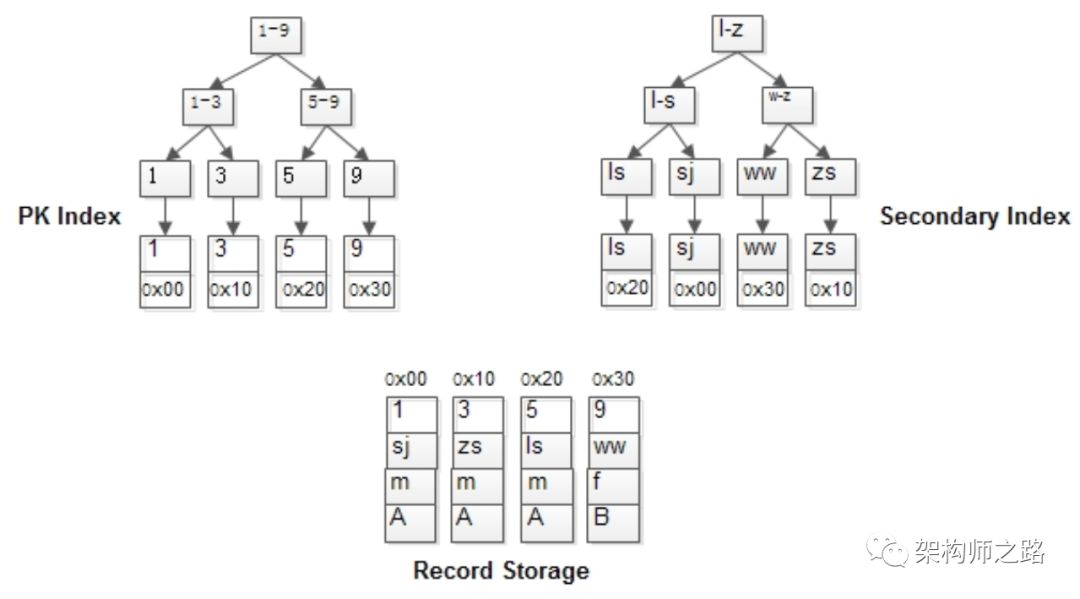
《數(shù)據(jù)庫索引,終于懂了》介紹了為什么B+樹適合做數(shù)據(jù)庫索引,數(shù)據(jù)庫的索引分為主鍵索引(Primary Inkex)與普通索引(Secondary Index)。InnoDB和MyISAM是怎么利用B+樹來實現(xiàn)這兩類索引,其又有什么差異呢?MyISAM的索引與行記錄是分開存儲的,叫做非聚集索引(UnClustered Index)。(1)有連續(xù)聚集的區(qū)域單獨存儲行記錄;(2)主鍵索引的葉子節(jié)點,存儲主鍵,與對應行記錄的指針;(3)普通索引的葉子結點,存儲索引列,與對應行記錄的指針;主鍵索引與普通索引是兩棵獨立的索引B+樹,通過索引列查找時,先定位到B+樹的葉子節(jié)點,再通過指針定位到行記錄。t(id PK, name KEY, sex, flag);1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
(2)id為PK,有一棵id的索引樹,葉子指向行記錄;(3)name為KEY,有一棵name的索引樹,葉子也指向行記錄;InnoDB的主鍵索引與行記錄是存儲在一起的,故叫做聚集索引(Clustered Index):(2)主鍵索引的葉子節(jié)點,存儲主鍵,與對應行記錄(而不是指針);(2)如果表沒有定義PK,則第一個非空unique列是聚集索引;(3)否則,InnoDB會創(chuàng)建一個隱藏的row-id作為聚集索引;
聚集索引,也只能夠有一個,因為行數(shù)據(jù)在物理磁盤上只能有一份聚集存儲。InnoDB的普通索引可以有多個,它與聚集索引是不同的:(1)普通索引的葉子節(jié)點,存儲主鍵(也不是指針);InnoDB由于數(shù)據(jù)行與索引一體,如果使用趨勢遞增主鍵,插入記錄時,不會索引分裂,不會大量行記錄移動。假設有一個用戶中心場景,包含身份證號,身份證MD5,姓名,出生年月等業(yè)務屬性,這些屬性上均有查詢需求,并且有事務需求,必須使用InnoDB存儲引擎。
此時,如何來設計數(shù)據(jù)表呢?(1)身份證作為主鍵;
(2)其他屬性上建立索引;
id_md5(index),
name(index),
birthday(index));
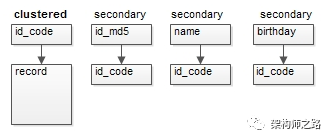
(1)id_code聚集索引,關聯(lián)行記錄;
(2)其他索引,存儲id_code屬性值;
身份證號id_code是一個比較長的字符串,每個索引都存儲這個值,在數(shù)據(jù)量大,內存珍貴的情況下,MySQL有限的緩沖區(qū),存儲的索引與數(shù)據(jù)會減少,磁盤IO的概率會增加。
此時,應該新增一個無業(yè)務含義的id自增列:(1)以id自增列為聚集索引,關聯(lián)行記錄;
(2)其他索引,存儲id值;
user(id PK auto inc,
id_code(index),
id_md5(index),
name(index),
birthday(index));
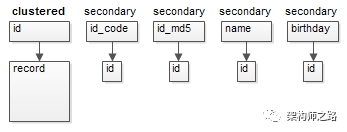
如此一來,有限的緩沖區(qū),能夠緩沖更多的索引與行數(shù)據(jù),磁盤IO的頻率會降低,整體性能會增加。InnoDB為何不宜使用較長的列作為主鍵,這下懂了吧?問題5:InnoDB的普通索引存儲主鍵鍵值,可能存在什么問題?使用普通索引查詢時,可能出現(xiàn)回表查詢。t(id PK, name KEY, sex, flag);
畫外音:id是聚集索引,name是普通索引。
表中有四條記錄:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
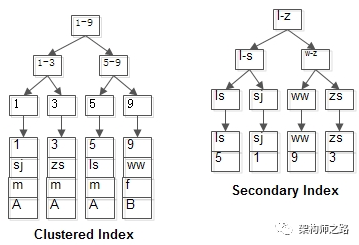
兩個B+樹索引分別如上圖:
(1)id為PK,聚集索引,葉子節(jié)點存儲行記錄;
(2)name為KEY,普通索引,葉子節(jié)點存儲PK值,即id;
既然從普通索引無法直接定位行記錄,那普通索引的查詢過程是怎么樣的呢?
通常情況下,需要掃碼兩遍索引樹。
例如:
select id,name,sex from t where name='lisi';
是如何執(zhí)行的呢?
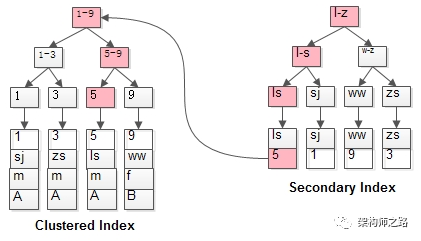
如粉紅色路徑,需要掃碼兩遍索引樹:
(1)先通過普通索引定位到主鍵值id=5;
(2)在通過聚集索引定位到行記錄;
這就是所謂的回表查詢,先定位主鍵值,再定位行記錄,它的性能較掃一遍索引樹更低。
問題6:如何優(yōu)化回表查詢?
常見的解決方案是覆蓋索引。
什么是索引覆蓋(Covering index)?
額,樓主并沒有在MySQL的官網找到這個概念。
畫外音:治學嚴謹吧?
借用一下SQL-Server官網的說法。

MySQL官網,類似的說法出現(xiàn)在explain查詢計劃優(yōu)化章節(jié),即explain的輸出結果Extra字段為Using index時,能夠觸發(fā)索引覆蓋。

不管是SQL-Server官網,還是MySQL官網,都表達了:只需要在一棵索引樹上就能獲取SQL所需的所有列數(shù)據(jù),無需回表,速度更快。
如何實現(xiàn)索引覆蓋?
常見的方法是:將被查詢的字段,建立到聯(lián)合索引里去。
對于查詢需求
select id,name,sex from t where name='lisi';
將單列索引(name)升級為聯(lián)合索引(name, sex),即可避免回表。
畫外音:屬性sex不用到聚集索引查詢了。MyISAM和InnoDB都使用B+樹來實現(xiàn)索引:(1)MyISAM的索引與數(shù)據(jù)分開存儲;(2)MyISAM的索引葉子節(jié)點存儲指針,主鍵索引與普通索引無太大區(qū)別;(3)InnoDB的聚集索引和行數(shù)據(jù)統(tǒng)一存儲;(4)InnoDB的聚集索引存儲數(shù)據(jù)行本身,普通索引存儲主鍵;(6)InnoDB普通索引可能存在回表查詢,常見的解決方案是覆蓋索引;架構師之路-分享可落地的架構文章
頻繁插入的場景,MyISAM和InnoDB誰更適合?