本類型,可能對多種數(shù)據(jù)結構。什么時候,使用什么樣數(shù)據(jù)結構,使用什么樣編碼,是redis設計者總結優(yōu)化的結果。
String:如果存儲數(shù)字的話,是用int類型的編碼;如果存儲非數(shù)字,小于等于39字節(jié)的字符串,是embstr;大于39個字節(jié),則是raw編碼。 List:如果列表的元素個數(shù)小于512個,列表每個元素的值都小于64字節(jié)(默認),使用ziplist編碼,否則使用linkedlist編碼 Hash:哈希類型元素個數(shù)小于512個,所有值小于64字節(jié)的話,使用ziplist編碼,否則使用hashtable編碼。 Set:如果集合中的元素都是整數(shù)且元素個數(shù)小于512個,使用intset編碼,否則使用hashtable編碼。 Zset:當有序集合的元素個數(shù)小于128個,每個元素的值小于64字節(jié)時,使用ziplist編碼,否則使用skiplist(跳躍表)編碼
1.4 合理的線程模型
I/O 多路復用

多路I/O復用技術可以讓單個線程高效的處理多個連接請求,而Redis使用用epoll作為I/O多路復用技術的實現(xiàn)。并且,Redis自身的事件處理模型將epoll中的連接、讀寫、關閉都轉換為事件,不在網(wǎng)絡I/O上浪費過多的時間。
2. Redis有幾種數(shù)據(jù)結構,底層分別是怎么存儲的
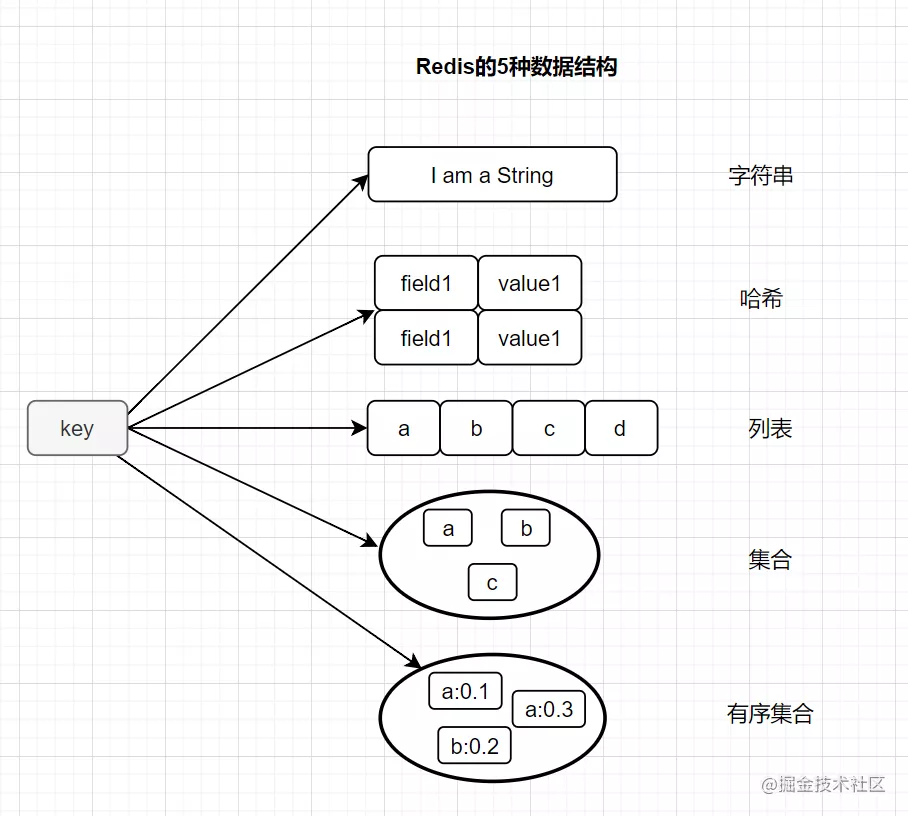
常用的,Redis有以下這五種基本類型:
String(字符串)
Hash(哈希)
List(列表)
Set(集合)
zset(有序集合) 它還有三種特殊的數(shù)據(jù)結構類型
Geospatial
Hyperloglog
Bitmap
2.1 Redis 的五種基本數(shù)據(jù)類型
String(字符串)
簡介:String是Redis最基礎的數(shù)據(jù)結構類型,它是二進制安全的,可以存儲圖片或者序列化的對象,值最大存儲為512M 簡單使用舉例: set key value、get key等 應用場景:共享session、分布式鎖,計數(shù)器、限流。 內(nèi)部編碼有3種,int(8字節(jié)長整型)/embstr(小于等于39字節(jié)字符串)/raw(大于39個字節(jié)字符串)
Hash(哈希)
簡介:在Redis中,哈希類型是指v(值)本身又是一個鍵值對(k-v)結構 簡單使用舉例:hset key field value 、hget key field 內(nèi)部編碼:ziplist(壓縮列表) 、hashtable(哈希表) 應用場景:緩存用戶信息等。
List(列表)
簡介:列表(list)類型是用來存儲多個有序的字符串,一個列表最多可以存儲2^32-1個元素。 簡單實用舉例: lpush key value [value ...] 、lrange key start end內(nèi)部編碼:ziplist(壓縮列表)、linkedlist(鏈表) 應用場景:消息隊列,文章列表
Set(集合)
簡介:集合(set)類型也是用來保存多個的字符串元素,但是不允許重復元素 簡單使用舉例:sadd key element [element ...]、smembers key 內(nèi)部編碼:intset(整數(shù)集合)、hashtable(哈希表) 應用場景:用戶標簽,生成隨機數(shù)抽獎、社交需求。
有序集合(zset)
簡介:已排序的字符串集合,同時元素不能重復 簡單格式舉例: zadd key score member [score member ...],zrank key member底層內(nèi)部編碼:ziplist(壓縮列表)、skiplist(跳躍表) 應用場景:排行榜,社交需求(如用戶點贊)。
2.2 Redis 的三種特殊數(shù)據(jù)類型
Geo:Redis3.2推出的,地理位置定位,用于存儲地理位置信息,并對存儲的信息進行操作。 HyperLogLog:用來做基數(shù)統(tǒng)計算法的數(shù)據(jù)結構,如統(tǒng)計網(wǎng)站的UV。 Bitmaps :用一個比特位來映射某個元素的狀態(tài),在Redis中,它的底層是基于字符串類型實現(xiàn)的,可以把bitmaps成作一個以比特位為單位的數(shù)組
3. Redis有幾種持久化方式
Redis是基于內(nèi)存的非關系型K-V數(shù)據(jù)庫,既然它是基于內(nèi)存的,如果Redis服務器掛了,數(shù)據(jù)就會丟失。為了避免數(shù)據(jù)丟失了,Redis提供了持久化,即把數(shù)據(jù)保存到磁盤。
Redis提供了RDB和AOF兩種持久化機制,它持久化文件加載流程如下:

3.1 RDB
RDB,就是把內(nèi)存數(shù)據(jù)以快照的形式保存到磁盤上。
什么是快照?可以這樣理解,給當前時刻的數(shù)據(jù),拍一張照片,然后保存下來。
RDB持久化,是指在指定的時間間隔內(nèi),執(zhí)行指定次數(shù)的寫操作,將內(nèi)存中的數(shù)據(jù)集快照寫入磁盤中,它是Redis默認的持久化方式。執(zhí)行完操作后,在指定目錄下會生成一個dump.rdb文件,Redis 重啟的時候,通過加載dump.rdb文件來恢復數(shù)據(jù)。RDB觸發(fā)機制主要有以下幾種:

RDB 的優(yōu)點
適合大規(guī)模的數(shù)據(jù)恢復場景,如備份,全量復制等
RDB缺點
沒辦法做到實時持久化/秒級持久化。 新老版本存在RDB格式兼容問題
3.2 AOF
AOF(append only file) 持久化,采用日志的形式來記錄每個寫操作,追加到文件中,重啟時再重新執(zhí)行AOF文件中的命令來恢復數(shù)據(jù)。它主要解決數(shù)據(jù)持久化的實時性問題。默認是不開啟的。
AOF的工作流程如下:

AOF的優(yōu)點
數(shù)據(jù)的一致性和完整性更高
AOF的缺點
AOF記錄的內(nèi)容越多,文件越大,數(shù)據(jù)恢復變慢。
4. 多線程情況下,如何保證線程安全?
加鎖,比如悲觀鎖select for update,sychronized等,如,樂觀鎖,樂觀鎖如CAS等,還有redis分布式鎖等等。
5. 用過volatile嗎?它是如何保證可見性的,原理是什么
volatile關鍵字是Java虛擬機提供的的最輕量級的同步機制,它作為一個修飾符, 用來修飾變量。它保證變量對所有線程可見性,禁止指令重排,但是不保證原子性。
我們先來看下java內(nèi)存模型(jmm):
Java虛擬機規(guī)范試圖定義一種Java內(nèi)存模型,來屏蔽掉各種硬件和操作系統(tǒng)的內(nèi)存訪問差異,以實現(xiàn)讓Java程序在各種平臺上都能達到一致的內(nèi)存訪問效果。 Java內(nèi)存模型規(guī)定所有的變量都是存在主內(nèi)存當中,每個線程都有自己的工作內(nèi)存。這里的變量包括實例變量和靜態(tài)變量,但是不包括局部變量,因為局部變量是線程私有的。 線程的工作內(nèi)存保存了被該線程使用的變量的主內(nèi)存副本,線程對變量的所有操作都必須在工作內(nèi)存中進行,而不能直接操作操作主內(nèi)存。并且每個線程不能訪問其他線程的工作內(nèi)存。 
volatile變量,保證新值能立即同步回主內(nèi)存,以及每次使用前立即從主內(nèi)存刷新,所以我們說volatile保證了多線程操作變量的可見性。
volatile保證可見性跟內(nèi)存屏障有關。我們來看一段volatile使用的demo代碼:
public?class?Singleton?{??
????private?volatile?static?Singleton?instance;??
????private?Singleton?(){}??
????public?static?Singleton?getInstance()?{??
????if?(instance?==?null)?{??
????????synchronized?(Singleton.class)?{??
????????if?(instance?==?null)?{??
????????????instance?=?new?Singleton();??
????????}??
????????}??
????}??
????return?instance;??
????}??
}??
編譯后,對比有volatile關鍵字和沒有volatile關鍵字時所生成的匯編代碼,發(fā)現(xiàn)有volatile關鍵字修飾時,會多出一個lock addl $0x0,(%esp),即多出一個lock前綴指令,lock指令相當于一個內(nèi)存屏障
lock指令相當于一個內(nèi)存屏障,它保證以下這幾點:
重排序時不能把后面的指令重排序到內(nèi)存屏障之前的位置 將本處理器的緩存寫入內(nèi)存 如果是寫入動作,會導致其他處理器中對應的緩存無效。
第2點和第3點就是保證volatile保證可見性的體現(xiàn)嘛
6. MySQL的索引結構,聚簇索引和非聚簇索引的區(qū)別
一個表中只能擁有一個聚集索引,而非聚集索引一個表可以存在多個。 索引是通過二叉樹的數(shù)據(jù)結構來描述的,我們可以這么理解聚簇索引:索引的葉節(jié)點就是數(shù)據(jù)節(jié)點。而非聚簇索引的葉節(jié)點仍然是索引節(jié)點,只不過有一個指針指向對應的數(shù)據(jù)塊。 聚集索引:物理存儲按照索引排序;非聚集索引:物理存儲不按照索引排序
7. MySQL有幾種高可用方案,你們用的是哪一種
主從或主主半同步復制 半同步復制優(yōu)化 高可用架構優(yōu)化 共享存儲 分布式協(xié)議
7.1 主從或主主半同步復制
用雙節(jié)點數(shù)據(jù)庫,搭建單向或者雙向的半同步復制。架構如下:

通常會和proxy、keepalived等第三方軟件同時使用,即可以用來監(jiān)控數(shù)據(jù)庫的健康,又可以執(zhí)行一系列管理命令。如果主庫發(fā)生故障,切換到備庫后仍然可以繼續(xù)使用數(shù)據(jù)庫。
這種方案優(yōu)點是架構、部署比較簡單,主機宕機直接切換即可。缺點是完全依賴于半同步復制,半同步復制退化為異步復制,無法保證數(shù)據(jù)一致性;另外,還需要額外考慮haproxy、keepalived的高可用機制。
7.2 半同步復制優(yōu)化
半同步復制機制是可靠的,可以保證數(shù)據(jù)一致性的。但是如果網(wǎng)絡發(fā)生波動,半同步復制發(fā)生超時會切換為異步復制,異復制是無法保證數(shù)據(jù)的一致性的。因此,可以在半同復制的基礎上優(yōu)化一下,盡可能保證半同復制。如雙通道復制方案
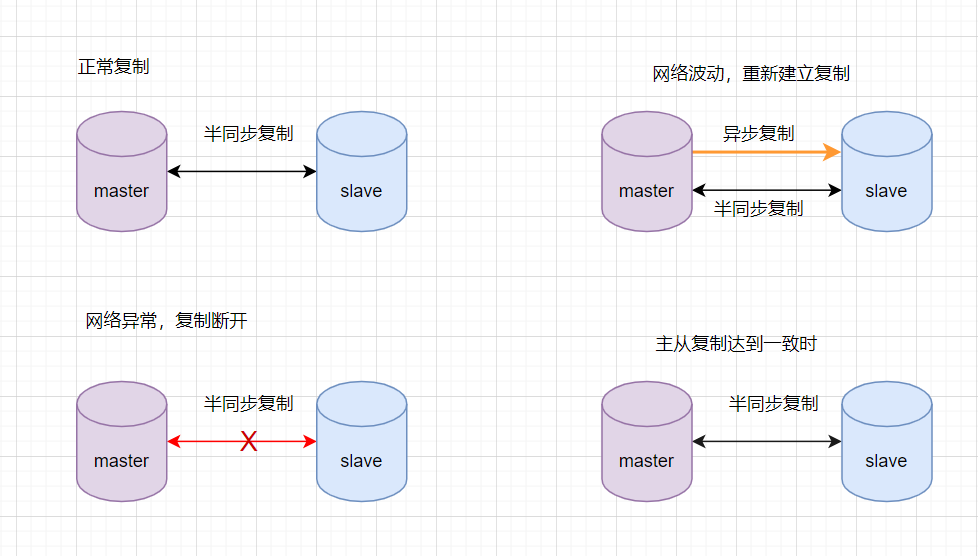
優(yōu)點:這種方案架構、部署也比較簡單,主機宕機也是直接切換即可。比方案1的半同步復制,更能保證數(shù)據(jù)的一致性。 缺點:需要修改內(nèi)核源碼或者使用mysql通信協(xié)議,沒有從根本上解決數(shù)據(jù)一致性問題。
7.3 高可用架構優(yōu)化
保證高可用,可以把主從雙節(jié)點數(shù)據(jù)庫擴展為數(shù)據(jù)庫集群。Zookeeper可以作為集群管理,它使用分布式算法保證集群數(shù)據(jù)的一致性,可以較好的避免網(wǎng)絡分區(qū)現(xiàn)象的產(chǎn)生。

優(yōu)點:保證了整個系統(tǒng)的高可用性,擴展性也較好,可以擴展為大規(guī)模集群。 缺點:數(shù)據(jù)一致性仍然依賴于原生的mysql半同步復制;引入Zookeeper使系統(tǒng)邏輯更復雜。
7.4 共享存儲
共享存儲實現(xiàn)了數(shù)據(jù)庫服務器和存儲設備的解耦,不同數(shù)據(jù)庫之間的數(shù)據(jù)同步不再依賴于MySQL的原生復制功能,而是通過磁盤數(shù)據(jù)同步的手段,來保證數(shù)據(jù)的一致性。
DRBD磁盤復制
DRBD是一個用軟件實現(xiàn)的、無共享的、服務器之間鏡像塊設備內(nèi)容的存儲復制解決方案。主要用于對服務器之間的磁盤、分區(qū)、邏輯卷等進行數(shù)據(jù)鏡像,當用戶將數(shù)據(jù)寫入本地磁盤時,還會將數(shù)據(jù)發(fā)送到網(wǎng)絡中另一臺主機的磁盤上,這樣的本地主機(主節(jié)點)與遠程主機(備節(jié)點)的數(shù)據(jù)就可以保證實時同步。常用架構如下:

當本地主機出現(xiàn)問題,遠程主機上還保留著一份相同的數(shù)據(jù),即可以繼續(xù)使用,保證了數(shù)據(jù)的安全。
優(yōu)點:部署簡單,價格合適,保證數(shù)據(jù)的強一致性 缺點:對IO性能影響較大,從庫不提供讀操作
7.5 分布式協(xié)議
分布式協(xié)議可以很好解決數(shù)據(jù)一致性問題。常見的部署方案就是MySQL cluster,它是官方集群的部署方案,通過使用NDB存儲引擎實時備份冗余數(shù)據(jù),實現(xiàn)數(shù)據(jù)庫的高可用性和數(shù)據(jù)一致性。如下:
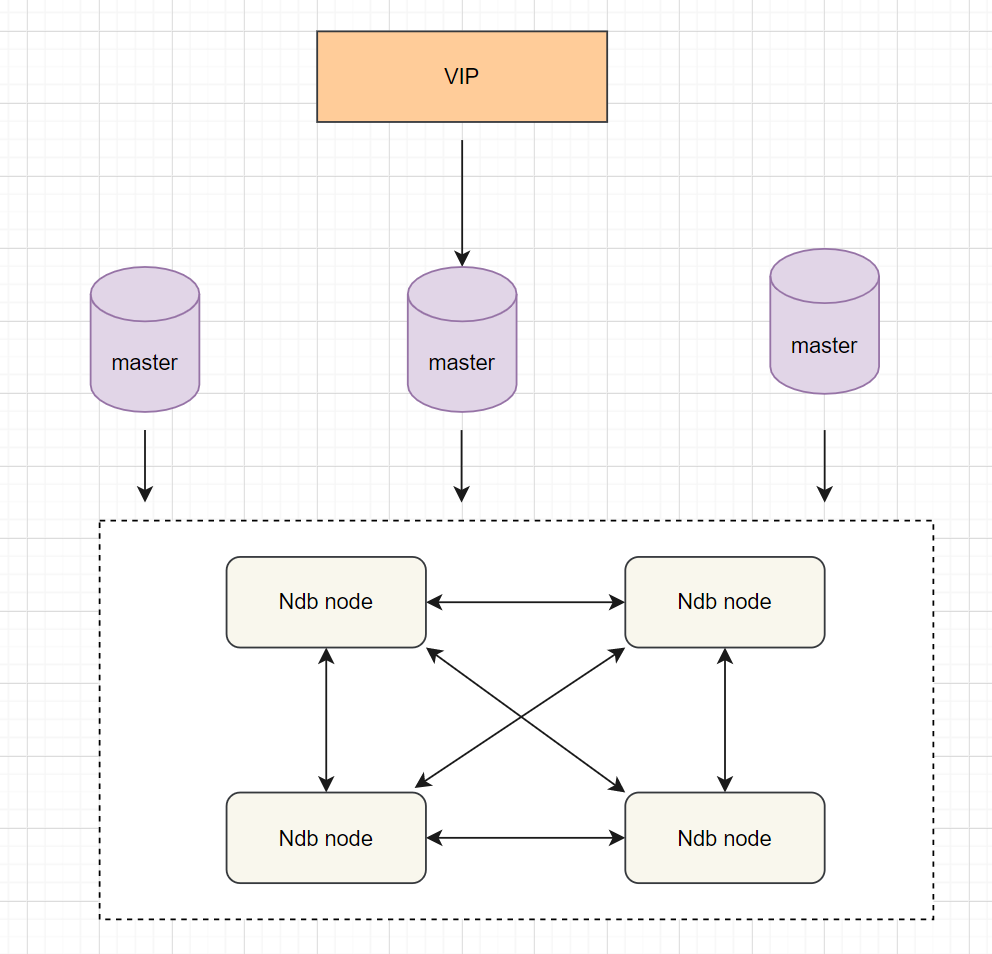
優(yōu)點:不依賴于第三方軟件,可以實現(xiàn)數(shù)據(jù)的強一致性; 缺點:配置較復雜;需要使用NDB儲存引擎;至少三節(jié)點;
8. 說說你做過最有挑戰(zhàn)性的項目, 你負責那個模塊,哪些最有挑戰(zhàn)性,說說你做了哪些優(yōu)化
項目這塊的話,大家可以結合自己實際做的項目說哈。也可以加我微信,跟我一起交流哈,加油加油。
9.秒殺采用什么方案。
設計一個秒殺系統(tǒng),需要考慮這些問題:
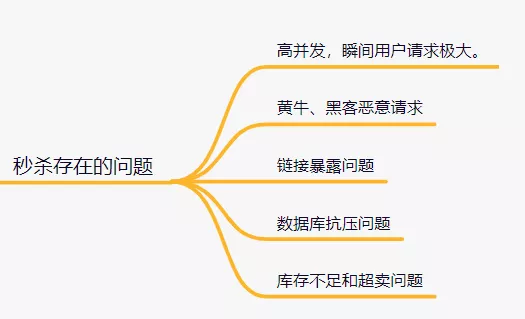
如何解決這些問題呢?
頁面靜態(tài)化 按鈕至灰控制 服務單一職責 秒殺鏈接加鹽 限流 分布式鎖 MQ異步處理 限流&降級&熔斷
9.1 頁面靜態(tài)化
秒殺活動的頁面,大多數(shù)內(nèi)容都是固定不變的,如商品名稱,商品圖片等等,可以對活動頁面做靜態(tài)化處理,減少訪問服務端的請求。秒殺用戶會分布在全國各地,有的在上海,有的在深圳,地域相差很遠,網(wǎng)速也各不相同。為了讓用戶最快訪問到活動頁面,可以使用CDN(Content Delivery Network,內(nèi)容分發(fā)網(wǎng)絡)。CDN可以讓用戶就近獲取所需內(nèi)容。
9.2 按鈕至灰控制
秒殺活動開始前,按鈕一般需要置灰的。只有時間到了,才能變得可以點擊。這是防止,秒殺用戶在時間快到的前幾秒,瘋狂請求服務器,然后秒殺時間點還沒到,服務器就自己掛了。
9.3 服務單一職責
我們都知道微服務設計思想,也就是把各個功能模塊拆分,功能那個類似的放一起,再用分布式的部署方式。
如用戶登錄相關的,就設計個用戶服務,訂單相關的就搞個訂單服務,再到禮物相關的就搞個禮物服務等等。那么,秒殺相關的業(yè)務邏輯也可以放到一起,搞個秒殺服務,單獨給它搞個秒殺數(shù)據(jù)庫。” 服務單一職責有個好處:如果秒殺沒抗住高并發(fā)的壓力,秒殺庫崩了,服務掛了,也不會影響到系統(tǒng)的其他服務。
9.4 秒殺鏈接加鹽
鏈接如果明文暴露的話,會有人獲取到請求Url,提前秒殺了。因此,需要給秒殺鏈接加鹽。可以把URL動態(tài)化,如通過MD5加密算法加密隨機的字符串去做url。
9.5 限流
一般有兩種方式限流:nginx限流和redis限流。
為了防止某個用戶請求過于頻繁,我們可以對同一用戶限流; 為了防止黃牛模擬幾個用戶請求,我們可以對某個IP進行限流; 為了防止有人使用代理,每次請求都更換IP請求,我們可以對接口進行限流。 為了防止瞬時過大的流量壓垮系統(tǒng),還可以使用阿里的Sentinel、Hystrix組件進行限流。
9.6 分布式鎖
可以使用redis分布式鎖解決超賣問題。
使用Redis的SET EX PX NX + 校驗唯一隨機值,再刪除釋放鎖。
if(jedis.set(key_resource_id,?uni_request_id,?"NX",?"EX",?100s)?==?1){?//加鎖
????try?{
????????do?something??//業(yè)務處理
????}catch(){
??}
??finally?{
???????//判斷是不是當前線程加的鎖,是才釋放
???????if?(uni_request_id.equals(jedis.get(key_resource_id)))?{
????????jedis.del(lockKey);?//釋放鎖
????????}
????}
}
在這里,判斷是不是當前線程加的鎖和釋放鎖不是一個原子操作。如果調用jedis.del()釋放鎖的時候,可能這把鎖已經(jīng)不屬于當前客戶端,會解除他人加的鎖。

為了更嚴謹,一般也是用lua腳本代替。lua腳本如下:
if?redis.call('get',KEYS[1])?==?ARGV[1]?then?
???return?redis.call('del',KEYS[1])?
else
???return?0
end;
9.7 MQ異步處理
如果瞬間流量特別大,可以使用消息隊列削峰,異步處理。用戶請求過來的時候,先放到消息隊列,再拿出來消費。
9.8 限流&降級&熔斷
限流,就是限制請求,防止過大的請求壓垮服務器; 降級,就是秒殺服務有問題了,就降級處理,不要影響別的服務; 熔斷,服務有問題就熔斷,一般熔斷降級是一起出現(xiàn)。
10. 聊聊分庫分表,分表為什么要停服這種操作,如果不停服可以怎么做
10.1 分庫分表方案
水平分庫:以字段為依據(jù),按照一定策略(hash、range等),將一個庫中的數(shù)據(jù)拆分到多個庫中。 水平分表:以字段為依據(jù),按照一定策略(hash、range等),將一個表中的數(shù)據(jù)拆分到多個表中。 垂直分庫:以表為依據(jù),按照業(yè)務歸屬不同,將不同的表拆分到不同的庫中。 垂直分表:以字段為依據(jù),按照字段的活躍性,將表中字段拆到不同的表(主表和擴展表)中。
10.2 常用的分庫分表中間件:
sharding-jdbc(當當) Mycat TDDL(淘寶) Oceanus(58同城數(shù)據(jù)庫中間件) vitess(谷歌開發(fā)的數(shù)據(jù)庫中間件) Atlas(Qihoo 360)
10.3 分庫分表可能遇到的問題
事務問題:需要用分布式事務啦 跨節(jié)點Join的問題:解決這一問題可以分兩次查詢實現(xiàn) 跨節(jié)點的count,order by,group by以及聚合函數(shù)問題:分別在各個節(jié)點上得到結果后在應用程序端進行合并。 數(shù)據(jù)遷移,容量規(guī)劃,擴容等問題 ID問題:數(shù)據(jù)庫被切分后,不能再依賴數(shù)據(jù)庫自身的主鍵生成機制啦,最簡單可以考慮UUID 跨分片的排序分頁問題(后臺加大pagesize處理?)
10.4 分表要停服嘛?不停服怎么做?
不用。不停服的時候,應該怎么做呢,分五個步驟:
編寫代理層,加個開關(控制訪問新的DAO還是老的DAO,或者是都訪問),灰度期間,還是訪問老的DAO。 發(fā)版全量后,開啟雙寫,既在舊表新增和修改,也在新表新增和修改。日志或者臨時表記下新表ID起始值,舊表中小于這個值的數(shù)據(jù)就是存量數(shù)據(jù),這批數(shù)據(jù)就是要遷移的。 通過腳本把舊表的存量數(shù)據(jù)寫入新表。 停讀舊表改讀新表,此時新表已經(jīng)承載了所有讀寫業(yè)務,但是這時候不要立刻停寫舊表,需要保持雙寫一段時間。 當讀寫新表一段時間之后,如果沒有業(yè)務問題,就可以停寫舊表啦
11. redis掛了怎么辦?
Redis是基于內(nèi)存的非關系型K-V數(shù)據(jù)庫,既然它是基于內(nèi)存的,如果Redis服務器掛了,數(shù)據(jù)就會丟失。為了避免數(shù)據(jù)丟失了,Redis提供了持久化,即把數(shù)據(jù)保存到磁盤。
Redis提供了RDB和AOF兩種持久化機制,它持久化文件加載流程如下:
11.1 RDB
RDB,就是把內(nèi)存數(shù)據(jù)以快照的形式保存到磁盤上。
什么是快照? 可以這樣理解,給當前時刻的數(shù)據(jù),拍一張照片,然后保存下來。
RDB持久化,是指在指定的時間間隔內(nèi),執(zhí)行指定次數(shù)的寫操作,將內(nèi)存中的數(shù)據(jù)集快照寫入磁盤中,它是Redis默認的持久化方式。執(zhí)行完操作后,在指定目錄下會生成一個dump.rdb文件,Redis 重啟的時候,通過加載dump.rdb文件來恢復數(shù)據(jù)。RDB觸發(fā)機制主要有以下幾種:
RDB 的優(yōu)點
適合大規(guī)模的數(shù)據(jù)恢復場景,如備份,全量復制等
RDB缺點
沒辦法做到實時持久化/秒級持久化。 新老版本存在RDB格式兼容問題
11.2 AOF
AOF(append only file) 持久化,采用日志的形式來記錄每個寫操作,追加到文件中,重啟時再重新執(zhí)行AOF文件中的命令來恢復數(shù)據(jù)。它主要解決數(shù)據(jù)持久化的實時性問題。默認是不開啟的。
AOF的工作流程如下:
AOF的優(yōu)點
數(shù)據(jù)的一致性和完整性更高
AOF的缺點
AOF記錄的內(nèi)容越多,文件越大,數(shù)據(jù)恢復變慢。
12.你怎么防止優(yōu)惠券有人重復刷?
對于重復請求,要考慮接口冪等和接口防重。
大家可以看下之前我寫的這篇文章哈:聊聊冪等設計
防刷的話,可以限流以及加入黑名單處理。
為了防止某個用戶請求優(yōu)惠券過于頻繁,我們可以對同一用戶限流。 為了防止黃牛等模擬幾個用戶請求,我們可以對某個IP進行限流。 為了防止有人使用代理,每次請求都更換IP請求,我們可以對接口進行限流。
13. 抖音評論系統(tǒng)怎么設計,如果加入好友關系呢?
需要考慮性能,以及可擴展性。大家平時有沒有做過評論、好友關注等項目需求呀,發(fā)揮你聰明的小腦袋瓜,怎么去回答好這道題吧。
14. 怎么設計一個短鏈地址,要考慮跨機房部署問題
14.1 為什么需要短連接?
為什么需要短連接呢?長鏈接不香嗎?因為有些平臺有長度限制,并且鏈接太長容易被識別為超鏈接等等。
14.2 短鏈接的原理
其實就是一個302重定向而已。
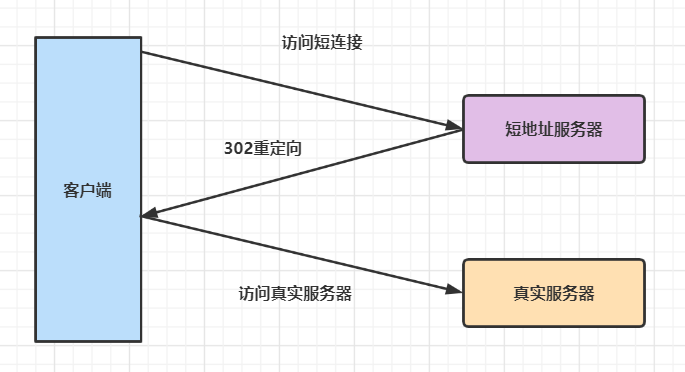
302狀態(tài)碼表示臨時重定向。
14.3 短鏈接生成的方法
可以用哈希算法生成短鏈,但是會存在哈希沖突。怎么解決呢?可以用布隆過濾器。
有沒有別的方案?自增序列算法,每次收到一個長鏈時,就分配一個ID,并轉成62進制拼接到短域后面。因為高并發(fā)下,ID 自增生成器可能成為瓶頸。
一般有四種分布式ID生成方法:
uuid,它保證對在同一時空中的所有機器都是唯一的,但是這種方式生成的id比較長,并且是無序的,插入浪費空間。 Snowflake雪花算法,這種方案不錯,但是如果某臺機器的系統(tǒng)時鐘回撥,有可能造成ID沖突重復,或者ID亂序(考慮跨機房部署問題) Mysql 自增主鍵,在高并發(fā)下,db的寫壓力會很大 用Redis做自增id生成器,性能高,但要考慮持久性的問題;或者改造雪花算法,通過改造workId解決時鐘回撥的問題)
15.有一個整型數(shù)組,數(shù)組元素不重復,數(shù)組元素先升序后降序,找出最大值。
例如:1,3,5,7,9,8,6,4,2,請寫一個函數(shù)找出數(shù)組最大的元素
這道題大家都會覺得很簡單,因為用快速排序排一下,時間復雜是O(nlgn),面試官可能不是很滿意。其實可以用二分查找法,只要找到升序最后一個元素即可。
我們以1,6,5,4,2為例子,用二分法圖解一下哈:
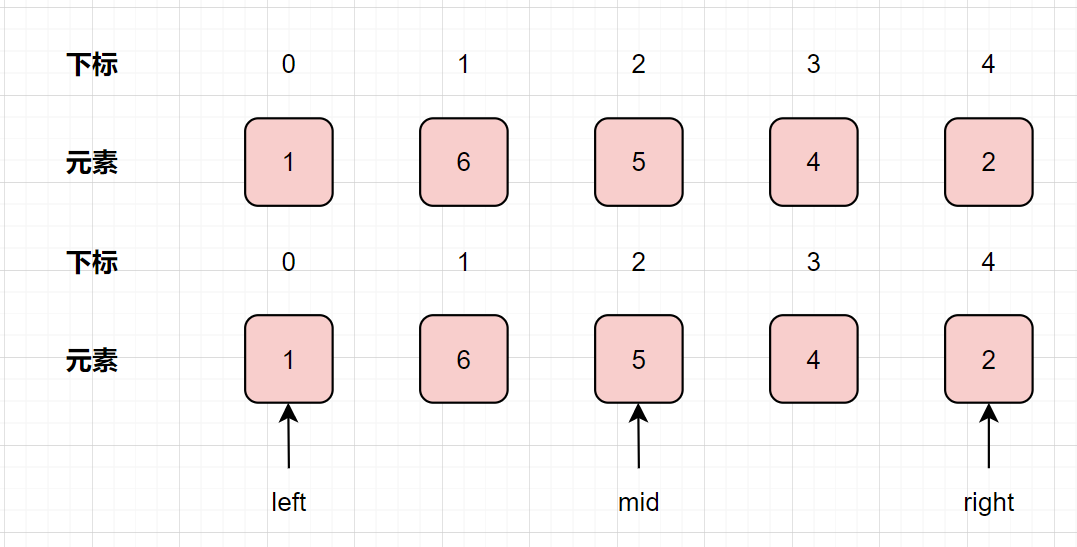
如何用二分法縮小空間呢?只要比較中間元素與其下一個元素大小即可
如果中間元素大于其下一個元素大小,證明最大值在左側,因此右指針左移 如果中間元素小于其下一個元素大小,證明最大值在左側,因此右指針左移
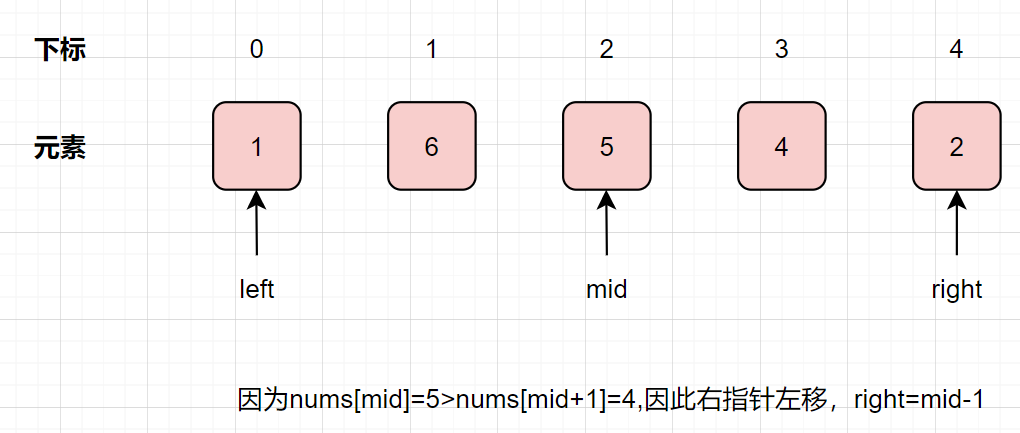
因為nums[mid]=5>nums[mid+1]=4,因此右指針左移,right=mid-1=2-1=1
mid = left+ (right-left)/2=left=0,因為nums[mid]=1left = mid+1=1;

最后得出最大值是nums[left] =nums[1]=6
實現(xiàn)代碼如下:
class?Solution?{
????public?static?void?main(String[]?args)?{
????????int[]?nums?=?{1,3,5,7,9,8,6,4,2};
????????System.out.println(getLargestNumInArray(nums));
????}
????private?static?int?getLargestNumInArray(int[]?nums)?{
????????if?(nums?==?null?||?nums.length?==?0)?{
????????????return?-1;
????????}
????????int?left?=?0,?right?=?nums.length?-?1;
????????while?(left?<=?right)?{
????????????int?mid?=?left?+?((right?-?left)?/?2);
????????????if?(nums[mid]?????????????????left?=?mid?+?1;
????????????}?else?{
????????????????right?=?mid?-?1;
????????????}
????????}
????????return?nums[left];
????}
}