
利用Python將Word試卷匹配轉換為Excel表格
回復“書籍”即可獲贈Python從入門到進階共10本電子書
需求
有一個下面這種形式的word表格:

希望能轉換為下面這種格式的excel表格:

測試word文檔讀取
先測試一個word文檔前1頁的數(shù)據(jù)讀取:
from docx import Document
doc = Document("編號02 質檢員高級技師(一級)理論試卷.docx")
for i, paragraph in enumerate(doc.paragraphs[:55]):
print(i, paragraph.text)
0 職業(yè)能力評價理論試卷
1 (一級. 質檢員)
2 注意事項:1.答卷前將密封線內的項目填寫清楚。
3 2.填寫答案必須用藍色(或黑色)鋼筆、圓珠筆,不許用鉛筆或紅筆。
4 3.本份試卷共四道大題,滿分100分,考試時間120分鐘。
5 一、單項選擇題(第1~40題。選擇正確的答案,將相應的字母填入題內的括號中。每題1分,滿分40分。)
6 1. 關于道德的敘述,正確的是( )。
7 (A)道德中的“應該”與“不應該”因人而異,沒有共同道德標準
8 (B)道德是處理人與人之間、人與社會之間關系的特殊行為規(guī)范
9 (C)道德是現(xiàn)代文明的產(chǎn)物
10 (D)道德從來沒有階級性
11 2.以下哪個選項不屬于遵守職業(yè)紀律( )。
12 (A)右側行駛 (B)客人先行 (C)先抑后揚 (D)下班鎖門
13 3. 國際標準化組織ISO9000:2000標準中,把質量定義為一組( )特性滿足要求的程度。
14 (A)常量 (B)變量 (C) 流動 (D)固有
15 4. 軟件是有通過載體表達的信息所組成的( )產(chǎn)品。
16 (A)知識 (B)信息 (C)數(shù)據(jù) (D)標準
17 5. ( )是指由最高管理者正式發(fā)布的與質量有關的組織總的意圖和方向。
18 (A)質量目標 (B)質量方針 (C)質量管理 (D)質量控制
19 6. ISO9000族當中,( )和八項管理原則一直是最核心的內容。
20 (A)PCDA模式 (B)PCDA循環(huán) (C)PDCA模式 (D)PDCA循環(huán)
21 7.( )是第一家實施六西格瑪管理的公司。
22 (A)通用電氣 (B)摩托羅拉
23 (C)豐田 (D)微軟
24 8. 產(chǎn)生、形成、實現(xiàn)、使用和衰亡的過程,質量專家朱蘭稱質量形成的這種過程為( )。
25 (A)質量螺旋 (B)質量周期 (C)產(chǎn)品螺旋 (D)產(chǎn)品周期
26 9. 計量值數(shù)據(jù)是指可以連續(xù)取值的數(shù)據(jù),又稱( )數(shù)據(jù)。
27 (A)計量型 (B)連續(xù)型 (C)穩(wěn)定型 (D)常規(guī)型
28 10. 國家標準當中強制性標準用( )指代含義。
29 (A)CCC (B)GB (C)GB/T (D)CCIB
30 11. 異常波動能引起系統(tǒng)性的( )。
31 (A)失誤或停滯 (B) 錯誤或中斷 (C) 失效或缺陷 (D) 失敗或終止
32 12.( )是判斷和預報生產(chǎn)過程中質量狀況是否發(fā)生波動的一種有效方法。
33 (A)分布圖 (B) 質量圖 (C) 控制圖 (D) 控制界限
34 13. 過程能力一般采用標準差的6倍即6σ來量度,其計算公式為( )。
35 (A)B=6σ≈6S=24(R/dn) (B)B=6σ≈6S=12(R/d?)
36 (C)B=6σ≈6S=6(R/dn) (D)B=6σ≈6S=6(R/d?)
37 14. 提高過程能力的重要途徑之一就是盡量減少σ,使質量特征值的離散程度( )。
38 (A)變大 (B)變小 (C)平穩(wěn) (D)不變
39 15.( )亦稱頻數(shù)分布圖,它適用于對大量計量值數(shù)數(shù)據(jù)進行整理加工,找出其統(tǒng)計規(guī)律。
40 (A)直方圖 (B)散布圖
41 (C)排列圖 (D)控制圖
42 16. 因素在實驗中所處的狀態(tài)和條件變化可能引起指標變動,把因素變化各種狀態(tài)和條件成為因素的( )。
43 (A)因子 (B)位級 (C)強度 (D)狀態(tài)
44 17. 1988年提出的一種確定客戶需求和相應產(chǎn)品或服務性能之間聯(lián)系的圖示方法叫做( )。
45 (A)質量屋 (B)顧客需求 (C)技術要求 (D)關系矩陣
46 18. ( )是指產(chǎn)品在存放和使用過程中,隨著時間的推移而直接影響產(chǎn)品質量特性穩(wěn)定性的因素。
47 (A)外噪聲 (B)內噪聲 (C)隨機噪聲 (D)以上都不對·
48 19. ( )是產(chǎn)品設計的核心,在系統(tǒng)設計確定了產(chǎn)品或系統(tǒng)的目的功能及結構之后進行。
49 (A)參數(shù)設計 (B)常量設計 (C)變量設計 (D)系統(tǒng)設計
50 20. 以下不屬于“雙五歸零”基本術語的是( )。
51 (A)質量問題 (B)質量缺陷
52 (C)重復性質量問題 (D)產(chǎn)品交付前的質量問題
53 21. 質量檢驗當中,( )可以保證工藝過程的質量符合性。
54 (A)進貨檢驗 (B)過程檢驗 (C)工藝檢驗 (D)最終檢驗從讀取效果上看,各行文本數(shù)據(jù)都能很順利的獲取到。
匹配題型、題目和具體的選項
現(xiàn)在我們需要做的是就是匹配題型、題目和具體的選項,觀察可以發(fā)現(xiàn)規(guī)律:
題型以大寫數(shù)字開頭 題目以普通數(shù)字+.開頭 選項以括號+字母開頭
?額外需要注意的:
?
開頭幾行文本也存在普通數(shù)字+.開頭的,需要直接排除。 第7題的題目,和第19題的選項存在一些特殊的空白字符需要排除, 括號和小數(shù)點都同時存在半角和全角兩種情況。
對于需要注意的第二點:
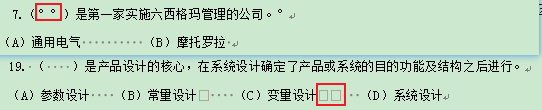
查看一下這2處的空白字符:
doc.paragraphs[21].text
'7.(\xa0\xa0)是第一家實施六西格瑪管理的公司。\xa0'doc.paragraphs[49].text
'(A)參數(shù)設計 (B)常量設計\u3000 (C)變量設計\u3000\u3000 (D)系統(tǒng)設計'發(fā)現(xiàn)分別是\xa0和\u3000。
整理好大致思路,我組織一下處理代碼:
import re
from docx import Document
doc = Document("編號02 質檢員高級技師(一級)理論試卷.docx")
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
# 從word文檔的“一、單項選擇題”開始遍歷數(shù)據(jù)
for paragraph in doc.paragraphs[5:25]:
# 去除空白字符,將全角字符轉半角字符,并給括號之間調整為中間二個空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 對于空白行就直接跳過
if not line:
continue
if title_rule.match(line):
print("題目", line)
elif option_rule.match(line):
print("選項", option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
print("題型", chinese_nums_match.group(1))
題型 單項選擇題
題目 1.關于道德的敘述,正確的是( )。
選項 ['(A)道德中的“應該”與“不應該”因人而異,沒有共同道德標準']
選項 ['(B)道德是處理人與人之間、人與社會之間關系的特殊行為規(guī)范']
選項 ['(C)道德是現(xiàn)代文明的產(chǎn)物']
選項 ['(D)道德從來沒有階級性']
題目 2.以下哪個選項不屬于遵守職業(yè)紀律( )。
選項 ['(A)右側行駛', '(B)客人先行', '(C)先抑后揚', '(D)下班鎖門']
題目 3.國際標準化組織ISO9000:2000標準中,把質量定義為一組( )特性滿足要求的程度。
選項 ['(A)常量', '(B)變量', '(C)流動', '(D)固有']
題目 4.軟件是有通過載體表達的信息所組成的( )產(chǎn)品。
選項 ['(A)知識', '(B)信息', '(C)數(shù)據(jù)', '(D)標準']
題目 5.( )是指由最高管理者正式發(fā)布的與質量有關的組織總的意圖和方向。
選項 ['(A)質量目標', '(B)質量方針', '(C)質量管理', '(D)質量控制']
題目 6.ISO9000族當中,( )和八項管理原則一直是最核心的內容。
選項 ['(A)PCDA模式', '(B)PCDA循環(huán)', '(C)PDCA模式', '(D)PDCA循環(huán)']
題目 7.( )是第一家實施六西格瑪管理的公司。
選項 ['(A)通用電氣', '(B)摩托羅拉']
選項 ['(C)豐田', '(D)微軟']
題目 8.產(chǎn)生、形成、實現(xiàn)、使用和衰亡的過程,質量專家朱蘭稱質量形成的這種過程為( )。從目前測試結果來看沒有問題。
保存匹配到的數(shù)據(jù)到結構化字典
現(xiàn)在我打算將當前匹配出來的文本數(shù)據(jù)存儲成字典形式的結構化數(shù)據(jù),字典結構的設計如下: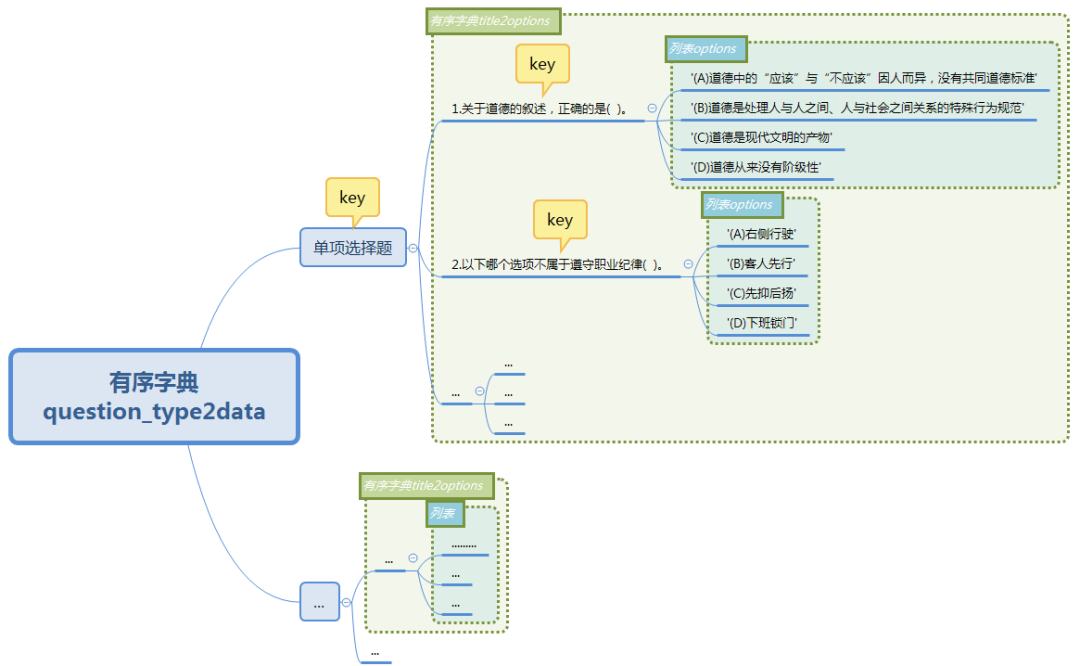
根據(jù)上述設計完善代碼:
import re
from docx import Document
from collections import OrderedDict
doc = Document("編號02 質檢員高級技師(一級)理論試卷.docx")
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
# 保存最終的結構化數(shù)據(jù)
question_type2data = OrderedDict()
# 從word文檔的“一、單項選擇題”開始遍歷數(shù)據(jù)
for paragraph in doc.paragraphs[5:]:
# 去除空白字符,將全角字符轉半角字符,并給括號之間調整為中間一個空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 對于空白行就直接跳過
if not line:
continue
if title_rule.match(line):
options = title2options.setdefault(line, [])
elif option_rule.match(line):
options.extend(option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
question_type = chinese_nums_match.group(1)
title2options = question_type2data.setdefault(question_type, OrderedDict())
遍歷結構化字典并存儲
然后我們遍歷結構化字典,將數(shù)據(jù)保存到pandas對象中:
import pandas as pd
result = []
max_options_len = 0
for question_type, title2options in question_type2data.items():
for title, options in title2options.items():
result.append([question_type, title, *options])
options_len = len(options)
if options_len > max_options_len:
max_options_len = options_len
df = pd.DataFrame(result, columns=[
"題型", "題目"]+[f"選項{i}" for i in range(1, max_options_len+1)])
# 題型可以簡化下,去掉選擇兩個字
df['題型'] = df['題型'].str.replace("選擇", "")
df.head()
結果:
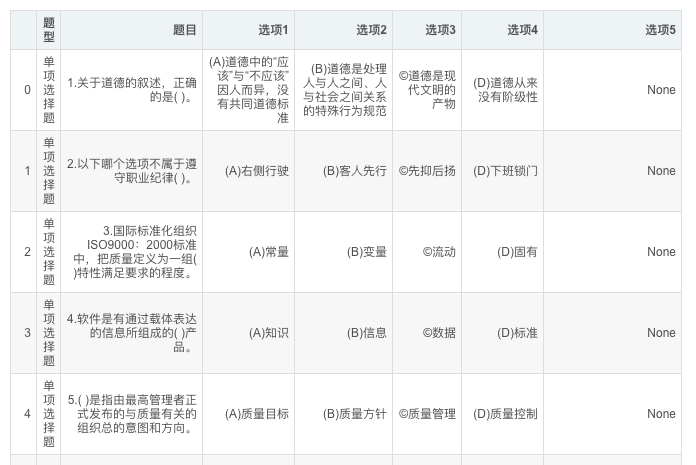
最終保存結果:
df.to_excel("result.xlsx", index=False)
完整代碼
最終完整代碼:
import pandas as pd
import re
from docx import Document
from collections import OrderedDict
doc = Document("編號02 質檢員高級技師(一級)理論試卷.docx")
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
# 保存最終的結構化數(shù)據(jù)
question_type2data = OrderedDict()
# 從word文檔的“一、單項選擇題”開始遍歷數(shù)據(jù)
for paragraph in doc.paragraphs[5:]:
# 去除空白字符,將全角字符轉半角字符,并給括號之間調整為中間一個空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )")
# 對于空白行就直接跳過
if not line:
continue
if title_rule.match(line):
options = title2options.setdefault(line, [])
elif option_rule.match(line):
options.extend(option_rule_search.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
question_type = chinese_nums_match.group(1)
title2options = question_type2data.setdefault(
question_type, OrderedDict())
result = []
max_options_len = 0
for question_type, title2options in question_type2data.items():
for title, options in title2options.items():
result.append([question_type, title, *options])
options_len = len(options)
if options_len > max_options_len:
max_options_len = options_len
df = pd.DataFrame(result, columns=[
"題型", "題目"]+[f"選項{i}" for i in range(1, max_options_len+1)])
# 題型可以簡化下,去掉選擇兩個字
df['題型'] = df['題型'].str.replace("選擇", "")
df.to_excel("result.xlsx", index=False)
最終得到的文件:
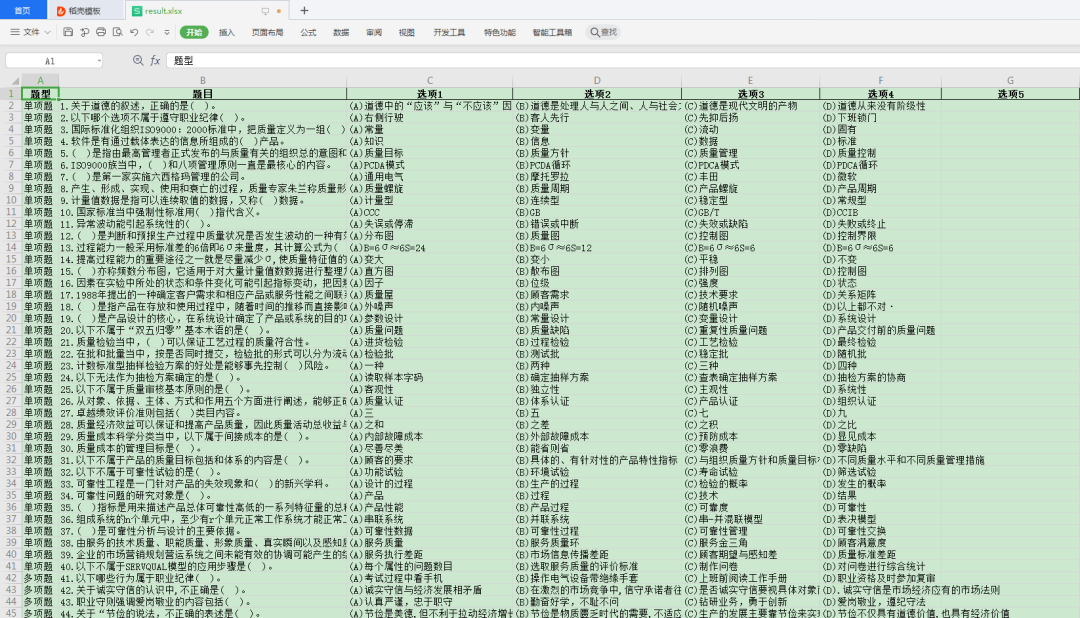
------------------- End -------------------
往期精彩文章推薦:
一篇文章帶你解鎖Python庫中操作系統(tǒng)級別模塊psutil
(Python實戰(zhàn)文)一篇文章教會你Arrow 時間庫在項目中的實際應用
一篇文章帶你了解Django ORM操作(高端篇)

歡迎大家點贊,留言,轉發(fā),轉載,感謝大家的相伴與支持
想加入Python學習群請在后臺回復【入群】
萬水千山總是情,點個【在看】行不行
/今日留言主題/
隨便說一兩句吧~~
評論
圖片
表情