
為什么說Heatmap方法是分類問題?
如果這篇文章對(duì)你有所幫助,也歡迎給我點(diǎn)個(gè)贊支持一下~
0. 分類問題
說到分類問題,應(yīng)該是大部分同學(xué)入門深度學(xué)習(xí)時(shí)最早接觸的任務(wù)了,常見的如MNIST和ImageNet數(shù)據(jù)集上進(jìn)行分類,模型需要輸入一張圖片,然后預(yù)測(cè)該圖片屬于哪一個(gè)類別。
對(duì)于這類問題,目前非常成熟的做法是:讓網(wǎng)絡(luò)在倒數(shù)第二層輸出一個(gè)任意長(zhǎng)度的一維特征,然后在最后一層放一個(gè)全連接層,將倒數(shù)第二層輸出的一維特征,線性變換成一個(gè)長(zhǎng)度為N的一維向量,N對(duì)應(yīng)了數(shù)據(jù)集的類別數(shù),對(duì)這個(gè)一維向量做Softmax歸一化后,用CrossEntropy即交叉熵作為損失函數(shù)進(jìn)行訓(xùn)練。而在推理時(shí),則是對(duì)Softmax歸一化的結(jié)果取argmax,得到分?jǐn)?shù)最高的那一項(xiàng)的位置,視為網(wǎng)絡(luò)的預(yù)測(cè)結(jié)果,而該位置上的分?jǐn)?shù),則視為分類的置信度(當(dāng)然,如果不需要置信度的話,連Softmax也不需要,因?yàn)镾oftmax不改變最大值的位置)。
以上過程可以用這個(gè)圖來描述:
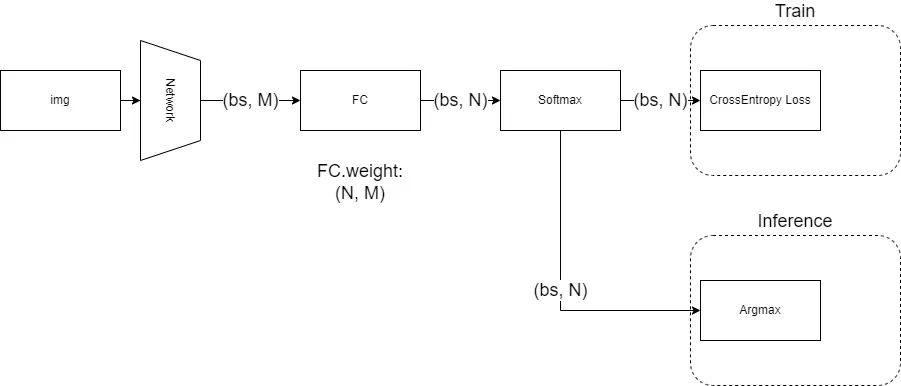
對(duì)于MNIST和ImageNet而言,我們做的都是單標(biāo)簽分類問題,也就是說,一張圖只會(huì)對(duì)應(yīng)一個(gè)類別,在網(wǎng)絡(luò)訓(xùn)練時(shí),我們訓(xùn)練的監(jiān)督信號(hào)實(shí)際上是一個(gè)one-hot向量,即形如:[0 0 0 1 0 0],在目標(biāo)類的位置上為1,其他位置為0。
由于我們是用Softmax歸一化后的結(jié)果去擬合以上one-hot向量,所以實(shí)際上這個(gè)監(jiān)督信號(hào)的意思是,目標(biāo)類的置信度100%,其他位置為0%,要求網(wǎng)絡(luò)去學(xué)習(xí)這樣的一個(gè)概率分布,因此原本交叉熵公式:
由于只有一個(gè)位置是1,其他位置都是0,所以硬生生變成了:
應(yīng)該不難看出,這是一個(gè)非常嚴(yán)格的監(jiān)督信號(hào),事實(shí)上網(wǎng)絡(luò)也的確做不到輸出某一類置信度100%,但整體的學(xué)習(xí)方向和目標(biāo)是沒問題的,能讓網(wǎng)絡(luò)的學(xué)習(xí)目標(biāo)為:目標(biāo)類位置上的得分最高,其他位置上得分都比目標(biāo)類低。
但事實(shí)上,大多數(shù)圖片是很難做到畫面中有且僅有目標(biāo)類內(nèi)容的,背景中難免會(huì)帶點(diǎn)別的東西,只不過可能不是畫面的主體,但對(duì)于神經(jīng)網(wǎng)絡(luò)來說,有就是有啊,這里面明明有這個(gè)東西,你卻告訴我它的置信度是0%?(我做對(duì)了事還要被罵.jpg)
所以這種過于強(qiáng)硬的監(jiān)督信號(hào)就可能帶來負(fù)面作用,使網(wǎng)絡(luò)的學(xué)習(xí)受到阻礙。
而改進(jìn)方案也很有名,叫做Label Smoothing,直譯的話可以叫標(biāo)簽軟化,什么意思呢?就是說我不再那么強(qiáng)硬地用100%和0%,我柔和一點(diǎn),目標(biāo)類我用90%,其他類我都用10%,這樣既不影響我原來的學(xué)習(xí)目標(biāo),又可以讓畫面中那些沒有標(biāo)注的類被預(yù)測(cè)出來時(shí)不會(huì)受到那么強(qiáng)的懲罰。
所以軟化后的交叉熵公式回到了原本的形式:
對(duì)分類問題進(jìn)行了以上簡(jiǎn)單介紹后,那么在關(guān)鍵點(diǎn)定位時(shí)Heatmap方法是怎么做的呢?
1. 定位問題
在為任何問題設(shè)計(jì)目標(biāo)函數(shù)時(shí),我們都必須明確我們的任務(wù)目標(biāo)是什么,對(duì)于圖片分類問題,我們的目標(biāo)是:目標(biāo)類位置上的得分最高,其他位置上得分都比目標(biāo)類低。
類比到關(guān)鍵點(diǎn)定位問題,我們的目標(biāo)應(yīng)該是:目標(biāo)點(diǎn)位置上的得分最高,其他位置上得分都比目標(biāo)點(diǎn)低。
這樣一看,是不是就會(huì)發(fā)現(xiàn)定位問題本質(zhì)上還是一個(gè)分類問題了?
所以按照這個(gè)思路,我們也可以想到,最原始的監(jiān)督信號(hào),也應(yīng)該是一個(gè)one-hot的標(biāo)注,即在一張二維平面上,只有目標(biāo)點(diǎn)所在的像素標(biāo)注為1,其他位置都為0,如果把這個(gè)二維向量拉直,那形狀就跟一維分類一模一樣:[0 0 0 1 0 0]
那么這樣做有什么不好呢?同樣類比分類問題,還是標(biāo)注信息惹的禍:在關(guān)鍵點(diǎn)標(biāo)注時(shí),我們沒法保證真的做到剛好在關(guān)鍵點(diǎn)那個(gè)像素標(biāo)注1,畢竟人都是會(huì)犯錯(cuò)的,再加上實(shí)際圖片往往還可能有模糊不清、遮擋等因素,標(biāo)注的結(jié)果跟真實(shí)位置有一點(diǎn)點(diǎn)偏移是再正常不過的了。
考慮到這個(gè)因素,再用one-hot去監(jiān)督就明顯不太好了,有時(shí)候網(wǎng)絡(luò)也許明明預(yù)測(cè)到了真實(shí)位置,卻因?yàn)闃?biāo)注員的標(biāo)注點(diǎn)歪了一個(gè)像素,導(dǎo)致網(wǎng)絡(luò)受到嚴(yán)厲懲罰,這對(duì)于性能自然是有很大影響的。
改進(jìn)方案也很自然,Label Smoothing嘛,但這一次卻不能像分類問題那樣0.9和0.1地來了,我們選擇了用高斯分布來渲染標(biāo)簽。
為什么呢?實(shí)際上,用高斯分布是引入了我們的一個(gè)先驗(yàn)知識(shí),即:離目標(biāo)點(diǎn)越近的像素得分應(yīng)該越高,目標(biāo)點(diǎn)上的得分最高。 這個(gè)先驗(yàn)知識(shí)是定位問題獨(dú)有的,而對(duì)分類問題顯然不適用,至于為什么用高斯分布,來自于中心極限定理的保證——任何大的數(shù)據(jù)都趨近于高斯分布,你怎么用它幾乎都是對(duì)的。
也很自然地可以想到,高斯分布只是一個(gè)很中庸的選擇,根據(jù)數(shù)據(jù)的真實(shí)分布,我們大可以選擇更好的分布來進(jìn)行監(jiān)督,能取得更好的效果。
經(jīng)過了軟化的標(biāo)簽,即使標(biāo)注信息有所偏移,但由于偏移通常也就幾個(gè)像素,所以網(wǎng)絡(luò)預(yù)測(cè)正確受到的懲罰相較于預(yù)測(cè)錯(cuò)誤還是小很多的。
2. 一點(diǎn)點(diǎn)延伸
其實(shí)上面已經(jīng)交代清楚了本文的標(biāo)題:為什么說Heatmap方法是分類問題。下面我進(jìn)行一點(diǎn)點(diǎn)的延伸:
(1)
用卷積神經(jīng)網(wǎng)絡(luò)做定位問題的一個(gè)優(yōu)勢(shì)在于,卷積網(wǎng)絡(luò)的本身是用一個(gè)個(gè)卷積核在圖片平面上滑動(dòng),就像在對(duì)目標(biāo)內(nèi)容做模式匹配一樣,這跟用全連接層擬合概率分布相比,保留了很多空間信息,因此效率上高多了。
(2)
分類問題的本質(zhì),回到網(wǎng)絡(luò)結(jié)構(gòu)上,網(wǎng)絡(luò)最后一層的全連接層是一個(gè)矩陣運(yùn)算,假如倒數(shù)第二層輸出的特征維度為M,類別數(shù)為N,那么這個(gè)矩陣的形狀就是(N, M),可以看成是N個(gè)長(zhǎng)度為M的向量。
從數(shù)學(xué)意義上,這個(gè)全連接層在做的,是讓網(wǎng)絡(luò)預(yù)測(cè)的特征向量,分別跟全連接層里學(xué)到的N個(gè)向量求內(nèi)積,所以才會(huì)越相似的向量之間內(nèi)積越大。
所以這背后的本質(zhì),是網(wǎng)絡(luò)在為每個(gè)類學(xué)習(xí)一個(gè)聚類中心。
(3)
對(duì)于標(biāo)準(zhǔn)的分類問題而言,總的類別數(shù)是固定的,不會(huì)莫名其妙多幾類或者少幾類,但是對(duì)定位問題來說,輸出的heatmap分辨率不同,這分類問題的類別數(shù)是不是就變化了?
分辨率越小,類別數(shù)就越少,即我們需要學(xué)習(xí)的聚類中心向量也少,那么這個(gè)分類問題就越簡(jiǎn)單;分辨率越大,類別數(shù)越多,每個(gè)聚類中心向量都學(xué)好的難度也就越大。
假如我們讓情況變得極端一點(diǎn),網(wǎng)絡(luò)預(yù)測(cè)的heatmap最小可以是1x1,即只有一個(gè)像素,那么這個(gè)時(shí)候,網(wǎng)絡(luò)預(yù)測(cè)的結(jié)果就變成了一個(gè)0-1的二分類問題,也就是在預(yù)測(cè)關(guān)鍵點(diǎn)的存在性。
所以關(guān)鍵點(diǎn)的存在性問題,實(shí)際上只是關(guān)鍵點(diǎn)定位問題的一個(gè)特殊情況,并且是難度最低的情況,也因此,在很多業(yè)務(wù)中我們需要知道每個(gè)點(diǎn)存在的概率時(shí),與其用最大響應(yīng)值點(diǎn)的置信度來作為存在性判斷,不如直接用一個(gè)頭部來做二分類準(zhǔn)確度高。
另一種極端情況是網(wǎng)絡(luò)預(yù)測(cè)的heatmap變大,當(dāng)heatmap跟輸入圖片一樣尺寸時(shí),我們的分類問題就成了對(duì)原圖片每一個(gè)像素進(jìn)行分類;假如我們的heatmap比原圖片還大,那我們的分類問題就是在亞像素上做的:錯(cuò)誤的量化誤差變成1/s。(當(dāng)然,代價(jià)是指數(shù)級(jí)上升的計(jì)算量,以及過擬合的風(fēng)險(xiǎn))
3. 尾語
這篇文章內(nèi)容實(shí)際上很基礎(chǔ),之所以寫出來一方面是對(duì)自己知識(shí)的一種梳理,另一方面也是受益于近期仔細(xì)拜讀了知乎上王峰大佬的Softmax系列文章,盡管大佬是做人臉識(shí)別任務(wù),但cv領(lǐng)域原本就是一通百通的,讀后我感覺收獲非常大,在此也強(qiáng)烈推薦大家前往閱讀。
https://zhuanlan.zhihu.com/p/45014864
如果這篇文章對(duì)你有所幫助,歡迎給我點(diǎn)個(gè)贊支持一下,我們下期再見~