
利用Python快速提取字體子集
添加微信號 " CNFeffery "加入技術(shù)交流群
?本文完整示例代碼及文件已上傳至我的
?Github倉庫https://github.com/CNFeffery/PythonPracticalSkills
大家好我是費(fèi)老師,這是我的系列文章「Python實(shí)用秘技」的第16期,本系列立足于筆者日常工作中使用Python積累的心得體會,每一期為大家?guī)硪粋€幾分鐘內(nèi)就可學(xué)會的簡單小技巧。
作為系列第16期,我們即將學(xué)習(xí)的是:快速提取字體子集。

在我們?nèi)粘_M(jìn)行數(shù)據(jù)可視化、web應(yīng)用開發(fā)等場景中,經(jīng)常會用到一些特殊的非系統(tǒng)自帶字體,尤其是中文字體,由于包含的字符數(shù)量眾多,因此體積一般都比較大,這在進(jìn)行數(shù)據(jù)可視化讀取字體文件,或是網(wǎng)頁應(yīng)用中通過網(wǎng)絡(luò)加載字體文件時,就會帶來更多的耗時。
而我們完全可以針對字體文件運(yùn)用“按需引入”的思想,從原始的體積較大的全量字體文件中,根據(jù)我們實(shí)際使用到的文字范圍,進(jìn)行子集的提取,從而大幅度提升效率。
我們可以利用Python中的fonttools庫來快捷實(shí)現(xiàn)此項需求,它由谷歌開源,自帶了若干實(shí)用的字體處理相關(guān)命令行工具,使用pip install fonttools安裝完成后,我們只需要按照下列格式執(zhí)行命令行工具pyftsubset即可:
pyftsubset 原始字體文件路徑 --text=需要保留的字符 --output-file=輸出子集字體文件路徑
而當(dāng)我們需要進(jìn)行保留的字符眾多時,則可以通過書寫Python腳本的方式,批量拼接命令行進(jìn)行模擬執(zhí)行:
import os
import re
# 讀入目標(biāo)文本內(nèi)容
with open('./將進(jìn)酒.txt', encoding='utf-8') as t:
source_content = t.read()
# 模擬執(zhí)行pyftsubset命令生成字體子集
os.system(
'pyftsubset 鐘齊志莽行書.ttf --text={} --output-file=鐘齊志莽行書mini.ttf'.format(
# 去除空白字符后去重
''.join(set(re.sub('\s', '', source_content)))
)
)
通過上面的示例代碼,我們從本地原體積為4698kb的字體文件中,提取出大小僅有76kb的目標(biāo)子集字體文件:
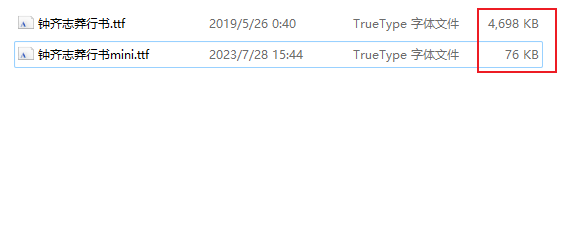
在此基礎(chǔ)上,我們就可以在項目中「大幅度」優(yōu)化外部字體的使用效率??,譬如下面的示例dash應(yīng)用(相關(guān)源碼及文件已上傳至文章開頭倉庫):

本期分享結(jié)束,咱們下回見~??
加入知識星球 【我們談?wù)摂?shù)據(jù)科學(xué)】
600+ 小伙伴一起學(xué)習(xí)!
· 推薦閱讀 ·
邊玩游戲邊學(xué)Git?這個開源網(wǎng)站我愛了
在Python中將markdown轉(zhuǎn)換為漂亮的網(wǎng)頁